とても多くのお客様がVantageとAWSのサービスとの統合に関心を持っています。そのようなトピックからここではAmazon Kinesis FirehoseとVantageの統合について説明します。
このガイドで説明するアプローチは、Kinesis Firehoseと統合するための多くの可能性のあるアプローチの一つであり、そのままの形で提供されるものです。 このアプローチは社内で実装されテストされていますが、TeradataまたはAWSのいずれからも、このアプローチに関する正式なサポートはありませんのでご注意ください。
とはいえ、何がうまくいったのか、何がうまくいかなかったのか、どうしたら改善できるのか、などなど、皆さんのフィードバックはとても望ましく、ありがたく思います。
ご意見・ご感想は、コメントとしてお寄せください。
免責事項:本ガイドは、AWSとTeradata製品の両方のドキュメントからの内容を含んでいます。
概要
AWS Kinesisは、リアルタイムのストリーミングデータを簡単に収集、処理、分析することができるストリーミングサービスです。
Kinesisストリーミングデータプラットフォームは、Kinesis Data Streams、Kinesis Data Firehose、Kinesis Data Analytics、Kinesis Video Streamsを提供しています。Kinesis Data Streamsは手動で管理され、最大7日間データをストリームに保存でき、その間にデータの変換を行うことができます。Kinesis Firehoseはフルマネージドで、データを収集し、S3、Redshift、Splunk、Elasticsearchに格納する。Kinesis Video streamsはライブビデオのストリーミングに使用され、Kinesis Data Analyticsは標準SQLを使用してストリーミングデータを処理、分析することができます。
Teradata Vantage Native Object Store(NOS)は、標準SQLとODBC、JDBC、.NET、Python、Rネイティブドライバーなどのアプリケーションインターフェイスを使って、AWS S3などの外部オブジェクトストアにあるデータを簡単に探索できるようにします。NOSを使用するためにオブジェクトストレージ側に特別なインフラは必要ありません。アクセスを許可されたバケットを指すようにNOSテーブル定義を作成するだけで、AWS S3バケットにあるデータを探索することができます。
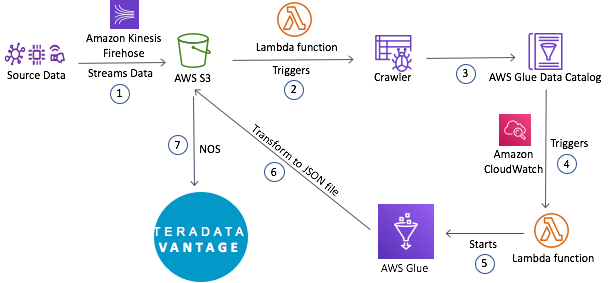
このガイドではソースからAWS Kinesis firehose経由でAWS S3にデータを流し、AWS Glue ETLジョブでJSON形式に変換し、Teradata NOSを使用してS3からデータにアクセスする手順について説明します。Lambda関数とCloudWatchのイベントルールも作成し、全体の処理を自動化します。
前提条件
AWS Kinesis、Lambda、CloudWatchサービス、Teradata Vantageに精通していることが期待されます。
以下のアカウント、システムが必要です:
・AWSアカウント
・SQLE 17.0+を搭載したTeradata Vantageインスタンス
・ストリーミングデータを格納するためのS3バケット
・JSONファイルを格納するS3バケット
・Glue Crawler、ETL、Lambdaの各サービスを許可するIAMロール
・AccessKeyId と SecretAccessKey
はじめに
Amazon S3バケットの作成
S3バケットは**こちら** の手順で作成します。この例ではストリーミングデータを格納するバケット(=ptctstoutput)と変換後のJSONファイルを格納するバケット(=awspilbucket)の2つが必要です。
IAMロールの作成
AWSのサービスでは、サービスが他のサービスのリソースに代理でアクセスできるようにするために、ロールを使用する必要があります。この例では、Kinesis Firehose用のロール、Glue用のロール、Lambda用のロールの3つが必要です。
Kinesis Firehoseのロールは、その場で作成されます。以下の手順で、GlueとLambdaのサービス用のロールを作成します。
AWS Glueのロール:
1.AWS IAM Console にアクセスし左側のナビゲーションペインで「Roles」を選択します。Create Role」を選択します。信頼されたエンティティのロールタイプは「AWSサービス」、「Glue」を指定します。

