はじめに
最近サーバレスアーキテクチャに興味を持っています。以下2エントリーはGoogle Apps ScriptでJava Scriptを使った時の記事ですが、今回はAWS上のLambdaを使って、サーバーレスでPythonコードを実行させることをやっていきたいと思います。記事の内容は、Pythonほぼ初めまして&&AWSほぼ初めましての人が、LambdaとDynamoDBでいろいろできるようになるまでの記録を書いていきます。
また最初AWS分かんなさすぎて最初は絶望していたし、Lambdaはエラー出まくって初見殺しだし、Python興味はあるけど使ったこと少なめと、かなり初心者目線で記事を書いていきたいと思ってます。写真多め、初心者がわかる程度の内容を、ひとつずつ書いていく感じですので、PythonistとAWS上級者の方は新しいことはないかと思いますが、どうぞよろしくお願いします。
この前書いた記事
前提
AWS初めまして
Python歴2週間くらい
AWSサービス登録済、無料枠中
AWS
自分の場合は、AWSのサービスの多さに混乱したので、どのサービスがどのサービスとつながってるのか、まず概要を勉強しました。下記あたりが参考になるかと思います。またKindleで無料の書籍とか探しました。「ってますが、自分で使いながら、この記事を見直しながらいろいろやってみました。
「AWS is 何」を3行でまとめてみるよ
AWS1年目無料期間でやったこととハマったこと
登録
登録済みと仮定しているのでAWS登録は別の記事を参照ください。
ロール作成
AWSロールがないといろいろ面倒なので、
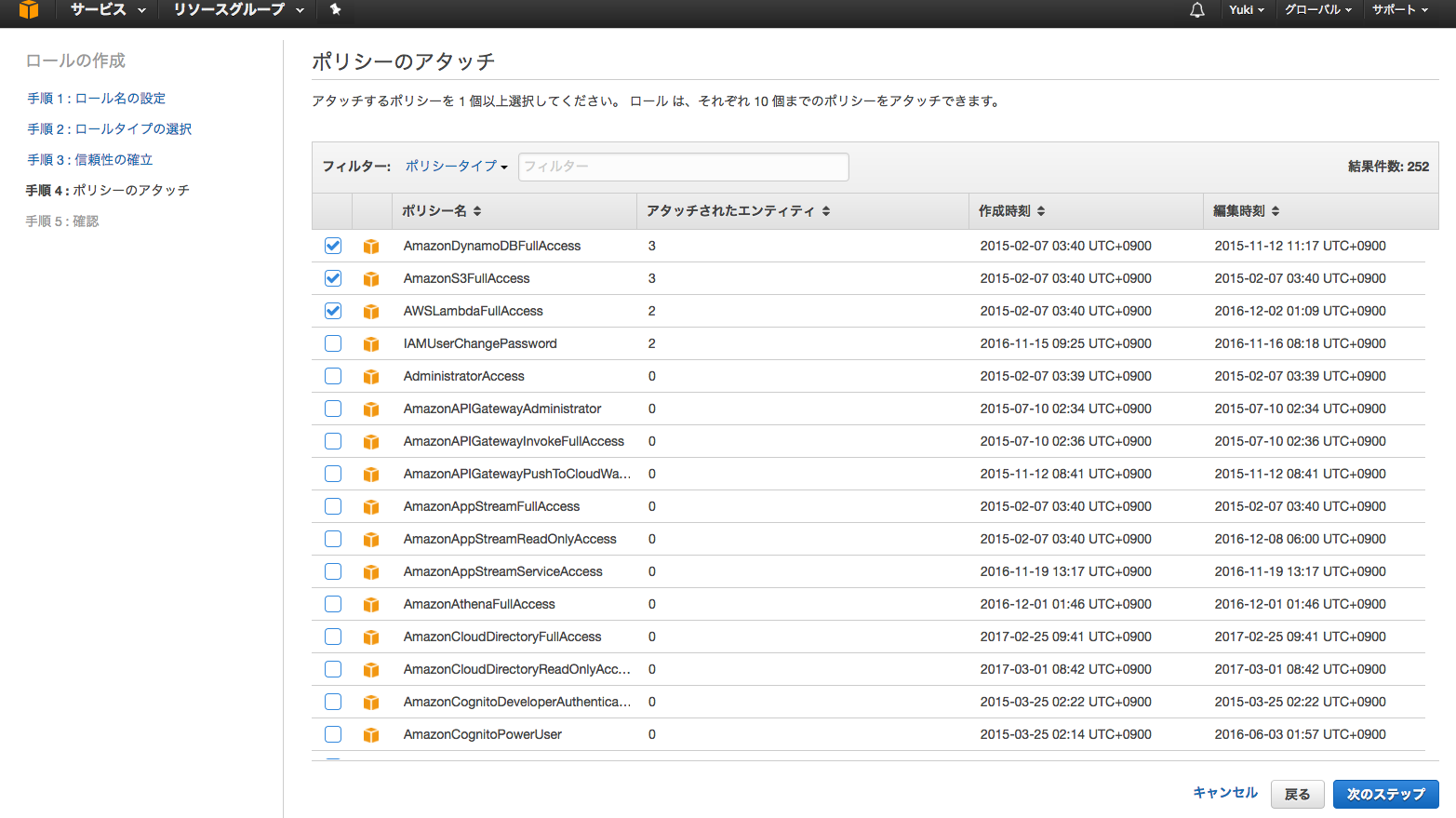
S3,DynamoDB,Lambdaにフルアクセスできるロールを今回作ります。
