やりたいこと
- Javaファイル群の複雑度を定量化したい
- ファイル単体の複雑度のみでなく、群として複雑度を定量化したい
なぜやりたい?
-
INPUT:仕様書、OUTPUT:Javaコードを生成するLLMタスクの難易度を定量的に把握したいから
- 複雑な問題を先に解くことはできない
- 複雑な問題であることを認識し、迂回策やMVPの定義を考えることに頭を使いたいから
-
「これつくりたい」って無邪気に言ってくる人に複雑さをどうにかして伝えたい
ツールをつくってみた
- tkinterを使ってGUIで動かせるようにしてみた
- ディレクトリを選んで分析ボタンを押すだけ
- 各種メトリクスが表示される
- 総合複雑度のスコアはメトリクスに重みづけた自作指標
動作イメージ
-
ディレクトリを選んで分析ボタンを押す
-
全体の複雑度の表示
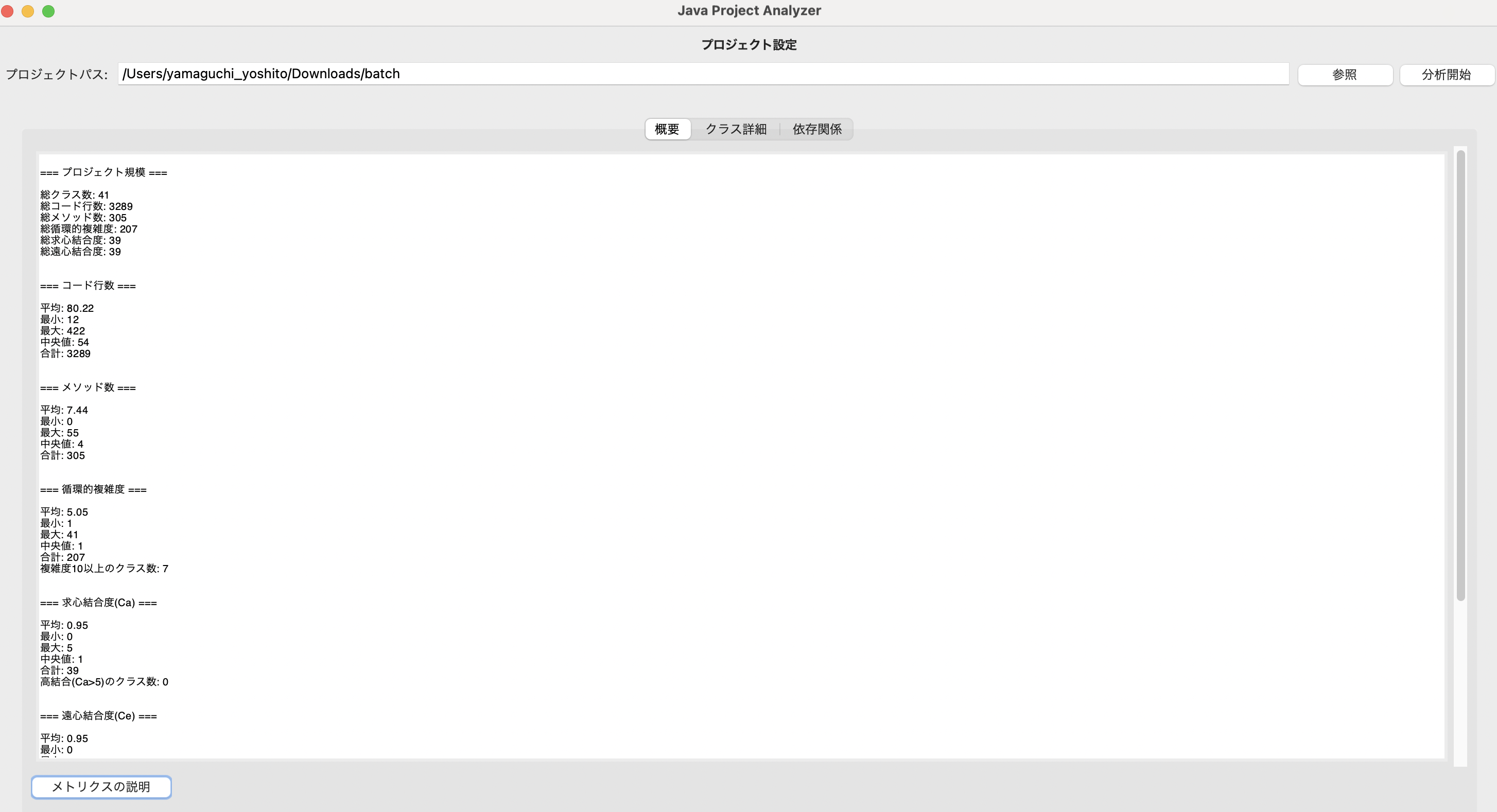
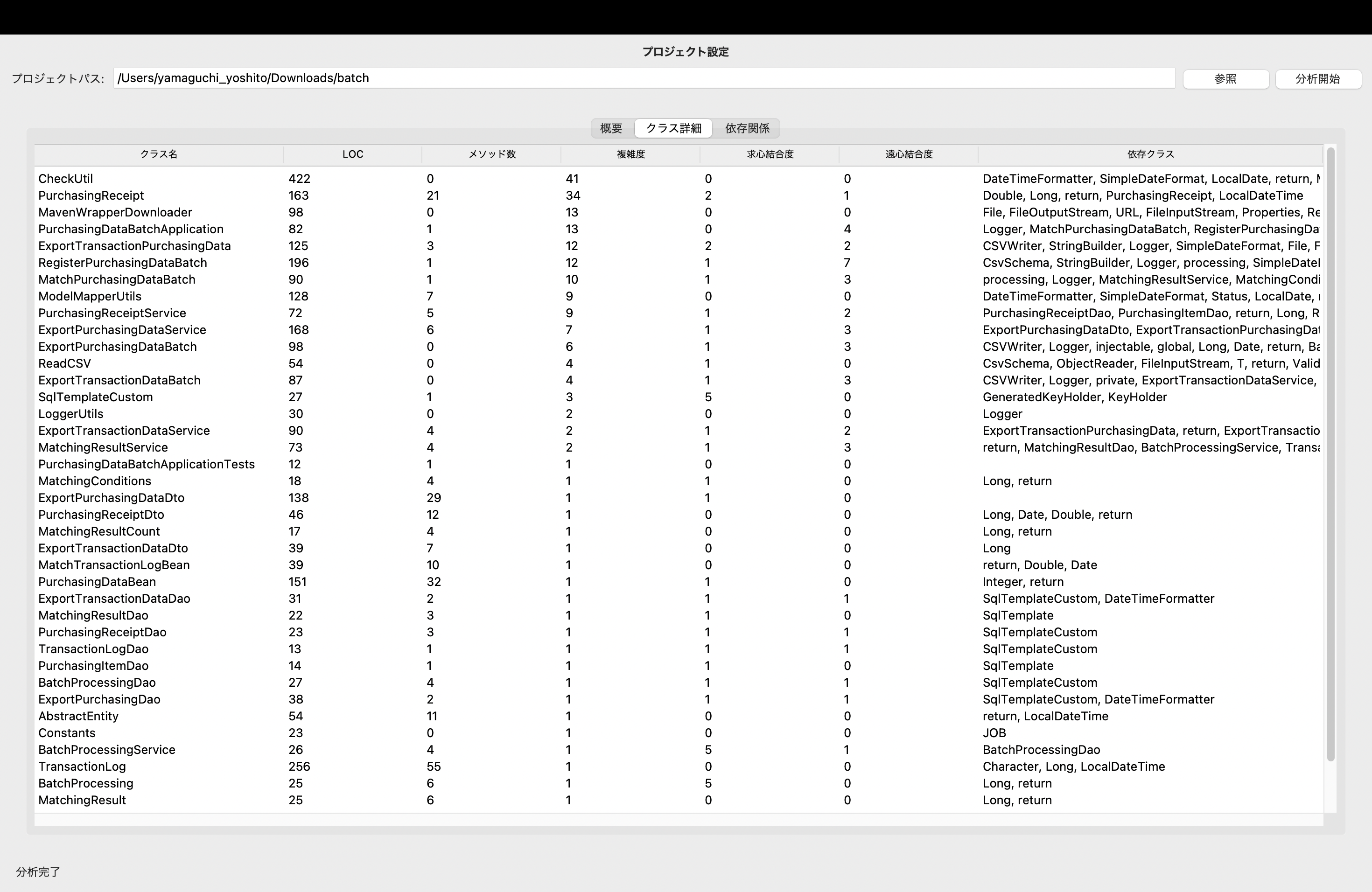
- クラスごとの複雑度
メトリクスの説明
以下は、各メトリクスの説明をまとめた表です。
| 指標名 | 説明 |
|---|---|
| LOC(Lines of Code) | コードの行数 |
| メソッド数 | クラス内に定義されているメソッドの数 |
| 循環的複雑度 | コードの複雑さを示す指標です。条件分岐やループが増えると値が高くなります。 |
| 求心結合度(Ca) | 他のクラスからどれだけ参照されているかを示します。値が高いほど他のクラスに影響を与えます。 |
| 遠心結合度(Ce) | 他のクラスをどれだけ参照しているかを示します。値が高いほど他のクラスに依存しています。 |
| 複雑度10以上のクラス数 | 循環的複雑度が10以上のクラスの数です。高すぎる場合はリファクタリングを検討してください。 |
動作コード
# ライブラリのインストール
pip install Pillow networkx pydot
java_project_complexity_analyzer.py
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from PIL import Image, ImageTk
import os
import re
from dataclasses import dataclass, field
from typing import Dict, Set, List
from collections import defaultdict
import networkx as nx
from pathlib import Path
import threading
import io
import pydot
@dataclass
class ClassMetrics:
"""Javaクラスの各種メトリクスを保持するクラス"""
class_name: str
file_path: str
loc: int = 0
methods: int = 0
cyclomatic_complexity: int = 0
imports: Set[str] = field(default_factory=set)
dependencies: Set[str] = field(default_factory=set)
afferent_coupling: int = 0
efferent_coupling: int = 0
class JavaProjectAnalyzer:
def __init__(self, project_path: str):
self.project_path = project_path
self.class_metrics: Dict[str, ClassMetrics] = {}
self.dependency_graph = nx.DiGraph()
def analyze_project(self):
"""プロジェクト全体の分析を実行"""
for java_file in Path(self.project_path).rglob("*.java"):
self.analyze_file(java_file)
self.analyze_dependencies()
self.calculate_coupling_metrics()
def analyze_file(self, file_path: Path):
"""個別のJavaファイルを分析"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
class_name = self._extract_class_name(content)
if not class_name:
return
metrics = ClassMetrics(
class_name=class_name,
file_path=str(file_path)
)
metrics.loc = self._count_loc(content)
metrics.methods = self._count_methods(content)
metrics.cyclomatic_complexity = self._calculate_complexity(content)
metrics.imports = self._extract_imports(content)
metrics.dependencies = self._extract_dependencies(content)