2.「次へ」を選択します。
3. "AWSGlueServiceRole "ポリシーを検索し選択します。
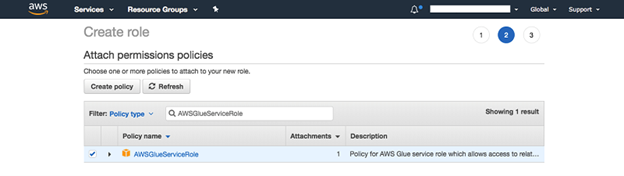
4."AmazonS3FullAccess" ポリシーを再度検索し選択します。

5.「次へ」を選択します。タグ」を選択し、タグのキーバリューペアがあれば追加します。
6.Next:Review "を選択します。
7.ロールに名前(例:GluePermissions)を付け選択したポリシーがすべて揃っていることを確認します。
8."ロールの作成"を選択します。
注:ポリシーを直接追加する権限がない場合は**インラインポリシー** として追加してください。
ラムダのロール:
Lambda用のポリシーをインラインポリシーとして追加していきます。
1.AWS Management ConsoleからIAMを検索します。IAMコンソールで、左のナビゲーションペインにある「Roles」を選択します。「Create Role」を選択します。信頼できるエンティティのロールタイプは「AWSサービス」、「Lambda」を指定します。

2.「次へ」を選択します。
3.「次へ」を選択します。タグ "を選択し、タグのキーバリューのペアを追加します。
4."Next:Review"を選択します。
5.ロールに名前(例:lambdaAccess)を付け、「ロールの作成」を選択します。
6."ロールの作成"を選択します。
7.作成したロール(例:lambdaAccess)をクリックし、"Add inline policy"をクリックします。

8.「JSON」タブをクリックし、以下のポリシーを貼り付けます。「ポリシーの確認」をクリックします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*",
"glue:*",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeRouteTables",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVpcAttribute",
"iam:ListRolePolicies",
"iam:GetRole",
"iam:GetRolePolicy",
"cloudwatch:PutMetricData",
"logs:*"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:CreateBucket"
],
"Resource": [
"arn:aws:s3:::aws-glue-*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::aws-glue-*/*",
"arn:aws:s3:::*/*aws-glue-*/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::crawler-public*",
"arn:aws:s3:::aws-glue-*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:/aws-glue/*"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateTags",
"ec2:DeleteTags"
],
"Condition": {
"ForAllValues:StringEquals": {
"aws:TagKeys": [
"aws-glue-service-resource"
]
}
},
"Resource": [
"arn:aws:ec2:*:*:network-interface/*",
"arn:aws:ec2:*:*:security-group/*",
"arn:aws:ec2:*:*:instance/*"
]
}
]
}

- ポリシーに名前を付け (例: lambdaFunctionPolicy)、"Create policy" を選択します。

Firehose配信ストリームの作成
Kinesis Console に移動し"Create delivery stream "をクリックします。
ステップ1. 名前とソース
Delivery stream name"に名前を指定します(例:firehoseStream)。"Choose a source"で、"Direct PUT or other sources"を選択し、それ以外はデフォルトのまま、"Next"をクリックします。

ステップ2. レコードを加工する
データ変換はLambdaではなくGlueを使用します。「データ変換」「レコードフォーマット変換」ともに「無効」のまま「次へ」をクリックします。

ステップ3.送信先を選ぶ
Kinesis firehoseからのストリーミングデータはS3、Redshift、Elasticsearch Service、Splunkに送信することができます。ここでは送信先として「Amazon S3」を使用します。
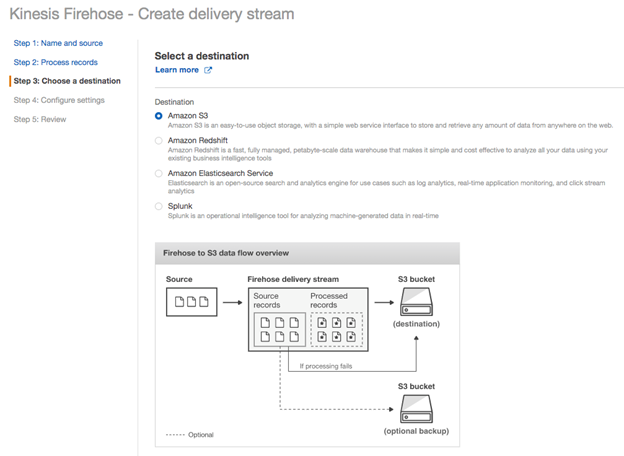
ストリーミングデータ用に**以前作成したバケット名(例:ptctsoutput)** を入れ、「S3 prefix」「S3 error prefix」は空欄にします。Next "をクリックします。

