こんにちは!
本日はVantageのブラックボックスを少し開いてそのソフトウェア・アーキテクチャを覗いてみましょう。
別記事の「Vantageのラインナップ」にある通り、VantageにはVantageCoreとVantageCloudがあり、さらにVantageCloudにはソフトウェア・アーキテクチャの大きく異なるVantageCloud EnterpriseとVantageCloud Lakeが存在します。
本日紹介するのはTeradata RDBMSから続く、VantageCoreとVantageCloud Enterpriseのソフトウェア・アーキテクチャです。ただVantageCloud Lakeも奥の奥を覗いてみると本日お話するアーキテクチャの部分が隠れているということもお知らせしておきます。
Vantageを表す言葉
Vantage、昔のTeradata RDBMSがなぜ素早く大量のデータを処理できるのかをいくつかの単語で表すと以下のような感じになります。
・ 並列処理
・ ハッシュ分散
・ ノード間接続ネットワーク BYNET
・ 結合ロジックと オプティマイザー
これらについてお話していきましょう。
並列処理
私があるお客様のところに伺いそこに新しく赴任された担当さんにVantageのことを説明する際にお客様のリーダーさんから必ず「あの話してよ」とリクエストされたお話をします。それがデータを並列で処理することの優位性をとても端的に表せるからです。題して「トランプとあなたと51人のお友達」です。データベース・ソフトウェアには重なったトランプでもカードそれぞれがそのカードであるか判るよう付箋を貼ったり(インデックス)、トランプをマークや数字ごとに置いておく(パーティション)といった技術もありますがそのことは忘れてお読みください。
ここに1組のトランプ、52枚のカードがあります。この52枚のカードをあなたが持っているとします。そして私はあなたにお願いします。
「そのトランプの中から、ハートのクイーンとスペードのキングを抜き出して私にください」
するとあなたはトランプのカードを1枚ずつ確認し、確認したカードがハートのクイーンかまたはスペードのキングの場合だけ他のカードと違う場所に置きます。まじめなあなたは途中で2枚のカードが見つかっても最後の52枚目までカードを確認します。
52枚全てを確認し終えたところであなたは私がリクエストした2枚のカードを私に差し出します。
全てのカードをあなた一人で確認するのはとても大変で時間のかかる作業でした。あなたは考えます。「これをもっと早く楽に行うにはどうしたらいいだろう?」と。
あなたはあなたの友人51人に声を掛けます。そしてあなたと友人51人がトランプのカードを1枚ずつ持つようにします。そして私に「欲しいカードが有ったら52人に呼び掛けてください」といいます。そして私は今度は52人に向かって「ハートのクイーンとスペードのキングを持っている人は私にください」と呼びかけます。
すると52人は一斉に自分が持つカードを確認し、ハートのクイーンを持つ人とスペードのキングを持つ人の二人がカードを差し出しました。
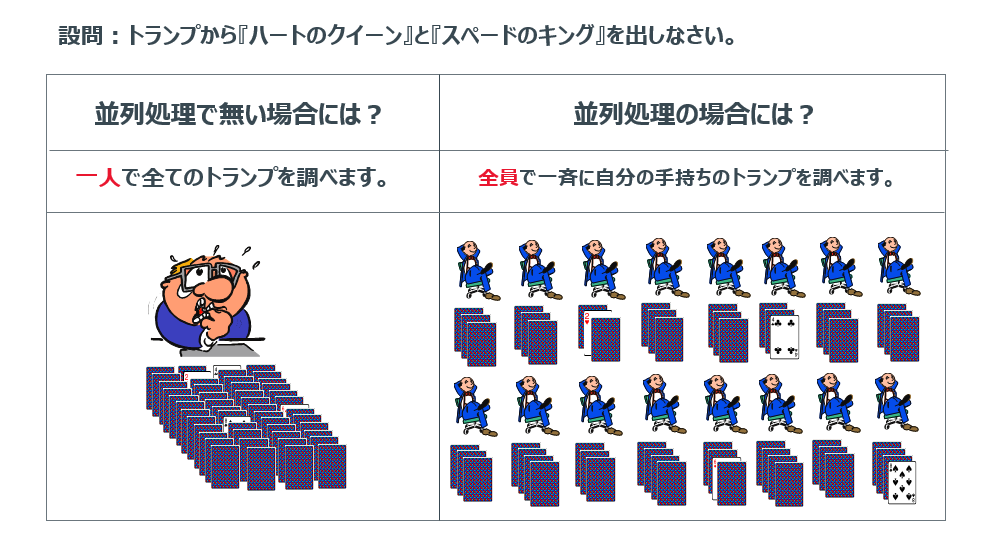
いかがでしょうか?トランプから2枚のカードを抜き出す処理は見事52分の1の時間に短縮されました。これが並列化です。Vantageは40年以上前にこれをデータベースの世界に取り入れるべく開発されました最初のリレーショナル・データベース・ソフトウェアです。
ハッシュ分散
並列処理の効果は理解いただけたかと思います。ですが実際にこれをデータベースの世界では行おうとすると先ほどのお話では触れなった大きな問題にぶつかります。先ほどのお話では「トランプのカードを1枚ずつ持つようにします。」と簡単に書きましたがこれが実は難しいのです。52枚のトランプはラウンドロビンで配っても問題ないですがデータベースの世界ではランダムにカードを配っていたのでは複雑な処理を行うのに困りごとが多いのです。また友達が51人集まらなかったらどうしましょう?例えば集まった友人は9人だったら…
