こんにちは。からっきーです。
IoTLT Advent Calendar 2017の7日目の記事です!
先週ラスベガスで開催されたAWSのカンファレンスre:Inventに参加してきました。
キーノートではたくさんの新サービスや新機能が発表されて盛り上がっていたことをご存じの方もいるかもしれませんが、その中でAWS DeepLensというものも発表されました。
DeepLensはサービス名でもあり、そのサービスで使用するデバイス名でもあります。
これを使うことでなにが嬉しいのかを簡単に説明すると、カメラで撮影した映像のエッジ解析をよりビジネスロジックに集中して実現することができる、といったところでしょうか。
ハードウェアの設計、セッティング、学習モデルのデプロイ、クラウドとの連携といった部分をAWSでマネージしてくれていて、開発者は学習モデルの開発と解析したデータの使い方を考えることに注力できます。
未発売!これが激レアのDeepLens
DeepLensデバイスはre:Inventで実施されたワークショップに参加した人だけに配布されたもので、なかなかレア度が高いです。
日本にも数個しか存在していないのでは・・
実際のブツはこんな感じ。
下の部分がコンピュータになっていて上にでている黒い部分がカメラです。

なんとも愛着の湧くフォルムをしたこの子ですが、中身は立派なコンピュータ。

Amazon.comでは2018/4/14に発売開始されるそうでお値段は$249!!
商品ページ
学習モデル、ファンクション、出力データ
機器の初期セットアップはこちらを参考にしてみてください。
セットアップが終わったら、あとは学習モデルとファンクションをDeepLensに流し込むだけです。
学習モデルは、こちらもre:Inventで新しく発表されたSageMakerというものを使ってよりシンプルに作れるようになったみたいです。しかしながらまだ学習モデルを作るというところまで私ができないため、最初から幾つか用意されているサンプルを使用します。
ファンクションは、学習モデルの実行と、推論した結果をどうするのか、ということが書かれたLambda Functionです。
推論されたデータアウトプットは、AWSのブログを見ると、AWS IoTにパブリッシュしたり、S3に保存したり、映像をkinesisに流し込んだりなどしてますね。
サンプルプロジェクトを試してみる!
AWSコンソールからDeepLensのページに行くと、予め以下のプロジェクトが使えるようになっています。
- Object detection
- 20種類のオブジェクトを検出します
- Artistic style transfer
- ゴッホが描いた絵っぽくします
- Face detection
- 顔を検出します
- Hotdog recognition
- ホットドッグなのか、そうじゃないのかを識別します
- Cat and dog recognition
- 犬なのか猫なのかを識別します
- Action recognition
- 30種類以上の動きを識別します
順番に試していきます!!
なお、カメラに写すものを実際に用意するのはしんどいのでブラウザで画像検索したものをDeepLensで撮影します。
リアルタイムに解析されて、モニターに出力された映像と、AWS IoTに解析結果が出力されるようになっているものについてはサブスクライブしたデータを記載します。
Object detection
検出できるのは下記のオブジェクト
aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, dinning table, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor
モニター映像
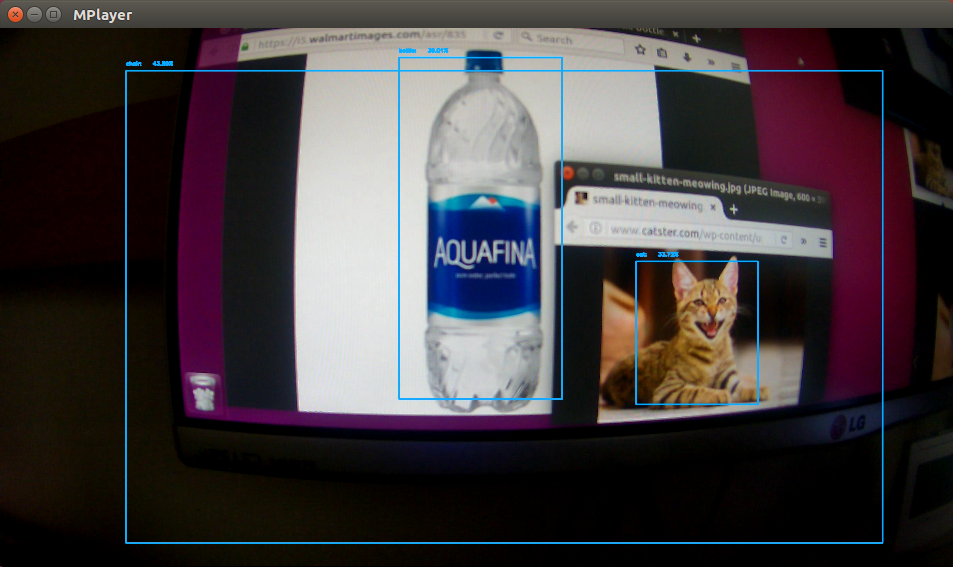
AWS IoTでサブスクライブしたデータ
{
"bottle": 0.39,
"cat": 0.27,
"chair": 0.44,
"tvmonitor": 0.35,
"null": 0
}
Artistic style transfer
モニター映像
左側がもとの画像、右側が出力結果です。
(これがゴッホの絵っぽいのかはちょっとよくわからない・・)
Face detection
モニター映像

AWS IoTでサブスクライブしたデータ
検出されている時
{
"1": 0.45,
"null": 0
}
検出されていない時
{
"null": 0
}
Hotdog recognition
モニター映像
ホットドッグじゃない時
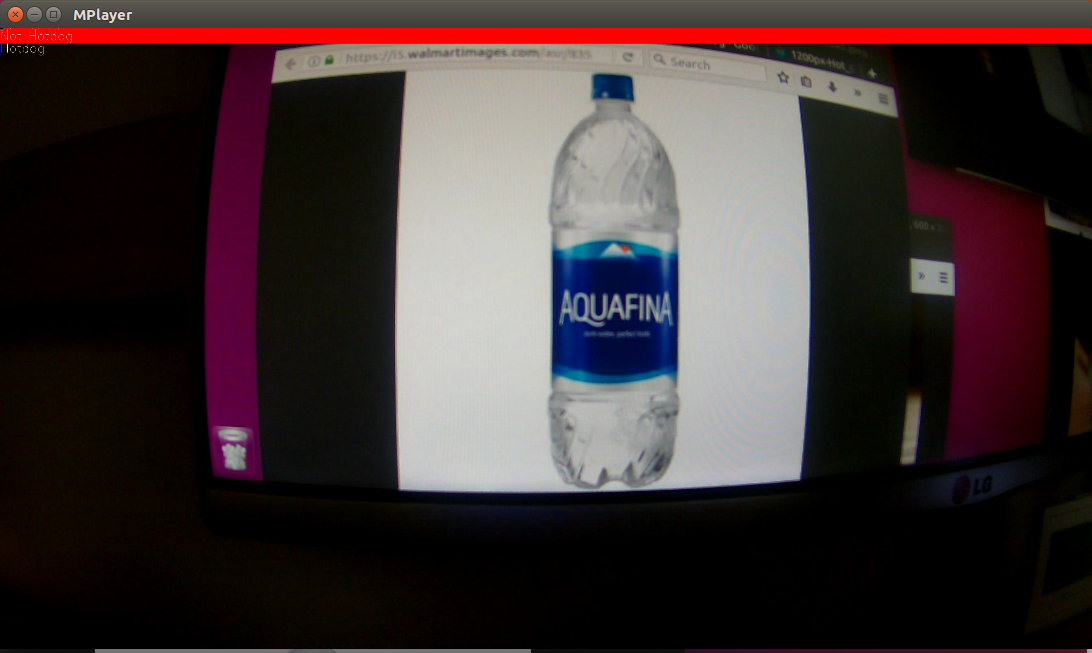
ホットドッグと識別されると青のインジケーターがぐいーん

AWS IoTでサブスクライブしたデータ
{
"Hotdog": 0.800466954708,
"Not Hotdog": 0.199533045292
}
re:InventのDeepLensワークショップではこちらのサンプルを使用しました。
AWS IoTでHotdogというキーワードを拾って、その値をイベントにしてLambdaをフックし、値が0.6以上だったらスマホのSMSに通知する、といった内容でした。
公式ブログ
このホットドッグネタ、現地の方に聞いたところあるドラマでのネタらしく、向こうの人ならわかるやつとのことでした。
調べてみたらその部分がYouTubeに上がっていました。納得。
https://www.youtube.com/watch?v=ACmydtFDTGs
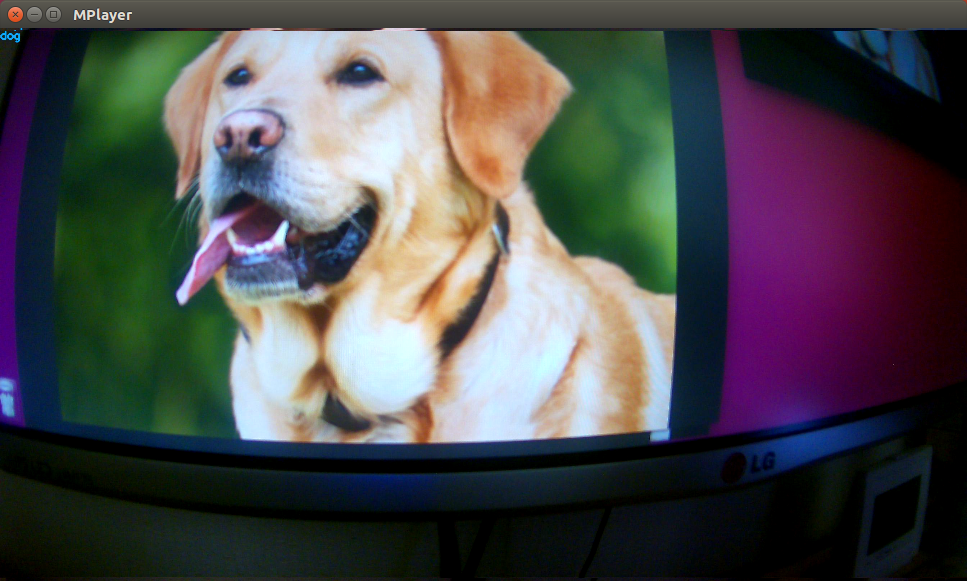
Cat and dog recognition
モニター映像
猫(左上にちっちゃくcat)
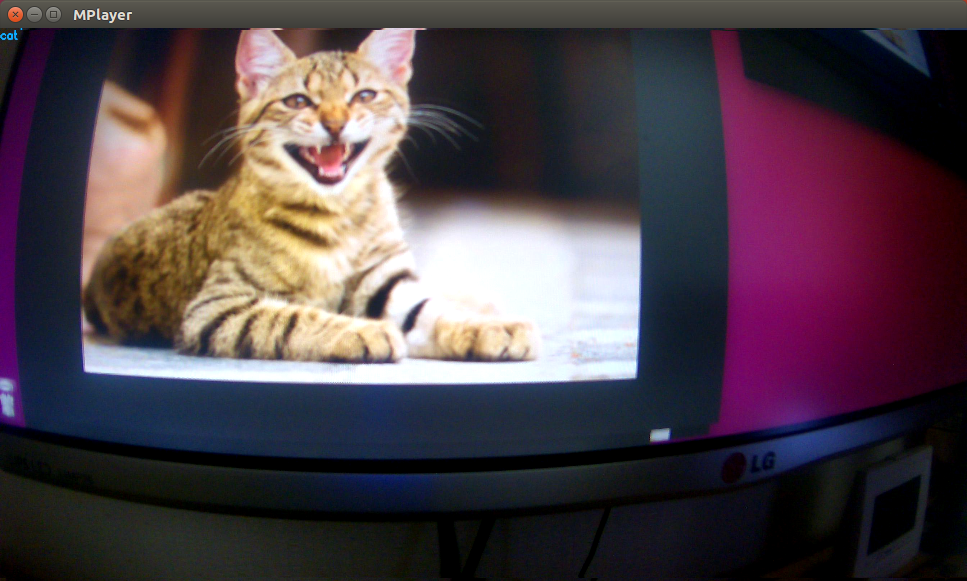
犬(左上にちっちゃくdog)
AWS IoTでサブスクライブしたデータ
猫の時
{
"cat": 0.991203427315,
"dog": 0.00879661552608
}
犬の時
{
"dog": 0.965661048889,
"cat": 0.0343389473855
}
Action recognition
識別できるのは下記の動き
applyeyemakeup, applylipstick, archery, basketball, benchpress, biking, billiards, blowdryhair, blowingcandles, bowling, brushingteeth, cuttinginkitchen, drumming, haircut, hammering, handstandwalking, headmassage, horseriding, hulahoop, jugglingballs, jumprope, jumpingjack, lunges, nunchucks, playingcello, playingflute, playingguitar, playingpiano, layingsitar, playingviolin, pushups, shavingbeard, skiing, typing, walkingwithdog, writingonboard, yoyo
モニター映像
(左上にちっちゃくhorseriding)

AWS IoTでサブスクライブしたデータ
{
"horseriding": 0.86,
"lunges": 0.14,
"pushups": 0,
"handstandwalking": 0,
"hulahoop": 0
}
まとめ
今回サンプルプロジェクトを使用しましたが、なんとなくDeepLensを使ってどんなことができるのかがイメージできたのではないでしょうか。
今後はSageMakerでモデルを作って遊んだりしてみたいです。