self.class_metrics[class_name] = metrics
def _extract_class_name(self, content: str) -> str:
"""クラス名を抽出"""
match = re.search(r'public\s+class\s+(\w+)', content)
return match.group(1) if match else ""
def _count_loc(self, content: str) -> int:
"""実効コード行数をカウント"""
lines = [line.strip() for line in content.split('\n')]
lines = [line for line in lines if line and not line.startswith('//')]
return len(lines)
def _count_methods(self, content: str) -> int:
"""メソッド数をカウント"""
pattern = r'(public|private|protected)\s+[\w\<\>\[\]]+\s+\w+\s*\([^\)]*\)\s*\{'
return len(re.findall(pattern, content))
def _calculate_complexity(self, content: str) -> int:
"""循環的複雑度を計算"""
complexity = 1
keywords = ['if', 'while', 'for', 'case', 'catch', '&&', '\\|\\|']
for keyword in keywords:
complexity += len(re.findall(rf'\b{keyword}\b', content))
return complexity
def _extract_imports(self, content: str) -> Set[str]:
"""インポート文を抽出"""
imports = re.findall(r'import\s+([\w\.]+);', content)
return set(imports)
def _extract_dependencies(self, content: str) -> Set[str]:
"""クラスの依存関係を抽出"""
deps = set(re.findall(r'new\s+(\w+)\s*\(', content))
deps.update(re.findall(r'(\w+)\s+\w+\s*[;=]', content))
return deps - {'String', 'int', 'long', 'double', 'float', 'boolean', 'char', 'byte', 'short'}
def analyze_dependencies(self):
"""依存関係グラフの構築"""
for class_name, metrics in self.class_metrics.items():
self.dependency_graph.add_node(class_name)
for dep in metrics.dependencies:
if dep in self.class_metrics:
self.dependency_graph.add_edge(class_name, dep)
def calculate_coupling_metrics(self):
"""結合度メトリクスの計算"""
for class_name, metrics in self.class_metrics.items():
metrics.efferent_coupling = len(list(self.dependency_graph.successors(class_name)))
metrics.afferent_coupling = len(list(self.dependency_graph.predecessors(class_name)))
def calculate_project_metrics(self) -> Dict[str, float]:
"""プロジェクト全体のメトリクスを計算"""
metrics = list(self.class_metrics.values())
if not metrics:
return {}
# 基本的な統計値の計算
loc_values = [m.loc for m in metrics]
method_values = [m.methods for m in metrics]
complexity_values = [m.cyclomatic_complexity for m in metrics]
afferent_values = [m.afferent_coupling for m in metrics]
efferent_values = [m.efferent_coupling for m in metrics]
return {
"プロジェクト規模": {
"総クラス数": len(metrics),
"総コード行数": sum(loc_values),
"総メソッド数": sum(method_values),
"総循環的複雑度": sum(complexity_values), # 合算値を追加
"総求心結合度": sum(afferent_values), # 合算値を追加