ステップ4.設定を行う
IAMロール以外の構成設定はデフォルト値のままにしておきます。Permissions"までスクロールし、"Create new or choose"をクリックします。

「IAM Role」については「Create new IAM Role」を選択し、「Allow」をクリックします。
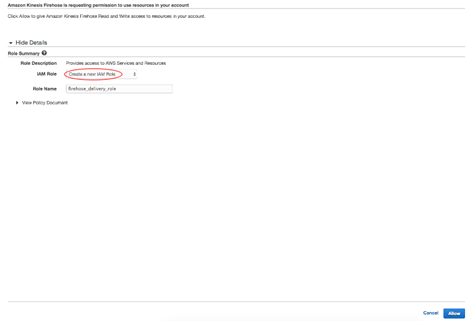
Configure settings"のページに戻り"Next"をクリックします。
ステップ5. レビュー
設定内容を確認し「配信ストリームの作成」をクリックします。
ステップ6. デモデータでテスト
Amazonから提供されたテスト用データでFirehoseストリームをテストしてみます。Firehoseストリームをクリックし、"Test with demo data "をクリックします。

「デモデータの送信を開始」をクリックします。約10秒後、「デモデータ送信停止」をクリックします。

結果はUTCで「YYYY/MM/DD/HH」の接頭辞(フォルダ)を付けて先に指定したS3バケットに入れられます。バケットのバッファリング設定により新しいオブジェクトがバケットに表示されるまでに数分かかる場合があります。すぐに結果が表示されない場合は数分待って画面を更新してください。

Glue ETL変換ジョブの作成
Teradata Native Object Store(NOS)はJSON、CSV、PARQUETのファイルを読み込むことができます。AWS GlueのETLジョブを作成してストリーミングデータをこれら3つのファイルのいずれかに変換することにします。
この例では、ストリーミングデータを生のJSON形式に変換しています。
1.カタログデータ
ETLジョブをオーサリングする際にデータソース、ターゲット、およびその他の情報の詳細を提供します。データソースを表すテーブルはすでにデータカタログで定義されている必要があります。以下の手順では、Kinesis firehoseデータ用のテーブルをカタログで定義します。
1.Glue Console に移動します。
2.左側のナビゲーションペインで"Databases"を選択します。
3.新しいデータベースを追加するか既存のデータベースを使用します。新しいデータベースを追加するには「Add database」を選択しポップアップウィンドウで名前を付けて、「Create」をクリックします(例:s3data)。
4.左側のナビゲーションペインで"Databases"の下にある "tables"を選択します。
5."Add tables"を選択しドロップダウンリストから "Add tables using a crawler"を選択する。

6.クローラー名を「streamData」とし「次へ」をクリックします。クローラー名はメモしておいてください。この名前は、後述 のLambdaコード(lambda_function.py)やCloudWatchのルールで使用されます。
7."Specify crawler source type "ウィンドウで "Data stores "を選択し、"Next "をクリックします。
8.「データストアの追加」画面で「データストアの選択」を「S3」、「クロールデータの場所」を「私のアカウント内の指定されたパス」にチェックし、「パスを含める」のフォルダアイコン(例:s3://ptctstoutput)をクリックして購読データが格納されているバケットを探します。Next "をクリックします。
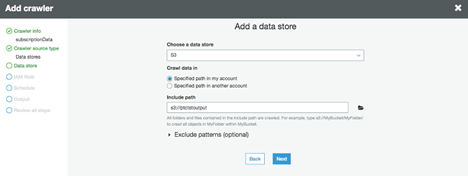
9."Add another data store "で "No "を選択し"Next "をクリックします。
10.IAMロール」ウィンドウで「既存のIAMロールを選択」し、「IAMロール」のドロップダウンリストから、先ほど 作成したロール(例:GluePermissions)を選択します。Next "をクリックします。

