概要:
この記事はZeals Advent Calendar 2020の1日目の記事です。
こんにちは。ZealsでSREエンジニアをしている周です。
Zealsでは主にインフラ周りを担当しています。
今回はAIによく使う自然言語処理(NLP)モデルついて説明します。
この記事の主な目的は、タイムラインを明確にし、プレトレーニングモデルの進化、モデル間の関係の整理と比較を行うことです。
具体的な理論と詳細については、元のペーパーとコードを参照してください。
まだ今回は初回として、ELMo、GPT、BERT3つモデルを紹介致します。
そもそもなぜプレトレーニングが必要か?
- 多くのNLPタスクは、言語に関する共通の知識を共有しているため(言語表現、構造的類似性など)。
- タスクは相互に通知できるため。例: 構文とセマンティクス。
- 注釈付きのデータは少ないです。可能な限り多くの監督学習の成果を利用したいため。
- 経験的に、転移学習は、多くの監督学習されたNLPタスク(分類、情報抽出、Q&Aなど)のSOTAを取得したため。
代表的なプレトレーニング自然言語モデル
※モデルの一部のみ記載
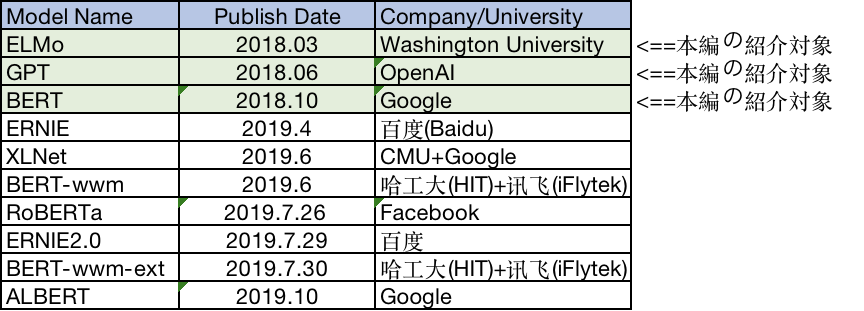
自然言語モデルのタイムライン
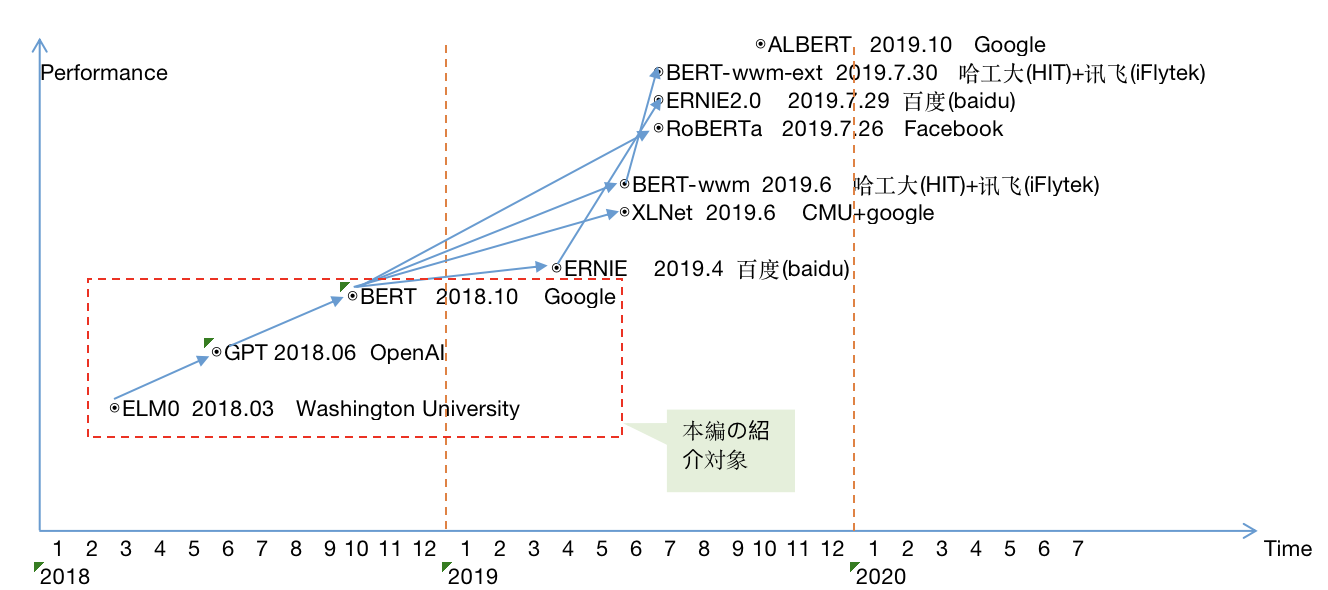
モデル間の進化関係
- 従来のword2vecは単語のポリセミーを解決できず、セマンティック情報も十分に豊富ではありません。改善するため、ELMoが誕生しました。
- ELMoはlstmと積み重ねられており、特徴の抽出する能力は十分ではありません、それを改善するためにGPTが誕生しました。
- GPTはtransformerと積み重ねられていますが、モデル自体は一方向であり、BERTを生み出しました。
