とても多くのお客様がVantageとAWSのサービスとの統合に関心を持っています。そのようなトピックからここではAmazon GlueとVantageの統合について説明します。
このガイドで説明するアプローチはVantageとAWS Glueとを統合するための多くの可能性のあるアプローチの一つです。 このアプローチは社内で実装されテストされていますが、TeradataまたはAWSのいずれからも、このアプローチに関する正式なサポートはありませんのでご注意ください。
とはいえ、何がうまくいったのか、何がうまくいかなかったのか、どうしたら改善できるのか、などなど、皆さんのフィードバックはとても望ましく、ありがたく思います。
ご意見・ご感想は、コメントとしてお寄せください。
免責事項:本ガイドは、AWSとTeradata製品の両方のドキュメントからの内容を含んでいます。
概要
AWS Glueはサーバーレスで、お客様が分析のためにデータを準備しロードすることを容易にする、完全に管理されたETL(抽出、変換、ロード)サービスを提供します。AWS Glueは、AWS Glue Data Catalogと呼ばれる中央メタデータリポジトリ、PythonまたはSalaコードを自動的に生成するETLエンジン、依存関係の解決、ジョブ監視、再試行を処理する柔軟なスケジューラーで構成されています。今回は、ETLの機能について見ていきます。
AWS Glueは、Amazon RedshiftとAmazon RDS(Amazon Aurora、MariaDB、Microsoft SQL Server、MySEL、Oracle、PostgreSQL)をネイティブでサポートしています。TeradataはAWS Glueでネイティブにサポートされていませんが、カスタムデータベースコネクタを使用してAmazon S3にデータをインポートすることは可能です。次の図は、Teradata VantageとAmazon S3間のデータの流れを示しています。
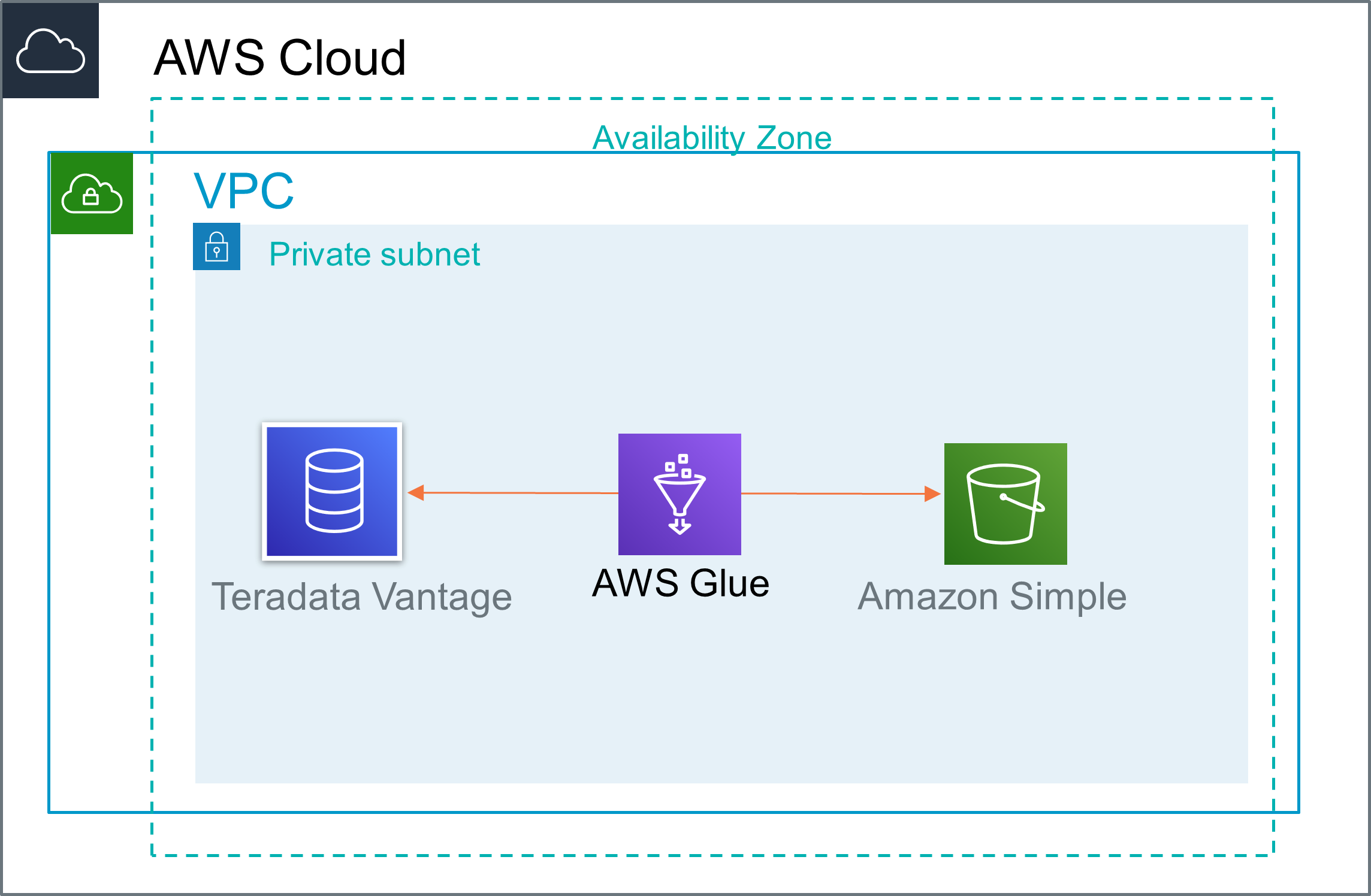
Teradata VantageからAmazon S3へ、Amazon S3からTeradata Vantageへデータを移行する手順について説明します。
前提条件:
・GlueがTeradata Vantageにアクセスすることを許可するセキュリティグループ
・JDBCドライバのS3ロケーション(例: tdjdbc)
・Glueジョブスクリプトを格納するS3の場所(例:tdglue/scripts)
・一時ディレクトリのS3ロケーション(例: tdglue/temp)
・入力データを格納するS3の場所(すなわち、tdglue/input)
・出力データを格納するS3の場所(例:tdglue/output)
・利用可能なVantageインスタンス
S3バケットの作成方法は、こちら をご覧ください。
はじめに
Teradata JDBC ドライバのダウンロード
最新のTeradata JDBC Driverをこちらからダウンロードします。JDBC Driverファイルを入手したら、こちらの手順でjarファイルを解凍し、AWSのS3バケット(例:tdjdbc)にアップロードしてください。
IAMロールの設定
次のステップは、ETLジョブが使用するIAMロールを作成することです。
・AWS Management Consoleから、IAMを検索します。IAMコンソールで、左のナビゲーションペインにある「Roles」を選択します。Create Role」を選択します。信頼できるエンティティのロールタイプは "AWSサービス"、"Glue "を指定します。
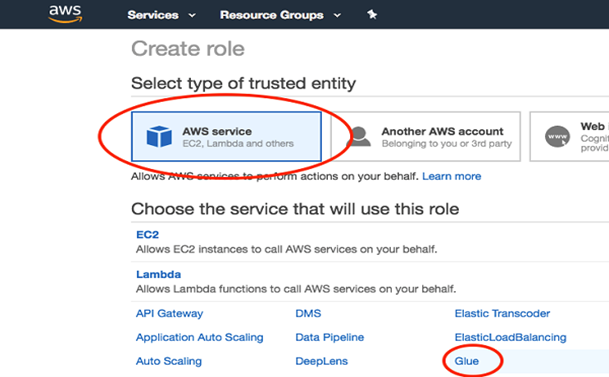
