目次
はじめに
私はAidemyのデータ分析講座を受講しており、このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開している。
私はSEの仕事をしており、AIを使用するPJに参画している。スキルとして不足しているコーディングとデータ分析のスキルアップのため、本講座を受講した。
実行環境
ブラウザ:Google Chrome
開発環境:Google Colaboratory
言語:Python 3.10.12
利用するデータ
Kaggleのコンペ「Store Sales – Time Series Forecasting」のデータセットを使用する。
https://www.kaggle.com/competitions/store-sales-time-series-forecasting
上記のデータセットの内、train.csvを使用して分析をする。
モデルの内容
時系列分析の手法を使用した月次の店舗売上を予測モデルを作成する。
モデル実装
共通ライブラリ導入
共通で使用するライブラリをimportする。
import numpy as np
import pandas as pd
データ内容の確認
データの構成を確認する。
# ファイルの読み込み
train_df = pd.read_csv('./data/train.csv')
# データの先頭5つを可視化
display(train_df.head())
# データの項目数とレコード数を確認
print(train_df.shape)
# データの各columnのデータ型を確認
print(train_df.dtypes)
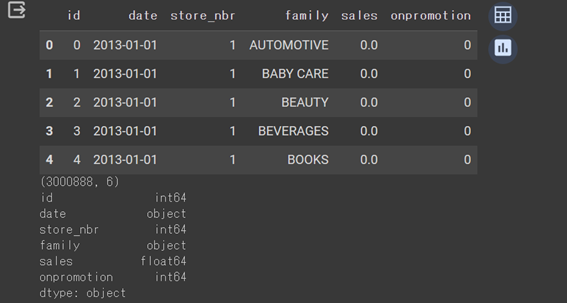
モデルに使用する日付(date)と売上高(sales)があることを確認した。
データの値を確認する。
# 分析のために型変換する
train_df['date'] = pd.to_datetime(train_df['date'], format="%Y-%m-%d")
train_df = train_df.astype(
{'id': str,'store_nbr': str}
)
# データの欠損値有無確認
print(train_df.isnull().sum())
# 重複確認
print(train_df['id'].duplicated().sum())
# データの統計量確認
display(train_df.describe())
display(train_df.describe(exclude=['number','datetime']))
# 日次でのデータ内容確認
display(train_df.groupby(pd.Grouper(key="date", freq="D")).sum())
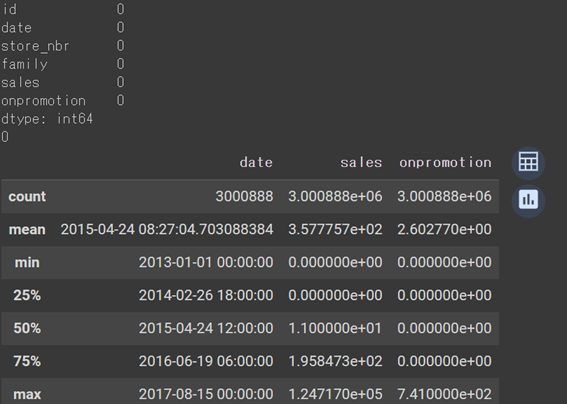
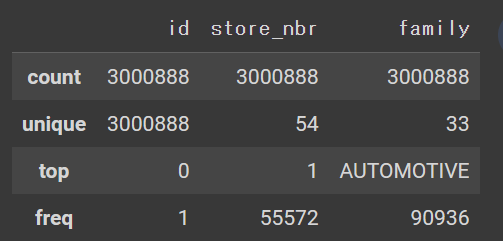
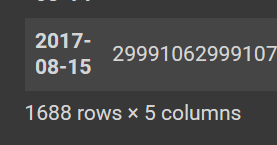
内容を確認した結果、日次データとしてデータ欠損はなく、キー(id)として重複するデータないことを確認した。データの期間は2013-01-01から2017-08-15。売上高の範囲は0から1.247170e+05。
データの性質確認
時系列分析として使用できるデータの性質であるか確認する。
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(train_df['sales'], period=365)
result.plot()
plt.show()
出力結果
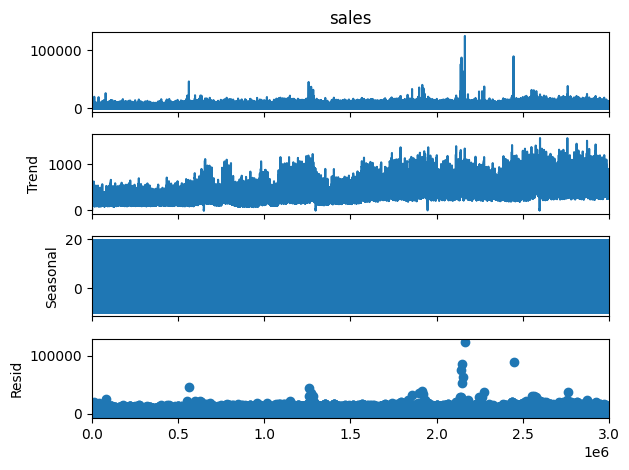
許容できない外れ値データがある。使用したデータセットを確認したところ、一部地域にて地震があったことで売上としては異常値扱いとなるデータが含まれていることが分かった。
異常値のデータ補正
