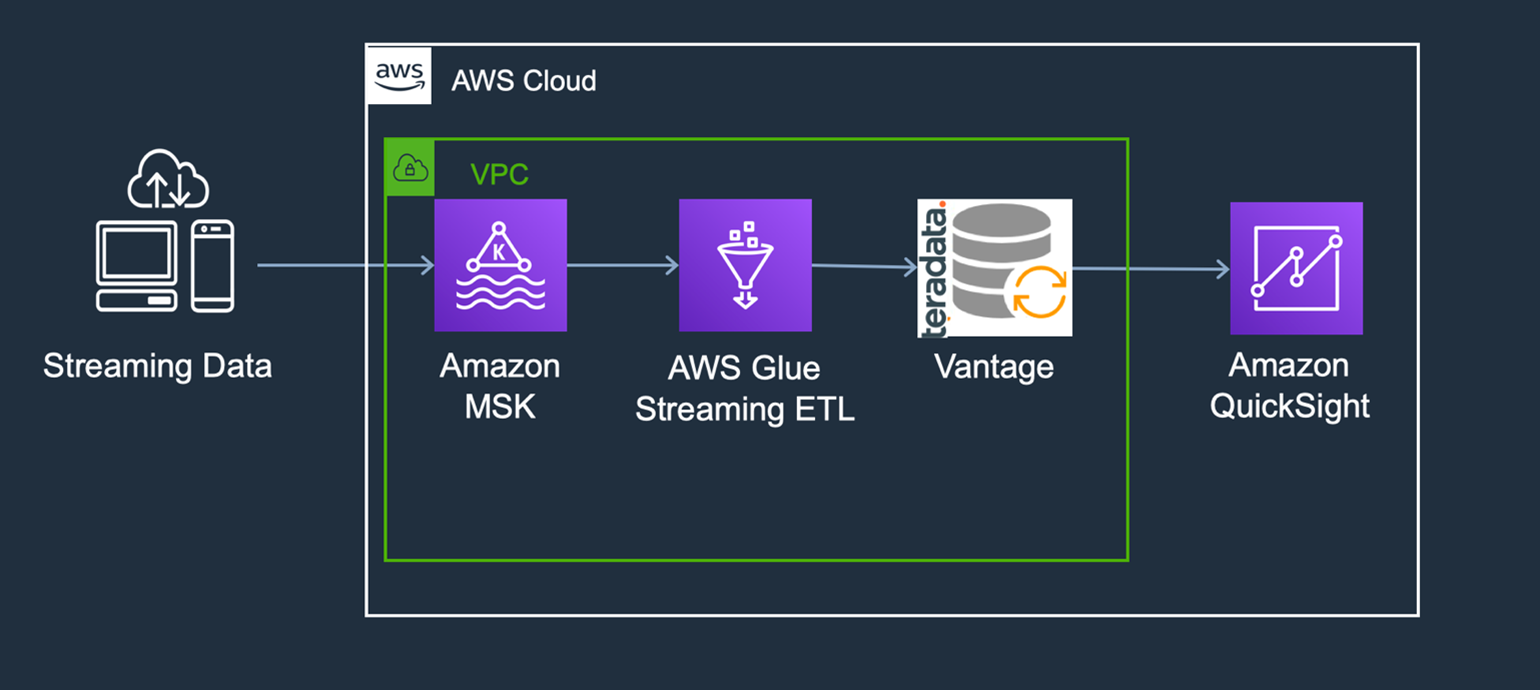
以下のアーキテクチャはMSKからのデータの流れを示しており、AWS GlueによってTeradata Vantageにストリーミングされそこで分析され最後にAmazon QuickSightに表示されるようになっています。このチュートリアルではシンプルなLambda関数を使用して別名MSK Producerを実行することにします。
前提条件
前提条件Teradata VantageでAWS Glue Streaming ETLを使用するにはまず以下の前提条件を満たしていることを確認してください:
・仮想マシンにログインするために、Amazon Elastic Compute Cloud (Amazon EC2)のキーペアが必要です。まだ持っていない場合は、新規に作成します。以下の手順では、キーペアをTeradata.pemと名付け、ローカルマシンにダウンロードすることにします。
・Amazon QuickSightのアカウントを作成します(サブスクリプションが必要です)。
手順
作業手順の概略は以下の通りです。
前提条件を満たした上で、以下のステップを踏んでください:
- Teradata Vantage Developer Edition にサブスクライブします。(この手順は、VantageがAs-a-Serviceで提供されている場合にも有効です)。
- AWS CloudFormation スタックを起動し、Teradata Vantage およびその他の必要なリソースをデプロイします。
- Teradata Vantage でユーザーと読み取り/書き込み可能なデータベースを作成します。
- AWS Glueコンソールを使用してMSK接続とTablesを作成する。
- Glue Streaming ETLジョブを作成しストリーミングを開始します。
- Amazon QuickSightを使用してTeradata Vantageにロードされたデータを可視化します。
- クリーンアップを行います。
ステップ1:Teradata Vantage Developer Editionのサブスクライブ
以下の手順に従って、Teradata Vantage Developer にサブスクライブしてください:
- AWSアカウントにログインします。
- AWS MarketplaceのTeradata Vantage Developer (Free, DIY)のリストにアクセスします。
- 右上の「Continue to Subscribe」を選択します。
- 「Accept Terms」を選択します。
選択すると条件に同意したことになりお客様のアカウントでこのAWS Marketplaceのソフトウェアを使用することができます。
ステップ2:AWS CloudFormation Stackを起動しVantageをデプロイする
AWS CloudFormation は、クラウド環境における AWS およびサードパーティのアプリケーションリソースのモデリングとプロビジョニングを行うための共通言語を提供します。Vantage をデプロイするには、次の手順に従います:
Launch Stack をクリックして、Teradata Vantage Developer Edition をこのチュートリアルの完了に必要なすべてのリソースと一緒にデプロイします。