"総遠心結合度": sum(efferent_values), # 合算値を追加
},
"コード行数": {
"平均": round(sum(loc_values) / len(metrics), 2),
"最小": min(loc_values),
"最大": max(loc_values),
"中央値": sorted(loc_values)[len(loc_values)//2],
"合計": sum(loc_values) # 合計を追加
},
"メソッド数": {
"平均": round(sum(method_values) / len(metrics), 2),
"最小": min(method_values),
"最大": max(method_values),
"中央値": sorted(method_values)[len(method_values)//2],
"合計": sum(method_values) # 合計を追加
},
"循環的複雑度": {
"平均": round(sum(complexity_values) / len(metrics), 2),
"最小": min(complexity_values),
"最大": max(complexity_values),
"中央値": sorted(complexity_values)[len(complexity_values)//2],
"合計": sum(complexity_values), # 合計を追加
"複雑度10以上のクラス数": sum(1 for x in complexity_values if x >= 10)
},
"求心結合度(Ca)": {
"平均": round(sum(afferent_values) / len(metrics), 2),
"最小": min(afferent_values),
"最大": max(afferent_values),
"中央値": sorted(afferent_values)[len(afferent_values)//2],
"合計": sum(afferent_values), # 合計を追加
"高結合(Ca>5)のクラス数": sum(1 for x in afferent_values if x > 5)
},
"遠心結合度(Ce)": {
"平均": round(sum(efferent_values) / len(metrics), 2),
"最小": min(efferent_values),
"最大": max(efferent_values),
"中央値": sorted(efferent_values)[len(efferent_values)//2],
"合計": sum(efferent_values), # 合計を追加
"高結合(Ce>5)のクラス数": sum(1 for x in efferent_values if x > 5)
},
"コードの特徴": {
"最も大きいクラス": max(metrics, key=lambda m: m.loc).class_name,
"最も複雑なクラス": max(metrics, key=lambda m: m.cyclomatic_complexity).class_name,
"最も依存されているクラス": max(metrics, key=lambda m: m.afferent_coupling).class_name,
"最も依存しているクラス": max(metrics, key=lambda m: m.efferent_coupling).class_name,
}
}
def update_overview(self):
"""概要タブの更新"""
self.metrics_text.delete(1.0, tk.END)
metrics = self.analyzer.calculate_project_metrics()
def format_section(title, data):
result = f"=== {title} ===\n"
if isinstance(data, dict):
for key, value in data.items():
if isinstance(value, dict):
result += f"\n{key}:\n"
for subkey, subvalue in value.items():
result += f" {subkey}: {subvalue}\n"
else:
result += f"{key}: {value}\n"
result += "\n"
return result
# 各セクションを追加
for section, data in metrics.items():
self.metrics_text.insert(tk.END, format_section(section, data))
# 注意事項の追加
self.metrics_text.insert(tk.END, "\n=== メトリクスの解釈 ===\n")
self.metrics_text.insert(tk.END, "• 循環的複雑度が10以上のクラスは要注意\n")
self.metrics_text.insert(tk.END, "• 求心結合度(Ca)が高いクラスは変更の影響が大きい\n")
self.metrics_text.insert(tk.END, "• 遠心結合度(Ce)が高いクラスは保守性が低い\n")
class AnalyzerGUI:
def __init__(self, root):
self.root = root
self.root.title("Java Project Analyzer")
self.root.geometry("1600x1000")
self.analyzer = None
self.project_path = None
# メインウィンドウの設定
self.setup_gui()
def setup_gui(self):
# スタイル設定
style = ttk.Style()
style.configure("TNotebook", tabposition='n')
style.configure("TFrame", background="#f0f0f0")
style.configure("Header.TLabel", font=('Helvetica', 12, 'bold'))
self.main_frame = ttk.Frame(self.root, padding="10")
self.main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
self.setup_project_selection()
# より大きなノートブック
self.notebook = ttk.Notebook(self.main_frame)
self.notebook.grid(row=1, column=0, columnspan=2, pady=10, sticky=(tk.W, tk.E, tk.N, tk.S))
self.setup_overview_tab()
self.setup_classes_tab()
self.setup_dependencies_tab()
# ステータスバーの改善
status_frame = ttk.Frame(self.main_frame)
status_frame.grid(row=2, column=0, columnspan=2, sticky=(tk.W, tk.E))
self.status_var = tk.StringVar()
self.status_bar = ttk.Label(status_frame, textvariable=self.status_var, padding=(5, 2))
self.status_bar.pack(side=tk.LEFT)
# レイアウトの調整
self.root.grid_rowconfigure(0, weight=1)
self.root.grid_columnconfigure(0, weight=1)
self.main_frame.grid_rowconfigure(1, weight=1)
self.main_frame.grid_columnconfigure(0, weight=1)
def setup_project_selection(self):
frame = ttk.Frame(self.main_frame)
frame.grid(row=0, column=0, columnspan=2, pady=(0, 10), sticky=(tk.W, tk.E))
header = ttk.Label(frame, text="プロジェクト設定", style="Header.TLabel")
header.grid(row=0, column=0, columnspan=4, pady=(0, 5))
ttk.Label(frame, text="プロジェクトパス:").grid(row=1, column=0, padx=(0, 5))
self.path_var = tk.StringVar()
path_entry = ttk.Entry(frame, textvariable=self.path_var)
path_entry.grid(row=1, column=1, sticky=(tk.W, tk.E))
browse_btn = ttk.Button(frame, text="参照", command=self.browse_project)
browse_btn.grid(row=1, column=2, padx=5)
analyze_btn = ttk.Button(frame, text="分析開始", command=self.start_analysis)
analyze_btn.grid(row=1, column=3)
frame.columnconfigure(1, weight=1)
def setup_overview_tab(self):
self.overview_frame = ttk.Frame(self.notebook)
self.notebook.add(self.overview_frame, text="概要")
# メトリクス表示の改善
self.metrics_text = tk.Text(self.overview_frame, wrap=tk.WORD, height=20, font=('Helvetica', 10))
scrollbar = ttk.Scrollbar(self.overview_frame, orient=tk.VERTICAL, command=self.metrics_text.yview)
self.metrics_text.configure(yscrollcommand=scrollbar.set)
self.metrics_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S), padx=5, pady=5)
