はじめに
- LangGraphを用いたLLMエージェントの品質評価をどのようにおこなうか
- LangSmithでの評価方法をまとめます
元記事
要約
Agents
- LLMを用いた自律エージェントは3つの要素で構成される
- ツール呼び出し
- メモリ
- プランニング
- エージェントはこれらを組み合わせて応答を生成する
- ツール呼び出しでは、モデルが呼び出すツールと入力引数を生成する
Tool use
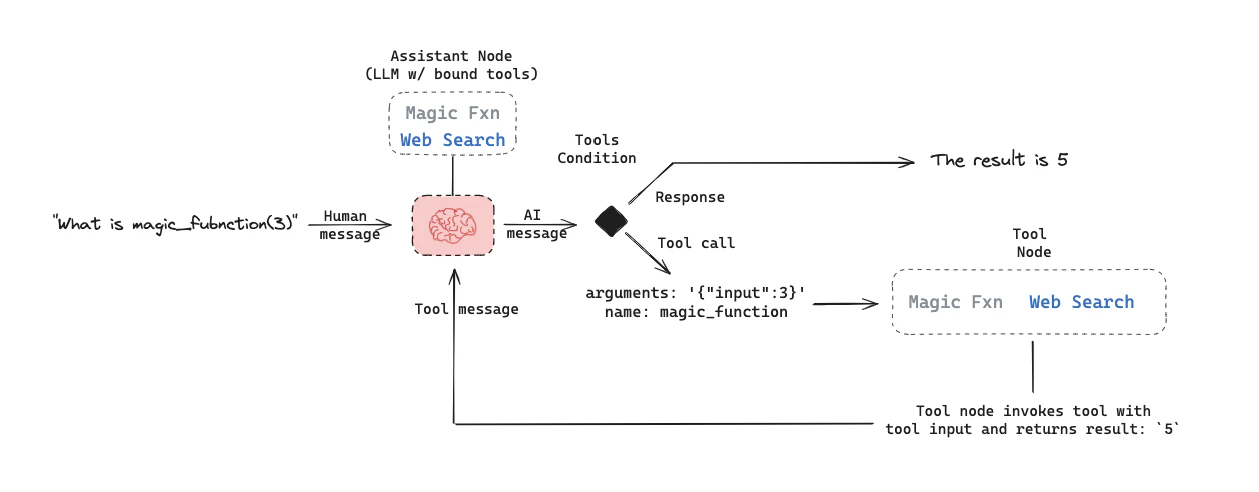
- LangGraphを用いたツール呼び出しエージェントの構造が説明されている
- アシスタントノード、ツール条件ノード、ツールノードで構成される
- ループ構造を持ち、ツールが選択されなくなるまで継続する
Agent評価の3つのタイプ
| 評価タイプ | 説明 | 評価対象 |
|---|---|---|
| 最終応答 Final Response |
エージェントの最終応答を評価する | タスク全体の達成度、最終的な出力の質 |
| 単一ステップ Single step |
エージェントの任意のステップを単独で評価する | 適切なツールの選択、個々のアクションの正確性 |
| 軌跡 Trajectory |
エージェントが予想される経路を辿ったかを評価する | ツール呼び出しの順序、全体的な問題解決プロセス |
Evaluating an agent's final response
-
エージェントがタスク全体でどの程度うまく機能するかを評価
- これは基本的に、エージェントをブラックボックスとして扱い、ジョブが完了するかどうかを評価することを含む
-
エージェントをブラックボックスとして扱い、タスク達成度を評価する
- 入力:ユーザー入力、(オプションで)ツールリスト
- 出力:エージェントの最終応答
-
評価器:エージェントに依頼するタスクによって異なる
- 多くのエージェントは比較的複雑な一連のステップを実行し、最終的なテキスト応答を出力する
- RAGと同様に、LLMを判定者とする評価器は、これらのケースでの評価に効果的である
- テキスト応答から直接、エージェントがジョブを完了したかどうかを評価できるため
利点と欠点
- 利点:総合的な性能評価が可能
- 欠点:
- 実行に時間がかかることが多い
- エージェント内部で起こることは評価していないため、失敗が発生した場合にデバッグが難しい
- 適切な評価指標を定義することが難しい場合がある
Evaluating a single step of an agent
- エージェントの個別のアクションを評価する
- 入力:単一ステップへの入力(ユーザー入力、ツールセット、前段階の結果など)
- 出力:そのステップのLLM応答(通常はツール呼び出しを含む)
- 評価者:正しいツール選択の二値スコアと、ツール入力の正確さのヒューリスティック
利点と欠点
- 利点:
- 個別のアクションを評価可能
- 実行が速い
- 評価が比較的簡単
- 欠点:
- エージェント全体を捉えられない
- データセット作成が困難(特に後半のステップ)
Evaluating an agent's trajectory
- エージェントが取ったすべてのステップの順序を評価する
- 入力:エージェント全体への入力(ユーザー入力、オプションでツールリスト)
- 出力:ツール呼び出しのリスト(厳密な順序または期待されるツールのリスト)
- 評価者:ステップのシーケンスに対する評価関数
評価方法
- 厳密な軌跡の一致を確認する二値スコア
- 「誤った」ステップの数に焦点を当てた評価指標
- 期待されるツールが任意の順序で呼び出されたかを確認
- LLM-as-judgeを用いた完全な軌跡の評価
利点と欠点
- 利点:エージェントの全体的な挙動を評価可能
- 欠点:
- 参照軌跡の作成が困難
- 評価指標の設計が難しい
Best practices
- 複数のツール呼び出しLLMをテストする
- 複数のレベルでエージェントを評価する(エンドツーエンドと個別ステップ)
- 繰り返しを用いてノイズを平滑化する
- LangSmith Evaluationシリーズの動画を参照する

Single step evaluation
- 複数のアクションを行うエージェントを評価する際、エンドツーエンドの評価だけでなく、個々のアクションを評価することも有用である
- これは、エージェントの単一のステップ(何をするかを決定するLLMコール)の評価を含む
- カスタム評価器を使用して、特定のツールコールをチェックできる
- ここでは、プロンプトを使用してアシスタントを呼び出し、結果のツールコールが期待通りかどうかをチェックする
- ツールがハードコードされた特殊なエージェントを使用している(データセット入力で渡されるのではなく)
- 評価中のステップの参照ツールコール
expected_tool_callを指定する
Trajectory
- カスタム評価器を使用して、ツールコールの軌跡をチェックできる
- ここでは、プロンプトを使用してエージェントを呼び出す
- ツールがハードコードされた特殊なエージェントを使用している(データセット入力で渡されるのではなく)
-
find_tool_callsを使用して、呼び出されたツールのリストを抽出する - カスタム関数は、これらのツールコールをさまざまなユーザー定義の方法で処理できる
- 期待されるすべてのツールが任意の順序で呼び出されたかどうかをチェックできる:
contains_all_tool_calls_any_order - 期待されるすべてのツールが、ツールコールの挿入を許可しながら、順番に呼び出されたかどうかをチェックできる:
contains_all_tool_calls_in_order - 期待されるすべてのツールが正確な順序で呼び出されたかどうかをチェックできる:
contains_all_tool_calls_in_order_exact_match
- 期待されるすべてのツールが任意の順序で呼び出されたかどうかをチェックできる: