こんにちは!
先日投稿した記事「VantageのデータをAWS SageMakerでの機械学習に使用してみた」でSageMakerで機械学習モデルを作成、推論を行う際にVantageが保有するデータを使用する方法について記述しました。
本日の記事はそこからさらに一歩進んでVantageのBYOM(Bring Your Own Model)機能を使用して
Vantageにモデルを取り込み → Vantageで高速推論
を行う方法を取り上げます。
機械学習モデルの業務利用を行う際にデータ移動に伴う時間的なコストや大容量データのハンドリングで困った経験のある方には福音になるのではと思います。
本記事で使用するデータはhttps://www.kaggle.com/code/georgepothur/4-financial-fraud-detection-xgboost/dataから取得したものです。
またVantage環境にはVAL(Vantage Analytic Library)とBYOM機能(MLDB)のインストールが必要です。それぞれのマニュアルに従ってインストールを行ってください。
Vantage Analytic Libraly ユーザーガイド
Bring Your Own Model ユーザーガイド
はじめに
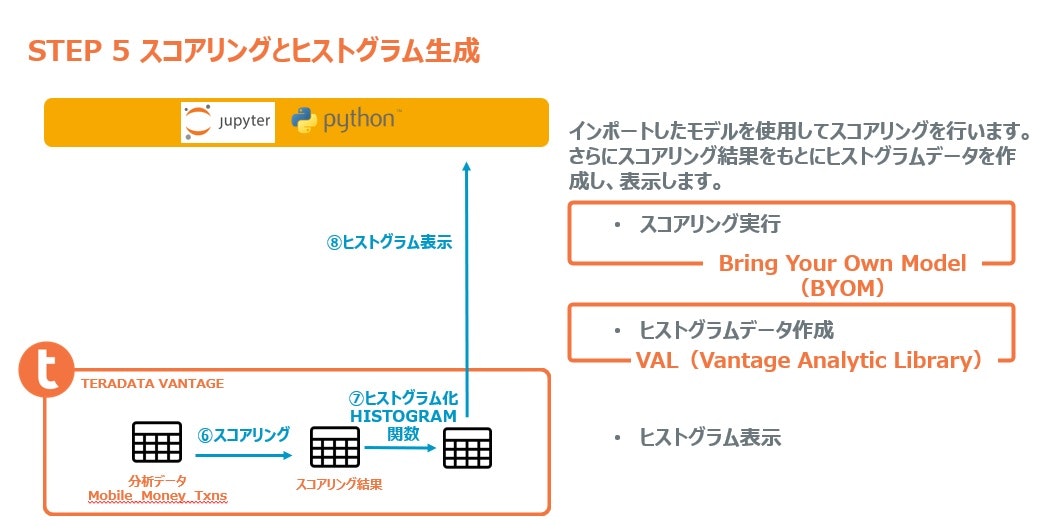
この記事行うことを図示すると下記のようになります。
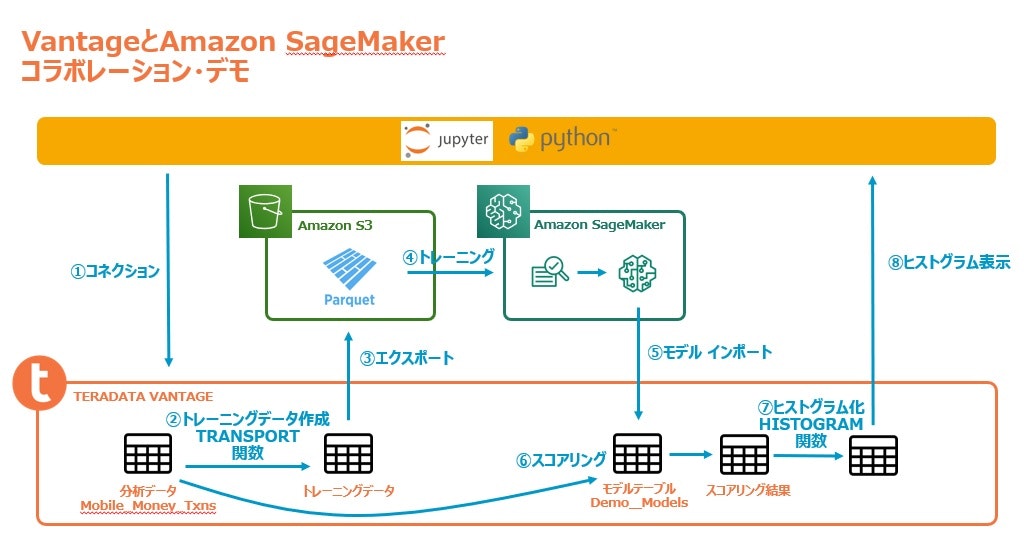
Jupyter環境はSageMakerノートブックインスタンスを使用しています。事前に2つのライブラリ、xgboost、teradatamlをインストールしてください。
事前準備
最初にライブラリのインポートとセッションの作成を行います。
# imports
import pandas as pd
import json
import pickle as pkl
import datetime as dt
import getpass
import boto3
import s3fs
import sagemaker
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
from sagemaker.serializers import CSVSerializer
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
import warnings
import psutil
import time
import tarfile as tf
import matplotlib.pyplot as plt
from matplotlib import cm
import plotly.express as px
import plotly.graph_objects as go
from teradataml import *
from vantage_utils import *
from teradatasqlalchemy.types import *
from teradataml.analytics.valib import *
import teradataml.analytics.Transformations as tdtf
import teradatasql
# TD-specific configurations settings
configure.byom_install_location = 'BYOMインストール先DB名'