- BERTは双方向ですが、マスクは自エンコードモデルには適しておらず、それを改善するためにXLNETが誕生しました。
- BERTでは、マスクはエンティティやフレーズの代わりに単一の文字を置き換え、字句構造/文法構造を考慮せず、トレーニング結果はよくない場合があります。それを改善するためにERNIEが誕生しました。
- 文字の代わりに中国語の単語をマスクし、BERTを中国のタスクにより適切に適用するために、BERT-wwmが誕生しました。
- BERTでは、より多くのデータ、トレーニングステップ、およびより大きなバッチを使用します。さらにマスクメカニズムが動的にすると、RoBERTaが誕生します。
- ERNIEに基づいて、大量のデータと事前知識を使用してマルチタスク連続学習を実行することで、ERNIE2.0が誕生しました。
- BERT-wwmは、トレーニングデータセットとトレーニングステップの数を増やし、BERT-wwm-extが誕生しました。
- BERTの他の改良モデルは、基本的にパラメータとトレーニングデータの追加を検討しました。それを元に軽量化した後、ALBERTが誕生しました。
ELMo、GPT、BERTモデルの紹介
1.ELMo
“Embedding from Language Models"
NAACL18 Best Paper
特徴:
従来の単語ベクトル(word2vecなど)は静的/コンテキストに依存しませんが、
ELMOは多面的な単語を解決します。
ELMOは2層の双方向LSTMを使用します。
短所:
ELMoはlstmと積み重ねられており、LSTMはシリアルであり、トレーニング時間が長い。
Transformerと比較して、特徴抽出能力が十分ではありません。
