こんにちは。わいけいです。
今回の記事では、生成AI界隈ではかなり浸透している RAG について改めて解説していきます。
「低予算で言語モデルを使ったアプリを開発したい」というときに真っ先に選択肢に上がるRAGですが、私自身もRAGを使ったアプリケーションの実装を業務の中で何度も行ってきました。
今回はその知見をシェア出来れば幸いです。
RAG(Retrieval-Augmented Generation)とは
まず、 そもそもRAGとは何ぞや? というところから見ていきましょう。
RAG(Retrieval-Augmented Generation) は自然言語処理(NLP)と特に言語モデルの開発において使用される技術です。
この技術は、大規模な言語モデルが生成するテキストの品質と関連性を向上させるために、外部の情報源からの情報を取得(retrieval)して利用します。
要は、ChatGPTなどの言語モデルに特殊な知識に関連した情報を喋らせる技術だと言えますね。
皆さんご存知の通り、ChatGPTなどの大規模言語モデル(LLM)は、人間と遜色ないレベルで自然言語を話すことが出来ます。
しかし、例えば
「わいけいという人物の好きな食べ物は?」
と質問してもChatGPTは(当然のことながら)答えることが出来ません。
これは、ChatGPTの学習データに含まれない情報について質問しているからです。
しかし、既存のデータベースなどから何らかの方法で
「わいけいの好きな食べ物はカレーです。」
という情報を事前に取得できていれば話は違ってきます。
この場合、以下のように他のDBからとってきた情報を組み込んだプロンプトをChatGPTに投げることで正しい答えを得ることが来ます。
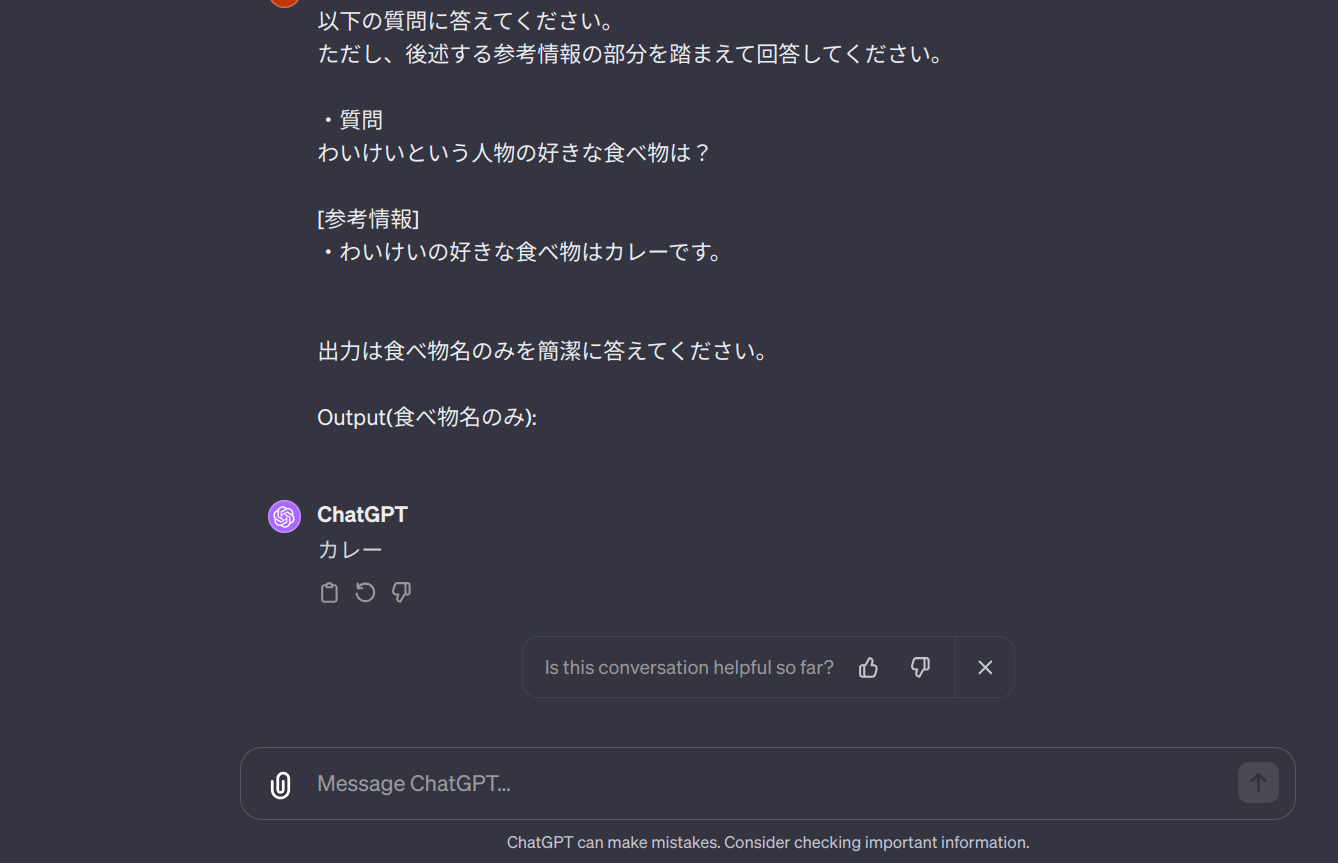
以下の質問に答えてください。
ただし、後述する参考情報の部分を踏まえて回答してください。
・質問
わいけいという人物の好きな食べ物は?
[参考情報]
・わいけいの好きな食べ物はカレーです。
出力は食べ物名のみを簡潔に答えてください。
Output(食べ物名のみ):
このように質問することでGPTは「カレー」という回答をすることが出来ます。
RAGが有効なアプリケーション
以上の概要からも分かるとおり、RAGは大元の言語モデルに含まれないような独自の知識を自然言語としてユーザーに返すことが求められるアプリケーション開発に活用できます。
例えば、以下のような例が挙げられます。
- 社内資料に関する情報を答えるチャットボット
- 特殊な業界用語に対応したチャットボット
- カスタマー対応用のチャットボット
他にもまだまだあるでしょう。
そもそも現実にアプリケーションを開発する際には、(翻訳アプリなどを除いて)一般的な知識だけをLLMに喋らせておけばOKというケースはあまりありません。
