はじめに
この記事では Amazon SageMaker を
実際に使ってみるハンズオン記事です。
主な内容としては実践したときのメモを中心に書きます。(忘れやすいことなど)
誤りなどがあれば書き直していく予定です。
対象読者
- クラウドを活用してデータサイエンスをやりたい人
- Python 書けるしデータサイエンスもなんとなくできるけどクラウドを使ったデータサイエンスはまだな人
- Amazon SageMaker のことがチョット気になっている人
※利用サービスの説明から入ります。
環境
-
初代 Surface Book
- 実装 RAM 8GB
-
エディション Windows 10 Pro
-
バージョン 20H2
-
OS ビルド 19042.867
-
Chrome
- 89.0.4389.90(Official Build) (64 ビット)
今回扱うサービス
- Git Hub
- Amazon SageMaker
- IAM
Git Hub とは
プログラムの元となるソースコードを共有、バージョン管理できるプラットフォーム
Amazon SageMaker とは
簡単に説明すると AWS の機械学習(ML)サービス
すべてのデータサイエンティストとデベロッパーのための機械学習
AWS の歴史の中で最も急速に成長しているサービスの 1 つ
ハンズオン開始
AWS マネジメントコンソールの操作
サービス検索で「SageMaker」と検索してサービス名をクリック
既存の Git リポジトリを AWS に設定
SageMaker のトップ画面にある左ペインから Git リポジトリの追加
ノートブック=>Git リポジトリの順にクリック

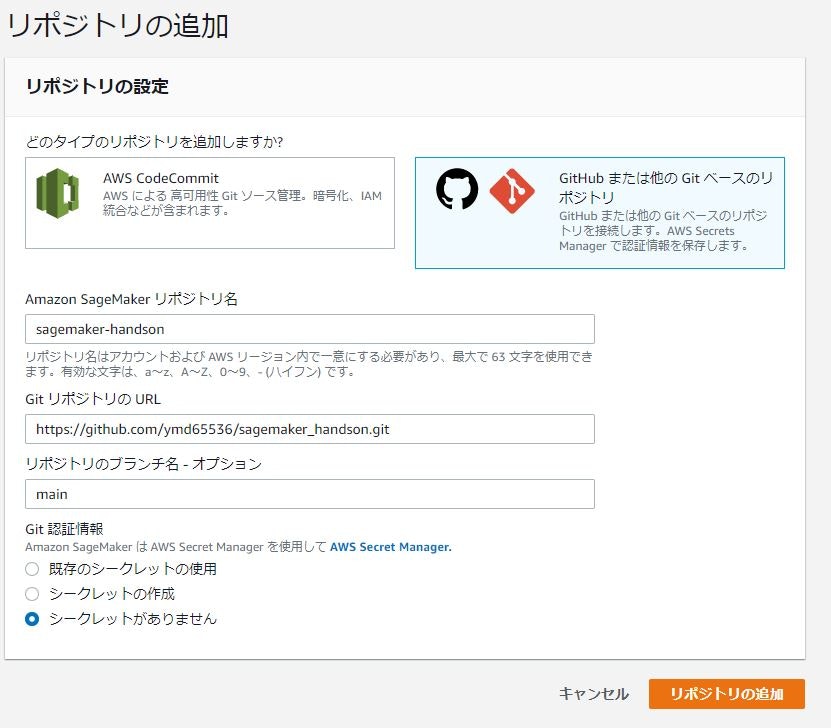
リポジトリの追加画面が表示される。以下のパラメータを各項目にセット
| 項目 | パラメータ |
|---|---|
| リポジトリタイプ | GitHub または 他の Git ベースのリポジトリ |
| Amazon SageMaker リポジトリ名 | sagemaker-handson |
| Git リポジトリの URL | https://github.com/ymd65536/sagemaker_handson.git |
| リポジトリのブランチ名 | main |
| Git 認証情報 | シークレットがありません |
ノートブックインスタンスの作成
SageMaker のトップ画面にある左ペインからノートブックインスタンスを作成する。
ノートブック=>ノートブックインスタンスの順にクリック

ノートブックインスタンスの作成をクリック後、以下のようにパラメータを設定
| 項目 | パラメータ |
|---|---|
| ノートブックインスタンス名 | sagemaker-handson |
| ノートブックインスタンスタイプ | ml.t2.medium |
| Elastic Inference | なし |
アクセス許可と暗号化
| 項目 | パラメータ |
|---|---|
| IAM ロール | 新しいロールの作成 |
| ルートアクセス | 無効化 |
| 暗号化キー | カスタム暗号化なし |
「新しいロールを作成」を選択するとロールを作成する画面に遷移
今回は S3 は利用しない為、なしにチェックを入れる。