・「次へ」を選択します。パーミッション"
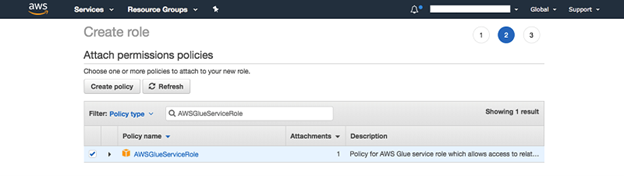
・AWSGlueServiceRole」ポリシーを検索し、選択する
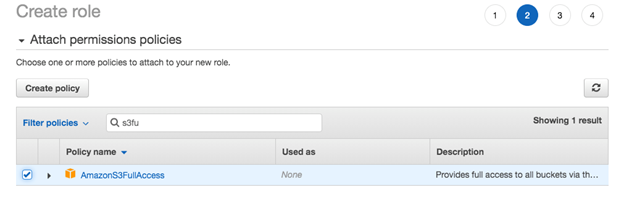
・AmazonS3FullAccess" ポリシーを再度検索し、選択します。
・SecretsManagerReadWrite」ポリシーを検索し、選択します。
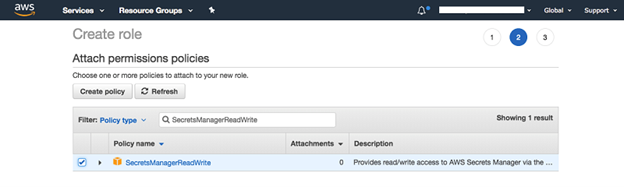
注:このポリシーはオプションです。このポリシーが必要なのは、「シークレットマネージャー」(次のセクションを参照)を使用する場合のみです。
・「次へ」を選択します。タグ "を選択し、タグのキーバリューペアを追加してください。
・Next:Review "を選択します。
・ロールに名前(例:GluePermissions)を付け、選択したポリシーが全て揃っていることを確認します。
・ロールの作成 "を選択します。
Secrets Managerのセットアップ(オプション)
Secrets Manager を使用すると、資格情報を安全に保管することができます。この場合、Secrets Managerを使用してデータベース情報を保存することができます。このステップはオプションです。
シークレットマネージャーをセットアップするには、次のようにします:
・コンソールを開き、"Secrets Manager "を検索します。
・AWS Secrets Managerコンソールで、"Store a new secret "を選択します。
・シークレットタイプの選択で、"その他のタイプのシークレット "を選択する
・Secret key/value "で、以下のパラメータをそれぞれ1行ずつ設定します:
o db_name
o db_username(ユーザー名)
o db_password
o db_url (jdbc:Teradata://<データベース・サーバ名> 例: jdbc:teradata:/10.10.10.10)
o db_table
o driver_name (com.teradata.jdbc.TeraDriver)
o output_bucket: (例: s3://tdglue/output)
・"次へ "を選択
・秘密の名前には、"TD_Vantage_Connection_Info "を使用します。
・"Next "を選択します。
・Disable automatic rotation "チェックボックスは選択したままにしておきます。
・Next "を選択します。
・Store "を選択します。
オーサリング・ジョブ
ETLジョブのオーサリング (VantageからS3へ)
次に、以下の手順でAWS Glueのジョブをオーサリングします:
・AWS Management Consoleで、"AWS Glue "を検索します。
・左側のナビゲーションペインで、"ETL "の下にある "Jobs "を選択します。
・"ジョブの追加 "を選択
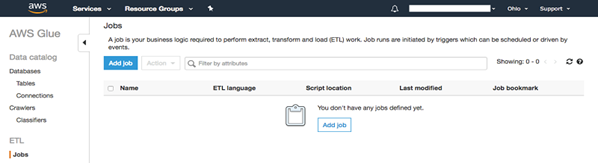
・基本的なジョブプロパティを入力します:
o ジョブに名前を付けます (例: td2s3)。
o 以前に作成したIAMロールを選択します(例:GluePermissions)。
o "Type" と "Glue version" は、"Spark "と最新のSparkとPythonのバージョンを使用します。
o "This job runs "は、"A new script to be authored by you "を選択します。