scrollbar.grid(row=0, column=1, sticky=(tk.N, tk.S))
# メトリクスの説明ボタンを追加
explain_button = ttk.Button(self.overview_frame, text="メトリクスの説明", command=self.show_metrics_explanation)
explain_button.grid(row=1, column=0, pady=5, sticky=tk.W)
self.overview_frame.columnconfigure(0, weight=1)
self.overview_frame.rowconfigure(0, weight=1)
def show_metrics_explanation(self):
explanation = (
"【メトリクスの説明】\n\n"
"・LOC(Lines of Code):\n"
" コードの行数を示します。値が大きいほどコード量が多いことを示します。\n\n"
"・メソッド数:\n"
" クラス内に定義されているメソッドの数です。\n\n"
"・循環的複雑度:\n"
" コードの複雑さを示す指標です。条件分岐やループが増えると値が高くなります。\n\n"
"・求心結合度(Ca):\n"
" 他のクラスからどれだけ参照されているかを示します。値が高いほど他のクラスに影響を与えます。\n\n"
"・遠心結合度(Ce):\n"
" 他のクラスをどれだけ参照しているかを示します。値が高いほど他のクラスに依存しています。\n\n"
"・複雑度10以上のクラス数:\n"
" 循環的複雑度が10以上のクラスの数です。高すぎる場合はリファクタリングを検討してください。\n"
)
messagebox.showinfo("メトリクスの説明", explanation)
def setup_classes_tab(self):
self.classes_frame = ttk.Frame(self.notebook)
self.notebook.add(self.classes_frame, text="クラス詳細")
# ツリービューの改善
columns = ("クラス名", "LOC", "メソッド数", "複雑度", "求心結合度", "遠心結合度", "依存クラス")
self.tree = ttk.Treeview(self.classes_frame, columns=columns, show="headings", selectmode="browse")
# 列の設定
column_widths = {
"クラス名": 200,
"LOC": 80,
"メソッド数": 80,
"複雑度": 80,
"求心結合度": 80,
"遠心結合度": 80,
"依存クラス": 300
}
for col, width in column_widths.items():
self.tree.heading(col, text=col, command=lambda c=col: self.sort_tree(c))
self.tree.column(col, width=width)
# スクロールバーの設定
scrollbar_y = ttk.Scrollbar(self.classes_frame, orient=tk.VERTICAL, command=self.tree.yview)
scrollbar_x = ttk.Scrollbar(self.classes_frame, orient=tk.HORIZONTAL, command=self.tree.xview)
self.tree.configure(yscrollcommand=scrollbar_y.set, xscrollcommand=scrollbar_x.set)
# 配置
self.tree.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
scrollbar_y.grid(row=0, column=1, sticky=(tk.N, tk.S))
scrollbar_x.grid(row=1, column=0, sticky=(tk.W, tk.E))
self.classes_frame.columnconfigure(0, weight=1)
self.classes_frame.rowconfigure(0, weight=1)
def setup_dependencies_tab(self):
self.dependencies_frame = ttk.Frame(self.notebook)
self.notebook.add(self.dependencies_frame, text="依存関係")
# 上下に分割したペイン
paned = ttk.PanedWindow(self.dependencies_frame, orient=tk.VERTICAL)
paned.pack(fill=tk.BOTH, expand=True)
# 依存関係リストの改善
top_frame = ttk.Frame(paned)
paned.add(top_frame, weight=1)
dep_label = ttk.Label(top_frame, text="クラス間の依存関係", style="Header.TLabel")
dep_label.pack(pady=(5,0))
