とても多くのお客様がVantageとAWSのサービスとの統合に関心を持っています。そのようなトピックからここではTeradata VantageとAWS Comprehend Medicalサービスとの連携について情報提供してみようと思います。
このアプローチは社内で実装されテストされていますが、そのままの状態で提供されます。AWSとTeradataのどちらも、Teradata VantageとAWSサービスの検証を提供していません。
このガイドで説明するアプローチは、QuickSightと統合するための多くの可能性のあるアプローチの一つであり、そのままの形で提供されるものです。 このアプローチは社内で実装されテストされていますが、TeradataまたはAWSのいずれからも、このアプローチに関する正式なサポートはありませんのでご注意ください。
とはいえ、何がうまくいったのか、何がうまくいかなかったのか、どうしたら改善できるのか、などなど、皆さんのフィードバックはとても望ましく、ありがたく思います。
ご意見・ご感想は、コメントとしてお寄せください。
免責事項:本ガイドは、AWSとTeradata製品の両方のドキュメントからの内容を含んでいます。
概要
この記事では、Vantageからフリーフォームの医療データを取得し、AWS Comprehend Medicalで実行し、その結果をVantageに戻してさらに高度な分析を行う手順について説明します。
AWS Comprehend Medicalは、機械学習機能を活用して非構造化テキストから関連する医療情報を抽出する自然言語処理(NLP)サービスです。AWS Comprehend Medicalは、設定が不要です。事前に学習したモデルを用いて、医師の診断書や検査結果などのドキュメントを調査し、テキスト内の医療エンティティに関する特定の情報を返します。
前提条件
AWSサービス、Teradata Vantage、Pythonに精通した方を想定しています。
以下のアカウント、パッケージ、システムが必要です。
・AWSのアカウント。無料アカウントから始めることができます。
・AWSアクセスキーとシークレットアクセスキー。
・ユーザーとパスワードが設定されたTeradata Vantageインスタンス。ユーザーは、テーブルを作成するための権限とスペースを持っている必要があります。Vantageは、AWSサービスからアクセス可能である必要があります。
・システムにインストールされたPython(64ビット)。本記事では、Python 3.x (バージョン 3.7 以上) を使用することを前提としています。
・Pythonのインストーラーに付随するPIP(Python Package Installer)がインストールされていること。
・Teradata Python Package、通称 "teradataml"。
・AWS Software Development Kit for Python、通称 "boto3"。
・AWS Command Line Interface, v2。
・Teradata StudioまたはTeradata Studio Express、Teradata Downloadsから入手可能。Vantageに代わるインターフェイスを使用することもできますが、ここではStudioのみを説明します。
・Vantage のソース医療データ。https://github.com/teradatadownload/aws/raw/master/singlepatient.xlsx で公開されているサンプルファイルを Vantage に読み込むことができます。
はじめに
VantageからAWS Comprehend Medicalへ医療情報を簡単に転送するために、Pythonスクリプトを使用します。このスクリプトは、Vantage に接続し、データをデータフレームにロードし、AWS Comprehend Medical に渡して処理を行い、その結果を Vantage の新しいテーブルに返します。
Python スクリプトは、Vantage との通信に Teradata Python Package を、AWS への接続に AWS Software Development Kit を使用します。Vantageへのアクセスはユーザー名とパスワードで認証され、AWSへのアクセスはアクセスキーとシークレットアクセスキーで認証されます。
PythonとPIPのインストール
Pythonはあなたのシステムにインストールされている必要があります。Windows、Mac、Linux用のインストーラを含む公式ソース http://python.org を利用することもできますし、お好みのソース/ディストロを利用することもできます。
Windowsの場合、64ビット版をインストールする必要があります。http://python.org のデフォルトは32ビットですので、64ビット版を明示的にダウンロードする必要があります。
Teradata Pythonパッケージのインストール
Teradata Python Package (teradataml)は、Teradata Vantageと対話するための関数群を提供します。
Teradata Python Packageをインストールするには、"pip "を使用します。
Windows
C:\>python -m pip install teradataml
Mac / Linux
$ pip3 install teradataml
AWS Software Development Kit for Pythonのインストール
AWS Software Development Kit for Python (boto3) は、Amazon Web Services プラットフォームと対話するための関数群を提供します。
AWS Software Development Kitをインストールするには、"pip "を使用します。
Windows
C:\>python -m pip install boto3
Mac / Linux
$ pip3 install boto3
AWSコマンドラインインターフェイスのインストール