Vantageではカードを配るためにカードのハッシュ値を算出しそれに基づいてカードを配ります。トランプの例ではマークと数字をハッシュ値の算出に使えばすべてのカードで違うハッシュ値が算出されカードを今いる人の数に応じて均等となるように配ることができます。友人が9人で合計10人となっら場合は不幸にも2人は6枚のカードを持つことになりますけれど、それはご愛嬌です。このときVantageではハッシュ値を算出するのに使ったマーク+数字を「プライマリ・インデックス」と呼びます。実はカードを配った私は誰がどのカードを持っているかを示したマップを持っていて、「ハートのクイーンを出して」というお願いをそのカードを持っている特定の人にだけすることができるインデックスの役割も果たしてくれるためです。
実際のデータベースの世界ではテーブルからある程度ハッシュ値のユニーク性が担保されてインデックスとして使われやすい項目でハッシュ値を算出します。52枚よりもっとレコード数が多いデータベースではある程度の均一性が保たれればそれで十分だからです。
BYNET
さて今度は私が「ハートのカードを数字の小さい順にそろえて出してください」とお願いしたとしましょう。それぞれのカードを持っている人が「ハートのカードありました!」と出してくれようとします。でもちょっと待ってください。私は「数字の小さい順に並べて」とお願いしました。わがままな私は無秩序に返されたカードを順番にそろえるなどという面倒なことはしません。じゃあ誰がその仕事をしてくれのでしょうか?
Vantageでそれを行うのはBYNETです。BYNETの本来の仕事は私のお願いを52人の人たちに伝えたり、逆に52人の人からカードを返してもらうのに使ったり時には52人の人たちが相互に相談するための通信回線です。ところがテラデータが特許を持っているこのBYNETという仕組みは単に通信をするだけではなくデータのソートもしてくれたりするのです。
そのため52人の人たちは思い思いのタイミングで(私から見ると無秩序に)カードを返してくれたとしても私の手元には数字の小さな順にカードが並んで届けられるのです。すごくないですか?
もともとこの通信経路はBYNETボードという専用のハードウェアを必要としていましたが現在はこのボードをソフトウェアでエミュレートできるようになり、テラデータが販売するハードウェアだけではなく仮想環境やクラウドの世界でもVantageを提供できるようになっています。
オプティマイザー
実際のリレーショナル・データベースは52枚のカードから欲しいカードを抜き出すといった単純な処理だけを行うわけではありません。むしろそのような処理が行われることの方が稀です。なぜリレーショナルという枕詞がついているのかを考えればわかると思います。複数のテーブルをそのリレーションによって結合し1つのテーブルだけからは得られない情報を簡単に生み出すことができるのがリレーショナル・データベースの最も重要な仕事です。
並列化されたリレーショナル・データベースでこの結合を行うことはとても難しいです。一つのテーブルのデータをたくさんの人が分散して持っているので結合のためにデータを別の人に引き渡したり、全員にコピーを渡したりといったことをする必要があるのです。
40年以上にわたる長い間にわたり開発が継続されてきたVantageは実に様々な結合(やそのほかのデータ処理)を行うための内部ロジックが用意されています。私が投げかけたとても複雑な依頼をどのロジックを組み合わせて処理すれば最速で答えを返すことができるのか?それを検討するのがオプティマイザーです。このオプティマイザーが優れたものでないと並列リレーショナル・データベースはその真価を発揮することはできません。Vantageは長い歴史の中で内部ロジックの開発とともにこのオプティマイザーも磨きをかけて現在に至っているのです。
最後に
いかがでしたでしょうか?
Vantage、なかなか凄いリレーショナル・データベースじゃないですか?でもVantageの中にはもっと様々な凄いことや機能が隠れています。それについては他の記事に譲らせていただきます。
日本テラデータが提供するほかの記事もぜひ読んでみてくださいね!