概要
RedshiftのゼロETL統合を使って、BedrockナレッジベースでDynamoDBを自然言語検索します。
説明
BedrockナレッジベースでRedshiftがデータソースに選べるようになり、自然言語でDBに対してクエリが行える様になりました。一方、RedshiftではゼロETL統合という機能でAWSの様々なDBと同期することができます。つまり、実質的にAWSの様々なDBをナレッジベースのデータソースにできるようになったと言うことではないでしょうか。
ナレッジベースのデータソースにしたRedshiftでDynamoDBとゼロETL統合を行い、チャット上から確かめます。
準備
Redshift
Redshiftを作成していきます
初回セットアップがあるので、デフォルト設定のまま保存をしてください。
ダッシュボードが表示されたら、右上の「ワークグループを作成」をクリックします。
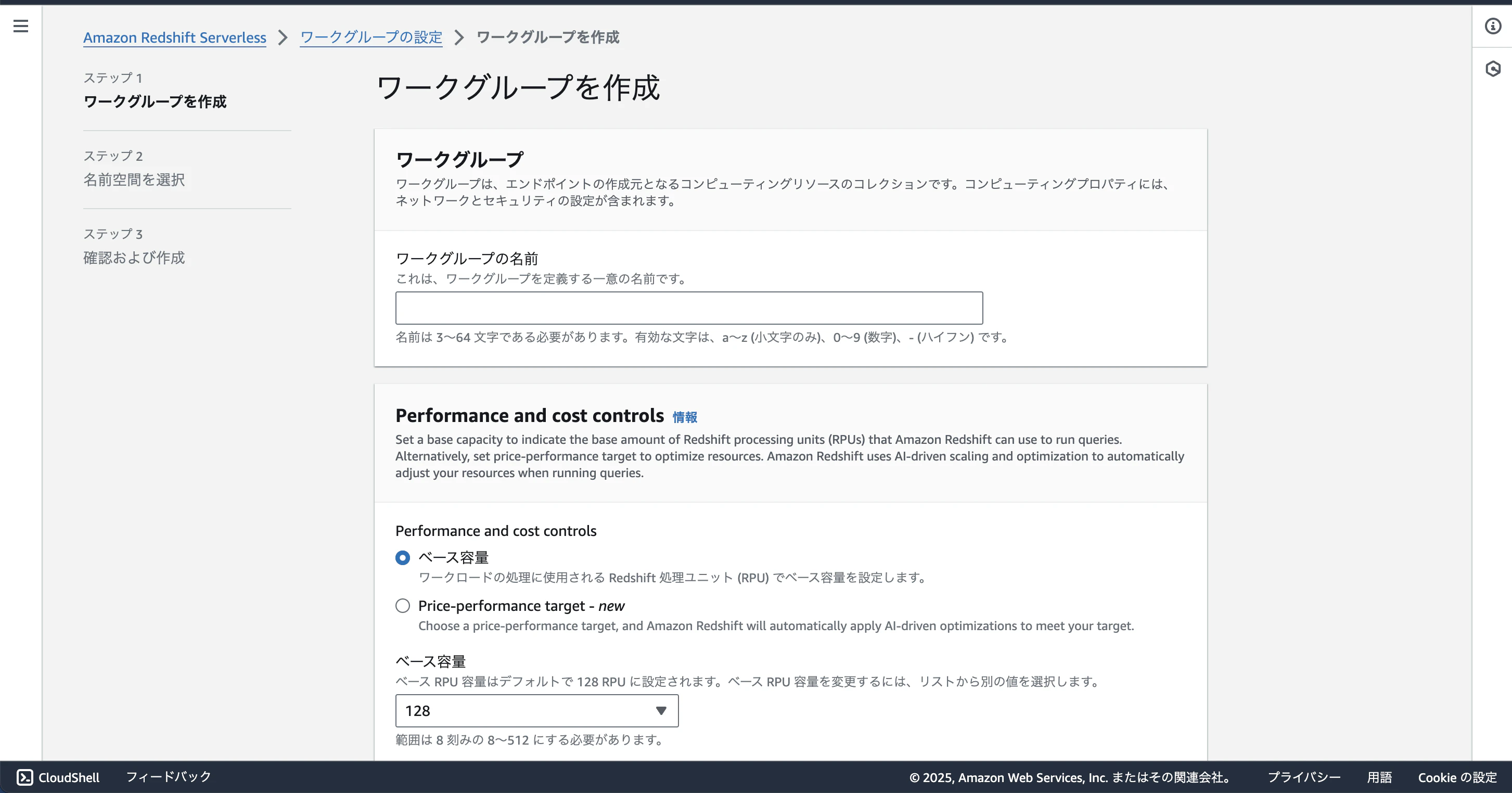
以下のような設定で作成します。ほかはデフォルトのものでよいです。
ステップ1:
ワークグループの名前:test-zero-etl-dynamo
ステップ2:
名前空間:test-zero-etl-dynamo
許可:「IAMロールを作成 > IAMロールをデフォルトとして作成する」をクリック
1分ほどでワークグループの作成が完了します。
dynamoDBテーブル
dynamoDBテーブルを作成していきます
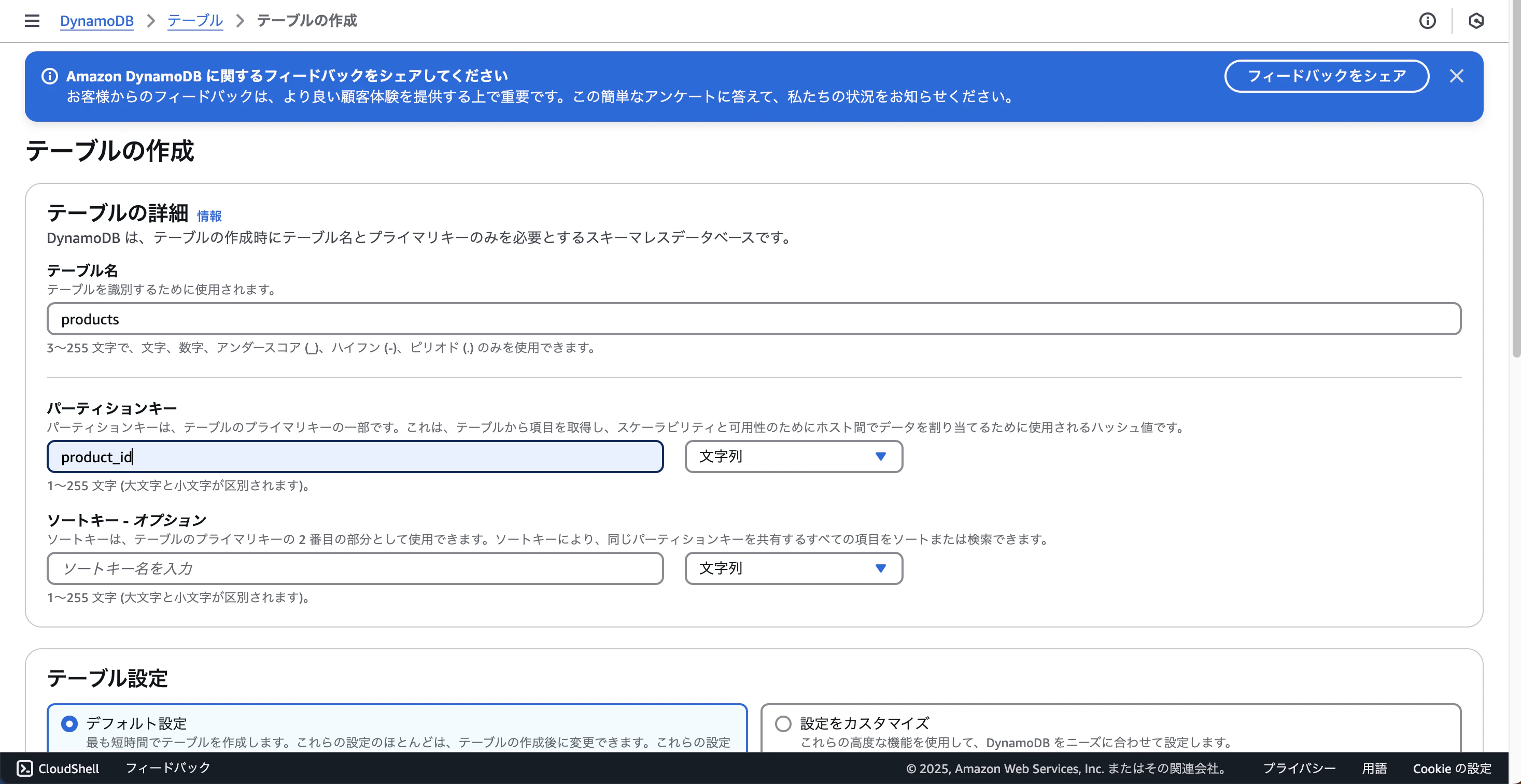
テーブル名: products
パーティションキー: product_id(文字列)
で作成してください
Zero-ETL統合の作成
準備ができたのでdynamoDBとRedshiftのZero-ETL統合の作成をします
サイドバーから「ゼロETL統合」を選択し、「Create DynamoDB integration」を選択します。
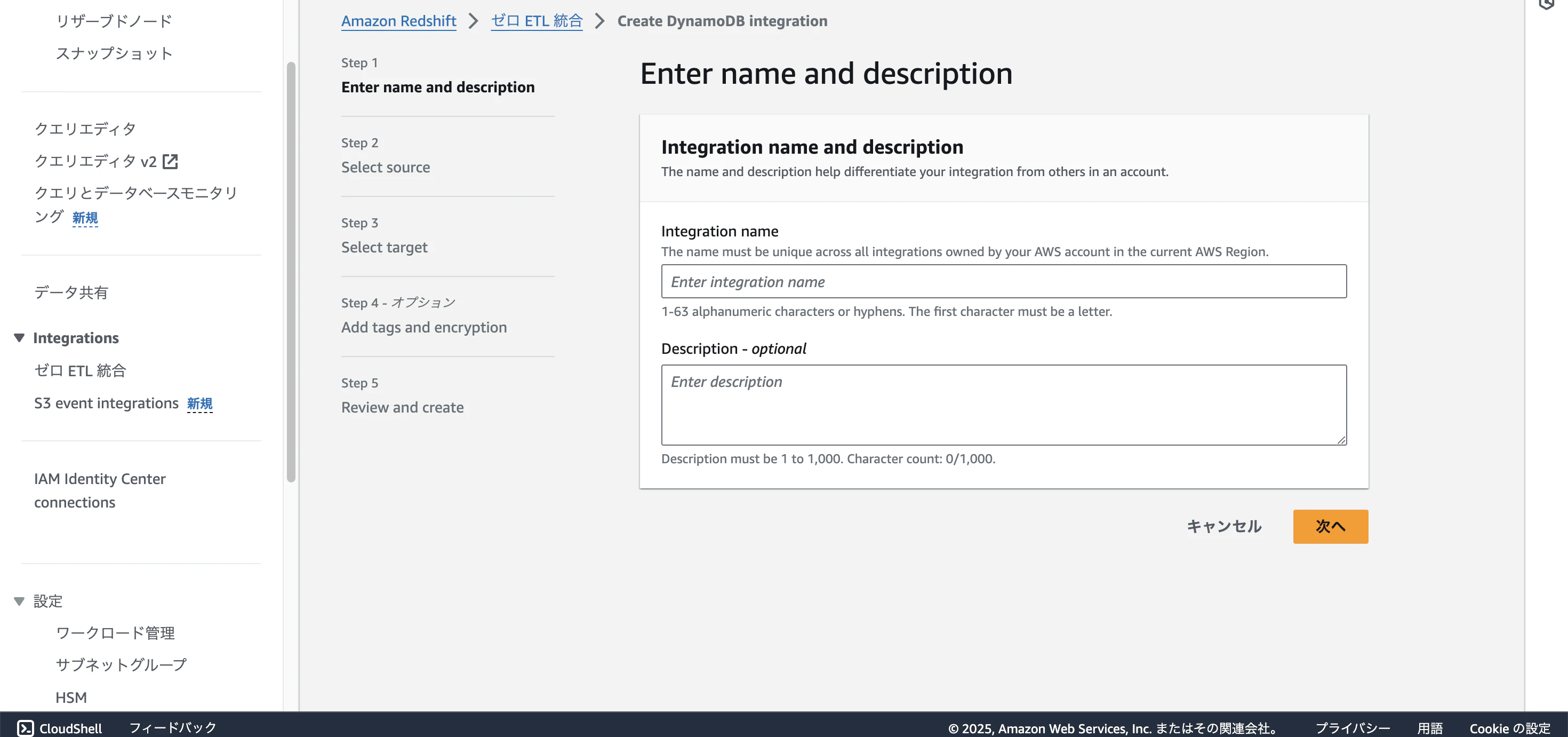
以下のような設定で作成します。ほかはデフォルトのものでよいです。
ステップ1:
Integration name:test-zero-etl-dynamo-integration
ステップ2:
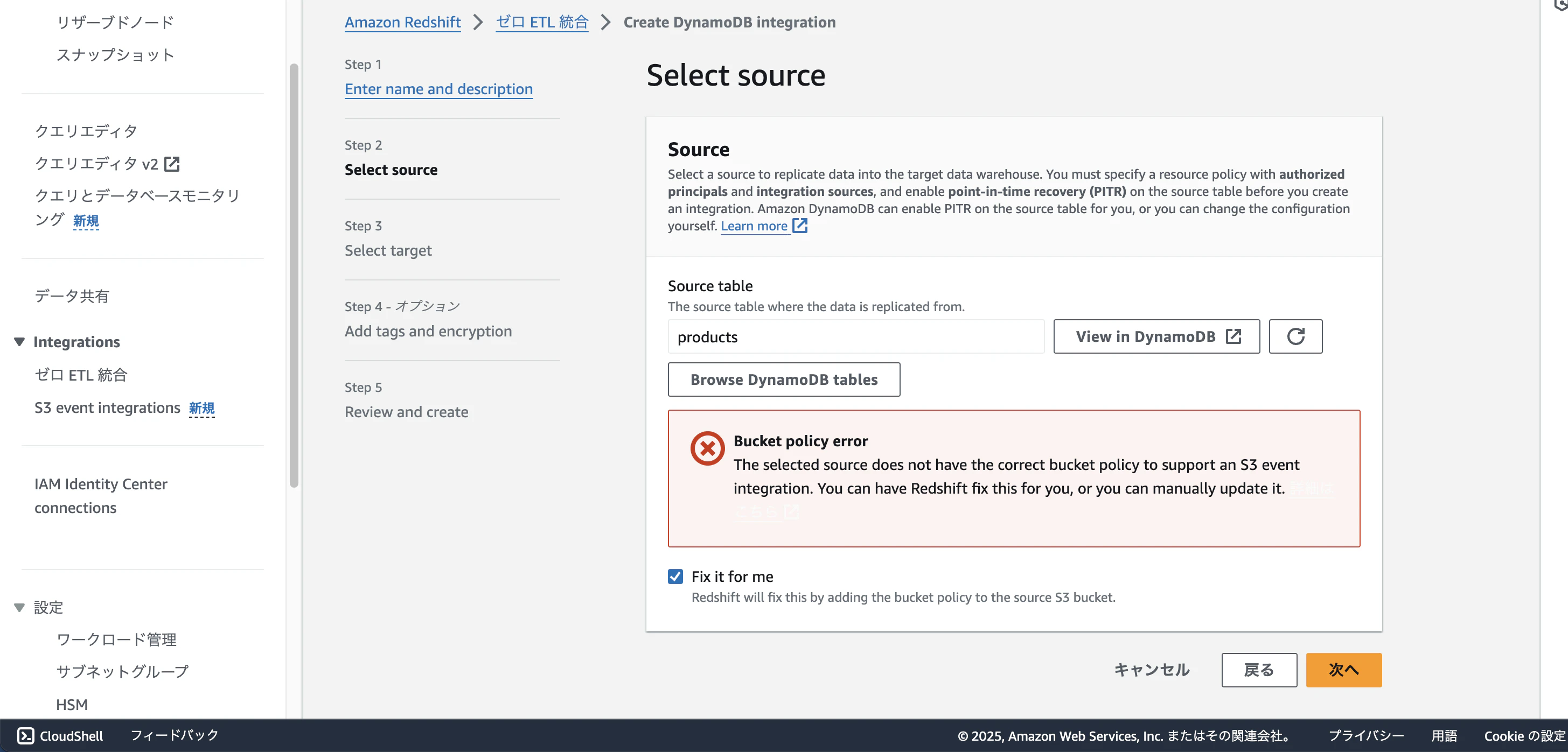
先ほど作成したdynamoDBテーブルを選択してください。画像のようなエラーがでるので「fix it for me」チェックを入れてください。
Zero-ETL統合を設定するには、選択したdynamoDBテーブルに適切なリソースポリシーとPITR設定が有効になっている必要があります。「fix it for me」オプションを選択すると、自動的に設定してくれます。
ステップ3:
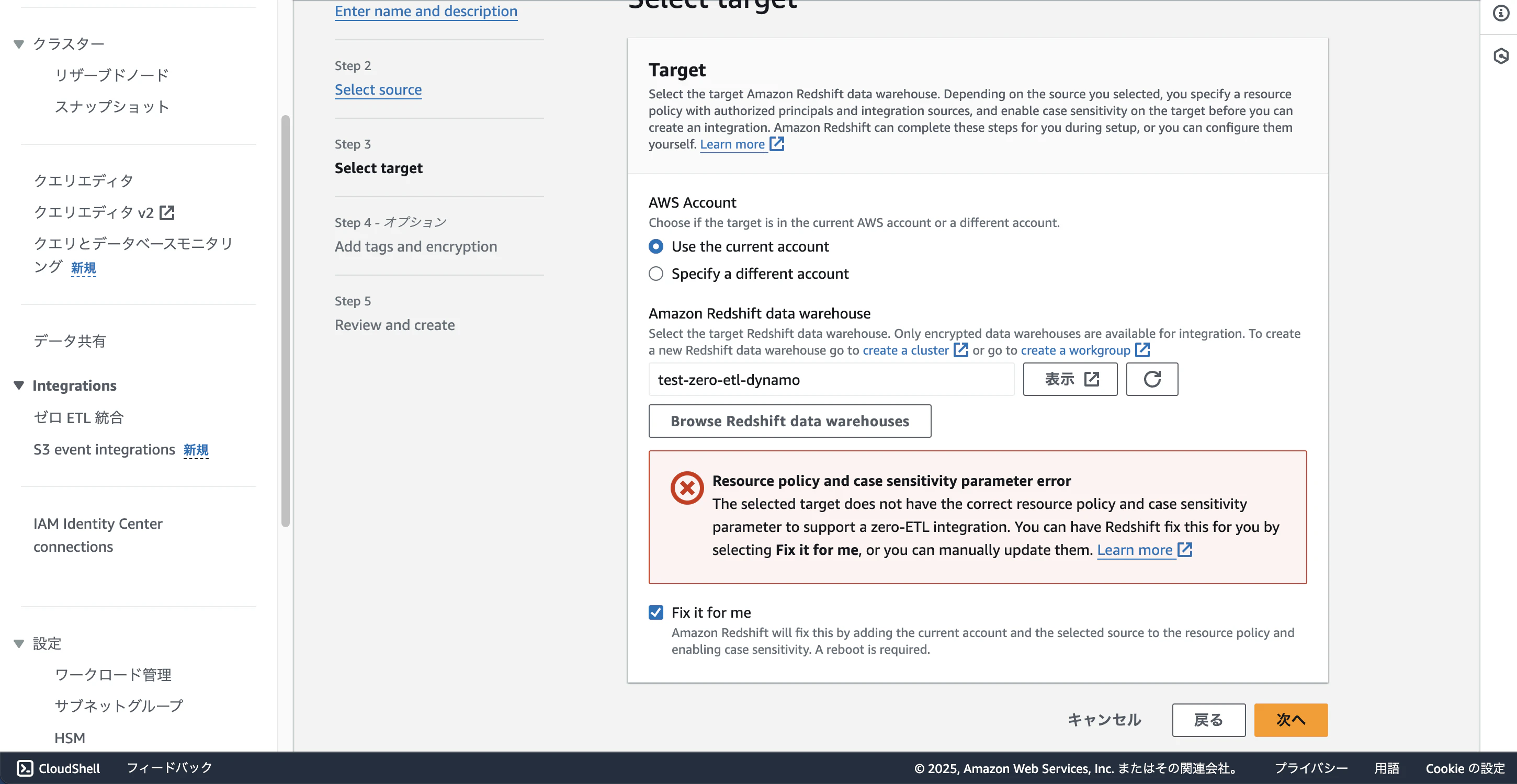
先ほど作成したRedshiftのワークグループを選択してください。画像のようなエラーがでるので「fix it for me」チェックを入れてください。こちらも必要な設定を自動的に設定してくれます。
ステップ4:
変更なし
ステップ5:
内容を確認して、「Create DynamoDB integration」を選択すると、Zero-ETL統合の作成が開始します。ステータスが「アクティブ」になれば問題ないです。
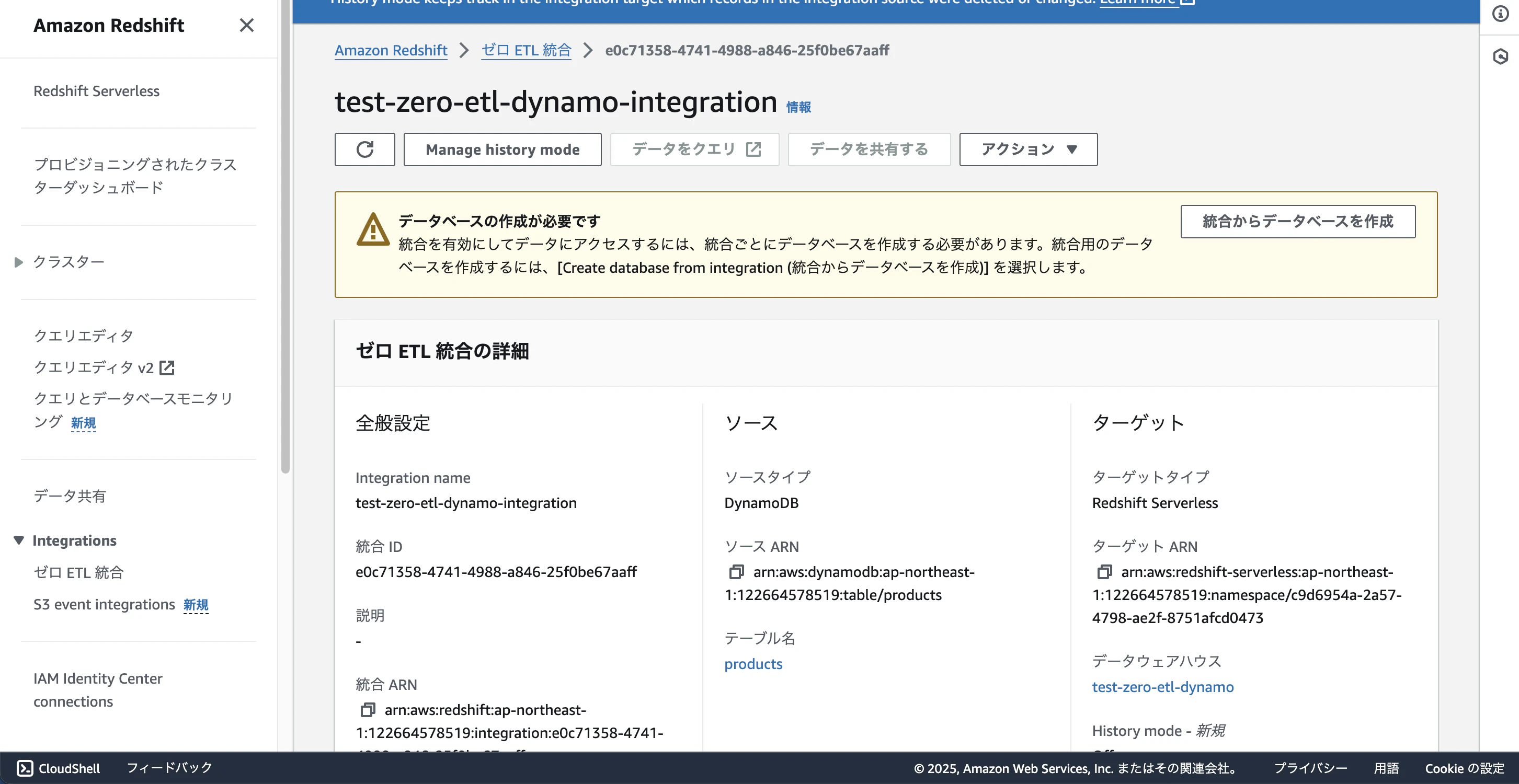
次は作成したZero-ETL統合を選択し、Redshiftのデータベースを作成します。
「統合からデータベースを作成」を選択してください。
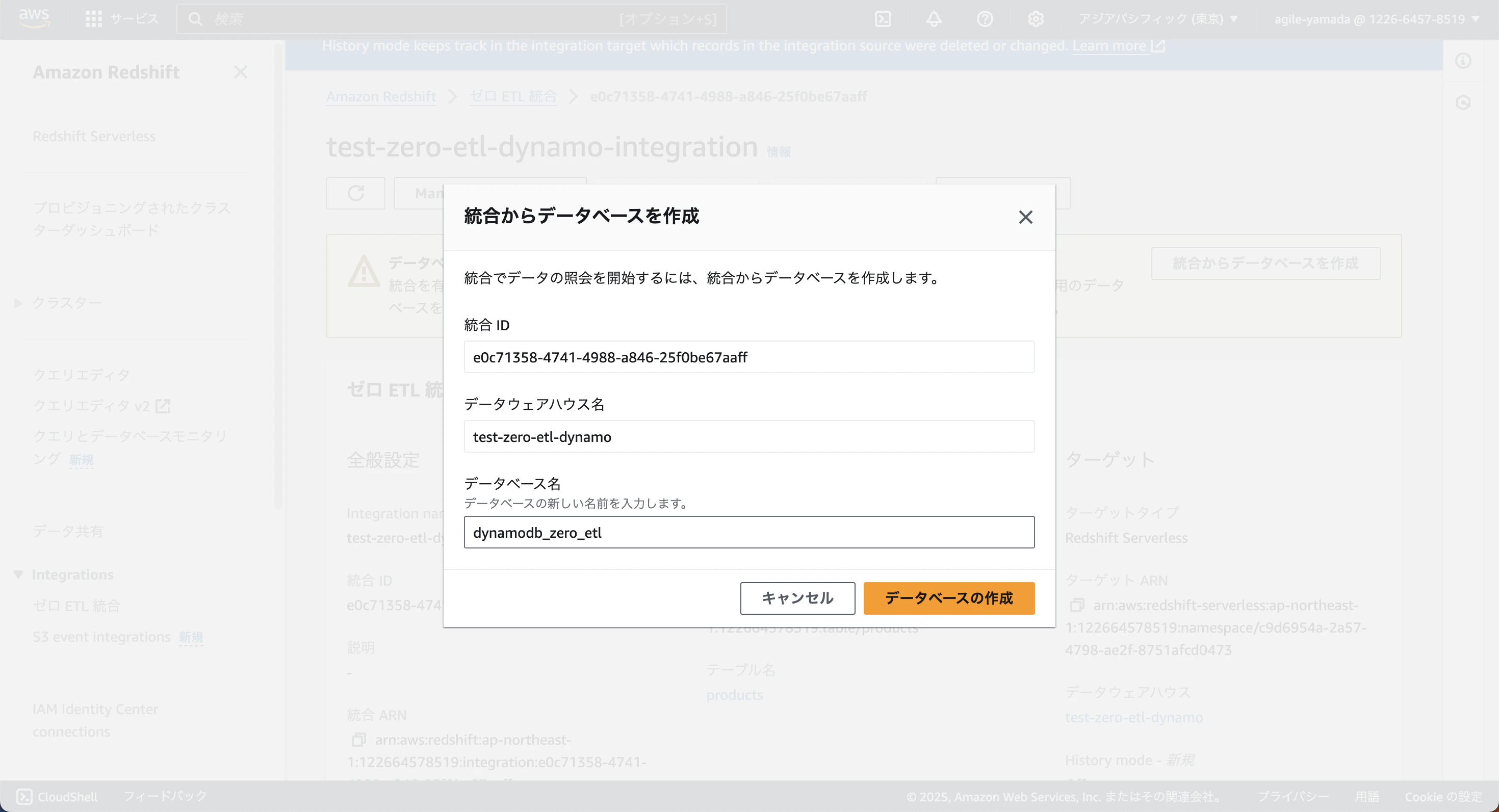
データベース名:dynamodb_zero_etl
で作成します。
ここまでで、dynamoDBと同期するための設定が終了しました。
では実際にdynamoDBにデータを挿入し、同期の様子をみてみましょう。
コンソールからデータをJSONで挿入します
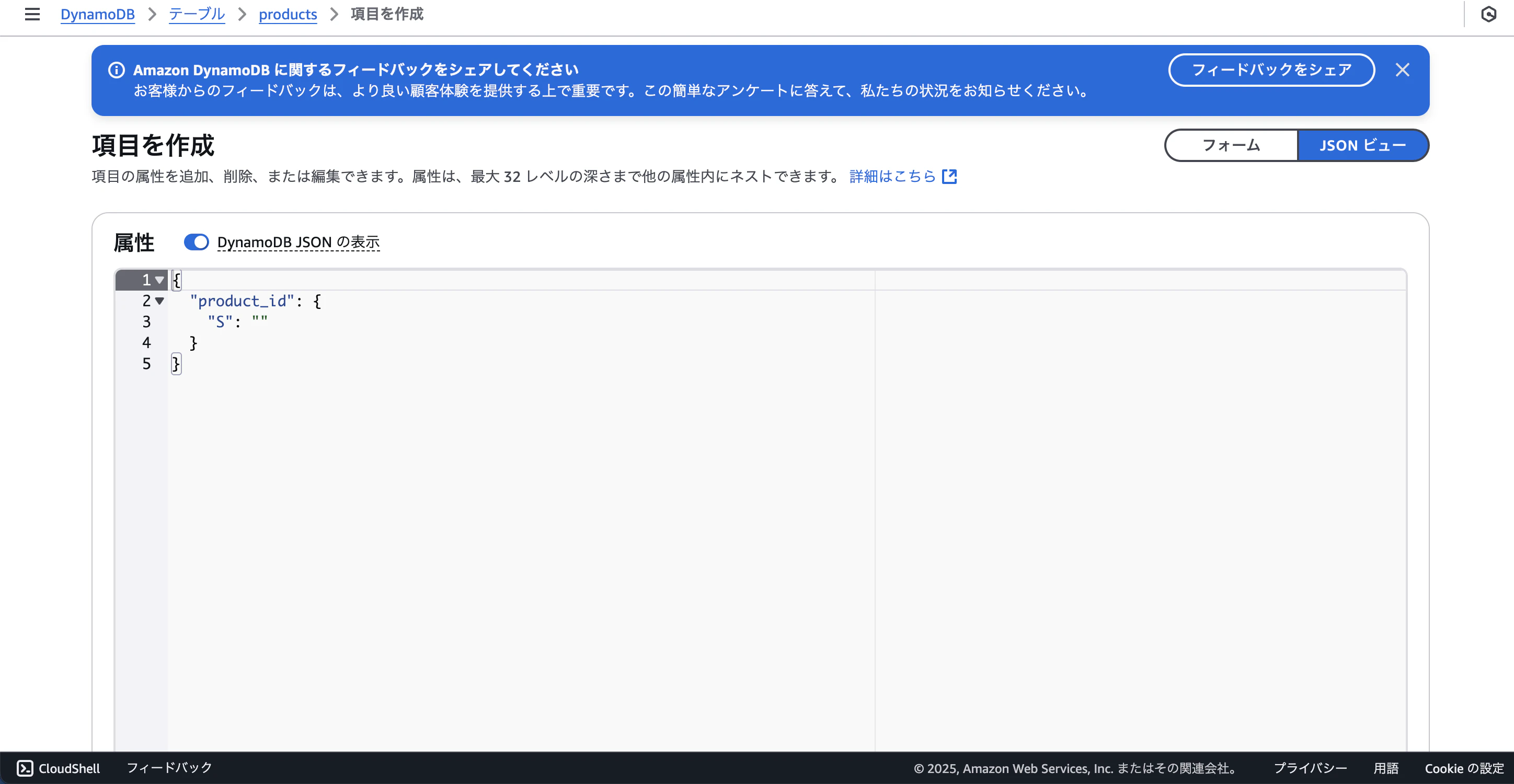
挿入データ
{
"product_id": {"S": "1"},
"product_name": {"S": "もも肉の焼き鳥"},
"sales": {"N": "800000"},
"popular_region": {"S": "大阪府"}
},

dynamoDBへのデータ挿入と同時にRedshift側では自動同期が動いています。
実際にRedshift内のデータを確認してみましょう
「ゼロETL統合」から作成した統合を選択し、「データをクエリ」を選択
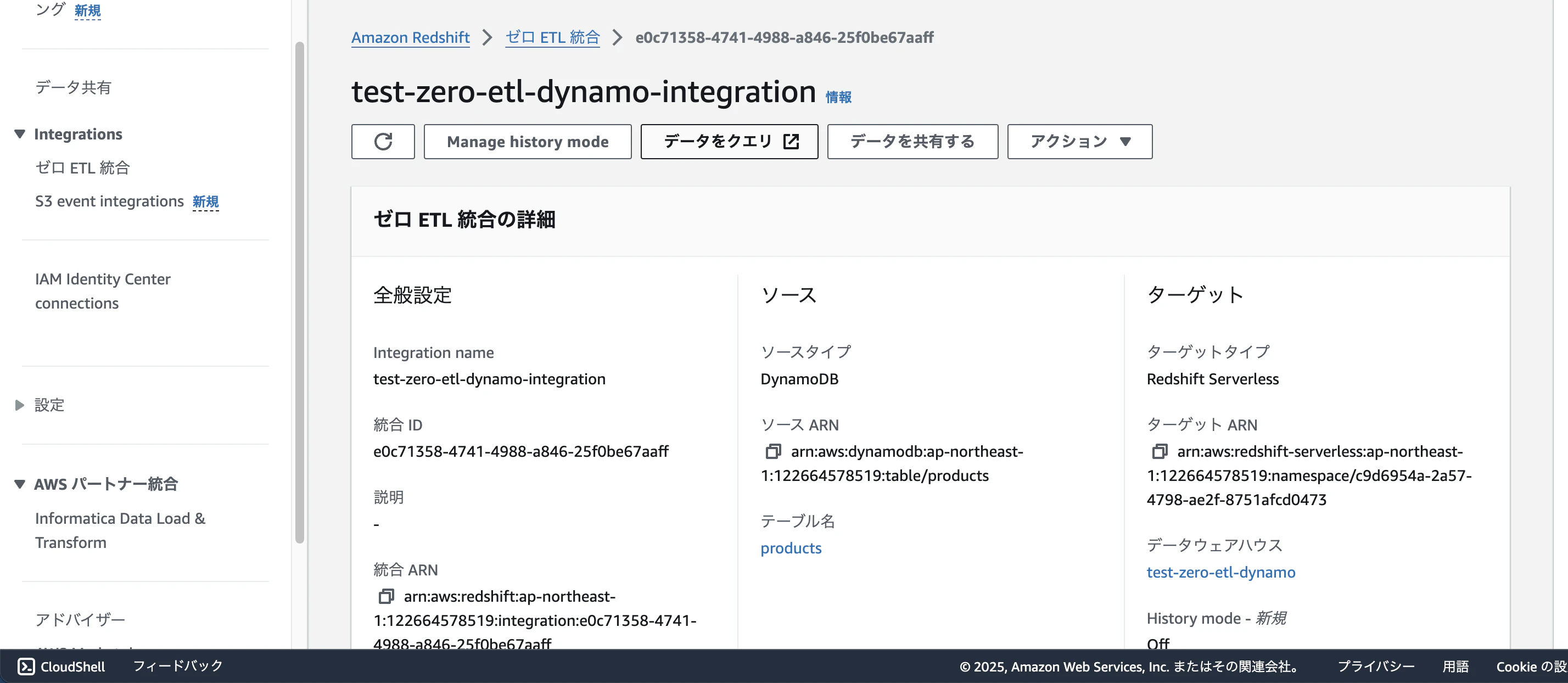
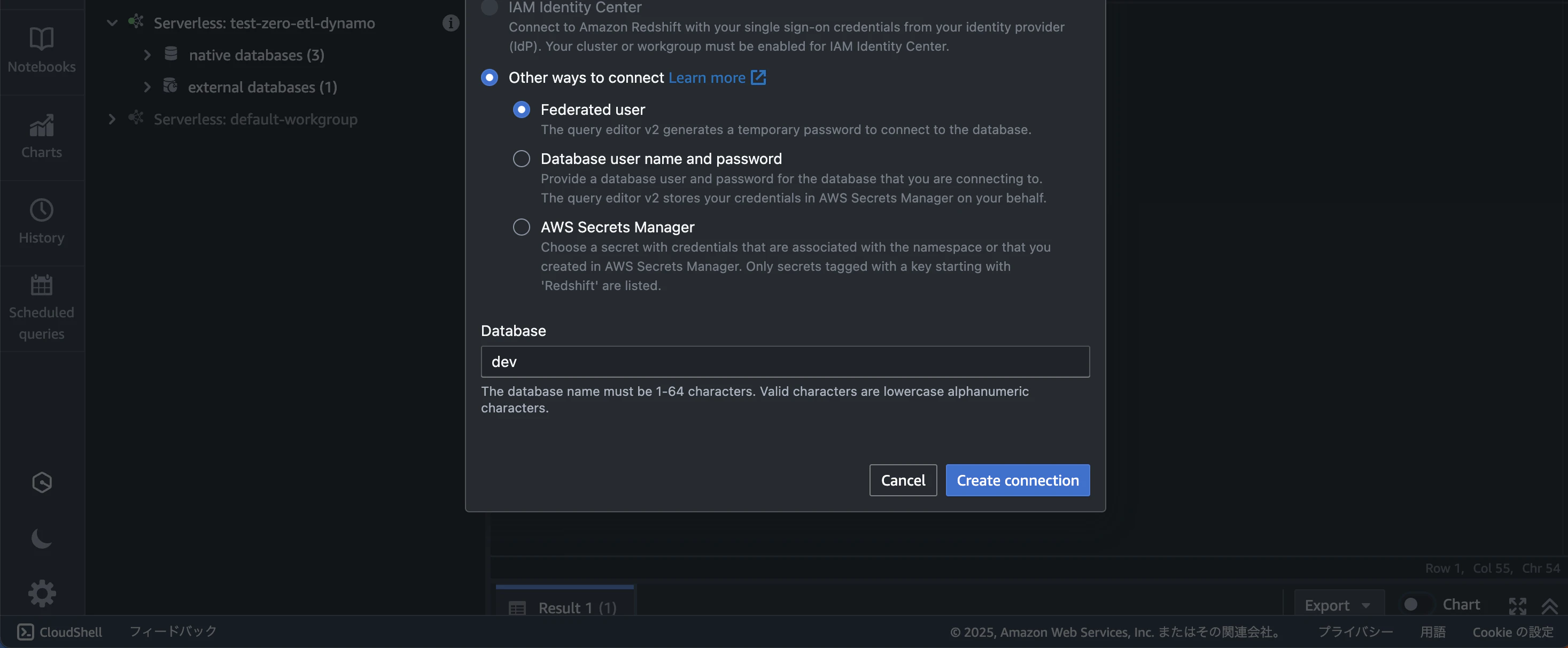
左側のワークグループ一覧から、今回作成した「test-zero-etl-dynamo」を選択し、「Federated user」で接続してください
dynamoDBの「products」テーブルが「test-zero-etl-dynamo」ワークグループの「dynamodb_zero_etl」データベースのテーブルとして存在していることがわかると思います。また、先程挿入したデータがクエリできています。
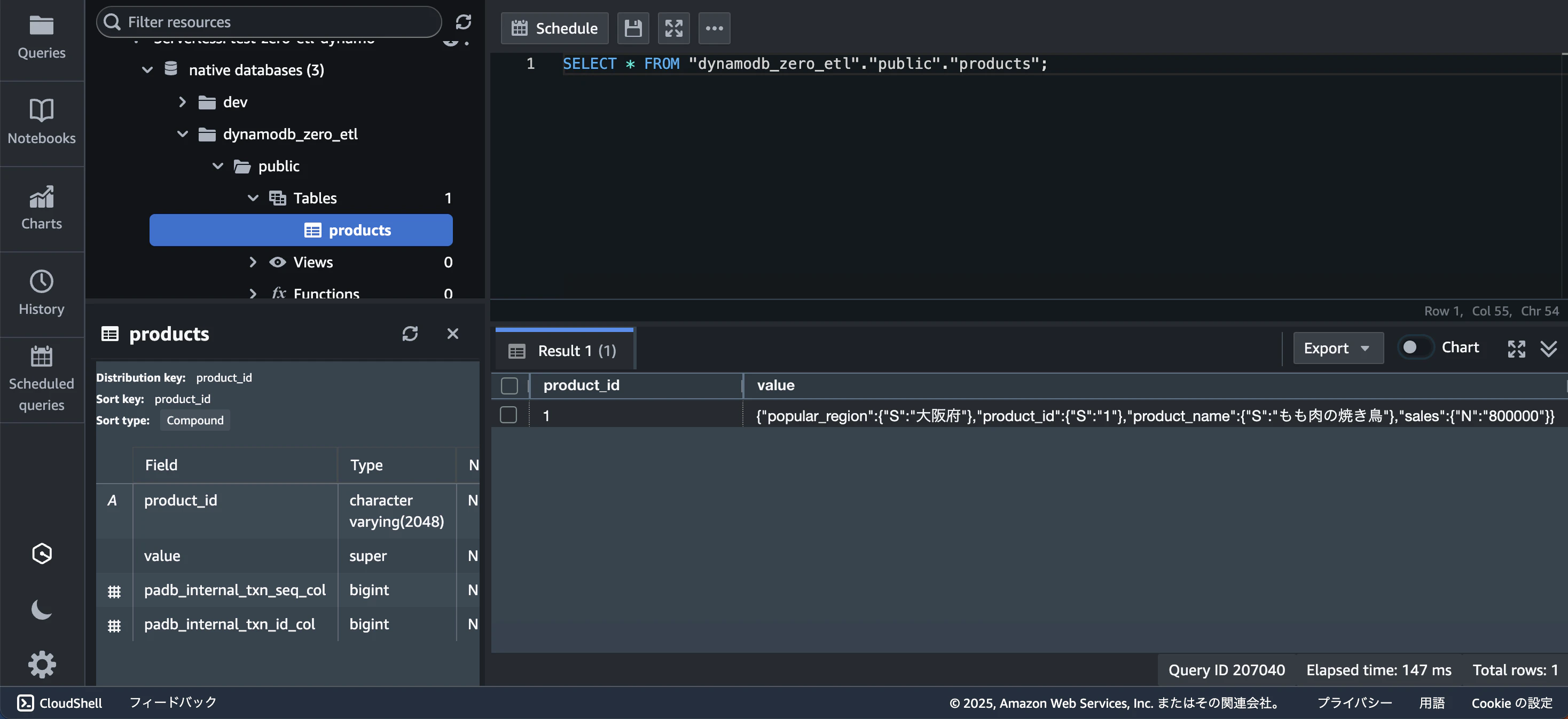
これでRedshiftのゼロETL統合を用いてdynamoDBテーブルと同期する作業は完了です。
ナレッジベースの作成
最後にナレッジベースを作成します。コンソールから「Create knowledge base with structured data store」を選択してください
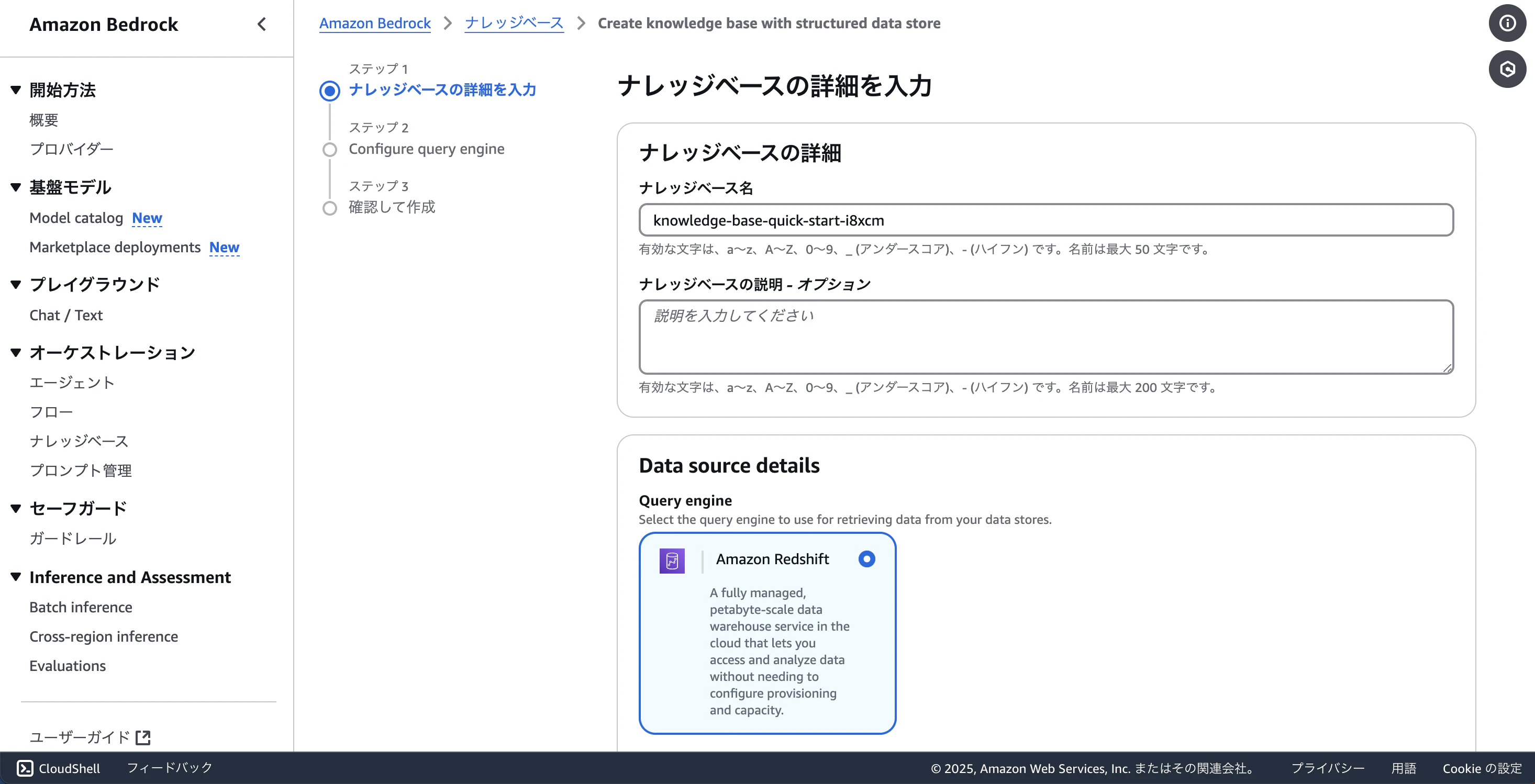