CloudFormationコンソールページにテンプレートURLが入力されたらドロップダウンからAWS Key Pair 「Teradata.pem as per prerequisites」を選択します。
他のパラメータはすべて自動入力されているのでスクロールダウンしてIAMリソースの作成を確認しチェックボックスにチェックを入れ「Create Stack」をクリックします。
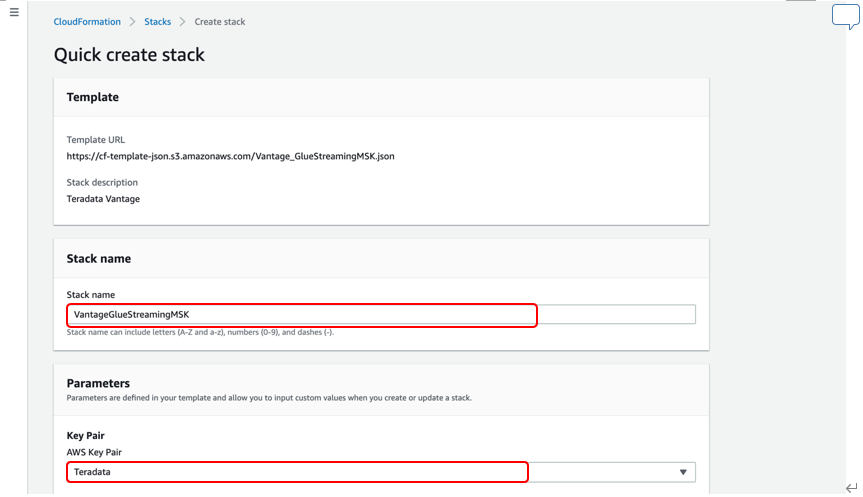
MSK Cluster、MSK Clientノード、Lambda関数、IAMロールなど、必要な前提条件をすべて備えたTeradata Vantage Developer Editionがお客様のアカウントにデプロイされるようになりました。これには最大で20分かかる場合があります。デプロイが完了したら、Stack Outputタブに移動して、そこに記載されているすべての詳細をメモしてください。今後のステップで必要になります。
ステップ3:Kafkaトピックの作成
前のセクションが完了したら.pemキーでKafkaクライアントノードにsshし以下のステップを実行してこのチュートリアルを完了するために必要なKafkaトピックを作成します。
Kafkaトピックを作成するには、CloudFormation Deploymentの一部として作成されたKafkaクライアント・ノードにログインする必要があります。以下のコマンドを使用してKafkaクライアント・ノードにSSH接続します。
ssh -i ~/Downloads/Teradata.pem ec2-user@: < KafkaClientInstance >
ターミナル上で以下のコマンドを実行し、「Say TeraTopic」という名前でKafkaトピックを作成しZookeeperConnectStringをMSKクラスタの「ZK URL」に置き換えます。ZookeeperのURLは、Get Zookeeper Connection Stringを参照してください:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper <ZookeeperConnectString> --replication-factor 1 --partitions 1 --topic TeraTopic
ステップ4:GlueでMSK接続とカタログテーブルを作成する
以下のステップではMSKへの接続を作成しGlue Streaming ETLジョブのソースとして使用するカタログテーブルを作成するのに役立つ設定を説明します。
MSKクラスタへのGlue Catalog Connectionを作成しましょう。
Services AWS Glue Catalog Connectionに移動し「Add Connections」をクリックします。接続のプロパティ画面でConnection Nameに「MSK_Connection」を指定し、Connection Typeを「Kafka」とし、9094ポートで動作するMSK SSLブートストラップURLを入力します。Getting the Bootstrap Brokers infoの手順でMSKブローカーurlを探すことができます。 (また、AWSコンソールを使うと楽かもしれません。)
次へをクリックします。
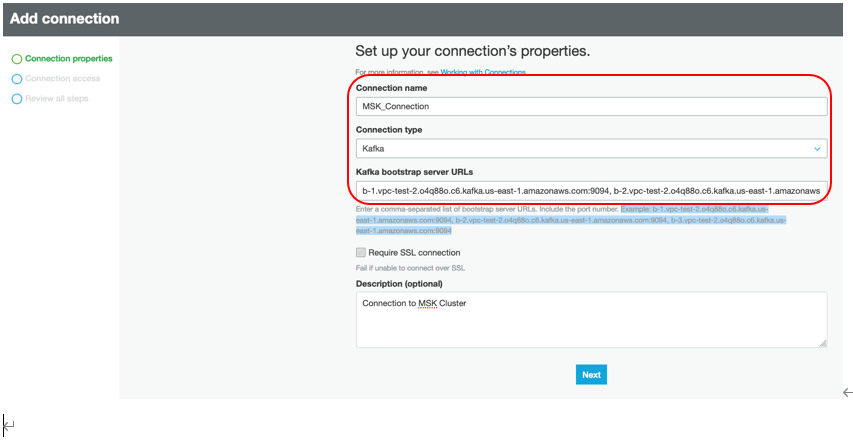