AWS CLIをシステムにインストールするには、以下の手順に従います。この手順は、Windows、Mac、Linuxを対象としています。バージョン1をインストールしていた場合は、バージョン2(以下、v2)を使用していることを確認する必要があります。
AWS Command Line Interfaceがインストールされていることは、以下のコマンドで確認することができます。
Windows
C:\>aws --version
Mac / Linux
$ aws --version
AWSコマンドラインの認証情報を設定する
「AWS Access Key ID」、「AWS Secret Access Key」、「Default region name」、「Default output format」を設定し、AWS CLIを構成する。
AWSアクセスキーIDとシークレットアクセスキーが必要な場合や紛失した場合は、「AWS CLIの構成」ページの手順に従って、新しいペアを作成してください。アクセスキーIDは以下のようなものになります。
| Sample Access key ID | Sample Secret access key |
|---|---|
| AKIA56JXJ3UNAFSAH2O5 | OcK8B9st/37xEAofoNKoyNB68b91JNjiTnuj+H/Z |
レイテンシーを最小にするために、あなたに近いリージョンを選択します。AWSは利用可能なリージョンのリストを保持しています。リージョン名は、「Northern Virginia」のような地理的な名前ではなく、「us-east-1」のような形式を使用する必要があることに注意してください。デフォルトの出力形式は空白または "none "のままで問題ありません。
AWS Command Line Interfaceが正しく設定されていることは、以下のコマンドで確認できます。
Windows
C:\>aws s3 ls
Mac / Linux
$ aws s3 ls
コマンドがエラーなく実行されていれば(結果が空でも)、AWS Command Line InterfaceはAWSと正しく認証できていることになります。
Vantageにソースデータをロードする
Teradata StudioまたはTeradata Studio Expressを使用して、Teradata Vantageシステムに接続します。
ソースデータ用のテーブルを作成します。提供されたサンプルデータを使って、以下のテーブル定義を使用することができます。(AWS Medical Comprehendはこの形式を要求していません。ほぼ全てのフォーマットで動作します)。
CREATE MULTISET TABLE HealthNotes
(
patient_key VARCHAR(40),
encounter_date VARCHAR(255),
assessment VARCHAR(20000)
)
PRIMARY INDEX ( patient_key );
データをテーブルにロードします。提供されているサンプルデータを使用する場合は、Teradata Studioでロードを実行します。データがヘッダー行を持つことを示すことを確認します。サンプルデータには18行があります。
より大きなデータセットをロードする場合は、Teradata Parallel Transporterの使用を検討してください。
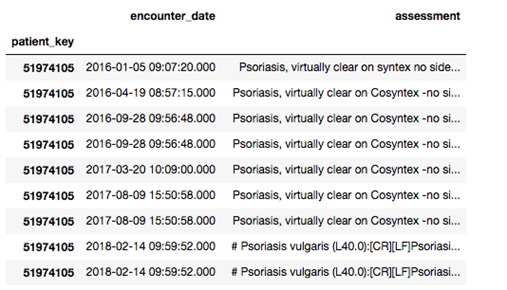
サンプルデータは以下のような感じです。
Pythonスクリプトの作成
スクリプトの完全なサンプルは、ダウンロード可能です。このスクリプトを実行するには、カスタマイズが必要です。Vantage インスタンスを指すようにスクリプトを変更し、認証情報を含める必要があります。
次の手順では、サンプル コードの各セクションについて説明します。
ライブラリのインポート
ライブラリは、使用できる関数の集まりです。
# Import Statements
import boto3
import teradataml as tdml
from teradataml import create_context, remove_context
import pandas as pd
import getpass
「getpass」ライブラリはオプションです。これは、スクリプトにパスワードが含まれていることを要求するのではなく、ユーザーにパスワードを要求するもので、セキュリティが強化されています。
元データを取得する
ソースデータは、任意の有効なデータソースから取得することができます。ここでは、Vantageのテーブルを使用しています。データが取得されると、AWS Comprehend Medical サービスに渡され、分析が行われます。
Vantageシステムへの接続は次のような構文になります。
create_context(host = ‘[host name/ip]’, username = ‘[database username]’, password = ‘[database password]’)
“[]”の中の値をお使いの環境に合わせて修正してください。
# Login to Teradata Vantage
create_context(host = '100.00.00.00', username = 'testUsr', password = getpass.getpass(prompt = 'Password:'))
Pythonのdataframeにデータを読み込むのは次のような構文になります
source_data = tdml.DataFrame(‘[database name].[table name]’)
“[]”の中の値をお使いの環境に合わせて修正してください。
# Retrieve input data
source_data = tdml.DataFrame('testUsr.healthnotes')
Vantage から読み込んだデータフレームをPandasのデータフレームに変換する構文は次の通りです。
# Convert to Pandas DataFrame
source_data_pd = source_data.to_pandas()
AWS Comprehend Medicalサービスを利用する
Comprehend Medicalサービスのハンドルを取得するのは次のような構文です。