11.クローラーの頻度は「オンデマンドで実行」です。"Next "をクリックします。
12.Configure the crawler's output」ウィンドウで「Database」に前のステップで作成したデータベース(例:s3data)を選択します。Prefix "は空欄のまま"Next "をクリックします。

13.クローラー情報を確認し「完了」をクリックします。
クローラーが作成されたら上部の緑色の「今すぐ実行しますか」をクリックするか、クローラーの横にあるチェックボックスにチェックを入れて「クローラーを実行」をクリックします。

クローラー実行後、先ほど設定したデータベースにストリーミングデータが格納されているバケット名のテーブル(例:ptctsoutput)が作成されます。このテーブルがETLジョブのソースとなります。
2.ETLジョブの追加
AWS Glueコンソール で左パネルから「ETL」の「Jobs」をクリックし、「Add job」をクリックします。
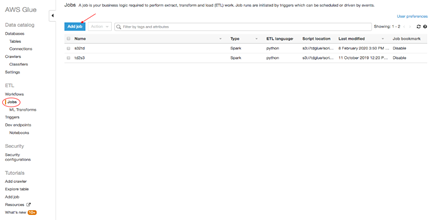
3.ジョブプロパティ
ジョブの「名前」(例:conver2JSON)を決め、先ほどの手順 で作成した「IAMロール」(例:GluePermissions)を選択します。This job runs "に "AWS Glue generated by proposed script "が選ばれていることを確認します。その他はデフォルトのまま"Next "をクリックします。

4.データソース
カタログデータ ステップで作成したテーブルをデータソースとして選び(例:ptctstoutput)、"Next "をクリックします。

5.トランスフォームの種類を選択する
変換の種類はデフォルトの「スキーマの変更」を使用します。"Next "をクリックします。
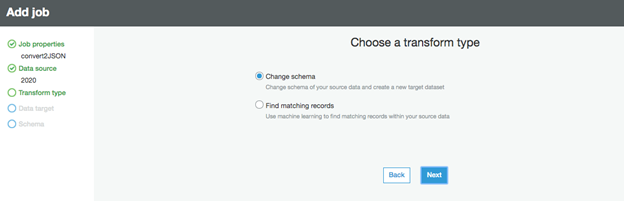
6.データターゲット
Choose a data targetは「Create tables in your data target」を使用します。"データストア "は「Amazon S3」、"フォーマット "は「JSON」、圧縮は無し、"ターゲットパス "は**先ほど作成した** JSONファイル用のバケットを選び(例:awspilbucket)、Next "をクリックします。
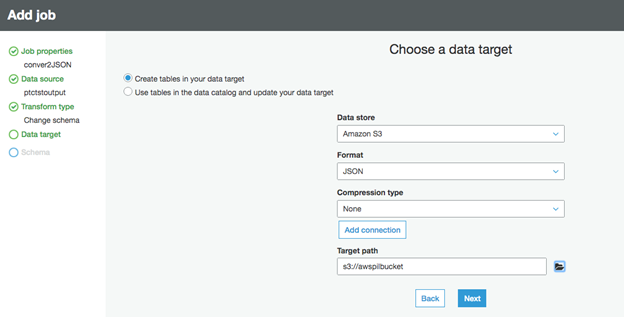
"Map the source columns to target columns"ウィンドウで必要に応じてターゲットファイルを修正します。この例では何も変更しません。Save job and edit script "をクリックしコードを保存します。
NOSを使ったストリーミングデータへのアクセス
1.外部テーブルの作成
外部テーブルによりVantage SQL Engine内で外部データを簡単に参照することができ構造化されたリレーショナル形式でデータを利用できるようになります。
Teradata Vantageシステムに認証情報を使用してログインします。S3バケットアクセス用のアクセスキーでAUTHORIZATIONオブジェクトを作成します。認可オブジェクトはAWS S3データにアクセスするために誰が外部テーブルの使用を許可されるかの制御を確立することでセキュリティを強化します。「USER "はAWSアカウントのAccessKeyIdで、"PASSWORD "はSecretAccessKeyです。
CREATE AUTHORIZATION DefAuth_S3
AS DEFINER TRUSTED
USER 'A*****************' /* AccessKeyId */
PASSWORD '********'; /* SecretAccessKey */
S3上のJSONファイルに対して、以下のコマンドで外部テーブルを作成します。
CREATE MULTISET FOREIGN TABLE streamingData,
EXTERNAL SECURITY DEFINER TRUSTED DefAuth_S3
(
Location VARCHAR(2048) CHARACTER SET UNICODE CASESPECIFIC,
Payload JSON(8388096) INLINE LENGTH 32000 CHARACTER SET UNICODE
)
USING
(
LOCATION ('/S3/s3.amazonaws.com/awspilbucket’)
)
;
最低限、外部テーブルの定義にはテーブル名とオブジェクトストアのデータを指すLocation句(黄色でハイライトされています)を含める必要があります。ロケーションは、Amazonでは "バケット "になります。
ファイル名の末尾に標準的な拡張子(.json, .csv, .parquet)がない場合、データファイルの種類を示すために、LocationとPayload列の定義も必要です。
外部テーブルは常にNo Primary Index (NoPI)テーブルとして定義されることを覚えておいて下さい。
外部テーブルを作成したら外部テーブルで "Select "をしてS3ファイルの内容を照会することができます。
SELECT * FROM streamingData;
SELECT payload.* FROM streamingData;
外部テーブルには2つのカラムしか含まれていません。LocationとPayloadです。Location はオブジェクトストアシステムにおけるアドレスです。データ自体はpayloadカラムで表現され外部テーブルの各レコード内のpayload値は1つのJOSNオブジェクトとその全ての名前-値ペアを表現します。
"SELECT * FROM streamingData; "の出力例です。