self.dep_text = tk.Text(top_frame, wrap=tk.WORD, height=8, font=('Courier', 10))
dep_scroll = ttk.Scrollbar(top_frame, orient=tk.VERTICAL, command=self.dep_text.yview)
self.dep_text.configure(yscrollcommand=dep_scroll.set)
self.dep_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(5,0), pady=5)
dep_scroll.pack(side=tk.RIGHT, fill=tk.Y, pady=5)
# グラフ表示の改善
bottom_frame = ttk.Frame(paned)
paned.add(bottom_frame, weight=2)
graph_label = ttk.Label(bottom_frame, text="依存関係グラフ", style="Header.TLabel")
graph_label.pack(pady=(5,0))
# ズームコントロール
zoom_frame = ttk.Frame(bottom_frame)
zoom_frame.pack(fill=tk.X, padx=5)
ttk.Button(zoom_frame, text="拡大", command=lambda: self.zoom_graph(1.2)).pack(side=tk.LEFT, padx=2)
ttk.Button(zoom_frame, text="縮小", command=lambda: self.zoom_graph(0.8)).pack(side=tk.LEFT, padx=2)
ttk.Button(zoom_frame, text="リセット", command=lambda: self.zoom_graph(1.0, reset=True)).pack(side=tk.LEFT, padx=2)
# スクロール可能なキャンバス
self.canvas_frame = ttk.Frame(bottom_frame)
self.canvas_frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
self.canvas = tk.Canvas(self.canvas_frame, bg='white')
h_scroll = ttk.Scrollbar(self.canvas_frame, orient=tk.HORIZONTAL, command=self.canvas.xview)
v_scroll = ttk.Scrollbar(self.canvas_frame, orient=tk.VERTICAL, command=self.canvas.yview)
self.canvas.configure(xscrollcommand=h_scroll.set, yscrollcommand=v_scroll.set)
# キャンバスとスクロールバーの配置
self.canvas.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
h_scroll.grid(row=1, column=0, sticky=(tk.W, tk.E))
v_scroll.grid(row=0, column=1, sticky=(tk.N, tk.S))
self.canvas_frame.columnconfigure(0, weight=1)
self.canvas_frame.rowconfigure(0, weight=1)
# ズーム関連の変数
self.zoom_level = 1.0
self.original_image = None
def browse_project(self):
path = filedialog.askdirectory()
if path:
self.path_var.set(path)
def start_analysis(self):
path = self.path_var.get()
if not path:
messagebox.showerror("エラー", "プロジェクトパスを選択してください")
return
self.status_var.set("分析中...")
self.analyzer = JavaProjectAnalyzer(path)
thread = threading.Thread(target=self.run_analysis)
thread.start()
def run_analysis(self):
try:
self.analyzer.analyze_project()
self.root.after(0, self.update_ui)
self.root.after(0, lambda: self.status_var.set("分析完了"))
except Exception as e:
self.root.after(0, lambda: self.status_var.set(f"エラー: {str(e)}"))
self.root.after(0, lambda: messagebox.showerror("エラー", str(e)))
def update_ui(self):
self.update_overview()