client = boto3.client('comprehendmedical')
# Call Comprehend Medical Service
client = boto3.client('comprehendmedical')
出力を保持するデータフレームを作成するのは次のような構文です。
dfobj=pd.DataFrame())
# Initialize output DataFrame
dfObj=pd.DataFrame()
サンプルのソースデータには、patient_key、encounter_data、assessmentの3つのカラムがあります。アセスメントのコンテンツは、Comprehend Medicalに渡すものです。i」は各行、「j」は各列を表し、データフレーム内の各行を「for」ループで反復処理します。
ComprehendMedical.Clientクラスには、多くのモジュールが含まれており、そのドキュメントを掲載しています。ここでは、detect_entitites_v2 メソッドを使用しています。また、ICD10コードや処方箋を扱う場合は、infer_icd10_cmとinfer_rx_normメソッドを使用することができます。
# Iterate through each row of input data
for i, j in source_data_pd.iterrows():
# Get content of 'assessment' column
str_val = j['assessment']
result = client.detect_entities_v2(Text=str_val)
detect_entities_v2 メソッドは、辞書の配列を返します。これをループして、各エントリに対応する行を作成します。各エントリについて、元のデータからいくつかの情報を取得する必要があります。
# Get content of 'encounter_date' column
encounter_date = j['encounter_date']
# Going through each array entry to prepare output data
entities = result['Entities']
for entity in entities:
# Adding patient_key and encounter_date to each entry. This step is optional
entity.update( {'patient_key' : i} )
entity.update( {'encounter_date' : encounter_date})
# Finish updating each entry with patient_key and encounter_date
各ディクショナリは、複数のキーと値のペアを持ち、それらはソースデータから医療エンティティに関する情報を提供する。各エンティティには、以下のキーが含まれます。ID、BeginOffset、EndOffset、Score、Text、Category、type、Traits、およびAttributesです。さらに、キーであるTraitとAttributesは、それ自体が辞書となります。
結果を Vantage に書き戻すには、まず値を文字列に変換する必要があります。
# Convert dictionary "Traits" to string
entity.update({'Traits': str(entity["Traits"])})
# Convert dictionary "Attributes" to string
if "Attributes" in entity:
attr = entity["Attributes"]
else:
attr = 'NaN'
entity.update({'Attributes': str(attr)})
ここで、Vantage に返す結果を「行」に配置します。
# Adding updated result entry to DataFrame
dfObj = dfObj.append(entity, ignore_index=True)
最後に、以下のコマンドで結果を Vantage に書き戻します:
tdml.copy_to_sql(df = dfObj, table_name = "[table name]", schema_name='[schema name]', if_exists = "replace")
"[]"を実際のスキーマ(ユーザー)名とテーブル名に置き換えます。このデスティネーション・テーブルは、同じ名前のテーブルを置き換えるので、ソース・テーブル名とは異なるテーブル名を使用してください。
# Write results back to Teradata Vantage
tdml.copy_to_sql(df = dfObj, table_name = "entity_assessment", schema_name='testUsr', if_exists = "replace")
remove_context()
スクリプトを実行する
スクリプトがローカルディレクトリにあると仮定して、以下のコマンドでスクリプトを実行します。
Windows
C:\>python vantage_awscomprehendmedical.py
Mac / Linux
$ python3 vantage_awscomprehendmedical.py
スクリプトの実行には1分程度かかる場合があります。
スクリプトの実行が終了すると、スクリプトの末尾にある宛先テーブル名を持つテーブルが、AWS Comprehend Medicalからの結果を含むスキーマでVantageに作成されます。
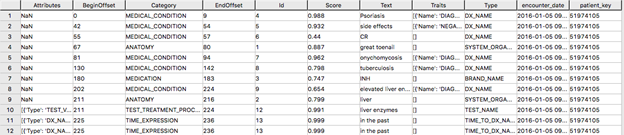
これは、AWS Comprehend Medical サービスからの結果を含むテーブルの結果の例です。
おわりに
いかがでしたでしょうか?みなさんもAmazon Comprehend MedicalとVantageのコラボレーションを使って、医療データの分析にご活用ください!