AWSサービス一覧からIAM
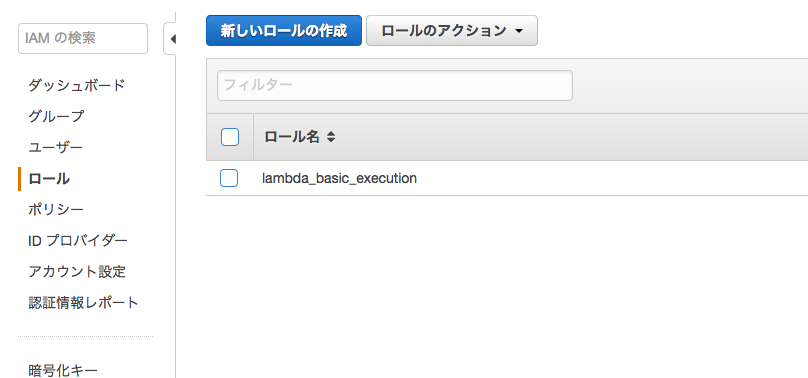
ロール >> 新しいロールの作成
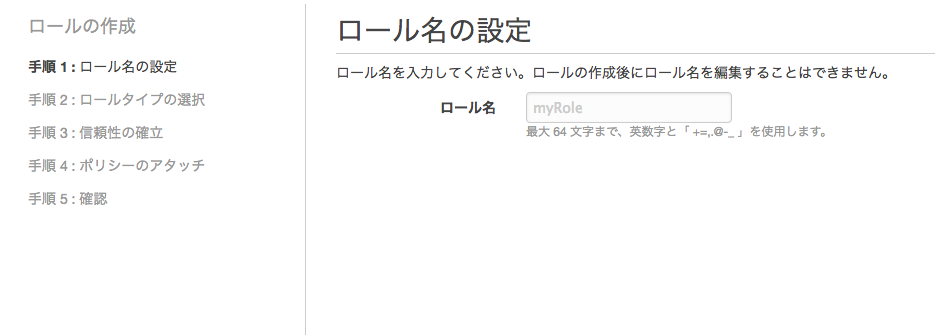
ロールの名前
今回は[lambda_dynamo]
Amazon Lambda >> 選択
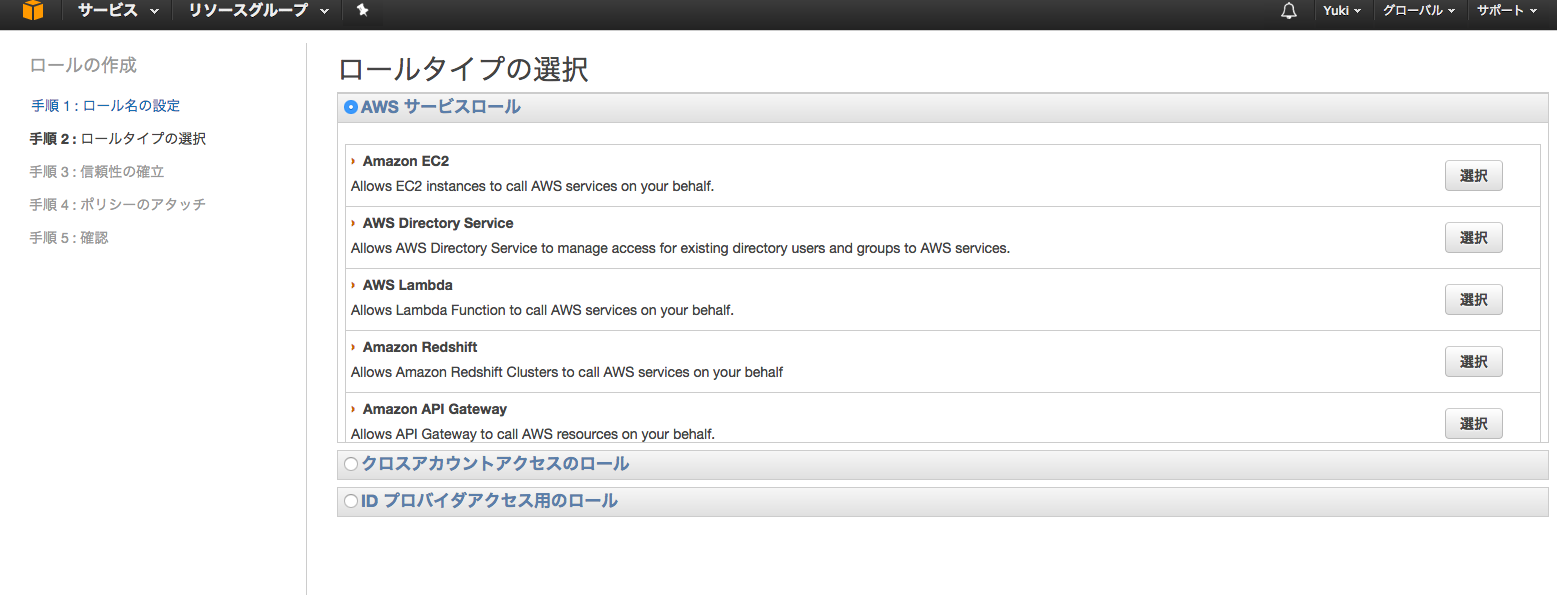
とりあえず今回はFullAccessを3つ付けます。
AWSLambdaFullAccess
AmazonS3FullAccess
AmazonDynamoDBFullAccess
次のステップ
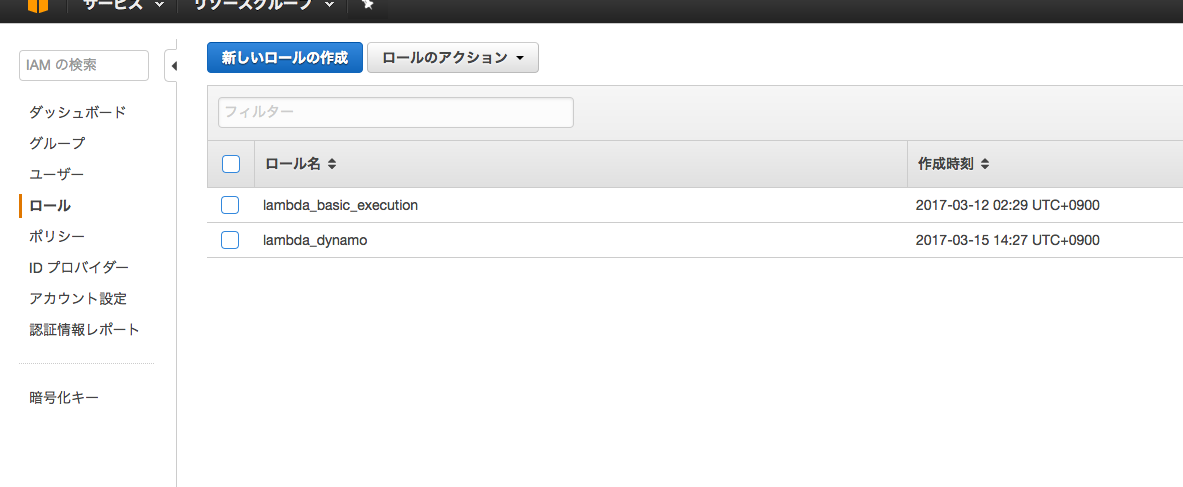
ロール >> lambda_dynamo
といいう項目が追加されてたらOkay。
Lambda
サーバーレスでスクリプト実行できるサービスです。便利。
料金体系
基本的にいくらテストに使っても大丈夫!公式
ラムダ無料枠
| 1ヶ月 | リクエスト | コンピューティング時間 [GB*秒] |
|---|---|---|
| 1,000,000 | 400,000 |
リクエスト:関数全体に対する合計リクエスト数
コンピューティング時間: メモリ数と時間をかけたもの
Lambdaの最小メモリが128MBなので1ヶ月3,200,000秒()使えば、400,000[GB*sec]に到達します。
(128.0[MB] / 1024[MB/GB]) * 3200000[sec] = 400,000[GB*sec]
なので、888時間くらいスクリプト動いても大丈夫。どんどん使おう。
(時間の計算は一応自分でやってみてくださいね!)
テストコードを使ってみる(Pythonエラー)
AWSサービス一覧からLambda
最初の関数作成
Lambda 関数の作成 >> lambda-canary
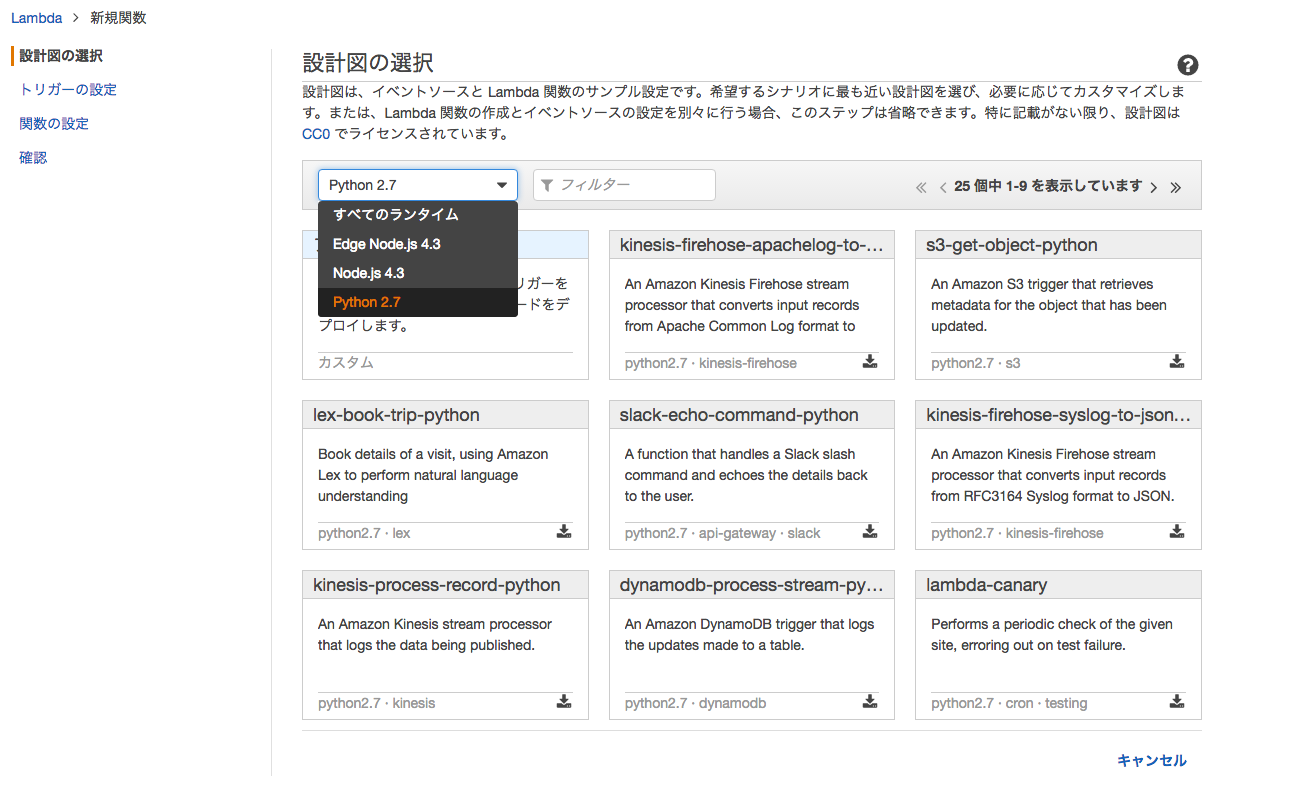
[ トリガーの設定 ] >> 削除 >> 次へ
ここで何分ごとに一度スクリプトを実行とかいじれます。
が後でも設定できるので今回は削除します。
[ 関数の設定 ]
名前をとりあえず[ sample ]にしました。
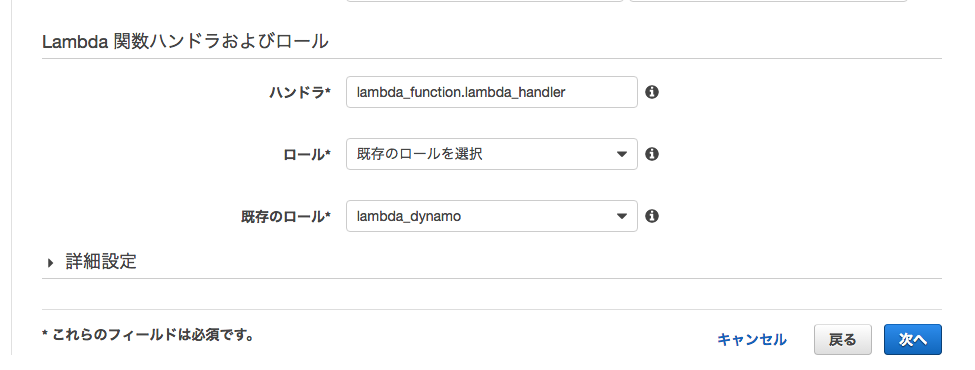
ロールを先程つくったロールにして関数作成します。
lambda_dynamo
最初のテスト
from __future__ import print_function
import os
from datetime import datetime
from urllib2 import urlopen
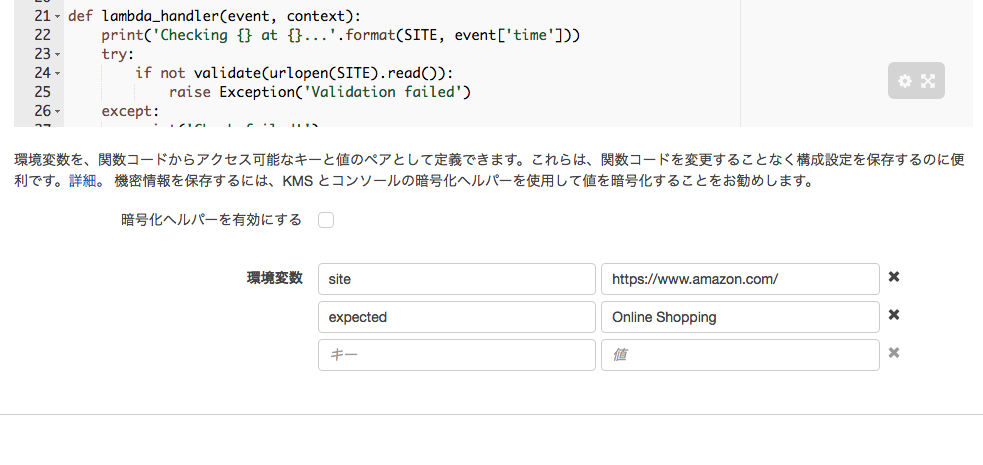
SITE = os.environ['site'] # URL of the site to check, stored in the site environment variable
EXPECTED = os.environ['expected'] # String expected to be on the page, stored in the expected environment variable
def validate(res):
return EXPECTED in res
def lambda_handler(event, context):
print('Checking {} at {}...'.format(SITE, event['time']))
try:
if not validate(urlopen(SITE).read()):
raise Exception('Validation failed')
except:
print('Check failed!')
raise
else:
print('Check passed!')
return event['time']
finally:
print('Check complete at {}'.format(str(datetime.now())))
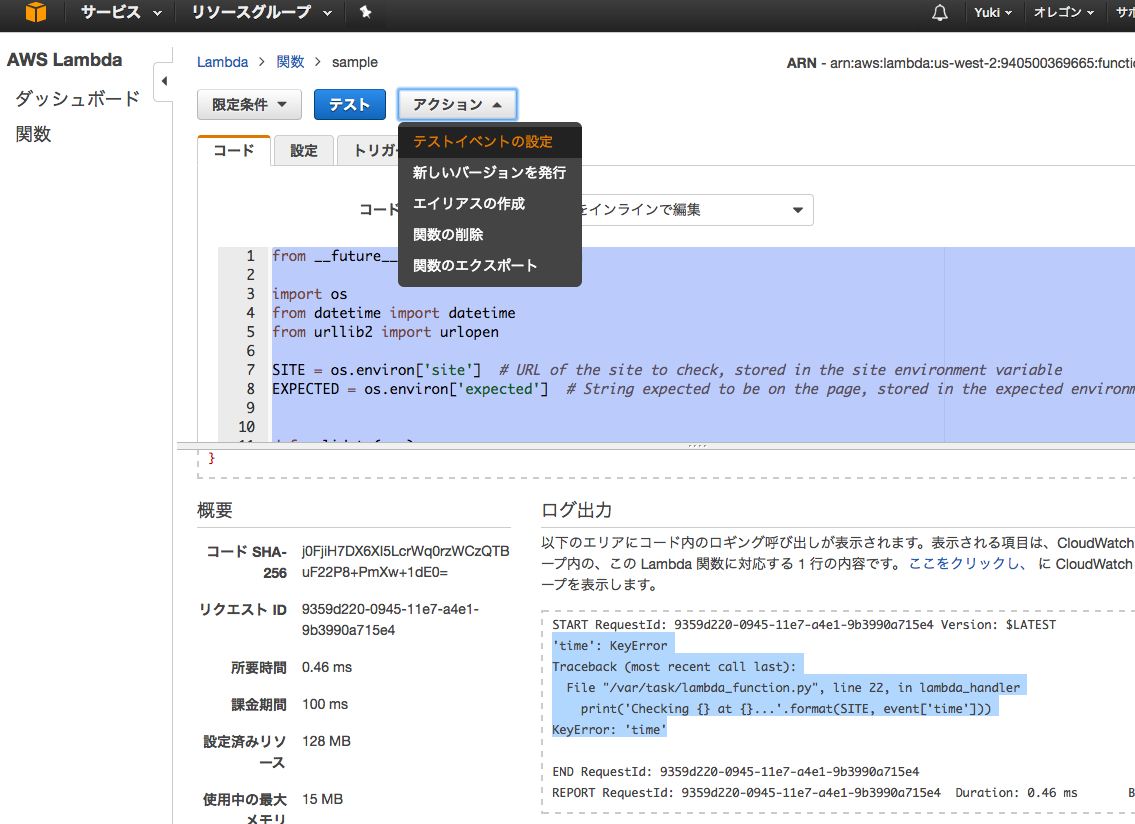
はい出ましたエラー。
print('Checking {} at {}...'.format(SITE, event['time']))
KeyError: 'time'
このエラーを解決する前にデフォルトで使用される変数を見ていきます。
デフォルトで使用される変数
- event - testで設定したところとか、トリガー発生元のイベントデータ
- Context - Context オブジェクト (Python)
- os.environ - コード自体を変更せずに、AWS上で環境変数を設定できる
event >> AWS Lambda はこのパラメーターを使用してイベントデータをハンドラーに渡します。このパラメータは通常、Python の dict タイプです。また、list、str、int、float、または NoneType タイプを使用できます。
context >> AWS Lambda はこのパラメーターを使用してランタイム情報をハンドラーに提供します。このパラメータは LambdaContext タイプになります。
となってます。
os.environで取れるところはこの環境変数
time ?
さて先程のエラーを処理していきます。
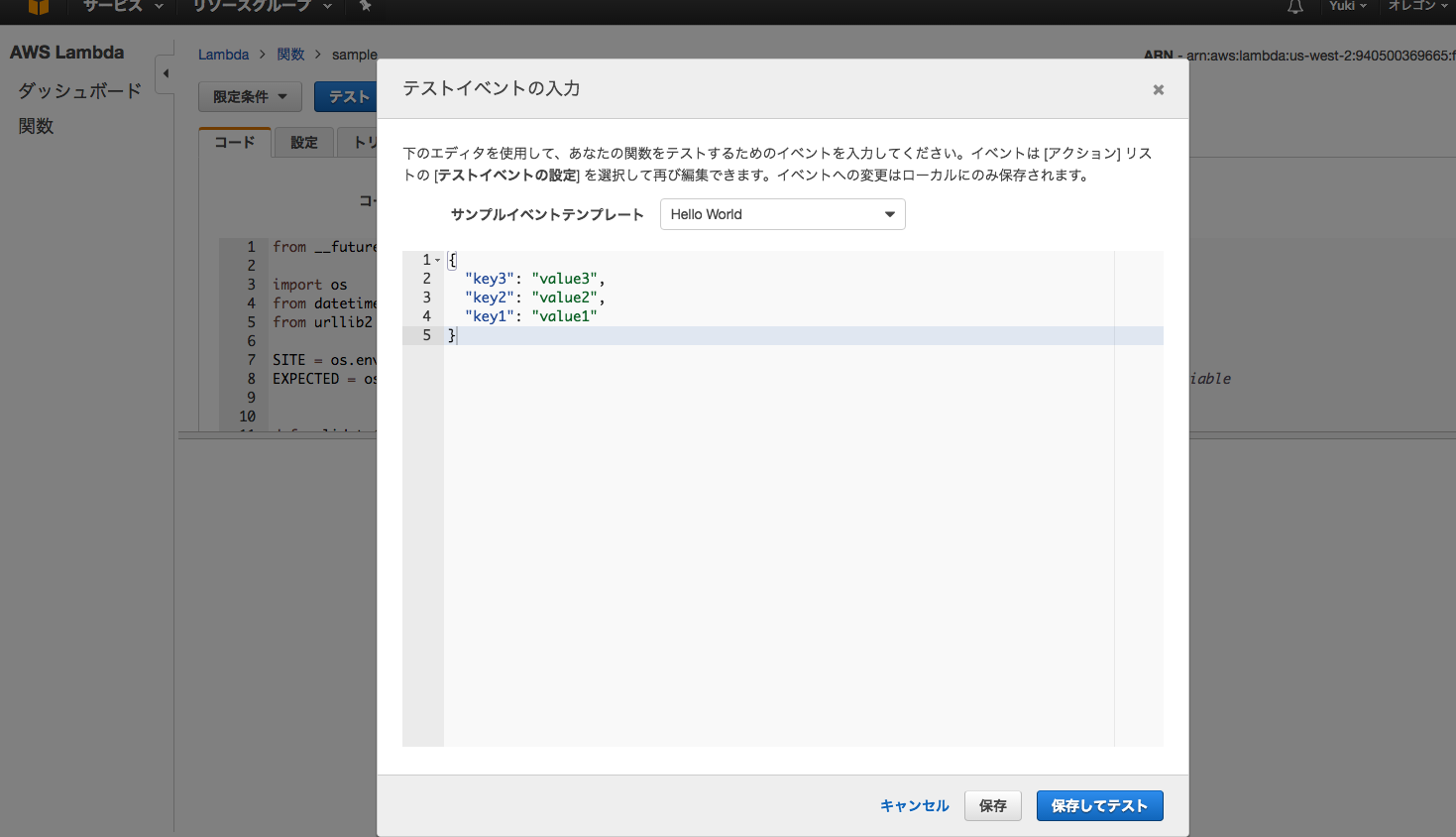
テストイベントの設定のtimeを追加します。
{
"key3": "value3",
"key2": "value2",
"key1": "value1",
"time": "now...!"
}
これでTimeの部分でエラーはでないと思います。
START RequestId: a8708105-0948-11e7-b83e-b71ae2e4dbbe Version: $LATEST
Checking https://www.amazon.com/ at now...!...
Check failed!
Check complete at 2017-03-15 06:28:53.016209
HTTP Error 503: Service Unavailable: HTTPError
Traceback (most recent call last):
(省略)
File "/usr/lib64/python2.7/urllib2.py", line 556, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
HTTPError: HTTP Error 503: Service Unavailable
END RequestId: a8708105-0948-11e7-b83e-b71ae2e4dbbe
REPORT RequestId: a8708105-0948-11e7-b83e-b71ae2e4dbbe Duration: 348.59 ms Billed Duration: 400 ms Memory Size: 128 MB Max Memory Used: 17 MB
まだエラーでるのでいろいろやっていきます。
except例外処理してるのになんでエラーでるねん!
まずは赤い画面でるの嫌なので、urlのリクエスト失敗してもエラーをでなくします。
try:
if not validate(urlopen(SITE).read()):
raise Exception('Validation failed')
except:
print('Check failed!')
raise
Pythonの場合、最後にraiseをいれると、エラーをexceptでキャッチしたのをそのまま素のpython文にエラーを戻しちゃいます。これを書き換えます。
def lambda_handler(event, context):
print('Checking {} at {}...'.format(SITE, event['time']))
try:
if not validate(urlopen(SITE).read()):
raise Exception('Validation failed')
except Exception as e:
print('Check failed!')
print(e)
else:
print('Check passed!')
return event['time']
finally:
print('Check complete at {}'.format(str(datetime.now())))
やっと緑チェックの成功がでました…!!!!
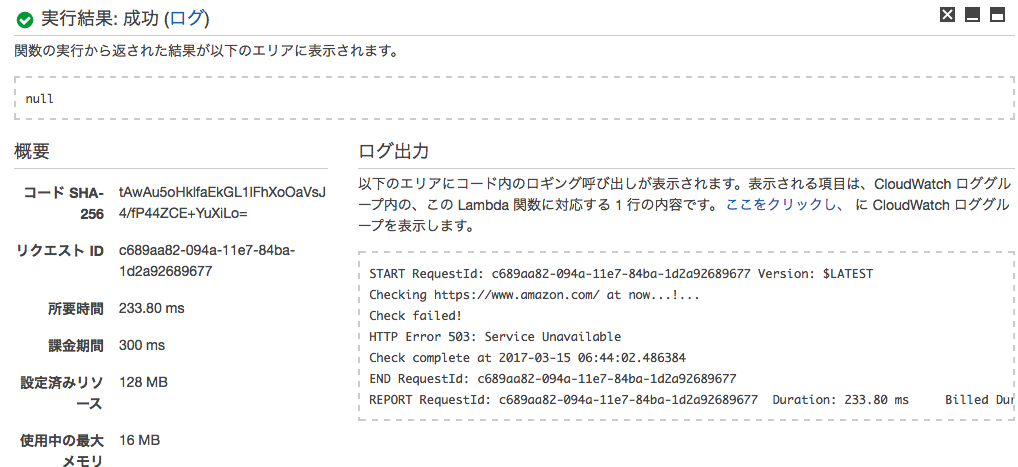
except Exception as e:でエラーをキャッチして
print(e)でエラー出力して
raise削除して、とりあえずはエラーでなくしました。
このあたりのpythonのエラーハンドリングかなり調べました。raise。。
HTTP Error 503
エラーがまだ続いてるのでHTTP Error 503: Service Unavailable: HTTPErrorの部分を見ていきます。
また、Validation failedという文字がないのでvalidate(urlopen(SITE).read())この部分で返ってきたエラーが上記のエラーだと判断していきます。
def validate(res):
return EXPECTED in res
こちらは https://www.amazon.com/ にアクセスして、返ってきたhtmlファイルの中に「Online Shopping」という文字があるかどうかの診断になります。
とりあえずAmazonからGoogleへのアクセスへ、環境変数の変更をする
そうすると
Checking https://www.google.co.jp/ at now...!...
Check passed!
Check complete at 2017-03-15 07:00:05.723916
やっとCheck passed!が出ました。
503 Service Unavailable
サービス利用不可。サービスが一時的に過負荷やメンテナンスで使用不可能である。
例として、アクセスが殺到して処理不能に陥った場合に返される。
https://www.amazon.com/
が落ちるわけないじゃーん。って心のそこから思って環境変数を返してチェックしてみることを失念してました。ただのGoogleサービスに変えたらうまくいきました。
Lambdaからのアクセス拒否してるの?