o "S3 path where the script is stored" と "Temporary directory" には、"Prerequisite" ステップで作成したバケットまたはフォルダ(すなわち tdglue/scripts と tdglue/temp) を選択します。
・Security configuration, script libraries and job parameters "セクションで、"Dependent jars "パスにJDBCドライバの場所(terajdbc4.jar)を選択してください。
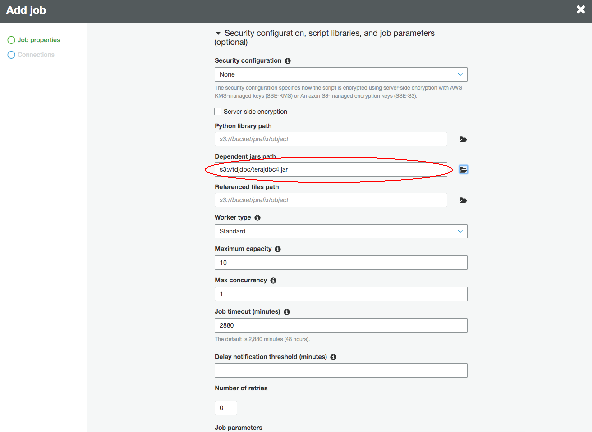
・"Next "を選択します。
・Connectionsページで、"Save job and edit script "を選択します。これでジョブが作成され、スクリプトエディタが開かれます。
エディタで、既存のコードを以下のスクリプトに置き換えます。
スクリプト中のの region_name は、Secrets Manager を使って秘密を作成したリージョンに置き換えてください。
import sys
import boto3
import json
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
#############################################################################
# Secrets Manager #
# Getting DB credentials from Secrets Manager #
# If Secrets Manager's not used, commented out this section #
# and assign values to variables manually in the "Assign Variables" section #
############################################################################
client = boto3.client("secretsmanager", region_name="us-west-2")
get_secret_value_response = client.get_secret_value(
SecretId="TD_Vantage_Connection_Info"
)
secret = get_secret_value_response['SecretString']
secret = json.loads(secret)
db_username = secret.get('db_username')
db_password = secret.get('db_password')
db_url = secret.get('db_url')
table_name = secret.get('db_table')
jdbc_driver_name = secret.get('driver_name')
s3_output = "s3://" + secret.get('output_bucket')
############################################################################
# End of Secrets Manager #
############################################################################
############################################################################