SELECT payload.* FROM streamingData; " の出力例です。
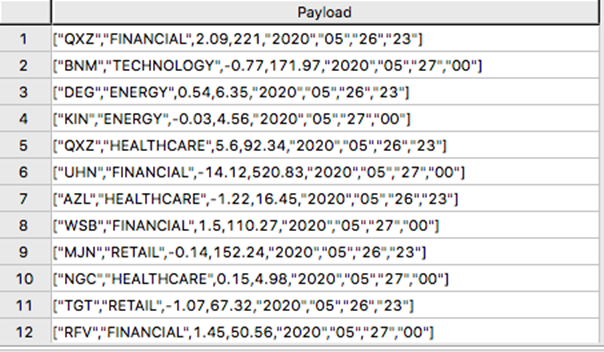
2.ビューの作成
ビューはペイロード属性に関連する名前を単純化し、オブジェクトストアのデータに対して実行可能なSQLを簡単にコーディングできるようにし、外部テーブルのLocation参照を隠して通常の列と同じように見えるようにすることができます。
REPLACE VIEW streamingDataView as (
SELECT CAST(payload.partition_0 as CHAR(4)) theYear,
CAST(payload.partition_1 as CHAR(2)) theMonth,
CAST(payload.partition_2 as CHAR(2)) theDay,
CAST(payload.partition_3 as CHAR(2)) theHour,
CAST(payload.ticker_symbol as VARCHAR(3)) ticker_symbol,
CAST(payload.sector as VARCHAR(20)) sector,
CAST(payload.change as DECIMAL(6,2)) change,
CAST(payload.price as DECIMAL(6,2)) price
FROM streamingData
);
SELECT * FROM streamingDataView;
Sample output from “SELECT * FROM streamingDataView”.
SELECT文の出力結果は以下のようになります。