ハマったところです。
indent
Pythonのエラーですがインデックスの数とかでも何回かエラー出しました。
Syntax error in module 'lambda_function':
unexpected indent (lambda_function.py, line 30)
このあたり勉強したのですが、タブとスペース(4つ)の戦争ですね。
プログラミングのコードを書く時のタブvsスペース戦争がついに決着
pythonはスペースで書くのが一般的だということが書かれてます。
自分がローカルで編集してたファイルがtabで入っていて
AWS上で編集したコードはスペース4つで入ります。
このindentエラーを見たくないのでスペース派に乗り換えました。
Requests
urlopenをそのまま使ってもいいのですがrequestsを導入したいと思います。
python urllib2モジュール
Requests: 人間のためのHTTP
Requestsを使わずに同じ事をするためのコード
slackとかにメッセージ送るのが簡単になります。
# coding: utf-8
from __future__ import print_function
import os
import json
import requests
from datetime import datetime
from urllib2 import urlopen
SITE = os.environ['site']
EXPECTED = os.environ['expected']
def validate(res):
return EXPECTED in res
def lambda_handler(event, context):
print('Checking {} at {}...'.format(SITE, event['time']))
try:
if not validate(urlopen(SITE).read()):
raise Exception('Validation failed')
except Exception as e:
print('Check failed!')
print(e)
else:
print('Check passed!')
finally:
print('Check complete at {}'.format(str(datetime.now())))
return "Finish"
Unable to import module 'lambda_function': No module named requests
requestsは外部モジュールなのでこんなエラーおきます。
外部モジュールの使用
requestsみたいなPython標準外のモジュールを入れるのにも一癖あったので書いていきます。
- lambda-uploaderを使ってリモート
- ローカルで自分でzipにかためてUP
lambda-uploader
このあたりが参考になります。
lambda-uploaderを使ってAWS Lambdaをリモートで開発、実行、デプロイする
AWS Lambda Pythonをlambda-uploaderでデプロイ
自分のコードをZIPアップロード
自分はこれで行いました。単発だとすぐできる。
【AWS】Lambdaでpipしたいと思ったときにすべきこと
作業フォルダにpip install requests -t .して、それをzipで固めてアップする感じです。
無事アップロードできたら、先程の今のコード.pyからスタートします。
Slack
import
- urllib2
- requests
- どっちでも可
api
- Slack api(token取得してごにょごにょ xoxp-12131212こんなやつ)
- Webhook(urlだけ取ってくる)
- どっちでも可
どの組み合わせを使っても良いのですが、今回は簡単なrequests * Webhookを使います。
こちらWebhookのURL取得はこちらを参考に!
SlackのWebhook URL取得手順
def send_slack(text):
url = "先程げっとしたURL"
payload_dic = {
"text":text,
"icon_emoji":':grin:',
"channel":'bot-test2',
}
r = requests.post(url, data=json.dumps(payload_dic))
たったこれだけでSlack送れます!
# coding: utf-8
from __future__ import print_function
import os
import json
import requests
from datetime import datetime
from urllib2 import urlopen
SITE = os.environ['site']
EXPECTED = os.environ['expected']
def validate(res):
return EXPECTED in res
def web_check():
try:
if not validate(urlopen(SITE).read()):
raise Exception('Validation failed')
except Exception as e:
print('Check failed!')
print(e)
else:
print('Check passed!')
finally:
print('Check complete at {}'.format(str(datetime.now())))
def lambda_handler(event, context):
print('Checking {} at {}...'.format(SITE, event['time']))
# web_check()
send_slack("test")
return "success!"
def send_slack(text):
url = "こちら自分のURL"