むしろ、ユーザーデータや社内データなどのクローズドなデータに関することを喋らせたい場合が多いはずです。
RAGの注目度が高いのには、こういった背景があります。
RAGのメリット
次にRAGのメリットとデメリットを見ていきましょう。
まず、メリットとして挙げられるのが、
- 低コストで実行できる
- 既存の言語モデルを活用しているので基盤性能が高い
という点です。
前提として、RAGではなく独自の学習データを混ぜ込んで新たにイチから大規模言語モデルを研究・設計・訓練しようとすると、GPUサーバーの購入や専門知識を持ったエンジニアの雇用などで低く見積もっても億単位の投資が必要になります。
(私が勤務する会社の例でもサーバーの購入費用は億単位でした。)
既存モデルのfine-tuningを行うに留める、といった選択肢を取ったとしてもプロダクションレベルのクオリティに達するには時間的にも金銭的にも大きなコストを要求されることになります。
さらに、それだけの投資をしたとしても既存のGPT3.5, GPT4やGemini proに匹敵する精度のLLMを学習させるのは非常に難易度が高いです。
以上の背景から、個人の場合は2024年2月現在だとまず独自LLMを学習させるのはコスト的にそもそも無理な話で、多かれ少なかれRAGに頼らざるを得ない状況です。
また、法人であってもさすがにいきなり数十億〜数百億円のレベルでの投資には踏み切れない、という企業も多いでしょう。
そこで、取り敢えずRAGを使ってPOCをしてみよう、というパターンが多いです。
例えばOpenAIの gpt-3.5-turbo-0125 モデルでは1000トークンの使用で
Inputが 0.0005ドル 、outputが 0.0015ドル となっています(2024/02)。
仮に日本語1文字を1.5トークンだとすると、入力・出力でそれぞれ1万文字ずつ使った場合でも課金額は0.03ドルです。
ドル円が150円/USDだとするとこれは4.5円に相当します。
このようにRAGは価格面で非常に始めやすいことがメリットです。
また、多くの場合RAGに組み込むのはGPTなどの既存LLMになると思いますが、 これらは低価格で使用できるのにも関わらず性能は桁違いに高い です。
ひと握りの組織以外は、そもそも普通に言語モデルに言葉を喋らせるという部分においてOpenAIやGoogleが開発しているモデルを超える性能を出すことは難しいでしょう。
RGAのデメリット
一方でRAGにはデメリットもあります。
- 既存データを検索する仕組みづくりが必要
- 処理に時間がかかることがある
- プロンプトに工夫が求められる
- セキュリティ要件に引っかかる可能性がある
まず、RAGを使う場合はLLMに与える参照データを検索するシステムが存在している必要があります。
冒頭の例であれば、ユーザーから
わいけいという人物の好きな食べ物は?