configure.val_install_location = 'VALインストール先DB名'
# If Java is not installed, install package jdk4py
# In a terminal (File->New->Terminal), execure the following command:
# pip install jdk4py --user
# and restart the kernel
# and set path to the path to java
# this uses a simple json file with credentials
with open('aws_creds.json') as f:
aws_creds_dict = json.load(f)
aws_bucket = aws_creds_dict['aws_bucket']
aws_key = aws_creds_dict['aws_key']
aws_secret = aws_creds_dict['aws_secret']
iam_role = 'SageMakerで使用するIAMロール' # Sagemaker IAM role
region = 'AWSリージョン'
prefix = 'S3バケットのプリフィックス' #bucket folder prefix
model_path = '作成済み機械学習モデルへのパス'
model_uri = f's3://{aws_bucket}/{model_path}'
boto_sess = boto3.Session(aws_access_key_id = aws_key, aws_secret_access_key = aws_secret, region_name = region)
role = boto_sess.client('iam').get_role(RoleName = iam_role)['Role']['Arn']
container = sagemaker.image_uris.retrieve("xgboost",region,"1.2-1")
sess = sagemaker.Session(boto_session = boto_sess)
モデルが使用するデータの作成
次にVantageにコネクトしてモデルトレーニング用のデータを作成します。
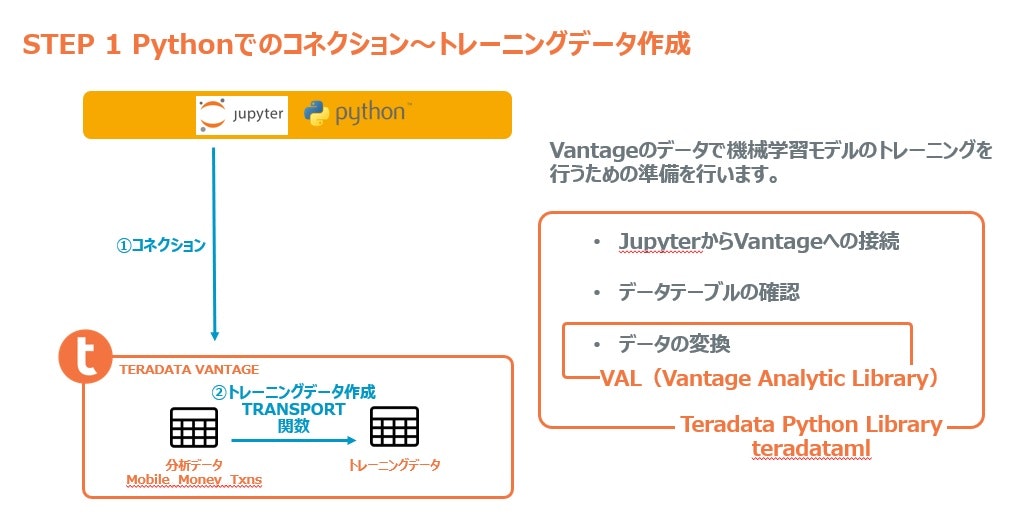
まずVantageに接続します。
# create_context creates a SQLAlchemy connecttion engine to the Vantage system
host = 'VantageのIPアドレス'
username = 'ユーザー名'
password = 'パスワード'
eng = create_context(host = host, username = username, password = password)
Vantageに正しく接続されたかTableを検索して確認してみましょう。
まず今回使用するデータのデータフレームを作成します。
データはSageMakerDemoというデータベースにMobile_Money_Txnsという名称のテーブルとして保存されていることとします。