以下のような設定で作成します。ほかはデフォルトのものでよいです。
ステップ1:
ナレッジベース名:dynamo-products
IAM 許可:新しいサービスロールを作成して使用
サービスロール名:AmazonBedrockExecutionRoleForKnowledgeBase_dynamo-products
ステップ2:
ワークグループとDBを選択する箇所があるので今回作成したものを選択してください。ほかはデフォルトで良いです。
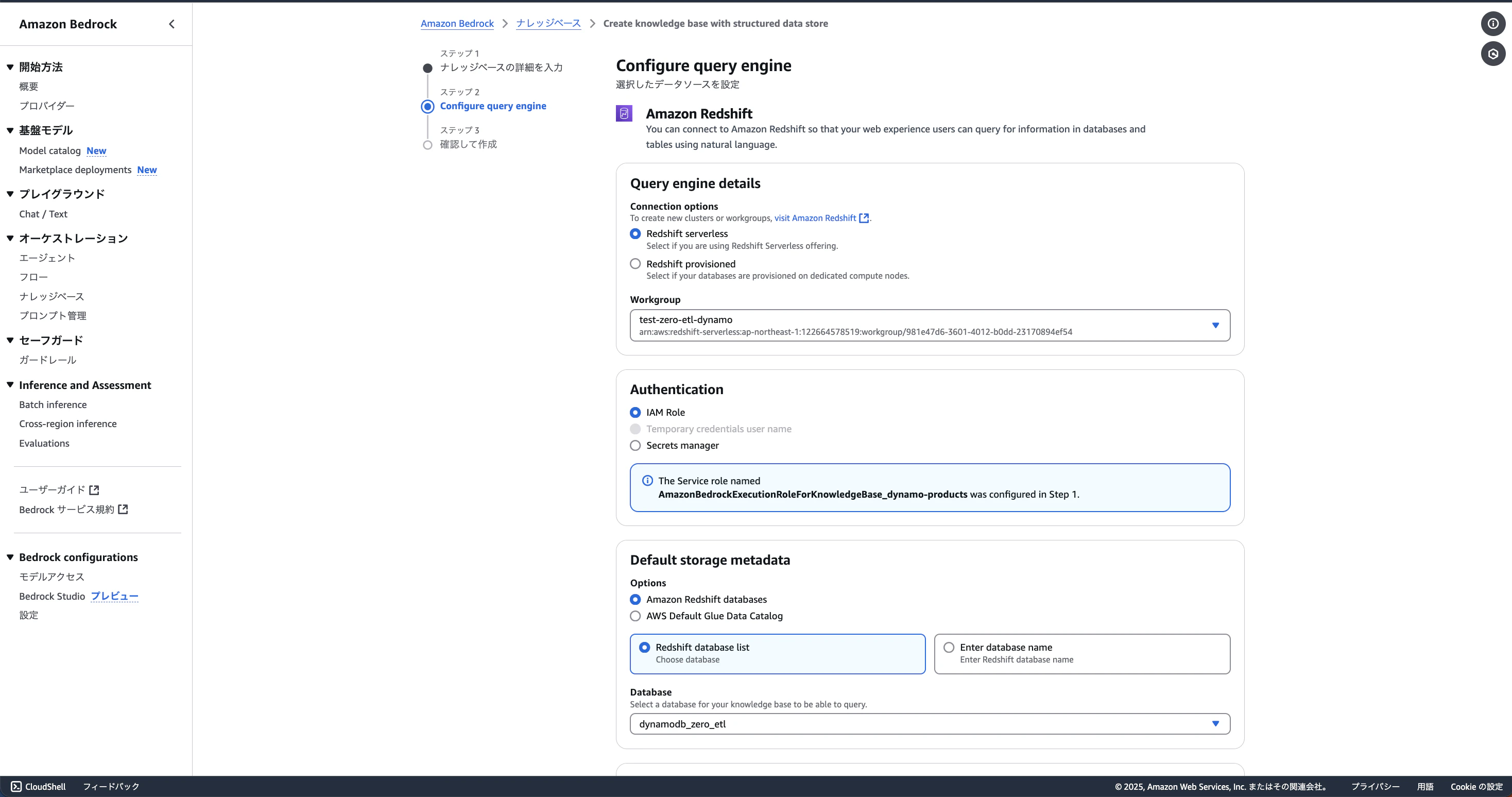
ステップ3:
内容を確認して作成してください。
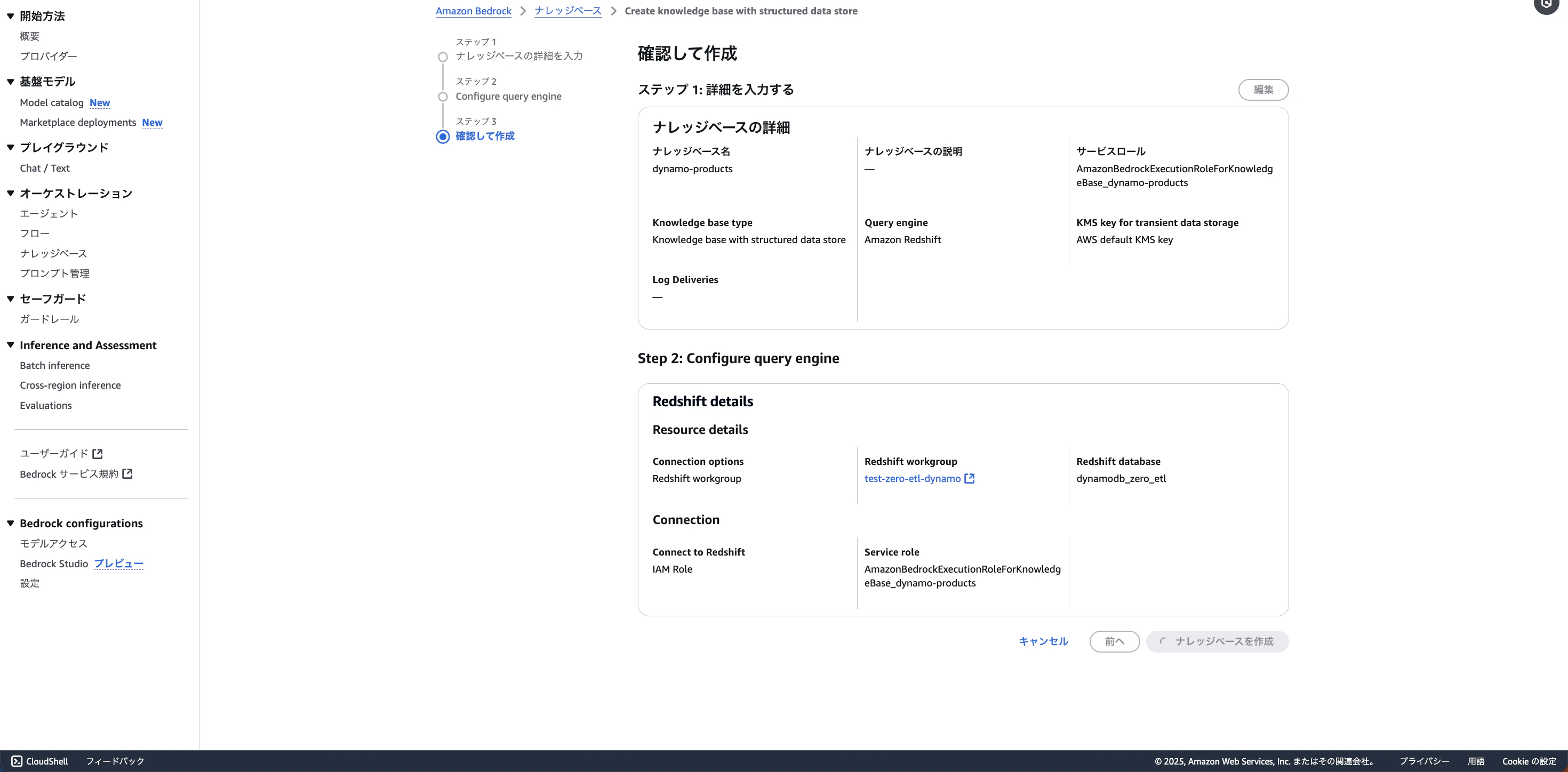
これでdynamoDBとゼロETL統合されたRedshiftをナレッジベースのデータソースにすることができました。
実行
ナレッジベースの同期
ナレッジベースの同期を行い、コンソールから実際にチャットをしてみます。
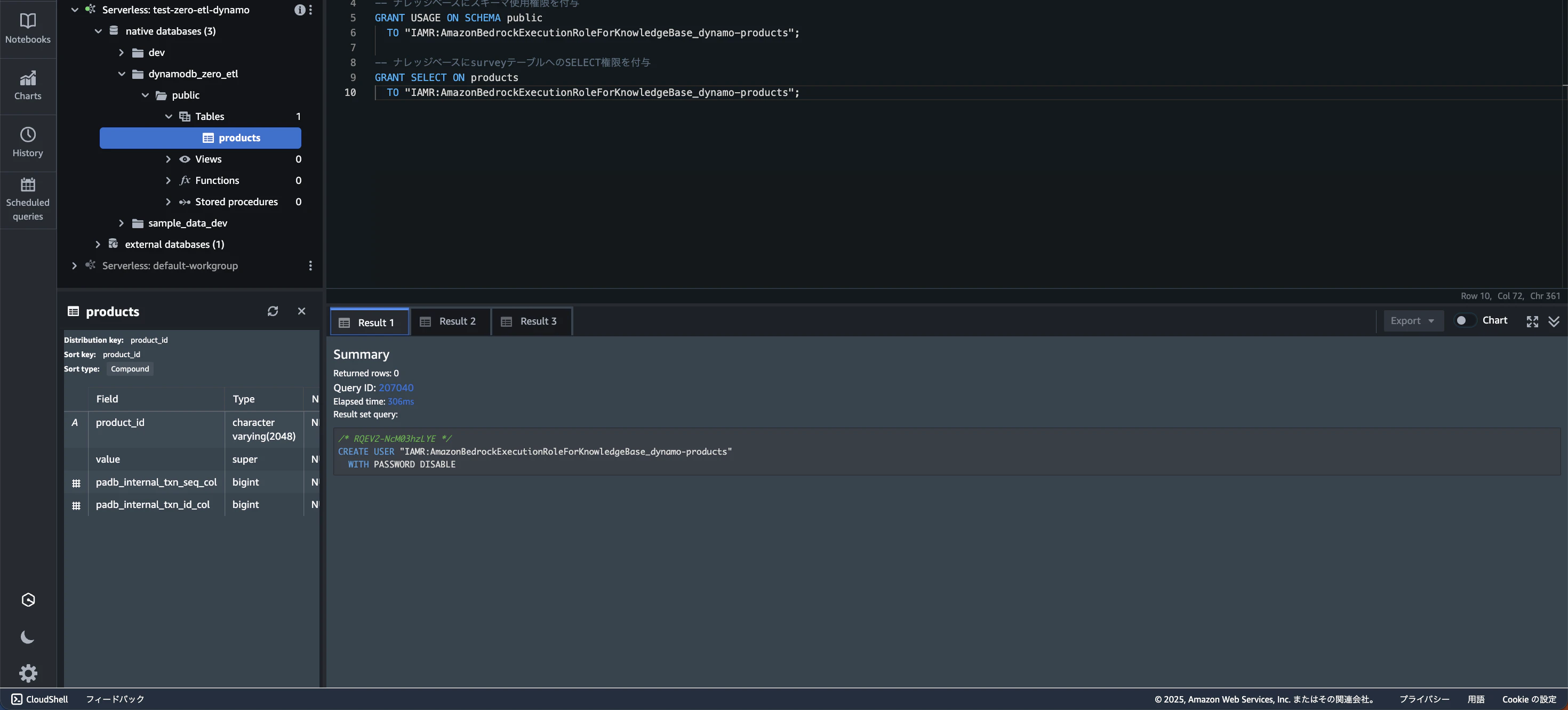
その前に、ナレッジベースがRedshiftを操作できるように権限を付与します。