# Assign Variables #
# if not using Secrets Manager, uncomment the following section #
# to assign values to variables manually #
# replace words in <> with real value #
############################################################################
# db_username = "<user>"
# db_password = "<password>"
# db_table = "<table>"
# db_url = "jdbc:teradata://<10.10.10.10>"
# jdbc_driver_name = "com.teradata.jdbc.TeraDriver"
# s3_output = "s3://<tdglue/output>"
############################################################################
# End of Assign Variables #
############################################################################
# Connecting to the source
df = glueContext.read.format("jdbc").option("driver", jdbc_driver_name).option("url", db_url).option("dbtable", table_name).option("user", db_username).option("password", db_password).load()
# Convert to DynamicFrame
dynamic_df = DynamicFrame.fromDF(df, glueContext, "dynamic_df")
# Writing to destination
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_df, connection_type = "s3", connection_options = {"path": s3_output}, format = "json", transformation_ctx = "datasink4")
・保存 "をクリックし、"ジョブの実行 "をクリックします。
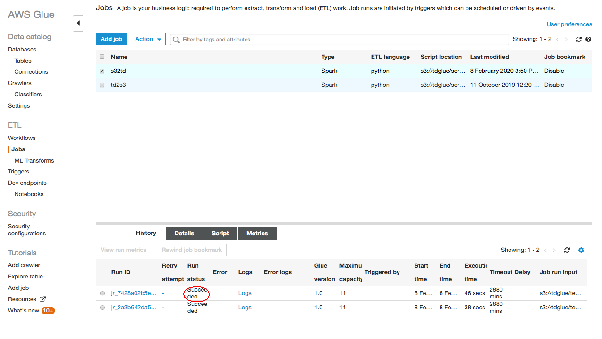
Glueコンソールからジョブの状態を確認することができます。ジョブが完了すると、"Run status "に "Succeeded "と表示されます。
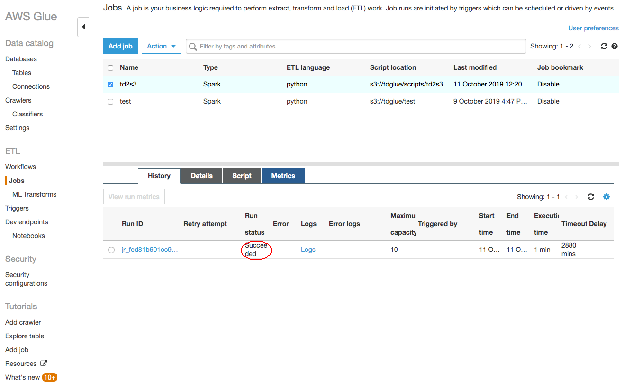
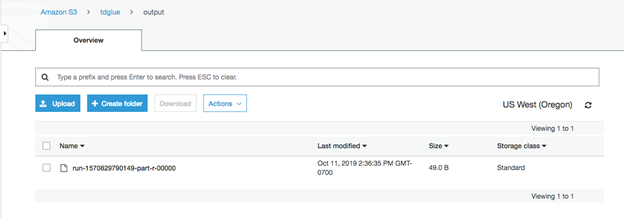
そして、出力されたファイルは、以前設定したS3出力バケットに保持されます。
ETLジョブのオーサリング (S3からVantageへ)
データの準備
このステップでは、Crawlerを使用してGlueテーブルを作成します。
データファイルをS3バケットにアップロードします(例:tdglue/input)。
・AWSマネジメントコンソールで、"AWS Glue "を検索します。
・左側のナビゲーションペインで、"Databases "を選択します。