プレトレーニングの使用は2つの段階に分けられます:
- 事前トレーニング
- ダウンストリームタスクへの適用。
本質は、現在のコンテキストに従ってWordEmbeddingを動的に調整するプロセスです。
1.1 言語モデルを使ってプレトレーニングを実施する
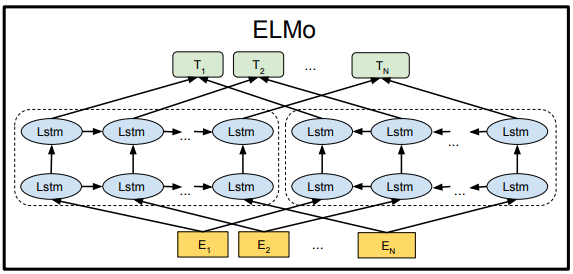
左側の順方向二重層LSTMは順方向エンコーダであり、予測される単語wの上部を順番に入力します。右側は逆方向エンコーダであり、wの次の部分を逆順で入力します。
トレーニング後、新しい文sを入力すると、各単語に3つのEmbeddingが表示されます。
①単語のEmbedding
②第1層の単語の位置に関するEmbedding
③第2層の意味情報を含むEmbedding
(上記の3つのEmbedding、 LSTMネットワークの結果ともに、トレーニングの結果となります。)
1.2 ダウンストリームタスクへの適用
ダウンストリームタスクを実行するときは、プレトレーニングされたネットワークから単語に対応するネットワークの各レイヤーのWord Embeddingを抽出してダウンストリームタスクに補足します。 例えば、QAタスク:Q / A文を入力し、3つのEmbeddingに重みを割り当て、新しいEmbeddingを統合して生成します。
2.GPT
“Generative Pre-Training"
メリット:
Transformerは、RNNよりも優れた、より広範囲の情報をキャプチャできます。
実行には並列で高速です。
短所:
入力データの構造を調整する必要があります。
一方向
2.1 構造特徴
- 2段階応用:一方向言語モデルのプレトレーニング(無監督学習)+ダウンストリームタスクに適用される微調整(監督学習)