-- ナレッジベース用のDBユーザーを作成
CREATE USER "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_dynamo-products"
WITH PASSWORD DISABLE;
-- ナレッジベースにスキーマ使用権限を付与
GRANT USAGE ON SCHEMA public
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_dynamo-products";
-- ナレッジベースにsurveyテーブルへのSELECT権限を付与
GRANT SELECT ON products
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_dynamo-products";
上記SQLをRedshiftのエディタで実行してください
ナレッジベースの「Query engine」から「dynamo_zero_etl」を選択して「同期」を開始してください。
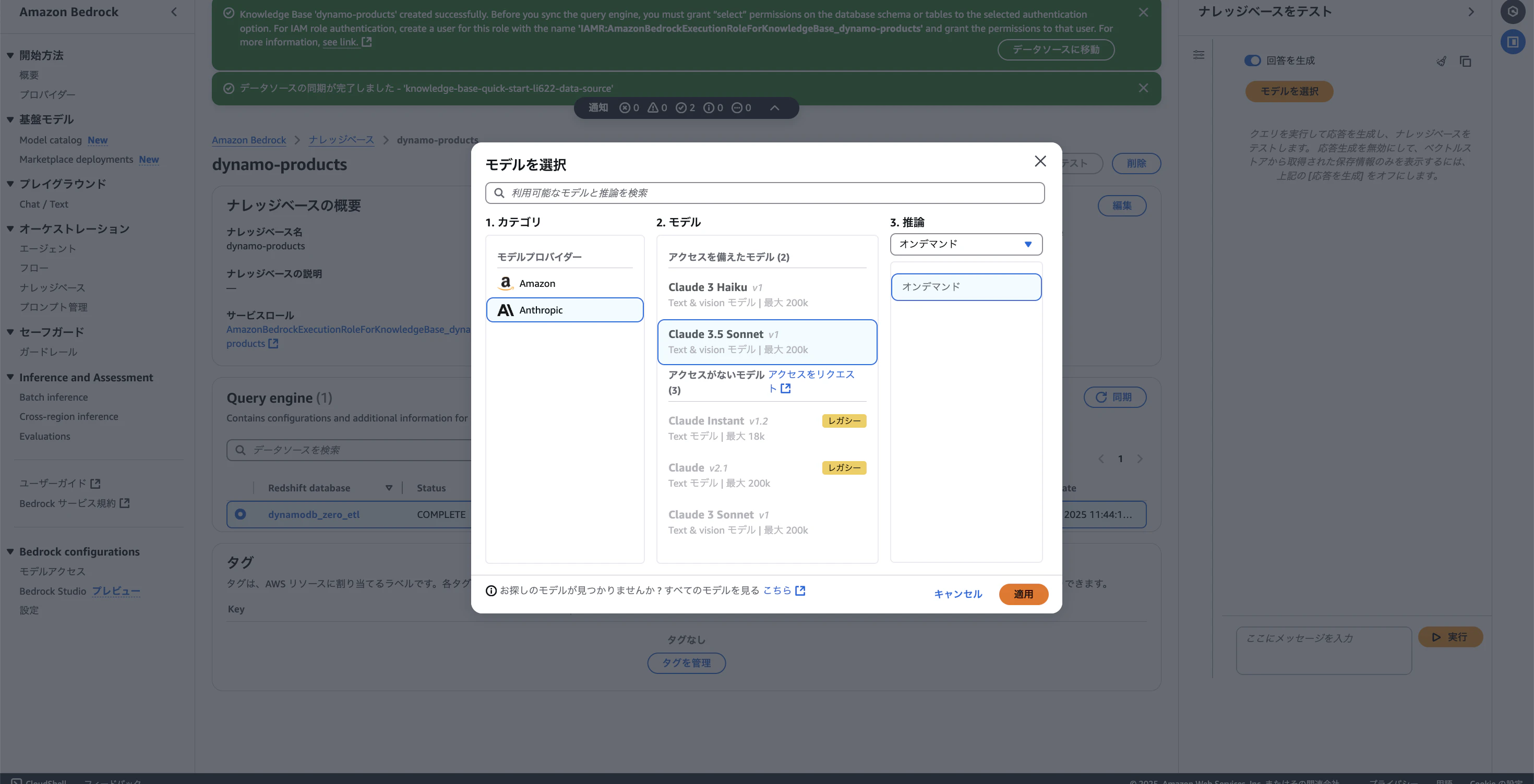