・"データベースの追加 "をクリックし、名前を付けて、"作成 "をクリックします
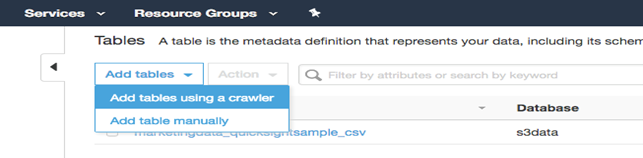
・左側のナビゲーションパネルの "データベース "の下にある "テーブル "をクリックします
・Add tables "の隣にある下向き矢印をクリックし、"Add tables using a crawler "を選択します。
・Add information about your crawler "ウィンドウで、クローラーに名前を付けて、"Next "をクリックします。
・Specify crawler source type "ウィンドウで、"Data stores "を選択し、"Next "をクリックします。
・Add a data store" ウィンドウで、"Choose a data store" に "S3" を使い、データファイルのパスを入れて、"Next" をクリックします。
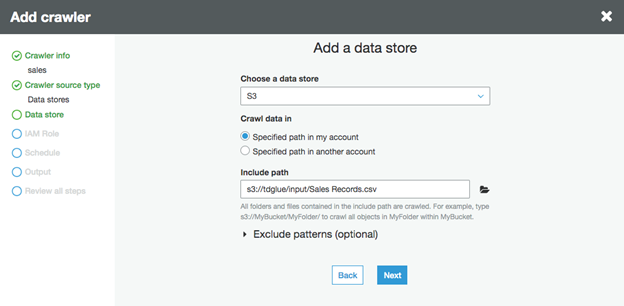
・Add another data store "で "No "を選択し、"Next "をクリックします。
・Choose an IAM role" ウィンドウで、"Choose an existing IAM role, and use the role your created at the "Set up IAM role" step (i e. GluePermissions), click on "next "を選択します。
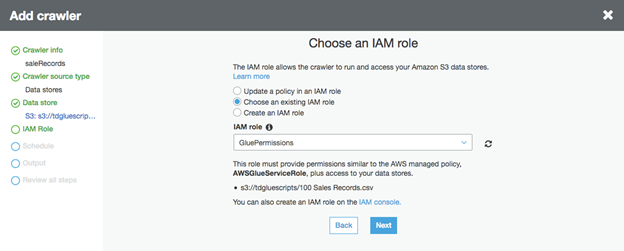
・Create a schedule for this crawler" ウィンドウで、Frequencyとして "Run on demand" を使用し、"Next" をクリックします。
・"Configure the crawler's output "ウィンドウで、先ほど作成したデータベースを選択し、"Next "をクリックします。
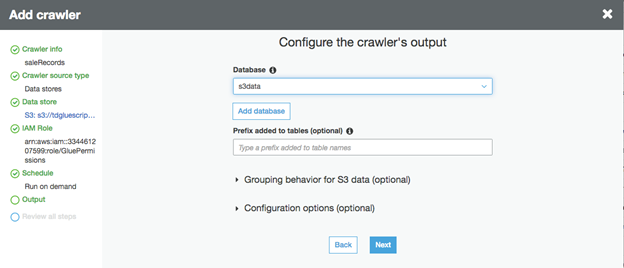
・次のウィンドウで、情報を確認し、"Finish "をクリックします。
・「Crawlers」ウィンドウで、「Run it now」をクリックすると、「Crawler was created to run on demand. 今すぐ実行しますか?質問が表示されない場合は、先ほど作成したクローラーを選択し、"Run crawler "をクリックします。
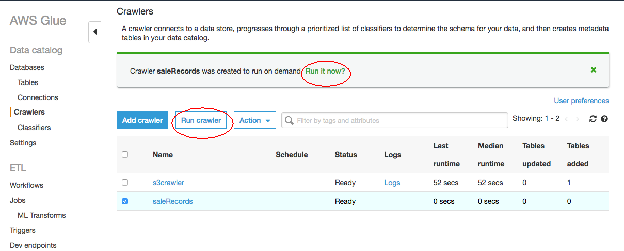
・クローラーが完了すると、ステータスが「Ready」になり、テーブルが作成され、先ほど作成した「Databases」の左パネルから「Tables」を選択すると見ることができるようになる。
ジョブを追加する
・Secrets Managerを使用している場合は、Secrets Managerコンソールに戻り、「TD_Vanatage_Connection_info」をクリックし、「秘密の値」の「秘密の値を取得する」を選択し、「編集」をクリックしてください。s3_databaseとs3_tableという2つのキーを追加します。この2つのキーには、クローラーを使って作成したデータベース名とテーブル名が入ります。
Secrets Managerを使用していない場合は、このステップをスキップしてください。
・左側のナビゲーションペインで、"ETL "の下にある "Jobs "を選択します。
・"ジョブの追加 "を選択します。
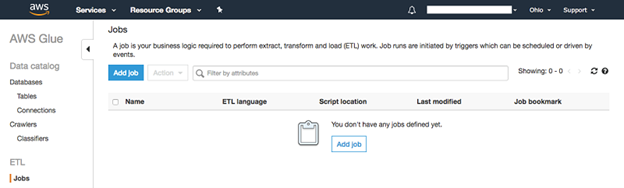
・基本的なジョブプロパティを入力します:
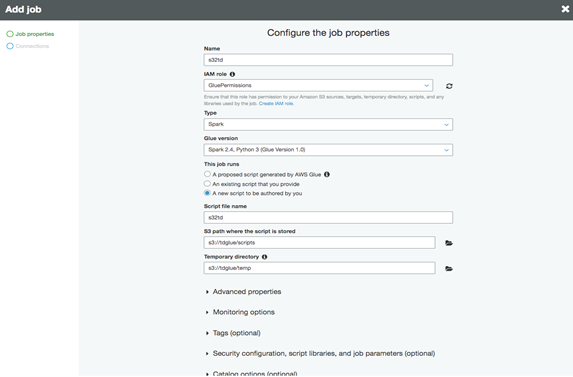
o ジョブに名前を付けます (例: s32td)。
o 以前に作成したIAMロールを選択します(例:GluePermissions)。
o "Type" と "Glue version" は、"Spark "と最新のSparkとPythonのバージョンを使用します。
o "This job runs "は、"A new script to be authored by you "を選択します。
o "S3 path where the script is stored" と "Temporary directory" には、"Prerequisite" ステップで作成したバケットまたはフォルダ(すなわち tdglue/scripts と tdglue/temp) を選択します。
・Security configuration, script libraries and job parameters" セクションを展開し、"Dependent jars" パスにJDBCドライバの場所(terajdbc4.jar)を選択します。
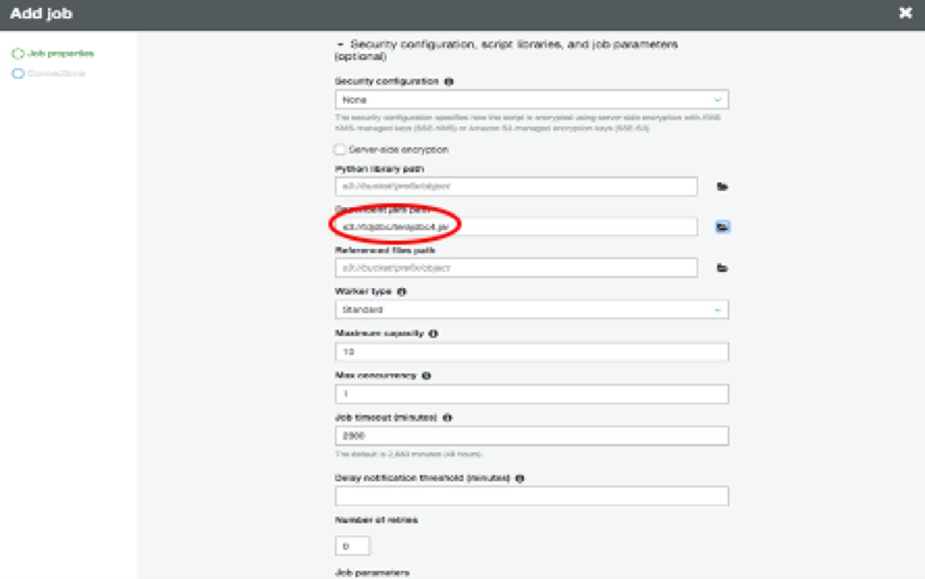
・"Next "を選択します。
・Connectionsページで、"Save job and edit script "を選択します。これでジョブが作成され、スクリプトエディタが開かれます。
エディターで、既存のコードを以下のスクリプトに置き換えてください。
注意:スクリプトのregion_nameは、Secrets Managerを使用して秘密を作成した地域に置き換えてください。**
import sys
import boto3
import json
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
sc = SparkContext()
glueContext = GlueContext(sc)
#############################################################################
# Secrets Manager #
# Getting DB credentials from Secrets Manager #
# If Secrets Manager's not used, commented out this section #
# and assign values to variables manually in the "Assign Variables" section #
#############################################################################
client = boto3.client("secretsmanager", region_name="us-west-2")
get_secret_value_response = client.get_secret_value(
SecretId="TD_Vantage_Connection_Info"
)
secret = get_secret_value_response['SecretString']
secret = json.loads(secret)
db_name = secret.get('db_name')
db_username = secret.get('db_username')
db_password = secret.get('db_password')
db_url = secret.get('db_url')
s3_table = secret.get('s3_table')