ネットワーク
| 項目 | パラメータ |
|---|---|
| VPC オプション | 非 VPC |
Git リポジトリは先ほど指定したリポジトリを選択

| キー | バリュー |
|---|---|
| sagemaker | handson |

最後にノートブックインスタンスの作成をクリック
これで GitHub にあるリポジトリを保存したノートブックインスタンスが作成されます。
ノートブックインスタンスの作成には時間がかかります。
Pending から InService になるまでしばらく待ちましょう。


ノートブックインスタンスを使ってみる(Jupyter を利用)
ノートブックを開く
sagemaker-handson をクリック

「Jupyter を開く 」をクリック

クリックするとJupyter Notebook が起動します。
SageMaker_handson をクリック

main.ipynb をクリック
ノートブックを起動
起動時に Kernel not found と表示された場合は
「conda_python3」 を選択して Set Kernel をクリック
| 項目 | 値 |
|---|---|
| 利用 Kernel | conda_python3 |

ノートブックを実行
基本的な使い方
jupyter notebook はセルという単位でソースコードを管理します。
具体的には
In セルにはコードを入力
Out セルには In セルに入力したコードの実行結果が出力されます。
先頭行で 1 度宣言すると 2 行目以降からは宣言が不要になります。
ただし、宣言内容を変更した場合は再度実行する必要があります。
また、jupyter notebook は宣言済みの変数名を書いて実行すると
変数の中身が表示されます。
いくつか実行してみる
import と配列を宣言
今回は numpy を利用して配列 fish_data を計算します。
## numpyをインポート
import numpy as np
fish_data = np.array([2, 3, 3, 4, 4, 4, 4, 5, 5, 6,7])
合計値を計算
numpy の sum メソッドを利用して合計値を計算
# 合計値(sum_value)を出す
sum_value = np.sum(fish_data)
sum_value
## Out[2] 47
配列の長さを計算
# 標本の数 N を数える
N = len(fish_data)
N
## Out[3] 11
平均値を計算
# 平均を出す sum_value / N
# mean メソッドを利用
avg_m = np.mean(fish_data)
avg_m
## Out[4] 4.2727272727272725
または
# 平均を出す sum_value / N
# average を利用
a_avg = np.average(fish_data)
a_avg
## Out[5] 4.2727272727272725
最小値を計算
np.amin(fish_data)
## Out[6] 4.2727272727272725
ノートブックインスタンスを使ってみる(Jupyter Lab を利用)
ノートブックを開く
「JupyterLab を開く 」をクリック

フォルダマークをクリック
SageMaker-handson をクリック

main.ipynb をクリック
すると notebook の画面が表示されます。
統計量を計算(numpy pandas を利用)
厚生労働省のオープンデータにある PCR の検査人数を題材に統計量を計算してみました。
※一部抜粋でお送りします。
import os
import pandas as pd
import matplotlib.pyplot as plt
# https://www.mhlw.go.jp/stf/covid-19/open-data.html PCRの検査人数
download_file = 'pcr_tested_daily.csv'
# PCRの検査人数ファイルをダウンロード
if not os.path.isfile(download_file):
df = pd.read_csv('https://www.mhlw.go.jp/content/pcr_tested_daily.csv',
encoding='UTF-8', index_col=False)
else:
df = pd.read_csv(download_file, encoding='UTF-8',
index_col=False)
# 検査人数のデータフレームをCSV化
df.to_csv(download_file,index=False)
df_copy = df.rename(
columns={'日付': 'date', 'PCR 検査実施件数(単日)': 'num'}).fillna(0.0)
上記のコードで日付と PCR の検査人数をまとめたデータフレームが作成されます。
以下のコードを実行することでPCR の検査人数の統計量を計算することができます。
# データの要約
df_copy.describe()
pickle を利用することでデータフレームを保存することができます。
また、to_csv を利用することでデータフレームを CSV にして保存することができます。
import numpy as np
import pandas as pd
import os
## 1か月分のデータを作る
data = pd.date_range(start='2021-07-01',end='2021-07-30')
np.random.seed(123)
df = pd.DataFrame(np.random.randint(1,30,30),index=data,columns=['乱数'])
## pickle ファイル名
pickle_file = './test.pickle'
## csv ファイル名
csv_file = './test.csv'
## データフレームを保存 pickle
if not os.path.isfile(pickle_file):
df.to_pickle(pickle_file)
## データフレームを保存 csv
if not os.path.isfile(csv_file):
df.to_csv(csv_file)
df
一度、ファイルとして保存することで
迅速な表の展開と再現性を担保することができるようになります。
GitHub 上のリポジトリを編集
SageMaker 上の Jupyter Lab は変更履歴を GitHub にコミットしたり、プルしたりすることができます。
GitHub を操作するには同じみのブランチマークから実施します。