payload_dic = {
"text":text,
"icon_emoji":':grin:',
"channel":'bot-test2',
}
r = requests.post(url, data=json.dumps(payload_dic))
def web_check():に処理を移して置きました。
def lambda_handler(event, context):
print('Checking {} at {}...'.format(SITE, event['time']))
# web_check()
send_slack("test")
return "success!"
これで
 Slack到着しました。
Slack到着しました。
Okay。
次はDynamoDBからデータを取ってきます。
DynamoDB
料金体系
AWS の無料利用枠の一部としてのDynamoDB無料枠
| ストレージ | 書き込み容量 | 書き込み容量 |
|---|---|---|
| 25GB | 25 | 25 |
1 つの容量のユニットで 1 秒あたりに 1 つのリクエストを処理します
1ユニットの書き込み容量: 最大1KBデータを1秒に1書き込み
1ユニットの読み込み容量: 最大4KBデータを1秒に1読み込み
DynamoDB ストリームからの 250 万回の読み込みリクエストを無料で利用できます。
とりあえずデータベースを作る時に書き込み容量と読み込み容量を1にセットして使えば、無料枠だとお金かからないと思います。
今回は1分に1度くらいでもいいので、最小単位の1(1秒に1度アクセスできるレベル)を選びます。
作ってみる
とりあえず設定はこんな感じ。
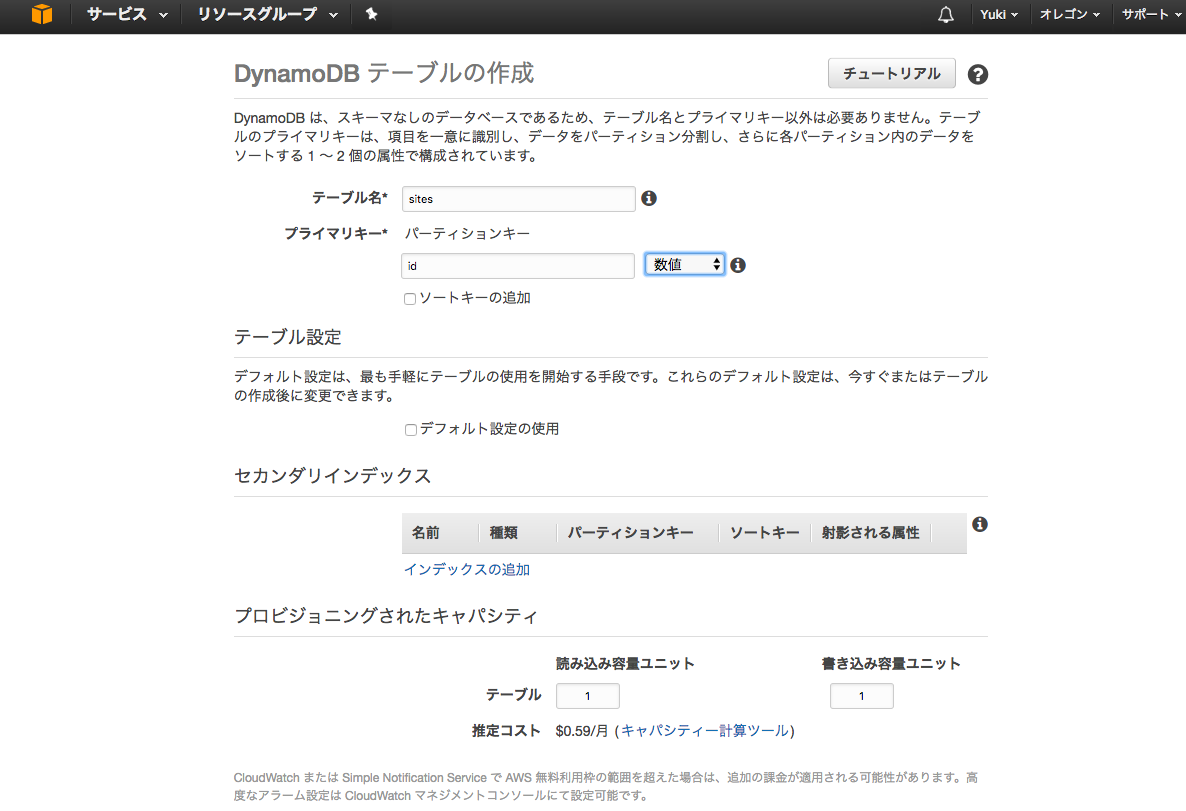
DynamoDBはハッシュ(言語によっては辞書型、連想配列など)のKeyでしかアクセスできません。今回はidをkeyとしてアクセスします。
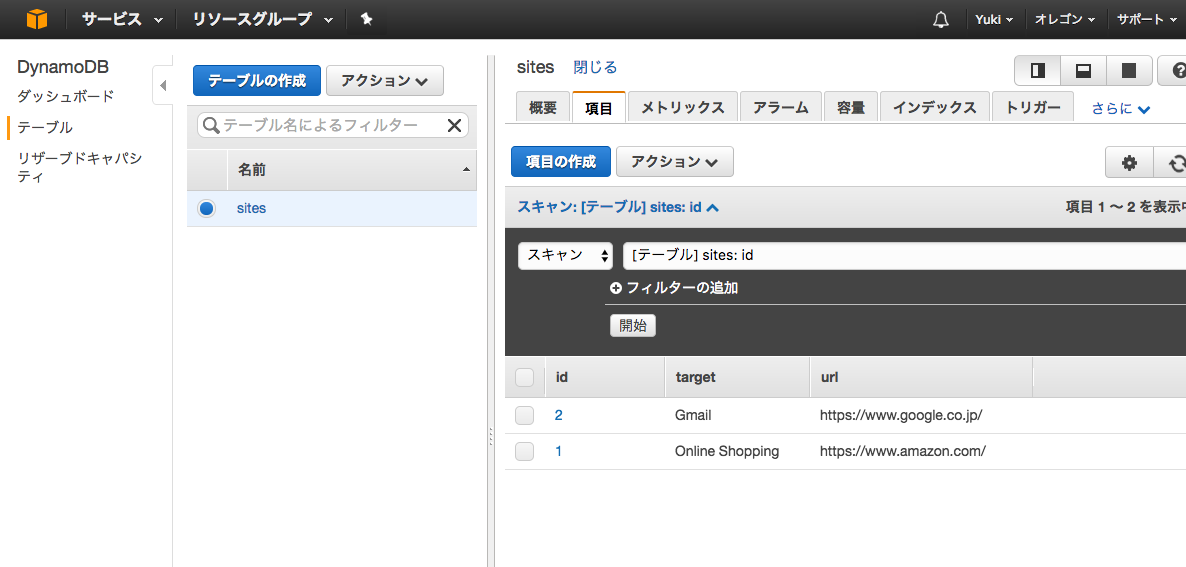
{
"id": 1,
"target": "Online Shopping",
"url": "https://www.amazon.com/"
}
{
"id": 2,
"target": "Gmail",
"url": "https://www.google.co.jp/"
}
urlからtargetを探すためのTableとして使います。
pythonコードから先程のデータを取ってみる
# 2つ追加
import boto3
from boto3.dynamodb.conditions import Key, Attr
def get_urls():
table = dynamodb.Table('sites')
response = table.scan()
sites = response["Items"]
return sites
機能を追加して、get_urls()でDynamoDBから取ってきたurlからtargetの文章があるかサーチしています。
# coding: utf-8
from __future__ import print_function
import os
import json
import requests
from datetime import datetime
from urllib2 import urlopen
import boto3
from boto3.dynamodb.conditions import Key, Attr
dynamodb = boto3.resource('dynamodb')
def validate(res, target):
return target in res
def web_check(url, target):
print("Serching ... " + target)
try:
if validate(urlopen(url).read(), target):
print("Find!")
else:
print("Not Find!")
except Exception as e:
print('Error')
print(e)
def get_urls():
table = dynamodb.Table('sites')
response = table.scan()
sites = response["Items"]
return sites
def send_slack(text):
url = "https://hooks.slack.com/services/"
payload_dic = {
"text":text,
"icon_emoji":':grin:',
"channel":'bot-test2',
}
r = requests.post(url, data=json.dumps(payload_dic))
def lambda_handler(event, context):
print('Check start')
sites = get_urls()
for site in sites:
web_check(str(site["url"]), str(site["target"]))
return "success!"
出力結果
Check start
Serching ... 技術情報共有サービスです at https://qiita.com/
Find!
Serching ... Gmail at https://www.google.co.jp/
Find!
Serching ... Gmailですか? at https://www.google.co.jp/
Not Find!
Serching ... Online Shopping at https://www.amazon.com/
Error
HTTP Error 503: Service Unavailable
END RequestId: 3992d81e-095e-11e7-b30a-1ddc7da9e992
ここでもエラーおきました。Pythonつまづく!