- 自動回帰モデル
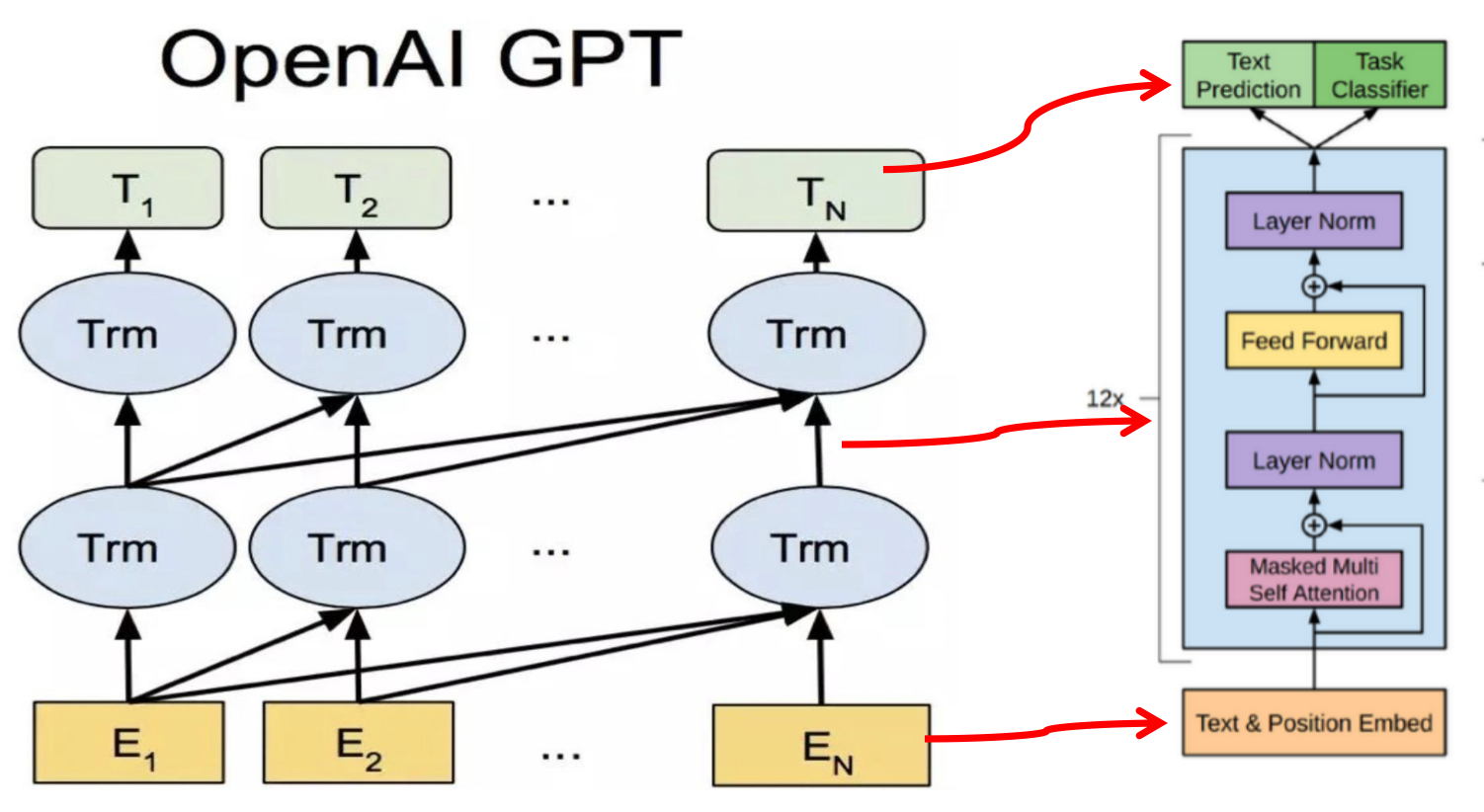
次の図に示すように、TransformerのDecoderには3つのサブモジュールがあります。GPTは1番目と3番目のサブモジュールのみを使用します。
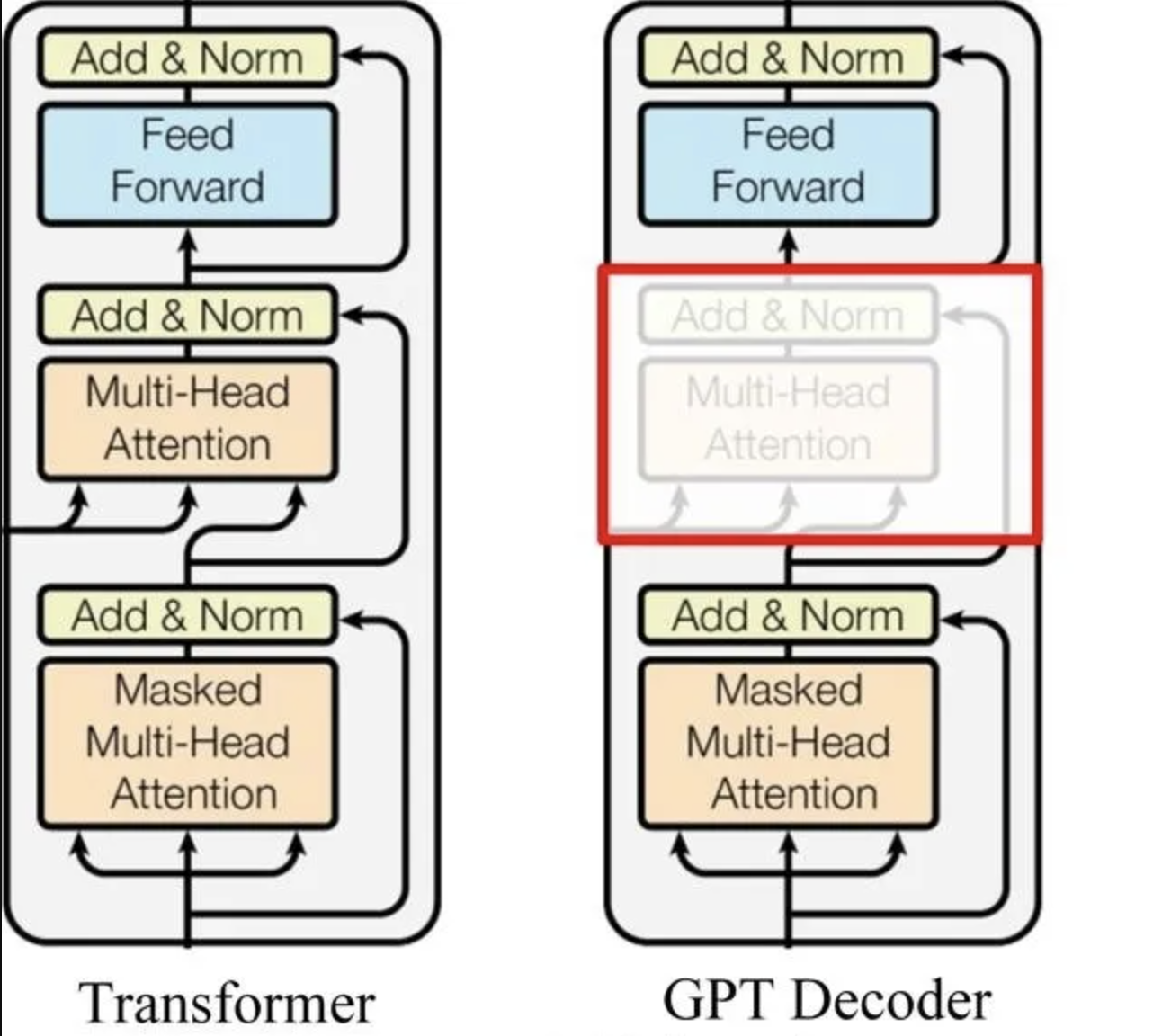
2.2 ELMoとの違い
- GPTにはBi-LSTMではなく、transformerのdecoderモジュールのみ使って特徴の抽出が実現されています。12層が積み重ねられています。
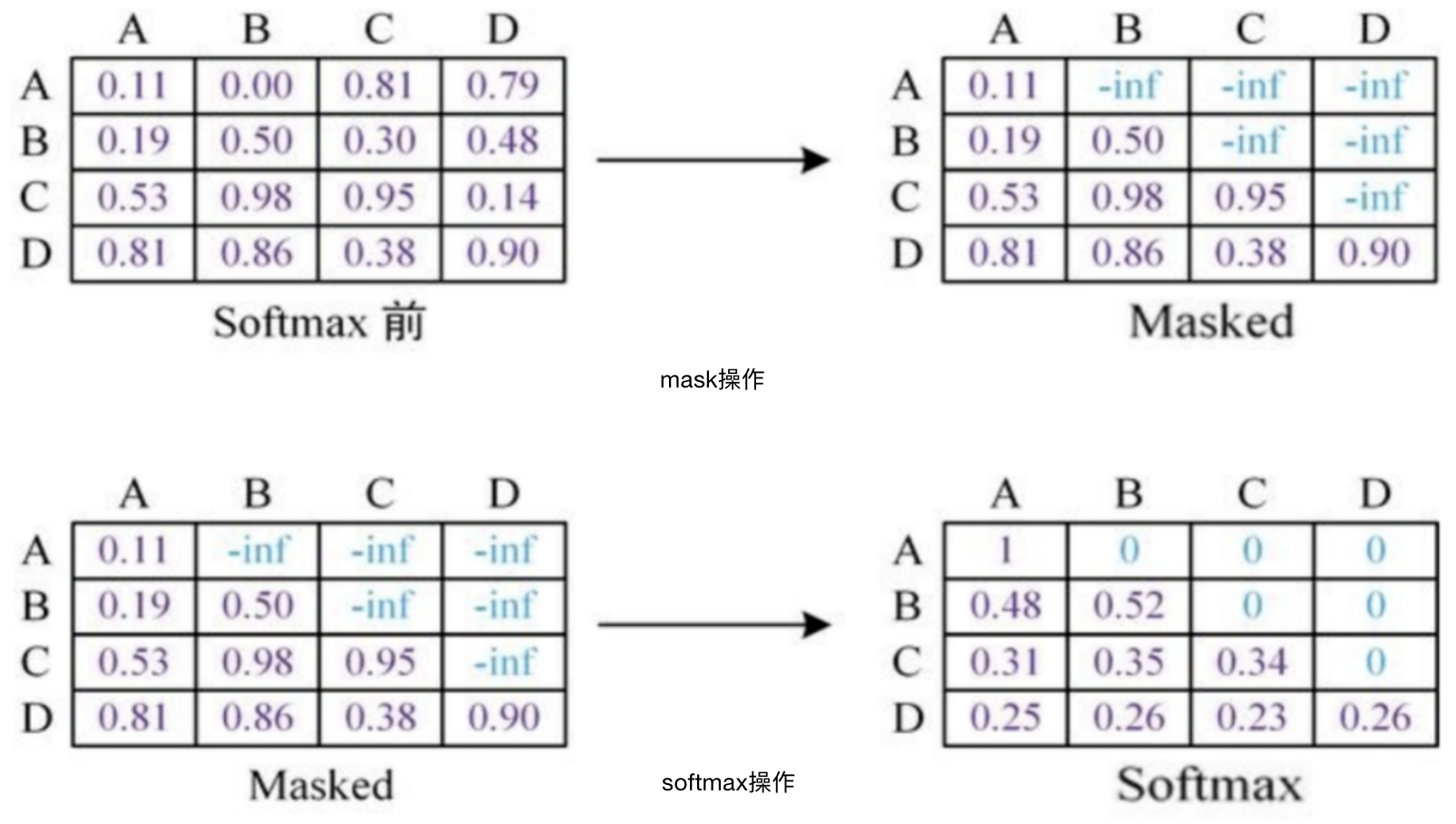
- 一方向のみ(予測対象単語の前の単語に基づいて単語を予測し、maskを使用して測対象単語の単語をマスクします。
GPT中のmaskのイメージは下記の通りです。mask実施後softmaxを実施します。
2.3 事前トレーニングとダウンストリームタスクへの適用
GPTはまだ2つの段階に分かれています。
最初の段階(事前トレーニング):
第2段階(ダウンストリームタスクに適用):
2.3.1 事前トレーニング
事前トレーニング(Pre training)イメージ:
2.3.2 ダウンストリームタスクに適用する方法
GPTのネットワーク構造に合わせて、タスクのネットワーク構造をGPTのネットワーク構造と同じになるように変換します。 アプローチは次のとおりです。
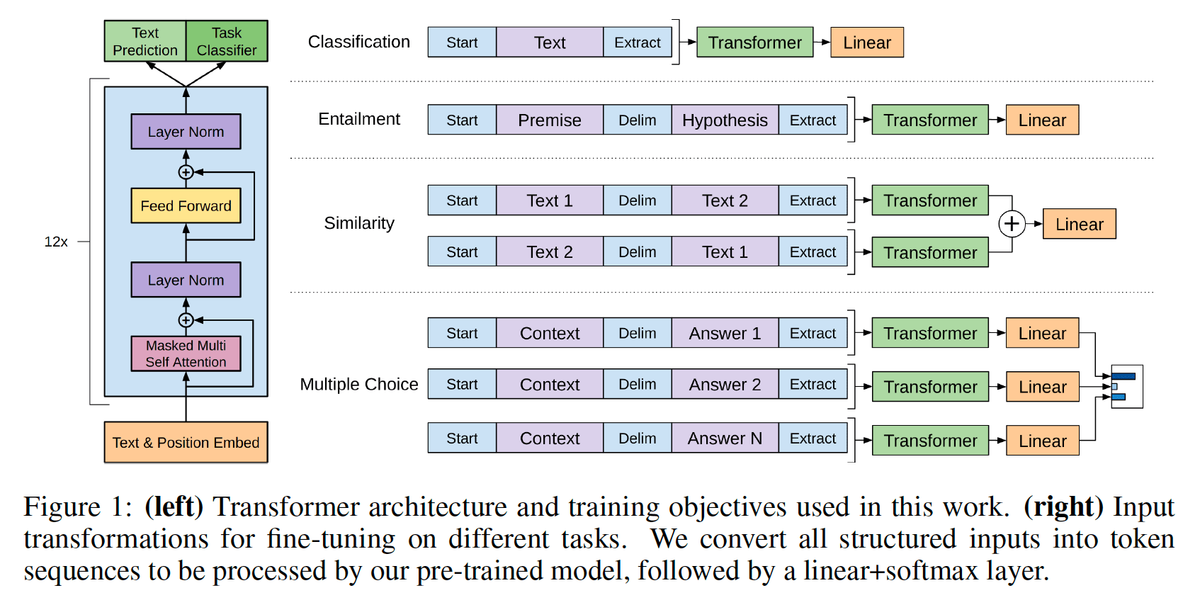
出典:Improving Language Understanding by Generative Pre-Training
(https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