異常値となるデータを削除する。
# 売上が0であるデータは欠損扱いであり、あると上位件数に影響があるので、レコードを削除する。
train_df = train_df[train_df.sales > 0]
#上位5%(2363以上)の売上高が異常値とする。
print(train_df['sales'].quantile(0.95))
train_df = train_df[train_df.sales < 2363]
#異常値を削除したことで日次データとして欠損がないか確認
display(train_df.groupby(pd.Grouper(key="date", freq="D")).sum())
データ補正後のデータ状態を確認する。
result = seasonal_decompose(train_df['sales'], period=365)
result.plot()
plt.show()
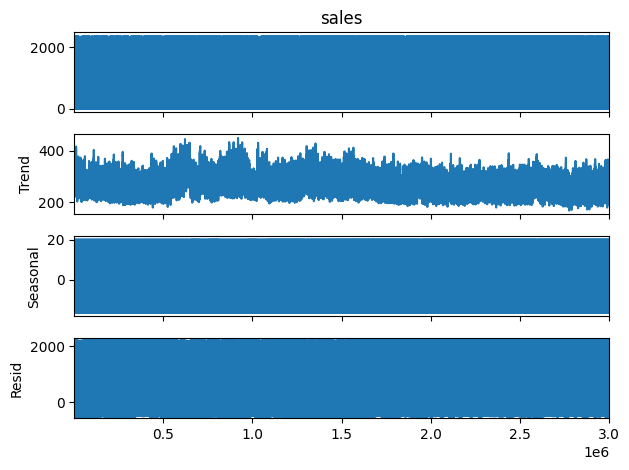
異常値がなくなったことで時系列データとして使用できる状態になった。
データ形式補正
モデルに使用できるようにデータ形式の整備をする。
# 不要な項目を削除
train_df = train_df.drop(columns=['id', 'store_nbr','family','onpromotion'])
# 日次から月次データに集約
train_df_temp = train_df.groupby(pd.Grouper(key='date', freq="M")).sum()
# データを学習用(2013-01から2016-12)と検証用(2016-01から2017-07)に分ける。8月分は15日までしかないので検証用に含めない。
sales_date_train = train_df_temp[train_df_temp.index <='2016-12-31']
sales_date_valid = train_df_temp[(train_df_temp.index >'2015-12-31') & (train_df_temp.index < '2017-08-01')]
モデルの選定
時系列分析をするモデル種類として、SARIMAXモデルとlightGBMモデルがある。どちらが準備したデータ的にモデルの制度がよいか確認する。
比較に使用する指標値は決定係数(R2)と二乗平均平方根誤差(RMSE)を使用する。
SARIMAXモデル
import statsmodels.api as sm
sm_model = sm.tsa.statespace.SARIMAX(sales_date_train).fit()
sm_pred = sm_model.predict('2016-01-31','2017-07-31')
指標値結果
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print("SARIMAXモデルのRMSEは",np.sqrt(mean_squared_error(sales_date_valid, sm_pred)))
print("SARIMAXモデルのR2は",r2_score(sales_date_valid, sm_pred))

lightGBMモデル
#lightGBMモデルのパラメータ形式に沿ったデータ形式の準備する。
#学習用データ
sales_date_train_1 = pd.to_datetime(sales_date_train.index)
sales_date_train_2 = sales_date_train
sales_date_train_2['yyyymm'] = sales_date_train_1
sales_date_train_3 = sales_date_train_2['yyyymm'].to_numpy()
X_train = np.array(sales_date_train_3).reshape(-1,1)
