はじめに
この記事はFUJITSU Advent Calendar 2022の18日目の記事です。
お約束ごとですが、記事は全て個人の見解です。会社・組織を代表するものではありません。
本記事ではAutoMLについて自動化のイメージを簡単な具体例を用いて書いてみます。
AutoML(Automated Machine Learning)
機械学習のステップは下記の様にそれなりに大きなものです。自動化できたら嬉しい、と自然に思えるのではないかと思います。
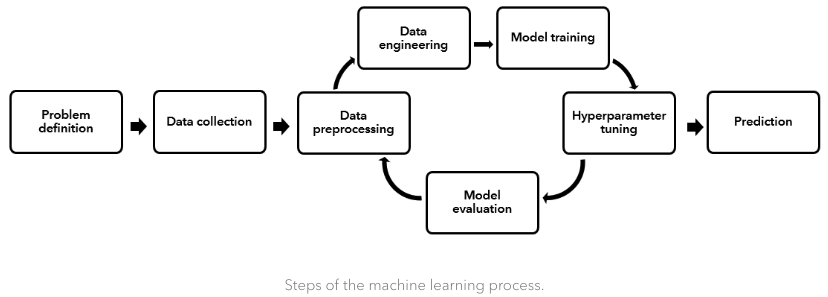
(引用: https://www.esri.com/arcgis-blog/products/arcgis-pro/analytics/automl-in-arcgis-pro-3-0/)
どうやって自動化するのか?
仕組みとしては種々ありますがここでは2パターン取り上げてみます。
- ルールベース
- 学習&推論ベース
1. ルールベース
if ... then ...のやつです。ここではAutogluonのTabularPredicorのタスク設定を例として取り上げます。凄く局所的な部分ですがコードを読んでいて想定よりも少なく書かれていて驚きだったのでこちらを取り上げます。
TabularPredictorはタスクとして、分類2種(バイナリ、マルチ)と回帰1種の3パターンを取り得ますが、problem_type引数にNoneを指定すると自動で推測してくれます。
'''
problem_type : str, default = None
Type of prediction problem, i.e. is this a binary/multiclass classification or regression problem (options: 'binary', 'multiclass', 'regression', 'quantile').
If `problem_type = None`, the prediction problem type is inferred based on the label-values in provided dataset.
'''
この自動推測がどう行われているか、ソースを追ってみましょう。
いろいろ端折ると下記の関数でタスクの推測をしてくれることが分かります。
def infer_problem_type(y: Series, silent=False) ->str:
70行程度のルールと学習セットの正解ラベルから推測しており、一番分かりやすいルールは以下です。「正解ラベルが2値しか取らない場合はバイナリ分類だろう」という推測。まさにルールベースだと思います。
unique_values = y.unique()
,,,
unique_count = len(unique_values)
if unique_count == 2:
problem_type = BINARY
reason = "only two unique label-values observed"
2. 学習&推論ベース
1.ルールベースで取り上げたタスクの自動推測を機械学習ベースで考えてみましょう。
Autogluonの内部コードでは、unique_count, unique_ratio, subdtype, can_convert_to_intという変数を使って判定していたので、これらを特徴量として3値の正解ラベル(binary, multi, regression)を推論するモデルを考えます。データセットを用意するのも大変なのでsklearnを使って擬似データセットを作り、学習と評価をしてみます。
2-1. まずは関数定義。
from typing import NamedTuple
import numpy as np
import numpy.typing as npt
import pandas as pd
from sklearn.datasets import make_classification, make_regression
from sklearn.metrics import accuracy_score
import category_encoders as ce
from lightgbm import LGBMClassifier
class Dataset(NamedTuple):
type: str # ['binary', 'multi', 'regression']
X: npt.NDArray
y: npt.NDArray
TASK_TYPES = ['binary', 'multi', 'regression']
class DatasetCreator():
def __init__(self, rand=20221218):
self.rng = np.random.default_rng(rand)
def create_datasets(self, n_sets: int):
return [self._create() for i in range(n_sets)]
def _create(self):
tt = self._pick_task_type()
rs = self.rng.integers(3, 100)
if tt == 'binary':
X,y= make_classification(n_classes=2, random_state=rs)
elif tt == 'multi':
X,y = make_classification(n_classes=rs, n_features=rs, n_informative=rs, n_redundant=0, n_clusters_per_class=1, random_state=rs)
elif tt == 'regression':
X,y = make_regression(random_state=rs)
else:
print('unexpected', tt)
return Dataset(type=tt, X=X, y=y)
def _pick_task_type(self):
return self.rng.choice(TASK_TYPES, 1)[0]
def generate_features(y: np.ndarray):
s = pd.Series(y)
unique_count = s.nunique()
unique_ratio = unique_count / float(len(y))
subdtype = y.dtype
can_convert_to_int = False
try:
can_convert_to_int = np.array_equal(s, s.astype(int))
except:
pass
return pd.DataFrame({'unique_count': [unique_count], 'unique_ratio': [unique_ratio], 'subdtype': [subdtype], 'can_convert_to_int': can_convert_to_int})
2-2. 次に学習。
subdtypeは値としてint64とfloat64を取りますがこのままだとモデルに食わせられないのでOneHotEncoderを挟んでいます。
n_trains = 1000
dc = DatasetCreator()
train_sets = dc.create_datasets(n_trains)
train_Xs = pd.concat([generate_features(set.y) for set in train_sets])
ohe = ce.OneHotEncoder(cols=['subdtype'])
train_Xs = ohe.fit_transform(train_Xs)
train_ys = pd.Series([set.type for set in train_sets])
cls = LGBMClassifier()
cls.fit(train_Xs, train_ys)
## なんとなく確認。
train_pred = cls.predict(train_Xs)
print(accuracy_score(train_ys, train_pred))
> 1.0
2-3. 最後に評価。
test_sets = dc.create_datasets(100)
test_Xs = pd.concat([generate_features(set.y) for set in test_sets])
test_Xs = ohe.transform(test_Xs)
test_ys = pd.Series([set.type for set in test_sets])
pred = cls.predict(test_Xs)
print(accuracy_score(pred, test_ys))
> 1.0
きちんと精度高く推論出来ていますね。ちなみにn_trainsが30程度と少ない場合は、学習セットですら精度100%が出ませんでした。書いたコードの量とデータセットのサイズからして、この程度であればルールベースでやってしまった方が賢そうですね。。
まとめ
例があまり良くなかったのか特徴量設計が不要なディープラーニングの導入のような流れになってしまいましたが、自動化ってきっとこんなイメージかと思っています。
今回の例では学習データセットの正解ラベルからタスクを自動推論(推測?)する例を取り上げましたが、入力データやラベルの傾向から必要な前処理というのは両手・両足では数えきれないくらいのパターンがあります。必要な前処理の例としては、特徴量に欠損値があったらImputerを挟む、他の特徴量に比べて幅広い値を取りうる場合にはscalingする、等です。
この辺りまとめて全部自動化してくれたらさぞ嬉しいですよね!!