- 分類の問題の場合、移動する必要はありません。開始記号と終了記号を追加するだけです。
- 含意などの文の関係判断の問題の場合は、2つの文の間に区切り文字を追加します。
- テキストの類似性判断の問題については、2つの文の順序を逆にして、2つの入力を行うだけです。
これは、文の順序が重要ではないことをモデルに伝えるためです。
- 複数選択の質問、マルチチャネル入力の場合、各チャネルは、記事と回答のオプションをつなぎ合わせることによって
入力として使用できます。
上の図からわかるように、この種の変換は依然として非常に便利です。
さまざまなタスクを入力部分で作成するだけで済みます。
2.3.3 効果:
12のタスクのうち、9つが最良の結果を達成し、一部のタスクではパフォーマンスが大幅に向上しました。
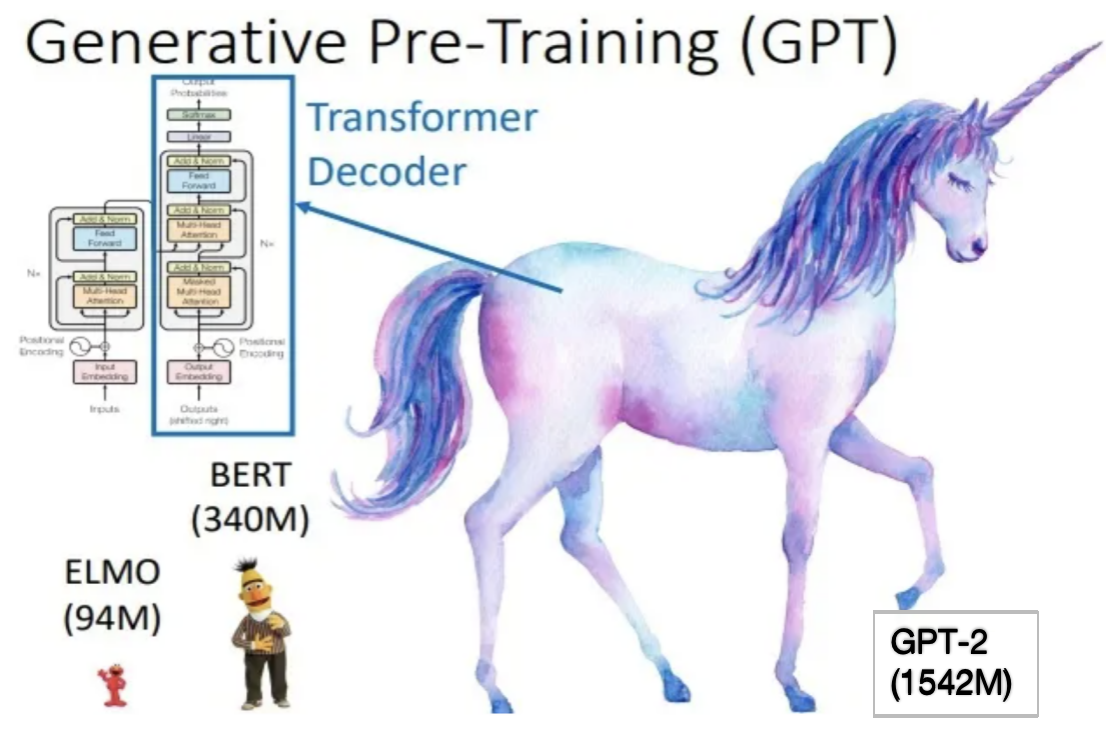
2.4 ELMO、BERT、GPT-2モデルサイズの比較
OpenAIは後にGPT-2モデルを提案しました。論文は「Language Models are Unsupervised Multitask Learners」で、構造はGPT-1(まだtransformerのencoder)に似ていますが、マルチタスクプレトレーニング+超大規模データセット+超大規模モデルを使用しています 、したがって、パフォーマンスは向上しますが、パラメーターもさらに増加しました。
以下は、ELMo、BERT、GPT−2のパラメータ数の比較です。
また、前の言葉から次の単語が一方向に予測されるため、GPTはBERTよりもテキスト生成タスクに適しています。
3.BERT
“Bidirectional Encoder Representations from Transformers"