sales_date_train_4 = sales_date_train_2['sales'].to_numpy()
Y_train = np.array(sales_date_train_4).reshape(-1,1)
#検証用データ
sales_date_valid_1 = pd.to_datetime(sales_date_valid.index)
sales_date_valid_2 = sales_date_valid
sales_date_valid_2['yyyymm'] = sales_date_valid_1
sales_date_valid_3 = sales_date_valid_2['yyyymm'].to_numpy()
X_valid = np.array(sales_date_valid_3).reshape(-1,1)
sales_date_valid_4 = sales_date_valid_2['sales'].to_numpy()
Y_valid = np.array(sales_date_valid_4).reshape(-1,1)
import lightgbm as lgbm
lgbm_model = lgbm.LGBMRegressor()
lgbm_model.fit(X_train,Y_train)
lgbm_pred = lgbm_model.predict(X_valid)
指標値結果
print("lightGBMモデルのRMSEは",np.sqrt(mean_squared_error(Y_valid, lgbm_pred)))
print("lightGBMモデルのR2は",r2_score(Y_valid, lgbm_pred))

選定結果
どちらとも指標値結果としては悪いが、今回の目的はよいモデルを作成することよりもモデル作成の方法を理解することである。指標値結果が悪いながらも、準備したデータを使用したlightGBMモデルを構築する。
モデルのチューニング
lightGBMモデルにパラメータ設定をして、モデルの精度を上げる。
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'l2',
'learning_rate': 0.9,
}
lgb_train = lgbm.Dataset(X_train, Y_train)
lgb_eval = lgbm.Dataset(X_train, Y_train, reference=lgb_train)
lgbm_model_tuning = lgbm.train(
params, lgb_train,
num_boost_round=100,
valid_sets=lgb_eval
)
lgbm_pred_tuning = lgbm_model_tuning.predict(X_valid)
チューニング後の指標値結果
print("チューニング後のlightGBMモデルのRMSEは",np.sqrt(mean_squared_error(Y_valid, lgbm_pred_tuning)))
print("チューニング後のlightGBMモデルのR2は",r2_score(Y_valid, lgbm_pred_tuning))
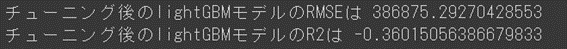
結果
モデルの実装、モデル評価、モデルのチューニングができた。
しかし、モデルの精度は非常に悪いので、改善ができるよう変数の追加、モデルの選定、パラメータのチューニングを再度検討したほうがよいと思った。
今後の展望
データ分析講座を受講した目的であるコーディングとデータ分析はスキルアップできたと思う。コーディングはメソッドの仕様方法の理解やエラー分析が受講前よりもスキルアップした。データ分析ではデータサイエンティストが実施するタスクについて、実際に試してみたことで精度の良いモデルを構築するのは非常に難しいことを理解した。
まだまだ業務レベルまでのスキルには達していないので、引き続き勉強を続けていこうと思った。