Lambda関数、Trigger、CloudWatch Eventの作成
Lambda関数を2つ、トリガーを1つ、CloudWatch Eventを1つ作成することにします。
・S3トリガーを使ってAWS Glue Crawlerを起動するLambdaファンクション
・Glue ETLジョブを実行するためのLambdaファンクション
・Glue ETLジョブを開始するためのCloudWatchイベントルール
S3トリガーはストリーミングデータバケットに新しいデータがロードされるとすぐに、Glue Crawlerを開始するためにラムダ関数をキックオフします。クローラーがストリーミングデータの分類を終えるとCloudWatchのイベントルールが2番目のラムダ関数を開始しGlue ETL変換ジョブを実行します。
ステップ1. クローラーLambda関数を作成する
Lambda Console に移動し"Create function"をクリックします。
「関数の作成」ページで
・"Author from scratch "を使用する
・ラムダ関数に名前をつけます (例: s3TriggerCrawler)
・Runtime "言語として最新バージョンのpythonを選択します
・Choose or create an execution role」を展開し「Use an existing role」を選択します。ドロップダウンリストから**以前**に作成したロールを選択します(例:lambdaAccess)
・"関数の作成"をクリックします

ステップ2. 関数にコードを追加する
関数コード "セクションに移動し"lambda_function "ウィンドウに以下のコードをコピー&ペーストしてください。
import json
from botocore.exceptions import ClientError
import boto3
client = boto3.client('glue')
glue = boto3.client(service_name='glue')
def lambda_handler(event, context):
# TODO implement
print("Starting Glue Crawler")
class CrawlerException(Exception):
pass
try:
response = client.start_crawler(Name = 'streamData')
except client.exceptions.CrawlerRunningException as c:
raise CrawlerException('Crawler In Progress!')
print('Crawler in progress')
クローラー名(streamData)はお使いのクローラー名に置き換えてください。保存」をクリックします。このコードでGlueのクローラーが起動します。

ステップ3. S3トリガーを追加する
関数を作成したらS3トリガーを追加します。
Designer "セクションの "Add trigger "をクリックします。

・"Trigger configuration"のドロップダウンリストから "S3 "を選びます
・サブスクライブしたデータセットを保存するために、先に作成したバケットを選択します(例:ptctstoutput)
・Event type "に "All object create events"を使用します
・フィルタリング条件を絞り込みたい場合は、プレフィックスまたはサフィックスを選択します。この例では空白のままにしておきます
・Enable trigger "がチェックされていることを確認します
・"Add"をクリックします
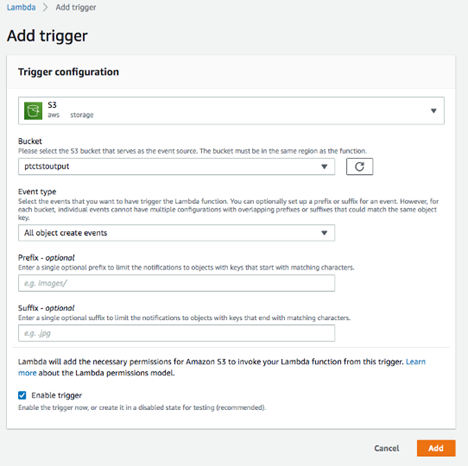
S3トリガーが作成されます。

ステップ4. ETL Lambda関数を作成する
1.Lambdaのコンソール を開きます。
2.「関数の作成」を選択します。
3."Author from scratch "を選択し、"Create Function "をクリックする。4.以下のオプションを設定します。
・Nameには関数の名前を入力します(例:callETL)。
・Runtimeには最新のPythonのオプションを選択します。
・Choose or create an execution role "を展開し"Use an existing role "を選択します。先ほど作成したLambda用のロールを選びます(例:lambdaAccess)。
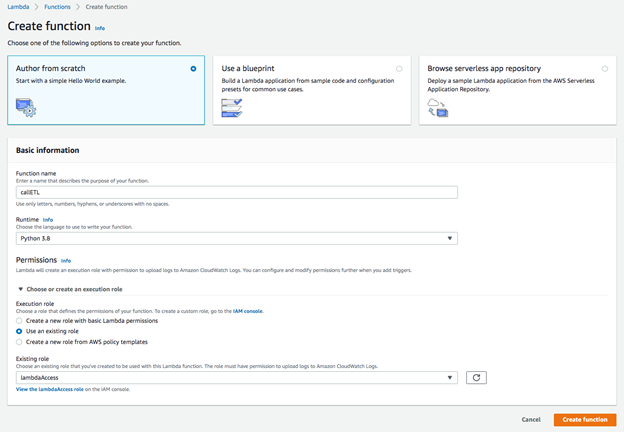
4.「関数の作成」をボタンをクリックします。
5.Function codeセクションに以下のコードを貼り付けます。conver2JSON "は、AWS GlueのETLジョブ名に置き換えてください。
# Set up logging
import json
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Import Boto 3 for AWS Glue
import boto3
client = boto3.client('glue')
# Variables for the job:
glueJobName = "conver2JSON"
# Define Lambda function
def lambda_handler(event, context):
logger.info('## TRIGGERED BY EVENT: ')
logger.info(event)
response = client.start_job_run(JobName = glueJobName)
logger.info('## STARTED GLUE JOB: ' + glueJobName)
logger.info('## GLUE JOB RUN ID: ' + response['JobRunId'])
return response
7.コードを保存します。
ステップ5. CloudWatch Eventsルールを作成する
1.CloudWatchのコンソール を開く。
2.ナビゲーションペインで"Events "の下にある "Rules "を選択し、Create ruleを選択する。
3.Event SourceセクションでEvent Patternを選択し、ドロップダウンリストからBuild event pattern to match...の下にあるCustom event patternを選択する。