self.update_classes_tree()
self.update_dependency_view()
self.update_dependency_graph()
def update_overview(self):
self.metrics_text.delete(1.0, tk.END)
metrics = self.analyzer.calculate_project_metrics()
def format_section(title, data):
result = f"\n=== {title} ===\n\n"
if isinstance(data, dict):
for key, value in data.items():
if isinstance(value, dict):
result += f"{key}:\n"
for subkey, subvalue in value.items():
result += f" {subkey}: {subvalue}\n"
else:
result += f"{key}: {value}\n"
result += "\n"
return result
# 各セクションを追加
for section, data in metrics.items():
self.metrics_text.insert(tk.END, format_section(section, data))
# 注意事項の追加
self.metrics_text.insert(tk.END, "\n=== メトリクスの解釈 ===\n\n")
self.metrics_text.insert(tk.END, "• 循環的複雑度が10以上のクラスは要注意\n")
self.metrics_text.insert(tk.END, "• 求心結合度(Ca)が高いクラスは変更の影響が大きい\n")
self.metrics_text.insert(tk.END, "• 遠心結合度(Ce)が高いクラスは保守性が低い\n")
def update_classes_tree(self):
self.tree.delete(*self.tree.get_children())
for metrics in sorted(self.analyzer.class_metrics.values(), key=lambda x: x.cyclomatic_complexity, reverse=True):
self.tree.insert("", tk.END, values=(
metrics.class_name,
metrics.loc,
metrics.methods,
metrics.cyclomatic_complexity,
metrics.afferent_coupling,
metrics.efferent_coupling,
", ".join(metrics.dependencies)
))
def update_dependency_view(self):
self.dep_text.delete(1.0, tk.END)
self.dep_text.insert(tk.END, "=== クラス間の依存関係 ===\n\n")
# 依存関係を整理してソート
dependencies = []
for class_name, metrics in sorted(self.analyzer.class_metrics.items()):
if metrics.dependencies:
deps = sorted(metrics.dependencies)
dependencies.append(f"{class_name} -> {', '.join(deps)}")
# 整理された依存関係を表示
for dep in sorted(dependencies):
self.dep_text.insert(tk.END, f"{dep}\n")
def update_dependency_graph(self):
try:
dot_data = nx.drawing.nx_pydot.to_pydot(self.analyzer.dependency_graph)
# グラフの設定を改善
dot_data.set_rankdir('LR')
dot_data.set_splines('ortho') # 直角の線を使用
# ノードとエッジのスタイルを改善
for node in dot_data.get_nodes():
node.set_shape('box')
node.set_style('filled,rounded') # 角丸の四角形
node.set_fillcolor('#E8F0FE') # 薄い青色
node.set_fontname('Helvetica')
node.set_fontsize('10')
for edge in dot_data.get_edges():
edge.set_color('#666666') # エッジの色を暗めのグレーに
edge.set_penwidth('1.0') # 線の太さ
png_data = dot_data.create_png()
# 画像の保存と表示
self.original_image = Image.open(io.BytesIO(png_data))
self.zoom_level = 1.0
# キャンバスのサイズに合わせて初期表示
self.zoom_graph(1.0, reset=True)
except Exception as e:
self.status_var.set(f"グラフの生成に失敗: {str(e)}")
messagebox.showerror("エラー", f"依存関係グラフの生成に失敗しました: {str(e)}")
def zoom_graph(self, factor, reset=False):
if self.original_image and hasattr(self, 'photo'):
if reset:
self.zoom_level = 1.0
else:
self.zoom_level *= factor
# 新しいサイズを計算
new_width = int(self.original_image.width * self.zoom_level)
new_height = int(self.original_image.height * self.zoom_level)
# リサイズして表示
resized = self.original_image.resize((new_width, new_height), Image.LANCZOS)
self.photo = ImageTk.PhotoImage(resized)
self.canvas.delete("all")
self.canvas.create_image(0, 0, image=self.photo, anchor=tk.NW)
self.canvas.configure(scrollregion=(0, 0, new_width, new_height))
def sort_tree(self, col):
"""ツリービューの列でソート"""
items = [(self.tree.set(item, col), item) for item in self.tree.get_children('')]
# 数値列は数値としてソート
if col in ["LOC", "メソッド数", "複雑度", "求心結合度", "遠心結合度"]:
items.sort(key=lambda x: float(x[0]) if x[0] else 0, reverse=True)
else:
items.sort()
for index, (_, item) in enumerate(items):
self.tree.move(item, '', index)
def export_metrics(self):
"""メトリクスをCSVファイルにエクスポート"""
if not self.analyzer:
messagebox.showerror("エラー", "プロジェクトを分析してください")
return
file_path = filedialog.asksaveasfilename(
defaultextension=".csv",
filetypes=[("CSV files", "*.csv"), ("All files", "*.*")]
)
if file_path:
try:
with open(file_path, 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
# ヘッダー行
writer.writerow([
"クラス名", "LOC", "メソッド数", "複雑度",
"求心結合度", "遠心結合度", "依存クラス"
])
# データ行
for metrics in self.analyzer.class_metrics.values():
writer.writerow([
metrics.class_name,
metrics.loc,
metrics.methods,
metrics.cyclomatic_complexity,
metrics.afferent_coupling,
metrics.efferent_coupling,
",".join(metrics.dependencies)
])
self.status_var.set(f"メトリクスを {file_path} にエクスポートしました")
except Exception as e:
messagebox.showerror("エラー", f"エクスポート中にエラーが発生しました: {str(e)}")
def save_dependency_graph(self):
"""依存関係グラフを画像ファイルとして保存"""
if not hasattr(self, 'original_image'):
messagebox.showerror("エラー", "依存関係グラフが生成されていません")
return
file_path = filedialog.asksaveasfilename(
defaultextension=".png",
filetypes=[("PNG files", "*.png"), ("All files", "*.*")]
)
if file_path:
try:
self.original_image.save(file_path)
self.status_var.set(f"依存関係グラフを {file_path} に保存しました")
except Exception as e:
messagebox.showerror("エラー", f"保存中にエラーが発生しました: {str(e)}")
def main():
root = tk.Tk()
app = AnalyzerGUI(root)
root.mainloop()
if __name__ == "__main__":
main()