# this data set is based on a kaggle xgboost example
# available here: https://www.kaggle.com/code/georgepothur/4-financial-fraud-detection-xgboost/data
# teradataml DataFrame method creates "virtual" dataframe which is a pointer to the data
# in the database - can be a table or a query
tdf_orig = DataFrame('"SageMakerDemo"."Mobile_Money_Txns"')
データフレームの中を見てみましょう。

Vantageに正しく接続されていることが確認できましたので、VAL(Vantage Analytic Library)のTransform関数を使用して機械学習モデルのトレーニングや推論に使用するデータを作成します。
ここでは上記で確認したテーブルの中のあるTypeという項目に格納されている値を元にダミー変数を作成します。VantageのTransform関数はこれ一つで様々なパターンのデータ変換を行うことができる関数ですが、その中からダミー変数を作成するOneHotEncoderを使用するわけです。
txn_type_mapping = {'CASH_OUT':'CASH_OUT', 'DEBIT':'DEBIT', 'CASH_IN':'CASH_IN', 'TRANSFER':'TRANSFER', 'PAYMENT':'PAYMENT'}
type_tf = tdtf.OneHotEncoder(values = txn_type_mapping, columns = 'type')
rt = Retain(columns = ['isFraud','amount','oldbalanceOrig', 'newbalanceOrig','oldbalanceDest','newbalanceDest'])
t_output = valib.Transform(data = tdf_orig,
one_hot_encode = [type_tf],
index_columns = 'txn_id',
retain = [rt])
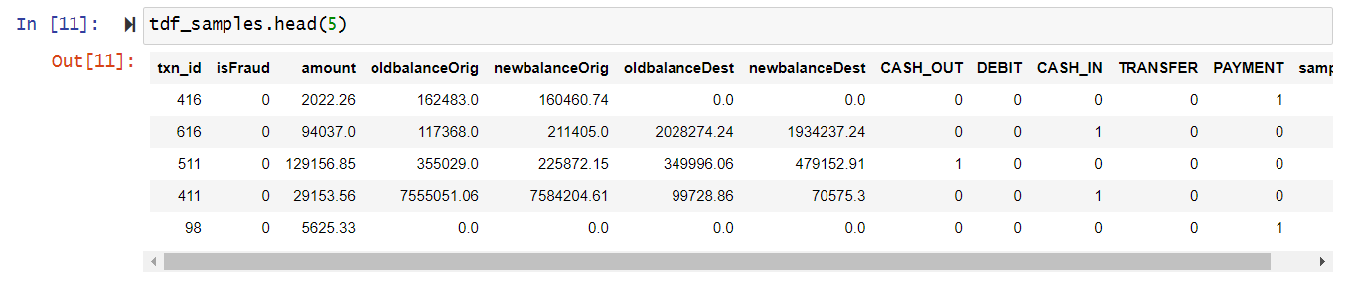
作成したデータの一部を参照してみます。

データが作成できましたのでそのうちの一部を抽出しトレーニングデータを作成します。
テーブルの右側にTypeの値であった「CASH_OUT」、「DEBIT」、「CASH_IN」、「TRANSFER」、「PAYMENT」といった項目が作成されていることがご覧いただけるかと思います。
さらに全件データからトレーニング用のサンプルデータを抽出します。
# built-in SAMPLE function to rapidly define data splits
tdf_samples = t_output.result.sample(frac = [0.001, 0.002, 0.003])
作成したトレーニングデータも一部を参照してみましょう。
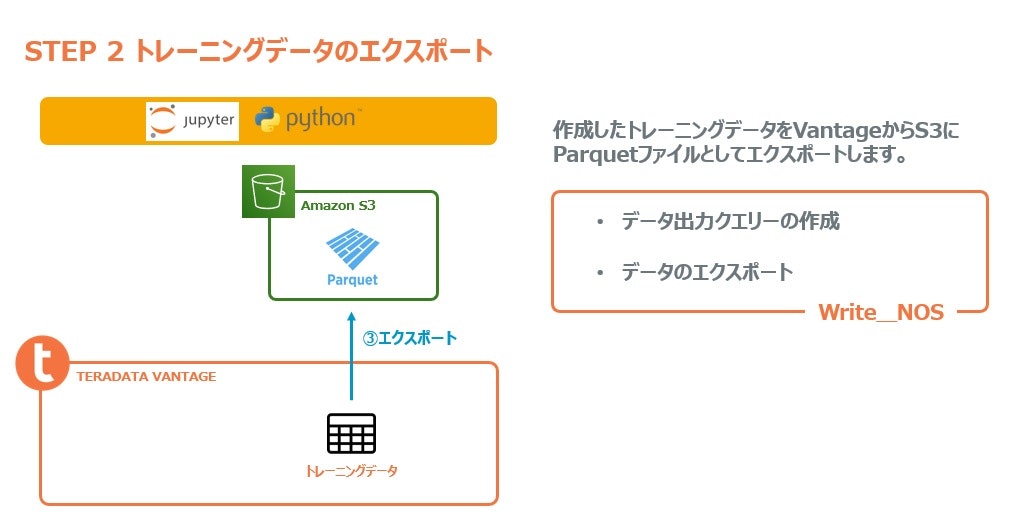
トレーニングデータのS3へのエクスポート
次にVantageのNOS機能を使用してトレーニングデータをVantageから直接S3にParquetファイルとして書き出します。