コミットする場合

プルする場合

Git の基本操作
add
commit
push
の 3 つが基本となります。
それ以外にも 2 つ重要なコマンドがあるので覚えておくと良いでしょう。
| コマンド | 内容 |
|---|---|
| git status | ブランチの状態を参照する |
| git log | 変更履歴を見る |
他、ブランチを切ってバージョン管理する場合は「git branch」コマンドが重要になります。
片付け
Jupyter Lab を閉じる
Jupyter Lab を起動している場合は
「File」をクリックして 「ShutDown」をクリック
Shutdown confirmation
と表示されましたら、Shut Down をクリック
Server Stopped と表示されましたら Window を × で閉じます。
ノートブックインスタンスを停止
ノートブックインスタンスを削除するにはまず、ノートブックインスタンスを停止する必要があります。
ノートブックインスタンスの名前にチェックをいれてアクションから停止をクリック

ステータスが Stopped になると停止完了です。

ノートブックインスタンスを削除
ノートブックインスタンスの名前にチェックをいれてアクションから削除をクリック
確認が入るので削除をクリック
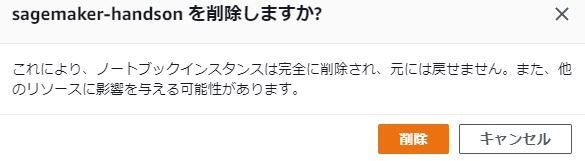
現在のリソースはありませんと表示されたら削除完了です。※ノートブックインスタンスが一つの場合
SageMaker に登録された Git リポジトリの削除
SageMaker のトップ画面にある左ペインから Git リポジトリを削除する。
ノートブック=>Git リポジトリの順にクリック
削除するリポジトリにチェックを入れて削除をクリック
以下のような確認が入るので削除をクリック
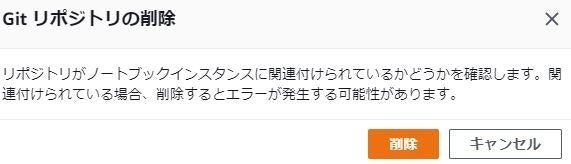
現在のリソースはありませんと表示されたら削除完了です。※git リポジトリが一つの場合
IAM ロールを削除
SageMaker でノートブックインスタンス構築時に新しいロールを作成したかと思います。
このロールを削除するには AWS マネジメントコンソールにある IAM から削除する必要があります。
IAM のページを開きましたら左ペインの「ロール」をクリック
削除対象の IAM ロールにチェックを入れて削除をクリック

確認が入るので IAM ロール名を入力して削除をクリック

まとめ
Amazon SageMaker を利用すると手元に実行環境を用意しなくても
Jupyter Notebook や Jupyter Lab を利用できる。
コンピューティングリソースは AWS のリソースを消費するので
自前でハイスペックな PC を準備する必要がない。
GitHub と連携することで手軽にローカル環境のリポジトリを
SageMaker 上のノートブックインスタンスに移行することができる。
ノートブックインスタンスを削除するときはインスタンスを停止してから削除を実行する。
おすすめ資料
参考技術書(Amazon 普通のリンク)
Pythonエンジニア育成推進協会監修 Python 3スキルアップ教科書 単行本(ソフトカバー) – 2019/10/7
キノコードさん
【毎日 Python】Pandas で CSV ファイルを読み込む方法| read_csv
【毎日 Python】Pandas で CSV ファイルに書き出しする方法| to_csv
【毎日 Python】Python でデータフレームの欠損値を置換する方法| fillna
【毎日 Python】Pandas でデータフレームの記述統計量を取得する方法| describe
【毎日 Python】Python でファイル名を変更する方法| rename
【毎日 Python】Python で指定したファイルの有無を確認する方法| isfile