s3_database = secret.get('s3_database')
jdbc_driver_name = secret.get('driver_name')
############################################################################
# End of Secrets Manager #
############################################################################
############################################################################
# Assign Variables #
# if not using Secrets Manager, uncomment the following section #
# to assign values to variables manually #
# replace words in <> with real value #
############################################################################
# db_name = "<database name>"
# db_username = "<user>"
# db_password = "<password>"
# db_url = "jdbc:teradata://<10.10.10.10>"
# s3_table = "<crawler table name>"
# s3_database = "<crawler database name>"
# jdbc_driver_name = "com.teradata.jdbc.TeraDriver"
############################################################################
# End of Assign Variables #
############################################################################
datasource = glueContext.create_dynamic_frame.from_catalog(database = s3_database, table_name = s3_table, transformation_ctx = "datasource")
datasink = glueContext.write_dynamic_frame.from_options(frame = datasource, connection_type = "jdbc",
connection_options = {"url": db_url,
"driver": jdbc_driver_name,
"dbtable": s3_table,
"database": db_name,
"user": db_username,
"password": db_password}, transformation_ctx = "datasink")
・保存 "をクリックし、"ジョブの実行 "をクリックします。
Glueコンソールからジョブの状態を確認することができます。ジョブが完了すると、"Run status "に "Succeeded "と表示されます。
おわりに
このようにAmazon Glueを使用して簡単にVantageへデータをだしいれすることが可能です。ぜひご活用ください!