4.Build custom event patternボックスで既存のコードを以下のコードに置き換えます。streamData "は必ずAWS Glueのクローラー名に置き換えてください。
{
"detail-type": [
"Glue Crawler State Change"
],
"source": [
"aws.glue"
],
"detail": {
"crawlerName": [
"streamData"
],
"state": [
"Succeeded"
]
}
}
5.ページ右側の「ターゲット」セクションで「ターゲットの追加」を選択します。
6.ドロップダウンリストでまだ選択されていない場合は、Lambda functionを選択します。
7.Function ドロップダウンリストでLambda 関数の名前 (例: callETL) を選択します。
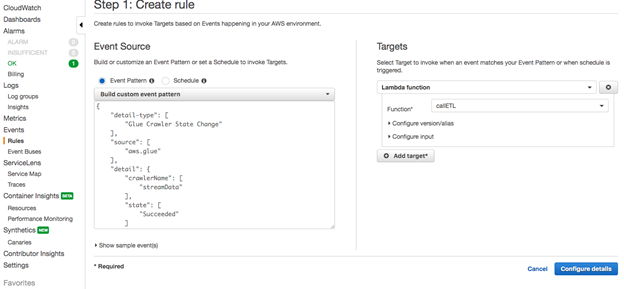
8.ページの右下隅で、Configure details(詳細設定)を選択します。
9.CloudWatch EventsルールのNameとDescriptionを入力し、"Create rule "を選択します。
実行
上記の手順でストリーミングデータをNOSが消費するためのJSON形式のファイルに変換するプロセスが自動化されます。このプロセスが確立されるとS3にストリーミングされた更なるデータを直接Vantageで分析することができます。
今回もAWSから提供されたデモデータを使ってS3にさらにデータをストリームしてみます。Kinesis Firehoseのコンソール に戻り、作成したFirehoseストリーム(例:firehoseStream)をクリックし「Test with demo data」をクリックします。
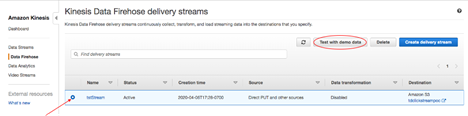
「デモデータの送信を開始」をクリックし、10秒後に「デモデータの送信を停止」をクリックします。全てのジョブが終了するまで数分待ちます。ジョブが終了したことを確認する一つの方法は、Glueコンソール でETLジョブをクリックし、履歴タブでジョブの実行状況を確認することです。ステータスが "Succeeded "になっていれば、ジョブは終了しています。

Vantageにログオンすると新しいデータが表示されます。
SELECT * FROM streamingData;
SELECT * FROM streamingDataView;
このデータには以前のセッションから流れ込んできたデータも含めバケットにあるすべてのものが含まれています。このデータを今日の実行分だけを抽出するためにselect文にwhere句を追加します。
SELECT * FROM streamingDataView
WHERE theMonth = '05' and theDay = '27';
おわりに
このようにAmazon kinesisでストリーミングされたデータも簡単にVantageにロードすることが可能です。ぜひご活用ください!