データストアを設定するための「接続アクセス」画面でドロップダウンから「VANTAGE-VPC」という名前のVPCを選択します。サブネット名は「MMPrivateSubnetOne」、セキュリティグループ名のプレフィックスは「VantageStreamingSG」を選択します。

「Next」をクリックし、確認後「finish」をクリックして接続を作成します。
ではMSKトピックのテーブルを作成しましょう。カタログ 「Table」をクリックし、「Add Table」をクリックします。「テーブルを手動で追加」を選択します。次の画面で名前 「TeraTopic」を入力します。ドロップダウンからデータベースを選択します。データベースを作成していない場合は、Glueデータベースの使い方を参照してデータベースを作成してください。
Add a Data storeページでType of Sourceを「Kafka」にします。Topic Nameは前項で作成した「TeraTopic」、Connectionは「MSK_Connection」を選択します。「Next」をクリックして次に進みます。

次のページで、Classificationを 'JSON' に選択して、nextをクリックします。スキーマの定義画面で、'Add Column'をクリックし、以下のようなタイプのカラム名を指定します。
| Type | Column Name |
|---|---|
| String | searchword, countrycode, useragent,languagecode, sourceip, visityearmonth, desturl, customer |
| BigInt | yearmonthkey, visitdate, duration, custkey |
「Next」をクリックして確認し次の画面で 「Finish」をクリックするとMSKテーブルの作成が完了します。

ステップ 5: MSKからVantageにデータをストリーミングするGlue Streaming ETLジョブのオーサリング
以下の手順でTeradata JDBCドライバをダウンロードした後、Amazon S3の任意の場所にロードすることでGlueストリーミングETLジョブでVantageデータベースに接続するために使用することができます。
- 最新のTeradata JDBCドライバをダウンロードします。
- ダウンロードしたファイルからtdjdcb4.jarを解凍します。
- Amazon S3バケットを作成します。
- S3バケットにtdjdbc4.jarをアップロードします。
では、AWS GlueのETLジョブタブからストリーミングETLジョブをオーサリングしてみましょう。左側のパネルからJobsをクリックし「Add Job」ボタンをクリックします。
次のページでは
- Name:MSK2Teradata
- IAM Role:ドロップダウンから TeradataGlueRole-MSK
- Type:Spark Streaming
- This Job Runs:Proposed Script generated by AWS Glue
として指定します。他はデフォルトのまま、下にスクロールします。
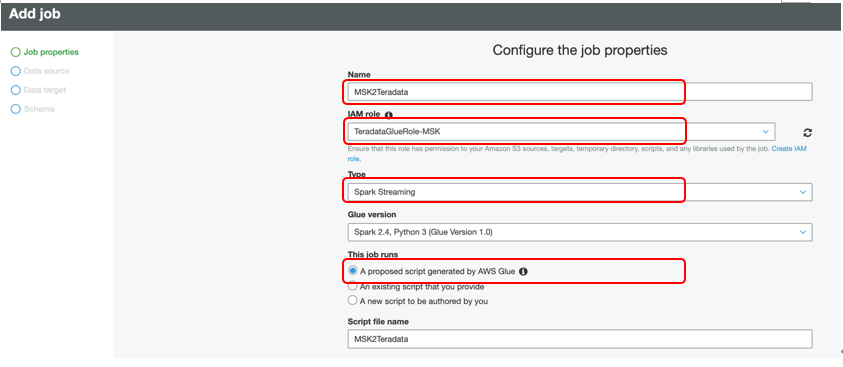
同じウィンドウ内で「Security Configuration, script libraries, and job parameters (optional)」を選択し、セクションを展開します。