作成したサンプルデータはデータフレームになっていますから、これをVantage上の恒久テーブルとしていったん書き出します。Vantageではデータフレームを恒久テーブル化する作業はわずか一つの関数で行うことが可能です。
persist the data as a permanent table if desired
copy_to_sql(tdf_samples[tdf_samples['sampleid']>0], table_name = 'txns_input_data', if_exists = 'replace')
この恒久テーブルから以下のようなクエリーでデータをS3に書き出します。
VantageのWrite_NOS機能を使用したクエリーであることが分かります。

このクエリーを実行すると実際にS3にトレーニングデータを格納した複数のParquetファイルが作成されます。
# Created some helper functions to simplify the iterative SQL calls
oput = write_parquet_data(aws_bucket, aws_key, aws_secret, eng)
関数の実行結果として各オブジェクトの情報が格納されたデータフォームが作成されますので内容を確認しみましょう。

モデルのトレーニング
S3に出力されたParquetファイルをトレーニングデータとしてSageMakerでモデルのトレーニングを行いましょう。まずデータのインプット情報を定義します。
# Create training input objects
s3_input_train = TrainingInput(
s3_data="s3://{}/{}/train".format(aws_bucket, prefix), content_type="parquet"
)
s3_input_test = TrainingInput(
s3_data="s3://{}/{}/test".format(aws_bucket, prefix), content_type="parquet"
)
s3_input_validation = TrainingInput(
s3_data="s3://{}/{}/validate/".format(aws_bucket, prefix), content_type="parquet"
)
次に実際にトレーニングを実行します。
# Create estimator and fit the model
xgb = sagemaker.estimator.Estimator(
container,
role,
instance_count = 1,
instance_type="ml.m4.xlarge",
output_path = "s3://{}/{}/output".format(aws_bucket,prefix),
sagemaker_session = sess,
)
xgb.set_hyperparameters(
max_depth = 5,
eta = 0.2,
gamma = 4,
min_child_weight = 6,
subsample = 0.8,
objective="reg:logistic",
num_round=100,
)
xgb.fit({"train": s3_input_train,"validation": s3_input_validation}, )
処理結果が表示されトレーニングが終了します。
モデルのインポート