という質問が来たときに、
わいけいの好きな食べ物はカレーです。
という情報を検索して持ってこれるような仕組みが必要です。
一般的にLLMに入力できるプロンプトの長さ(トークン長)には制限があるので、甘く見積もっても検索結果上位10件くらいに正しい情報が入っていないとキツイ場合が多いでしょう。
また、例えば社内質問ボットなどを作りたい場合、検索対象にしたいデータが社内に散財していて検索用データベースかするのがそもそも難しい、というケースもあります。
こういった場合、どうしても泥臭い検索エンジン作りの工程が発生してしまいます。
そして、実務ではこの検索システムの精度を出すのが中々難しいものです。
例えば私が以前取り組んだ例ではRAG全体としてうまく機能しなかったケースの内の7割程度で適切なデータ検索に失敗していました。
同業者の話を聞いても状況は似たりよったりであるケースが多く、RAGでは検索精度を担保することが一つのキーポイントになると思われます。
また、LLMをただ喋らせるだけでなくその前段に関連データの検索処理が入るのでシステム全体としての安定性や速度が低下します。
特に、現状ユーザーからのクエリ(問いかけ内容)に対して意味的に近いデータを引っ張ってくるためにOpenAIEmbeddingsなどの機械学習されたモデルでユーザークエリをベクトル化するケースが多いのですが、この辺りの処理を行う際コンマ何秒かの時間的ロスを考慮する必要があります。
時間的要件が厳しいワークロードの場合は注意が必要です。
さらに、プロンプトに工夫が求められることが多いのもデメリットと言えるかもしれません。
例えば検索用の情報をwebスクレイピングなどで雑に作っていた場合、RAGで検索してきたデータが完全な自然文になっていないことも多いです。
例えば、
「わいけいという人物はネオミミコというAI秘書のLINE公式アカウントを運営している」
という完全な文ではなく
「ネオミミコ 運用の話!〜〜わいけい〜〜」
という微妙な文章(チャンク)を検索してきてGPTに渡した結果、出力が崩壊するというパターンなどが挙げられます。
ちなみにこういった場合、プロンプトに
以下の参照情報はwebからスクレイピングして来たものです。
そのため日本語として不完全な形式になっている可能性がありますが、その場合でも正確な日本語を出力するよう注意してください。
参照情報として意味が取れないものは無視して構いません
などといった文言を組み込むと出力が改善することも多いです。
最後に、RAGを使う際(というか正確にいうと既存の言語モデルを使ってアプリ作成する時全般)はセキュリティ的な要件に引っかかることも多いです。
RAGで既存のLLMを使用する場合、海外サーバー(OpenAI, Azure, Googleなどのサーバー)へプロンプトを投げなければいけないことが多々あります。
この際、企業によっては
- ホワイトリストに掲載されている企業にしかデータを流してはならない
- 海外サーバーとの通信は一律禁止
などの制限があることも多いです。
「低コストでRAGが出来ることはわかっているんだけど、社内規約的に難しいんだよな〜」
という声は実務ではよく聞くところです。
また、「うちの会社は社内規約上OpenAIはNGだけどAzure OpenAIはOKだよ!」みたいなケースも意外と多く、奥が深い(?)ところでもあります。
検索コンポーネント(Retriever)の例
さて、ここではRAGの仕組みの内、Retriever(情報を既存データベースから検索してくる部分)で使用可能な選択肢を整理してみたいと思います。
RAGでは大前提として、Retrieverではユーザークエリ、例えば
「わいけいという人物の好きな食べ物は?」
から意味的に近いデータを検索することが要求されます。
「意味的に近い」という言葉をどのように解釈するかは要件により異なります。
例えば、業界用語や社内専門用語の意味をGPTに教えたい場合であれば、「カレーライス」に対して「カレー・ライス」を検索してくるようなあいまい検索で十分なケースも想定されます。
とはいえ、一般的には先にも少し触れたベクトル検索を用いるケースが多いかと思います。
- ユーザーが発したクエリをOpenAIEmbeddingsなどでベクトル化する
- ベクトル化したクエリと既存のデータベースに保存されているデータ(こちらはあらかじめベクトル化されている)とのコサイン類似度などから近傍データを抽出
- 抽出したデータをpromptに埋め込みLLMに投げる