ナレッジベースで使用するモデルを選択し、チャットを開始しましょう。
アクセス権がない場合は適当なモデルを申請してください。
結果
薄々予感はしていましたが、dynamoDBからの取り込みはパーティションキーとソートキー以外の属性に関してはまとめてvalueに入っているので価格や、名前では検索ができないですね…
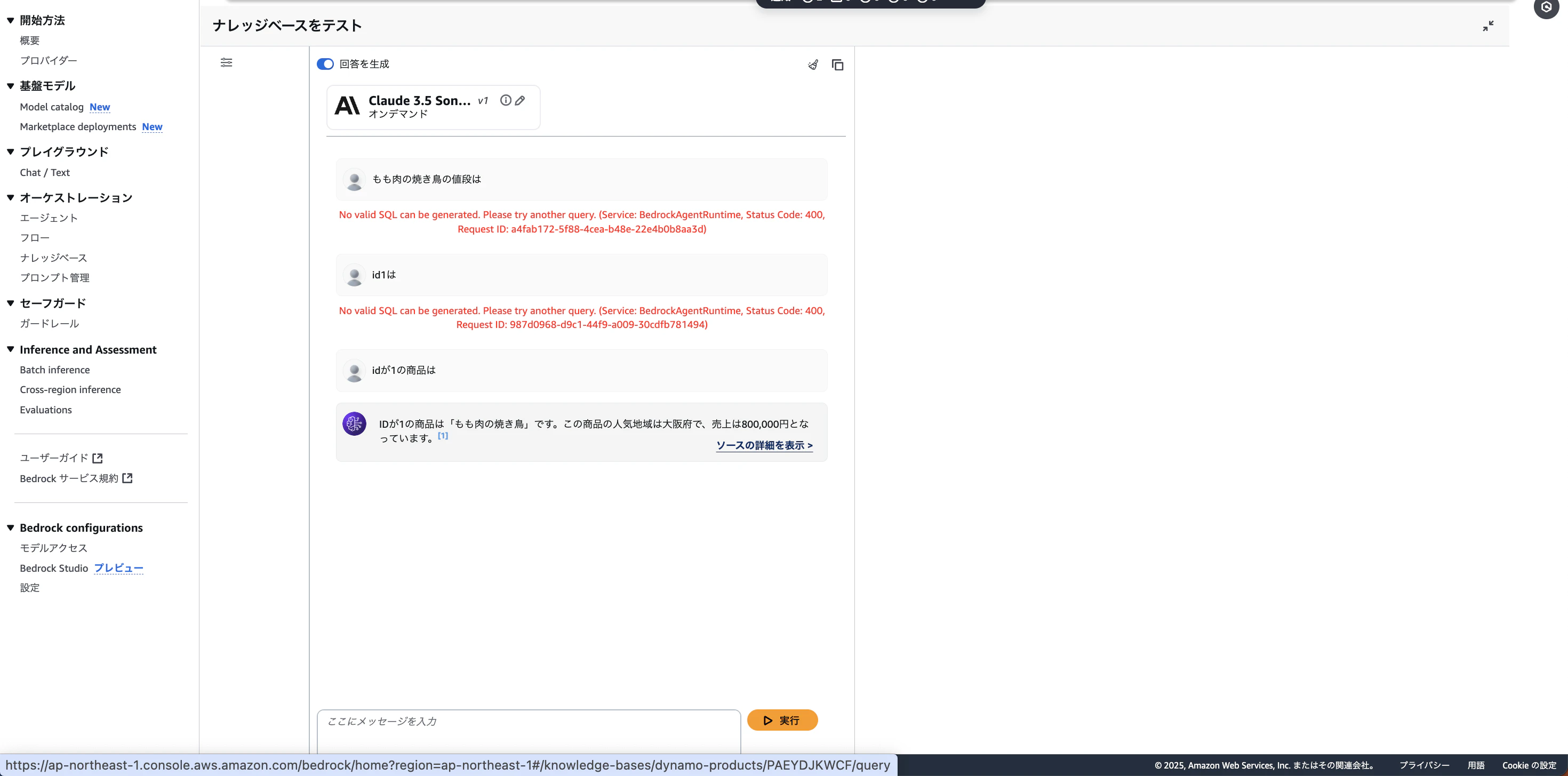
今回は、パーティションキーだけ設定していたのでidでのみの検索が可能でした
一応、下記クエリを行うことができればpopular_regionが大阪府であるデータを抽出することができます。
SELECT *
FROM "dynamodb_zero_etl"."public"."products"
WHERE value.popular_region."S" = '大阪府'
なので、「人気地区が大阪府の商品の名前と値段を教えてください」といった入力で上のクエリが自動生成されるくらいの域になればすごいですね。
まとめ
RedshiftのゼロETL統合を使って、BedrockナレッジベースでDynamoDBを自然言語検索する