機械学習モデルのトレーニングが終了しましたので推論を行うためモデルをVantageにインポートします。

最初に既にVantageにインポートされているモデルが存在しないか確認してみましょう。
table_name = 'demo_models'
list_byom(table_name)
既にインポートされたモデルが存在すると下記のような結果が返ります。

既存のモデルとモデルIDが重複しない名称で新しいモデルをインポートします。
# serialize the model with my util function
# that will take the model and serialize it to PMML format
model_id = 'sagemaker_xgb3'
table_name = 'demo_models'
model_file = serialize_aws_model(aws_bucket, model_path, 'model.tar.gz', boto_sess)
model_metadata = {'Description': 'Sagemaker XGBoost model',
'ModelSavedDate': dt.date.today(),
'ModelSavedTime': dt.datetime.now().time()}
model_datatypes = {'Description':VARCHAR(100),
'ModelSavedDate':DATE(),
'ModelSavedTime':TIME()}
res = save_byom(model_id = model_id,
model_file = model_file,
table_name = table_name,
additional_columns = model_metadata,
additional_columns_types = model_datatypes)
次のような結果が表示されてモデルがVantageにインポートされました。
モデルによる推論(スコアリング)の実行
インポートしたモデルとVantageのデータを使用して推論を行ってみます。
まず最初に推論に使用するモデルを指定します。
model_id = 'sagemaker_xgb3'
table_name = 'demo_models'
model_tdf = retrieve_byom(model_id, table_name)
table_nameはモデルのインポート先のテーブルの名称を表しています。
次に実際に推論を行ってみましょう。
# Run the PMMLPredict function in Vantage
# use my exsting transformed data
# 6 MM records
result = PMMLPredict(
modeldata = model_tdf,
newdata = t_output.result,
accumulate = ['isFraud','amount']
)
tdf_results = result.result.assign(pred_float = result.result['prediction'].cast(FLOAT))
newdataが推論に使用するデータを示しています。「モデルが使用するデータの作成」の章で作成したデータを指定しています。
tdf_resultが推論結果の格納されたデータフレームになります。次はこのデータフレームを使用してVALのヒストグラム関数を実行してみます。