というフローですね。
2で用いるベクトルデータを保存しておくDBとしては、例えば下記のようなものが挙げられます。
| ベンダー | サービス名 |
|---|---|
| Azure | AI Search |
| AWS | OpenSearch, Kendra |
| GCP | Vertex AI Matching Engine |
| その他 | Pinecone, FAISS(ライブラリ) |
ちなみに、この内私が実務で使ったことがあるのはAzure AI SearchとOpensearch, Pineconeです。
どれに対しても機能的に不足を感じることはあまりありませんでした。
他の使用サービスとの兼ね合いで現在はAI Searchをよく使っていますが、各自の要件や状況に合わせて好きなものを選ぶと良いと思います。
他にも拡張的な機能を使えば、PostgresQLなどのRDBにベクトル化したものを保存しそれをRDBから近傍検索することも可能です。
参考: Amazon RDS for PostgreSQL with pgvector
ちなみに、この記事の後半で紹介する予定のRAGのpythonコードサンプルではこれらのDBサービスの代替として、ローカルファイルにベクトル情報をそのまま書き込むことで疑似DBとして使います。
何をやっているのかが誰の目にも明白になることと、上記に挙げたDBを本格的に使うとなると課金が必要になったり、DB提供サービス側のセットアップが必要になるのでこの方針としました。
生成コンポーネント(Generator)の例
RAGにおける生成コンポーネントとは基本的には大規模言語モデル(LLM)を指します。
例えば以下のようなものですね。
| 提供元 | 名称 | 特徴 |
|---|---|---|
| OpenAI | GPT | GPT-3.5とGPT-4はそれぞれ速度と精度に強みがある |
| Gemini | Gemini proはGPT-3.5に対して全く見劣りしない性能 | |
| Meta | Llama2 | オープンソース |
| 各自 | 独自モデルを開発 | 個人や小規模法人だと要件によっては現実的ではない |
Llamaの場合はローカルにモデルを落としてきて動かす、といったことも可能ですが、手軽にRAGを試したい場合はまずOpenAIのGPT3.5-turboなどのAPIを試してみるのが楽だと思います。
一応課金されるとはいえ少し試すぐらいであればせいぜい数十円程度の範囲に収まるはずです。
OpenAI APIでGPTを使ってRAGを実践してみる
さて、ここからは実際にコードを動かしてRAGの概要を掴んでいきましょう。
最終的に作るものは以下のようなフローを辿ることとします。
[下準備]
- OpenAI APIkeyの発行(openAIの公式ページから取得しておいてください。記事中では掘り下げません。)
- 必要ライブラリなどのインストール
[実装]
- テスト用データをベクトル化し、元テキストと共にjsonファイルとして保存(疑似DB)
- ユーザークエリを受け取ったら、それをベクトル化
- 疑似DBからデータを読み取り、ベクトル近傍検索を行う
- 検索結果をプロンプトに埋め込みGPTに投げる
- 得た回答を表示する
なお、コードは私のgithubリポジトリで公開しています。
準備編
まず、必要ライブラリをインストールしていきましょう。
必要に応じて仮想環境などを作ります。
python3 -m venv venv
source venv/bin/activate
下記のrequirements.txtファイルを作成します。
openai==1.10.0
numpy==1.26.4
pipでインストールします。
pip install -r requirements.txt
これで必要ライブラリがインストール出来ました。
実装編
さて、まずは次のファイルを作成し実行しましょう。
注:以下のコードを実行することで軽微ですが課金が発生することに注意してください。
from abc import ABC, abstractmethod
import json
import openai
# データをベクトル化するモジュールのインターフェース
class Embedder(ABC):
@abstractmethod
def embed(self, texts: list[str]) -> list[list[float]]:
raise NotImplementedError
@abstractmethod
def save(self, texts: list[str], filename: str) -> bool:
raise NotImplementedError
# Embedderインターフェースの実装
class OpenAIEmbedder(Embedder):
def __init__(self, api_key: str):
openai.api_key = api_key
def embed(self, texts: list[str]) -> list[list[float]]:
# openai 1.10.0 で動作確認
response = openai.embeddings.create(input=texts, model="text-embedding-3-small")
# レスポンスからベクトルを抽出
return [data.embedding for data in response.data]
def save(self, texts: list[str], filename: str) -> bool:
vectors = self.embed(texts)
data_to_save = [
{"id": idx, "text": text, "vector": vector}
for idx, (text, vector) in enumerate(zip(texts, vectors))
]
with open(filename, "w", encoding="utf-8") as f:
json.dump(data_to_save, f, ensure_ascii=False, indent=4)
print(f"{filename} に保存されました。")
return True
if __name__ == "__main__":
import os
texts = [
"佐藤一郎は、東京生まれの35歳のプログラマーです。趣味は写真撮影とハイキング。新しい技術を学ぶことに情熱を注いでいます。",
"鈴木花子は、北海道出身の28歳のイラストレーターです。猫を二匹飼っており、自然と動物を愛する心優しい人物です。",
"田中健二は、大阪で小さなカフェを経営する45歳の起業家です。コーヒーに対する深い知識と情熱を持ち、地域社会に貢献しています。",
"山本美咲は、福岡県出身の22歳の大学生です。法律を専攻しており、将来は人権に関わる仕事に就きたいと考えています。",
"伊藤高志は、長野県の山の中で育った30歳の写真家です。自然の美しさを捉えることに特化し、国内外で展示会を開催しています。",
"小林由紀子は、沖縄県出身の40歳の小学校教師です。子どもたちに芸術と文化の大切さを教えることに生きがいを感じています。",
]
# OpenAI APIキーを事前に環境変数にセットしてください。
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("APIキーがセットされていません。")
embedder = OpenAIEmbedder(api_key)
embedder.save(texts, "sample_data.json")
見ての通り、サンプルとして架空の人物たちに関する文章をベクトル化してローカルのjsonファイルに疑似DBとして保存するものです。
まず、環境変数にopenaiのAPIキーを設定して実行すると、ローカルにベクトルデータと共にファイルが保存されているのが確認できるでしょう。
export OPENAI_API_KEY=sk-**************************
python3 embedder.py
次は保存したデータから近傍検索を行うコードを作成しましょう。
同ディレクトリに下記のファイルを作成してください。
from abc import ABC, abstractmethod
import json
import numpy as np
class NearestNeighborsFinder(ABC):
@abstractmethod
def find_nearest(self, vector: list[float], topk: int = 3) -> list[dict]:
pass
class CosineNearestNeighborsFinder(NearestNeighborsFinder):
def __init__(self, data_file: str):
self.data = self._load_data(data_file)
def _load_data(self, data_file: str) -> list[dict]:
with open(data_file, "r", encoding="utf-8") as f:
return json.load(f)
def _cosine_similarity(self, vec1: list[float], vec2: list[float]) -> float:
vec1 = np.array(vec1)
vec2 = np.array(vec2)
# openAI embeddingのベクトルを対象にする場合は正規化されているため、np.dot(vec1, vec2) だけでも良い
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def find_nearest(self, vector: list[float], topk: int = 1) -> list[dict]:
similarities = [
(idx, self._cosine_similarity(vector, item["vector"]))
for idx, item in enumerate(self.data)
]
# 類似度が高い順にソート
sorted_similarities = sorted(similarities, key=lambda x: x[1], reverse=True)
# Top-Kの結果を返す
return [self.data[idx] for idx, _ in sorted_similarities[:topk]]
見ての通り、検索時は全データに対してユーザークエリをembeddingしたものとのcos類似度を一つ一つ計算するので効率は悪いです。
また、計算結果をソートするところでもO(nlogn)の計算量が発生しています。
とはいえ、サンプルとしてはこれで十分でしょう。
最後にgptとの連携を行うためのモジュールchatBot.pyを作成します。
from abc import ABC, abstractmethod
from openai import OpenAI
class ChatBot(ABC):
@abstractmethod
def generate_response(self, user_query: str, refs: list[str]) -> str:
pass
class GPTBasedChatBot(ChatBot):
def __init__(self):
self.client = OpenAI()
def generate_response(self, user_query: str, refs: list[str]) -> str:
# GPTによる応答を生成
context = "\n".join(refs) + "\n"
prompt = f"以下の情報に基づいてユーザーの質問に答えてください:\n\n{context}\n\n質問: {user_query}\n答え:"
print("#" * 30)
print("#" * 30)
print(f"\nprompt:\n {prompt}\n")
print("#" * 30)
print("#" * 30)
completion = self.client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": prompt,
},
],
)
return completion.choices[0].message.content
これらのモジュールを以下のように統合しました。
import os
from embedder import OpenAIEmbedder
from searcher import CosineNearestNeighborsFinder
from chatBot import GPTBasedChatBot
# OpenAI APIキーを事前に環境変数にセットしてください。
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("APIキーがセットされていません。")
def main():