Dependent jars pathフィールドにS3バケットのパスとTeradata JDBCドライバーのキー名を入力します。s3://<あなたのバケット名>/terajdbc4.jar のような形式である必要があります。
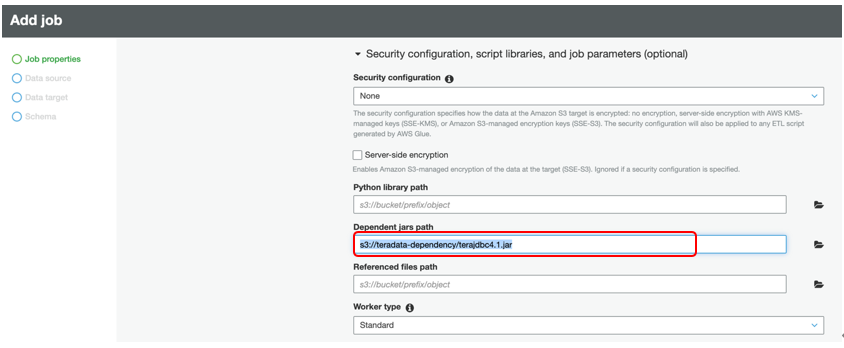
残りのパラメータはデフォルト値のままスクロールダウンし「Next」を選択します。
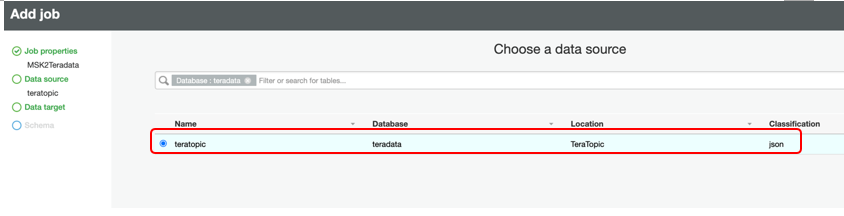
Data Sourceペインが表示されます。MSKトピックを使用して上で作成したテーブルTeraTopicのラジオボタンを選択し、「Next」をクリックします。
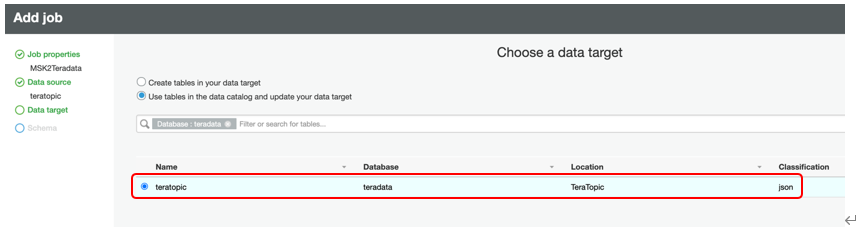
データターゲット]ペインが表示されます。同じTeraTopicを選択し「Next」をクリックします。ここでは、代わりにスクリプトで宛先を変更します。
次のウィンドウにはソースカラムとターゲットカラムのマッピングが表示されます。変更の必要はありません。

「Save Job」をクリックしスクリプトに次の変更を加えます:
- 34行目で、windowSize を100秒 から5秒 に変更します。

- 32行目で「datasink1=」の行を複製し、元のバージョンをコメントアウトします。これらの値を使用して、Teradata JDBCドライバの詳細を示す以下のスニペットを追加し、この中でvantage ip/hostnameを更新することを確認します。
datasink1 = glueContext.write_dynamic_frame.from_options(frame = apply_mapping, connection_type = "jdbc", connection_options = {"url": "jdbc:teradata://ec2-XX-YYY-ZZZ-AA.us-west-2.compute.amazonaws.com/DATABASE=GlueDB,TMODE=ANSI","driver":"com.teradata.jdbc.TeraDriver","dbtable": "TeraTopic","database": "GlueDB","user": "GlueUser","password": "aws"}, transformation_ctx = "datasink1")
ページの上部の「Save」をクリックします。最後に「Run Job」をクリックしてMSKから Vantageへのデータ転送を開始します。ジョブが起動するまでには数分かかります。
ステップ6:Lambda Streamingシミュレータの起動 - MSK Producer
ではCloudFormation Resourcesページに戻り、VantageMSKProducer Physical IDのリンクをクリックして、Lambdaコンソールを起動しましょう。
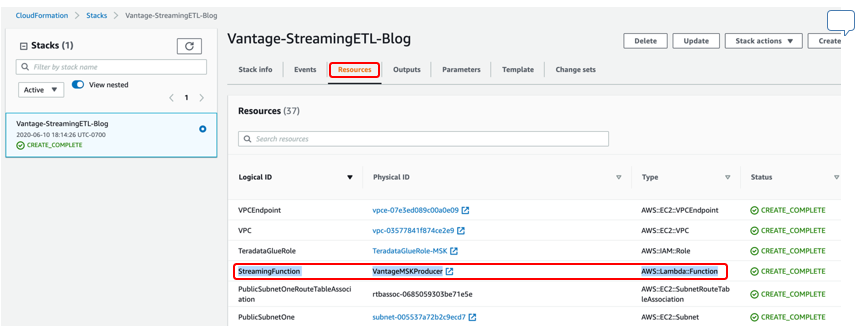
Lambdaコンソールで右上のTestボタンをクリックしストリーミングデータをシミュレートします。
configure test event画面が表示されます。configure test event画面でシミュレータが実行するためにリストされたフィールドにフォーマットされたJSONレコードを提供します。YOUR_MSK_BOOTSTRAP_SERVER_LISTを「Bootstrap Broker String TLS」に置き換え、テスト・イベントの名前を指定し「Save」をクリックしてテスト・イベントを作成します。