GPTとの違い:
- 双方向
- Transformerのencoderを使用(GPTはdecoder、ELMOはBi-LSTMを使用)
- マルチタスク学習トレーニング:ターゲットワードを予測し、次の文を予測します。
利点:優れた効果、強力な普遍性、優れた効果
短所:
- 膨大なハードウェアリソースを消費します。
- トレーニングの時間が長いです。
- 事前トレーニングでは[MASK]フラグが使用され、微調整中のモデルのパフォーマンスに影響します。
3.1 BERTモデルPre Trainingのプロセス
3.1.1 Embedding
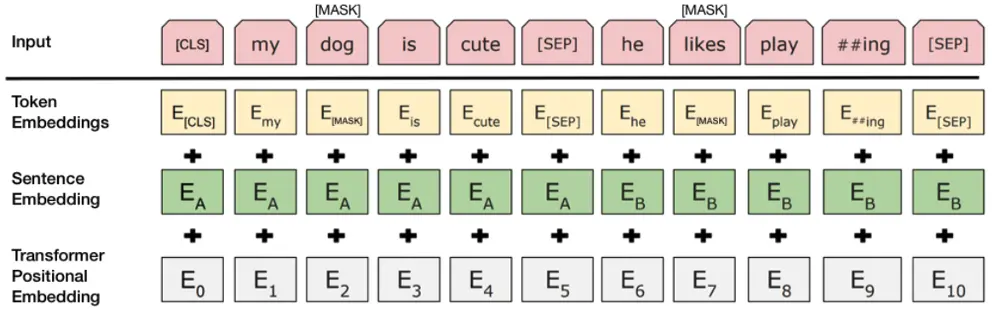
3つのEmbeddingの合計を計算します。
a.Token Embeddings:
単語ベクトル、最初の単語は[CLS]マークで、分類タスクに使用できます。
b.Segment Embeddings:
[SEP]マークを使用して、センテンスを2つのセグメントに分割します。
これは、事前トレーニングにはLMだけでなく、2つのセンテンスを入力とする分類タスクにも使用されるためです。
c.Position Embeddings:
その前のTransformerとは異なり、三角関数ではなく、学習によってできたものです。
3.1.2 ターゲットワードを予測するMaskedLM
文中の単語の15%をランダムに選択し、コンテキストを使用して予測します。 これらの15%のうち、80%は[マスク]に置き換えられ、10%はランダムな単語に置き換えられ、10%は変更されません。 無監督学習方法を使用して、これらの単語を予測します。
3.1.3 Next Sentence Prediction