'utf8' codec can't decode byte 0x90 in position 102: invalid start byte
PythonのUnicodeEncodeErrorを知る
ここを参考にエラー解決しました。
type(site["url"])したら<type 'unicode'>だったので、
str(site["url"])をして<type 'str'>に変えました。
LambdaからDynamoDB書き込み
sites_check1テーブルの追加
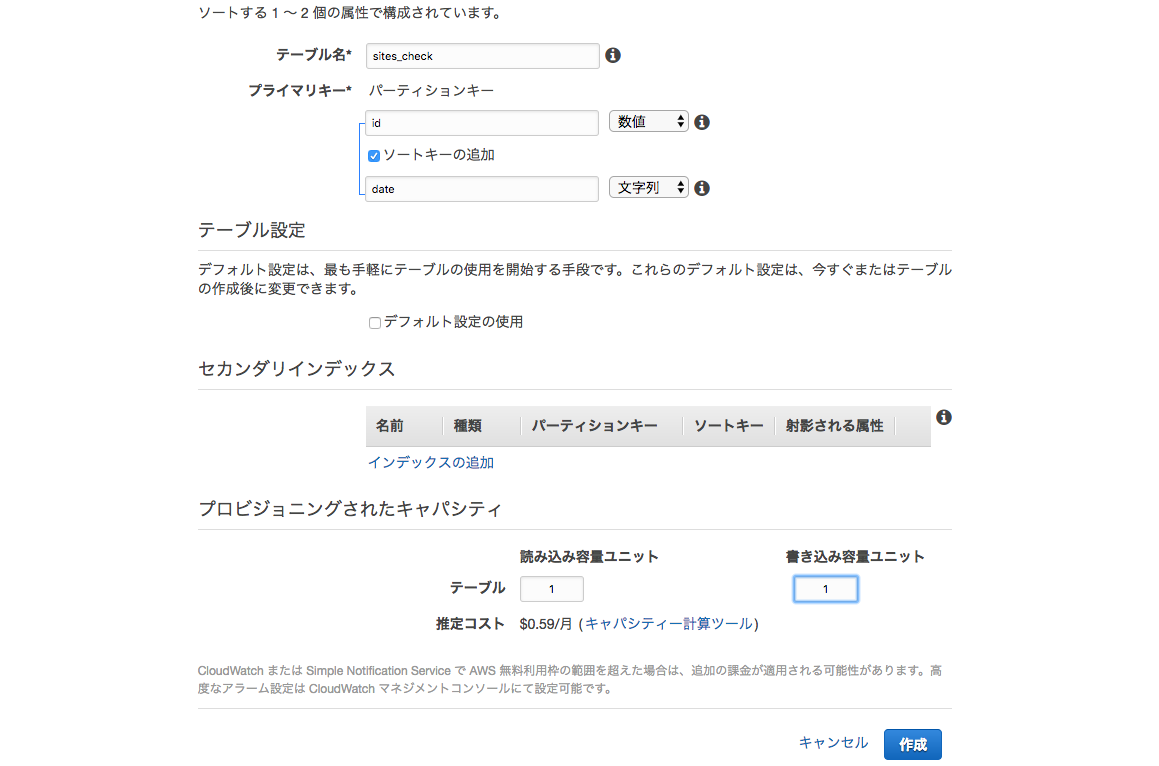
追加
from datetime import datetime, timedelta
def insert(results):
date = datetime.now() + timedelta(hours=9)
id = 0
table = dynamodb.Table('sites_check')
table.put_item(
Item={
"id": id,
"date": date.strftime("%Y/%m/%d %H:%M"),
"result": results
}
)
時間の増減を行うtimedeltaとかを追加しました。
DynamoDBのsitesテーブルにタイトル追加しました。
現在のコード
# coding: utf-8
from __future__ import print_function
import os
import json
import requests
from datetime import datetime, timedelta
from urllib2 import urlopen
import boto3
from boto3.dynamodb.conditions import Key, Attr
dynamodb = boto3.resource('dynamodb')
def validate(res, target):
return target in res
def web_check(url, target):
print("Serching ... " + target + " at " + url)
try:
if validate(urlopen(url).read(), target):
return "Find!"
else:
return "Not Find!"
except Exception as e:
return str(e)
def get_urls():
table = dynamodb.Table('sites')
response = table.scan()
sites = response["Items"]
return sites
def send_slack(text):
url = "https://hooks.slack.com/"
payload_dic = {
"text":text,
"icon_emoji":':grin:',
"channel":'bot-test2',
}
r = requests.post(url, data=json.dumps(payload_dic))
def insert(results):
date = datetime.now() + timedelta(hours=9)
id = 0
table = dynamodb.Table('sites_check')
table.put_item(
Item={
"id": id,
"date": date.strftime("%Y/%m/%d %H:%M"),
"result": results
}
)
def lambda_handler(event, context):
print('Check start')
results = {}
sites = get_urls()
for site in sites:
msg = web_check(str(site["url"]), str(site["target"]))
results[str(site["title"])] = msg
insert(results)
return "success!"
データを挿入した結果がこちら。
{
"date": "2017/03/15 18:37",
"id": 0,
"result": {
"Amazon": "Find!", # なぜかFindとなってエラー起きず
"Google": "Find!",
"Google-2": "Not Find!",
"Qiita": "Find!"
}
}
{
"date": "2017/03/15 18:48",
"id": 0,
"result": {
"Amazon": "HTTP Error 503: Service Unavailable", # こちらでエラー起きたときにstr(e)にしました
"Google": "Find!",
"Google-2": "Not Find!",
"Qiita": "Find!"
}
}
str(e)ってしないとeがstr型じゃないのでエラーが起きました。
Pythonに慣れてきたので10分くらいで解決。
jsonってコメントつけられないんですね。
def get_recent_codes():
date = datetime.now() + timedelta(hours=9)
now = date.strftime("%Y/%m/%d %H:%M")
last = (date + timedelta(minutes=-9)).strftime("%Y/%m/%d %H:%M")
# idが0かつ、10分以内のデータを取ってくる感じのクエリ
response = table.query(
KeyConditionExpression=Key('id').eq(0) & Key('date').between(last, now)
)
return response
response['Count']に取ってこれたクエリの数が入ります。
response['Items']に取ってこれたTableのデータがはいってます。
それ以外のデータ必要な場合は適宜、Printしつつデータの取り出しをしてください。
結果こんな感じ
# coding: utf-8
from __future__ import print_function
import os
import json
import requests
from datetime import datetime, timedelta
from urllib2 import urlopen
import boto3
from boto3.dynamodb.conditions import Key, Attr
dynamodb = boto3.resource('dynamodb')
def validate(res, target):
return target in res
def web_check(url, target):
print("Serching ... " + target + " at " + url)
try:
if validate(urlopen(url).read(), target):
return "Find!"
else:
return "Not Find!"
except Exception as e:
return str(e)
def get_urls():
table = dynamodb.Table('sites')
response = table.scan()
sites = response["Items"]
return sites
def send_slack(text):
url = "https://hooks.slack.com/"
payload_dic = {
"text":text,
"icon_emoji":':grin:',
"channel":'bot-test2',
}
r = requests.post(url, data=json.dumps(payload_dic))
def insert(results):
table = dynamodb.Table('sites_check')
date = datetime.now() + timedelta(hours=9)
id = 0
table.put_item(
Item={
"id": id,
"date": date.strftime("%Y/%m/%d %H:%M"),
"result": results
}
)
def get_recent_codes():
table = dynamodb.Table('sites_check')
date = datetime.now() + timedelta(hours=9)
now = date.strftime("%Y/%m/%d %H:%M")
last = (date + timedelta(minutes=-9)).strftime("%Y/%m/%d %H:%M")
print(last + " から " + now + " までのチェック")
response = table.query(
KeyConditionExpression=Key('id').eq(0) & Key('date').between(last, now)
)
return response
def lambda_handler(event, context):
print('Check start')
results = {}
sites = get_urls()
for site in sites:
msg = web_check(str(site["url"]), str(site["target"]))
results[str(site["title"])] = msg
insert(results)
print(get_recent_codes())
return "success!"
定期実行させたりいろいろできると思われます。
さいごに
PythonとLambdaの素人なのでかなりエラーだしました。が、PythonとLambdaによるアーキテクトはかなり便利になると思うのでこれからも使っていきたいと思っています。