{
"BOOTSTRAP_SERVERS": "<YOUR_MSK_BOOTSTRAP_SERVER_LIST>",
"TOPIC": "TeraTopic",
"BUCKET": "streaming-data-repo"
}

バケットにストリーミングされるデータが入ります。保存] をクリックします。保存したら、もう一度 [テスト] をクリックして、シミュレータを起動し、設定にある MSK トピックにデータをストリームします。クリックすると、シミュレータは2分間実行され、その後、エラーでタイムアウトします。[タイムアウトは、コンソールからラムダ設定で調整できます。リソースの消費を避けるために、ストリーミングが停止するように設定されています]。
ステップ7:Amazon QuickSightを使ってデータを可視化・分析する
Vantage にロードされたデータにはさまざまな分析を適用できます。しかしこの例ではQuickSight を使用して Vantage にロードされたデータを視覚化する方法に焦点を当てます。
はじめにAmazon QuickSightを開き新しいデータセットを作成します。
データセットの一覧から「Teradata」を選択します。ポップアップウィンドウが表示されます。
- 「Database Name」フィールドに、データベースサーバーのVantageインスタンスのDNS 名と手順3で作成したデータベースのポート(1025)およびデータベース認証情報を入力します。
- 「Validate Connection」を選択してパラメータの正しさを確認します。接続が確立され検証されるとその横に緑色のチェックマークが表示されます。
- 同じポップアップウィンドウで、「Create Data Source」を選択します。
データソースが作成されるとAmazon QuickSightはVantageのテーブルを特定します。
- TeraTopicテーブルを選択し、ポップアップウィンドウから「Use Custom SQL」を選択します。
- クエリの名前を指定しクエリとして「select * from TeraTopic」を入力し「Confirm Query」をクリックします。
- 読み込んだら「Edit/Preview data」をクリックします。以下のようにデータが読み込まれます。

- 日付フィールドのデータ型を必要に応じて変更するか計算フィールドを作成してQuickSightを使用してデータの可視化を開始することができます。
Amazon QuickSightでAutoGraphのビジュアライゼーションを作成する方法についてはこのドキュメントを参照してください。
ステップ8:後始末
この記事の一部として作成されたリソースによる追加料金が発生しないようにAWS CloudFormationのスタックを削除することを確認します。CloudFormationコンソールに移動しStacksで作成されたスタックを削除します。また作成されたGlueジョブを停止し接続、データベース、テーブル、作成されたGlueジョブを削除してください。
おわりに
今回のブログでは、AWS Glueでカスタムデータベースコネクタを設定する方法、Streaming ETLを使用してTeradata VantageにMSKデータをロードする方法、Amazon QuickSightを使用して結果を直接可視化する方法について学習しました。
ぜひお試しください!