# use a Vantage Analytics Library histogram function on the 6MM records
td_hist = valib.Histogram(data = tdf_results[tdf_results['pred_float'] > 0.05] , columns = ['pred_float'], bins = 10)
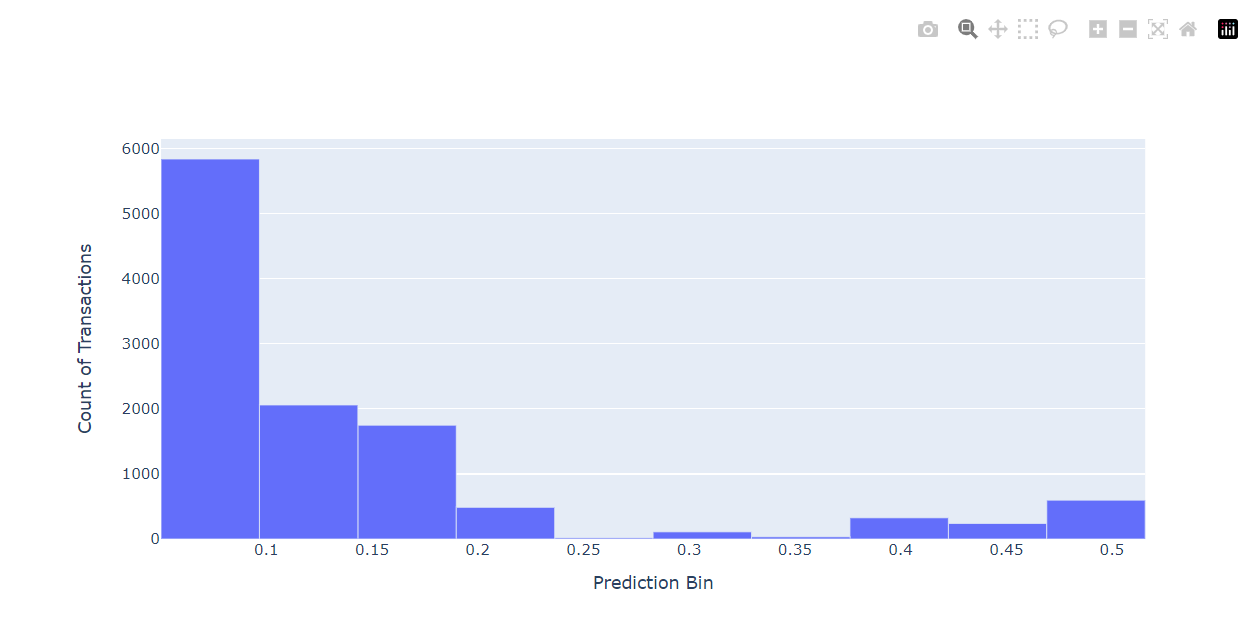
さらにこのヒストグラムデータをPlotlyライブラリを使ってビジュアルに表示することも可能です。
# calling the result property will execute the function
# to_pandas method will retrieve the data - 50 rows - to the client
data = td_hist.result.to_pandas().reset_index()
# use the Plotly visualization library to plot the histogram
data["xcenter"] = (data.xend + data.xbeg) / 2
data["xwidth"] = data.xend - data.xbeg
fig = go.Figure(data=[go.Bar(x=data.xcenter, y=data.xcnt, width=data.xwidth)])
fig.update_layout(height=500)
fig.update_yaxes(title="Count of Transactions")
fig.update_xaxes(title="Prediction Bin")
fig.update_layout(showlegend=False)
fig.show()
この処理では最初にPlotlyライブラリ実行のためにデータフレームの変換を行っています。実はここまでの処理で使用してきたデータフレームはVantageが提供するteradatamlライブラリで定義されるデータフレームでした。
このデータフレームはVantageの内部では一時テーブルというデータベース・テーブルとして保持されています。このためこのデータフレームに対する処理はすべてデータベースの中で行われていました。サーバーサイドで処理を行い、サーバーとクライアントの間での無駄なデータの移動を抑制するためです。そのためこれまでの処理を非常に高速に行うことができます。
またデータフレームの変換はto_pandasという関数一つで行うことができます。この一つの関数を実行するだけでデータフレームが持つデータをクライアント(今回の場合はSageMakerノートブックインスタンス)に移動しPandasデータフレームを構築しています。今回のように処理結果として得られたデータだけをクライアントに移動することでそのサイズも極小化し時間的なコストを大幅に縮小することができます。
まとめ
いかがでしたでしょうか?今回の記事では単にBYOMを使用しSageMakerモデルの推論を行うだけにとどまらず、VAL(Vantage Analytic Library)関数やNOS機能を使用してみました。またこれらの処理を全てPythonで記述し実行もしています。
このようにSQLに記述することなく実行できるデータベース・サーバーでの高速処理をぜひ体感してみてくださいね!