embedder = OpenAIEmbedder(api_key)
searcher = CosineNearestNeighborsFinder("sample_data.json")
user_query: str = "アートを教えられる先生を探しています"
user_query_vector: list[float] = embedder.embed([user_query])[0]
search_results: list[dict] = searcher.find_nearest(user_query_vector, topk=2)
chat_bot = GPTBasedChatBot()
response: str = chat_bot.generate_response(
user_query, [search_result["text"] for search_result in search_results]
)
print("*" * 30)
print("*" * 30)
print("【AIの返答】")
print(response)
if __name__ == "__main__":
main()
全体のストーリーとしては、ローカルに保存した架空の人物情報を参照しながら、ユーザーからの"アートを教えられる先生を探しています"というクエリに応答する、という立て付けですね。
早速実行してみます。
python3 main.py
私の環境では、AIの回答は以下のようになりました。
小林由紀子先生は、芸術と文化の大切さを子どもたちに教えることに生きがいを感じていますので、あなたが探しているアートを教える先生としてぴったりです。お住いの地域や学校において、小林由紀子先生との面談や採用の相談をおすすめします。
無事、疑似DBの内容を踏まえた回答が出来ました。
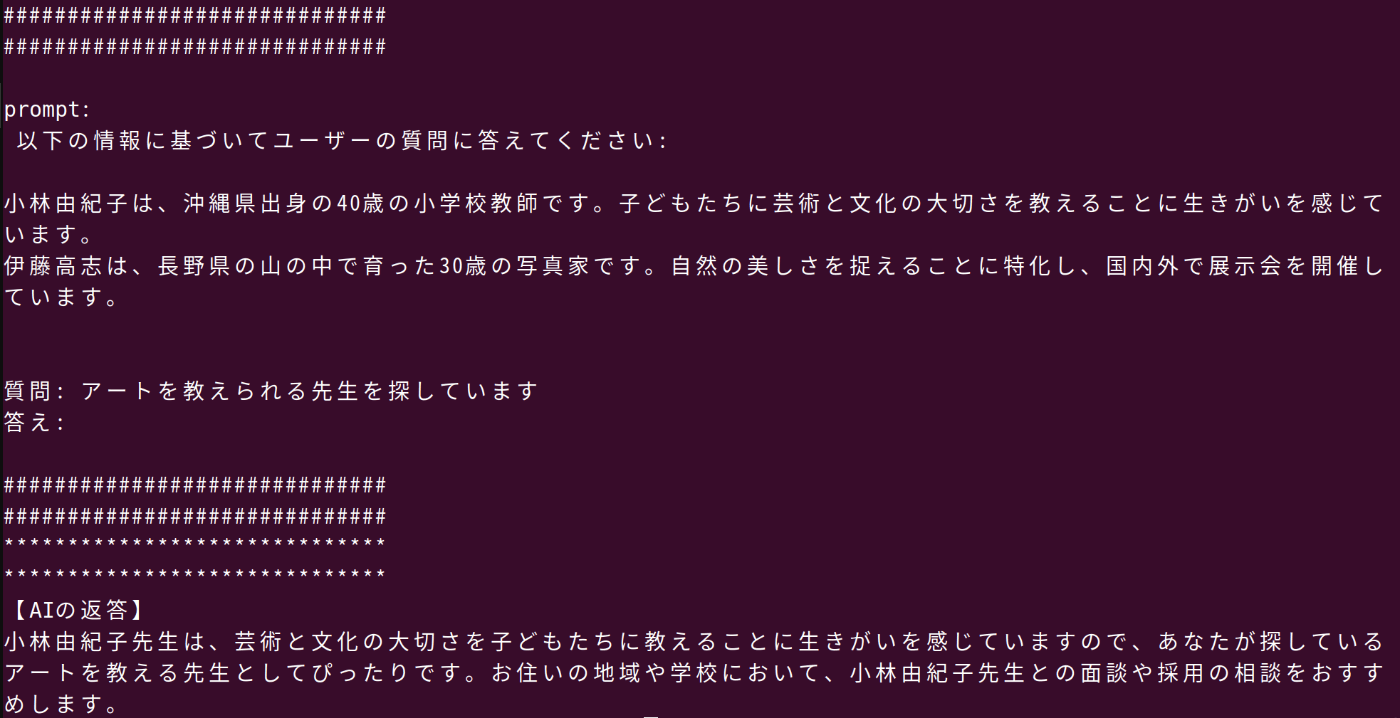
printされたプロンプトを見たところ、ベクトル近傍検索で小林さんと伊藤さんが選ばれていたこともわかります。
RAGの問題点とその克服案
以上がRAGの概要となります。
ここからは結びとして、実務でRAGを使う中で感じた課題点とその克服案などを考えていきたいと思います。
RAGの限界
今回扱ったような簡単な例だと求める回答が得られましたが、実務では必ずしもそうではありません。
私のこれまでの経験だと特にベクトル検索に失敗して後段のGPT処理がうまく行かないケースが目立ちました。
例えば
- ベクトル検索時のtopkを増やす
などの方法でこの問題を緩和できるはずですがその分プロンプトに渡すトークンが増えるのでコストは上がります。
RAGをうまく動作させるために
RAGをうまく動作させるためには
- データ保存時の工夫
- データ検索時の工夫
がそれぞれ必要となります。
前者については以下のような施策が有効になるケースが多かったです。
- webページやファイルのコンテンツを機械的に分解して検索対象のデータに使っている場合は、整形してからデータ投入するようにする。
- 特にデータを直接人の目で見て、前後の文脈が削ぎ落ちたような細切れの形式で保存されていないかチェックする。
- 上記に問題がある場合は前後の文脈が揃った状態でデータ保存されるように工夫する。
また、保存時にデータを加工しておくのも良いかもしれません。
「日本で一番高い山は富士山です」 → 「日本で一番高い山はなんですか?」
という変換をしておいて、「日本で一番高い山はなんですか?」というデータが検索ヒットしたらシステム的にその回答(つまり「富士山です」)をセットでLLMに渡す、といった方法ですね。
ベクトル検索はあくまで意味的に似たような文同士を検索するのでユーザークエリと検索対象文が両方とも質問文であったほうが精度が向上することが予想されます。
後者については、例えば
- DBをカテゴリ毎に分割しておいて、ユーザークエリに対してどのカテゴリのDBに対して検索をかけるか尋ねる
といった手法などが考えられます。
このような多段階選別をGPT-4を使って行えば最終的にベクトル検索を行う対象データ数をかなり減らせると期待できます(ただし、その分処理時間とコストも上がることに注意)。
いずれにせよ銀の弾丸は無いので、要件に照らして最適なソリューションを常に考えていく必要があります。
最後ちょっと逃げてしまいましたが、今後なにかアップデートがあれば私のXアカウントなどでも発信していく予定なので良ければフォローしていただけると幸いです。