文のペアA + Bを選択します。ここで、Bの50%はAの次の文であり、50%はコーパスからランダムに選択されます。
3.2 BERTの微調整(fine tuning)参照パラメータ
Batch Size:16 or 32
Learning Rate: 5e-5, 3e-5, 2e-5
Epochs:2, 3, 4
3.3 BERTの性能
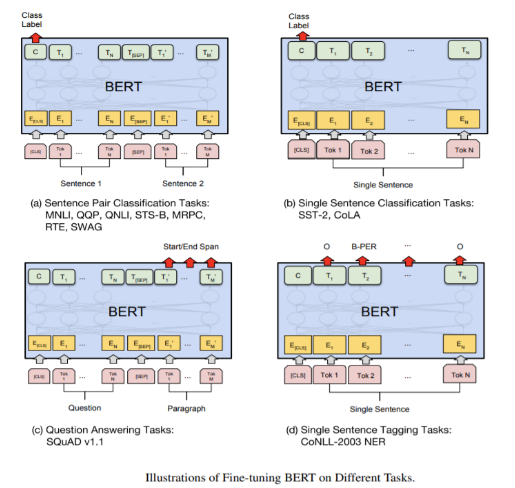
BERTは非常に強力で、11のNLPタスクでSOTAの結果を達成しています。
これらの11のタスクは、次の4つのカテゴリに分類できます。
–––––––––––––––––––––––––
文ペア分類タスク
一文分類タスク
質疑応答タスク
単一文のタグ付けタスク
–––––––––––––––––––––––––
纏め
- ELMoはBi-LSTMを使用し、GPTはTransformerのDecoderを使用し、BERTはTransformerのEncoderを使用します。
- ELMo:双方向、GPT、一方向、BERT:双方向
- ELMo:ポリセミーを解決します。
- GPT:より豊富な機能を解決します。
- BERT:双方向/マルチタスクトレーニング/より長い距離依存性が可能です。
- GPT:テキスト生成(NLGタスク)などのタスクに適しています。BERT:予測タスク(NLUタスク)に適しています。
- GPT-2は自動回帰モデルですが、BERTはそうではありません。自動回帰メカニズムは使用されていませんが、BERTは、単語の前後のコンテキスト情報を組み合わせる機能を備えています。 より良い結果を達成できるようになりました。
モデルに関する論文
ELMo:https://arxiv.org/pdf/1802.05365.pdf
GPT:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
BERT:https://arxiv.org/pdf/1810.04805.pdf
モデルに関するソースコード
ELMo:https://github.com/allenai/allennlp
GPT-2:https://github.com/openai/gpt-2
BERT:https://github.com/guotong1988/BERT-tensorflow
参考Reference:
https://www.cnblogs.com/zhaopAC/p/11219600.html
https://baijiahao.baidu.com/s?id=1652093322137148754&wfr=spider&for=pc
https://blog.csdn.net/ljp1919/article/details/100666563
https://zhuanlan.zhihu.com/p/76912493
https://www.cnblogs.com/yifanrensheng/p/13167796.html
https://zhuanlan.zhihu.com/p/70257427
https://www.jiqizhixin.com/articles/2020-04-283
https://blog.csdn.net/u012526436/article/details/101924049
https://www.sohu.com/a/330319491_657157
https://www.cnblogs.com/yifanrensheng/p/13167796.html