博士の友人に聞いたところ、とても勉強になったので共有します。
質問は、accが次の図になっているとき、学習不足なのかどうかです。
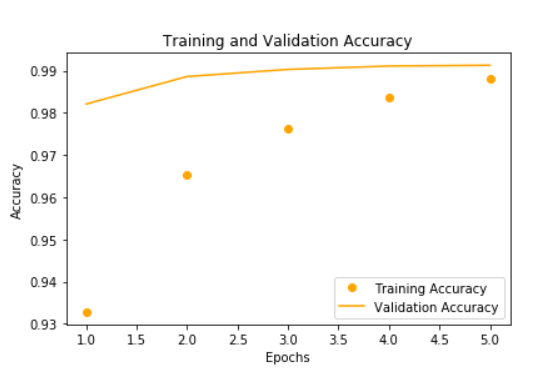
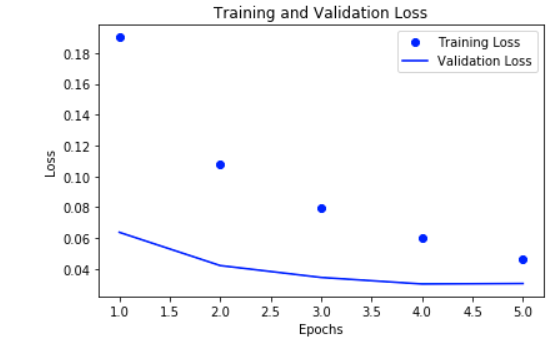
なお、後半で出てくるlossは次の図です。
acc < val_accのときは学習不足の可能性がある
まず、accってのは学習データに関するaccuracyで、val_accってのはvalidationデータに対するaccuracyになるはずです。
一般的には、データセットの全体を10とした時のデータの配分は、訓練用、評価用、テスト用の3つに8:1:1の割合で分けておくはずで、その状態で出てくるaccはいわば「学習用に用意した、見たことあるデータ」での結果で、val_accは「評価用に用意した、見たことないデータ」にあたるところから、もしacc < val_accであったとすると、まだまだ未知のデータに対してaccuracyが上がってないことになるので、もっと学習をしましょうという単に学習が足りないorモデルを見直してもう少し汎化できる初期値やハイパーパラメータを探しましょう、みたいな結論に至ることになります。
なので、個人的には学習が足りてないというだけで片付けるのはちょっと乱暴ですが、一つの可能性としては学習が足りていない、ということがありえるとは思います!
短くいえば、未知のデータを相手にして著しく結果が下がる場合
acc << val_acc
の時はモデルの初期値等々を見直したほうがいいかもしれないですし、
accとval_accの差分がそこまで大きくない場合
acc < val_acc
の時はもう少し学習させて様子を見てみようかなってなるのは気持ちとしては分かりますね。
ただ、そういう時は、val_accだけでなく、val_lossとかもlossと比較したりして、学習ができていないのか、汎化していないのかとかチェックしますね、単一の指標だけでは結論は出さないほうがいいかもしれません。
acc < val_acc かつ loss > val_loss のときは学習不足ではない
val_lossのほうが小さいとなると、それはそれで学習の状態としては割と終わりに近いのかも?
loss自体の大きさも、理論値にどれだけ近くなっているか(もっとも収束した場合のlossは大半の場合0になるはずですが、loss関数の形によっては最小値が違いますね)とか見たりして、
学習の進行状態はチェックしますね。
なんで、val_accとaccを見比べるだけでは、あくまで未知のデータにうまくいっていないと判断する指標なだけだと認識しています。
じゃあどこを調整してうまく学習できるようにするかとか、その辺がちょっと経験則で職人チックなので、難しいですが・・・
あと、kerasだとval_lossの算出時に正則化が入ってなかったりするので、loss > val_loss になるのは学習序盤に現れがちなのはあるかも。