本記事ではAutoMLについて自分が面白いなぁ、かっこいいなぁ、と思った部分を垂れ流します。
AutoML
機械学習のステップは下記の様にそれなりに大きなものです。自動化できたら嬉しい、と自然に思えるのではないかと思います。
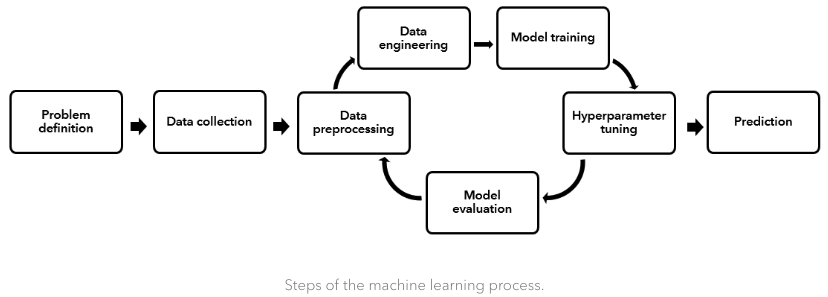
(引用: https://www.esri.com/arcgis-blog/products/arcgis-pro/analytics/automl-in-arcgis-pro-3-0/)
どうやってAutomateするのか?
仕組みとしては種々ありますがここでは2パターン取り上げます。
- ルールベース
- 学習&推論ベース
1. ルールベース
if ... then ...のやつです。ここではAutogluonのTabularPredicorのタスク設定を例として取り上げます。凄く局所的な部分ですがコードを読んでいて想定よりも少なく書かれていて驚きだったのでこちらを取り上げます。
TabularPredictorはタスクとして、分類2種(バイナリ、マルチ)と回帰1種の3パターンを取り得ますが、problem_type引数にNoneを指定すると自動で推測してくれます。
'''
problem_type : str, default = None
Type of prediction problem, i.e. is this a binary/multiclass classification or regression problem (options: 'binary', 'multiclass', 'regression', 'quantile').
If `problem_type = None`, the prediction problem type is inferred based on the label-values in provided dataset.
'''
この自動推測がどう行われているか、ソースを追ってみましょう。
いろいろ端折ると下記の関数でタスクの推測をしてくれることが分かります。
def infer_problem_type(y: Series, silent=False) ->str:
70行程度のルールと学習セットの正解ラベルから推測しており、一番分かりやすいルールは以下です。「正解ラベルが2値しか取らない場合はバイナリ分類だろう」という推測。まさにルールベースだと思います。
unique_values = y.unique()
,,,
unique_count = len(unique_values)
if unique_count == 2:
problem_type = BINARY
reason = "only two unique label-values observed"
2. 学習&推論ベース
上記ルールベースの例では正解ラベルからのルールを取り上げましたが、入力データやラベルの傾向から必要な前処理というのは両手では数えきれないパターンくらいあり、であればそれ用にモデルを作って推論させてしまうのも上手い手だと思います。
入力データと必要な前処理の例としては、特徴量に欠損値があったらImputerを挟む、他の特徴量に比べて幅広い値を取りうる場合にはscalingする、等です。
こう書いてしまうと全部ルールで書けば?とも思われるかもしれませんが、それはそれで大変です。
昨今のトレンド(ポエム)
ここからはポエムです(ここまでもポエムでしたが)。
自動化というとデータ分析の素人でもできる!みたい方向性が王道ですがまさにそういうところを訴求ポイントとして各社売り込んでいると思います。
普及に向けた訴求例
有名どころとしてAndrew Ng先生のTED Talkの1スライドを取り上げます。

(引用: https://youtu.be/reUZRyXxUs4?t=384 )
個人の理解としては以下です。
AIや機械学習ってその昔はターゲティング広告やWeb検索などスケールすることで莫大な価値を生む領域で取り入れられて進化してきた。でもデータっていろんなところに溢れていて価値が小さめな領域(long tail)もあって今はここも大事になってきてるよね
ここでいう価値が小さめな領域はガチな技術者が寄ってたかって競い合う領域ではなく、どちらかというとAI/機械学習が本業ではない方が多いのだと思います。
そこで、自動化、です。
一方でそれなりに大きめデータを扱う機械学習、かつ、そこまで詳しくない方が取り組むシーンではそもそも最初のendが定まっていないことって往々にしてありえます。十分に理解していない事はその時点で言語化することは難しいですよね。
UXの肝は比較
そこで今後こういう方向ならかっこいいなぁと漠然と思っていた事が下記Tweetで見事に言語化されていました。
tiktokでもtinderでもstable diffusionでも、ユーザーが特徴空間をさまよいながらほしいものを見つける情報検索のUI/UXが定着しつつあるけど、これって名前付いてるのかな? もはやpersonalization という表現は古いと思う。
— Kazunori Sato (@kazunori_279) November 27, 2022
自分はAkinatorやTumblrで遊んでいた時に似たような事を思いました。知りたい事は頭の中にモヤっとあるけれどきちんと言語化は出来ていない、けど知りたい。その際に言語化するのは難しいけど、比較とかYes/Noの質問に答えることは出来ます。
機械学習でもデータは持っていて何かしら有用に使えると良いなぁと思っている人がまずはやってみて「違う、そうじゃない」と問答を機械と繰り返す事で核心に近づくor妥協点を探せると、普及してくれるのではと思っています。