背景
日本ディープラーニング協会の資格試験(E資格)受験資格を得るためにラビット・チャレンジの講座プログラムを受けることにした。
当該講座を受講する時、科目ごとにレポートを作成しWebに投稿する必要があるためQiitaで作成することとした。
個人的には各科目の全要点などを記述よりも自分が難しいと思うところまたは理解不足なポイントをまとめる形にしたいと考えている。
ちなみにラビット・チャレンジについては以下から参考できる
再帰型ニューラルネットワークの概念
1.要点
再帰型ニューラルネットワーク(Recurrent Neural Network:RNN)とは、時系列データに対応可能なニューラルネットワークである。
時系列データ:
時間的順序を追って一定間隔ごとに観察され,しかも相互に統計的依存関係が認められるようなデータの系列という。例としては音声データ、テキストデータなどが挙げられる。
RNNの特徴:
時系列モデルを扱うには、初期の状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造が必要になる。
BPTT:
RNNにおいてのパラメータ調整方法の一種。
2.実装演習の考察
バイナリ加算を予測するRNNモデルを実行してみる
・初期モデル(最初の誤差の振動は大きいが最終的にきれいに収束できた)

重みの初期化方法:Xavier(誤差は収束したが、収束スビートがやや遅い)

重みの初期方法:He(初期モデルより良い学習ができた)
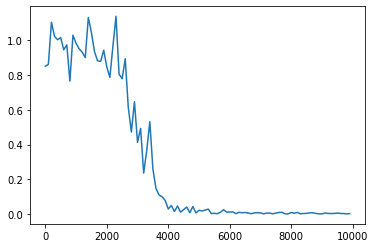
中間層の活性化関数:ReLU(勾配爆発が起きた)

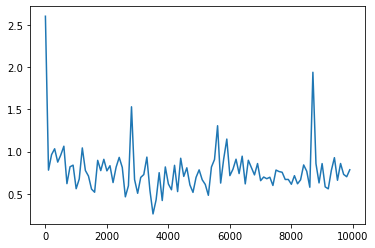
中間層の活性化関数:tanh(勾配爆発はおきないものの誤差の振動が収束できなかった)
3.確認テストの考察
下図のy1をx・s0・s1・win・w・woutを用いて数式で表せ。
※バイアスは任意の文字で定義せよ。
※また中間層の出力にシグモイド関数g(x)を作用させよ。

y_1 = g(W_{out}*S_1 + b)\\
S_1= W_{in}*x_1 + W*S_0
LSTM
1.要点
RNNの最適化手法BPTTが誤差逆伝播法の一種であるため、時系列を遡れば遡るほど、勾配が消失していく課題がある。その解決方法として構造自体を変えて解決したものがLSTMである。
LSTMの全体図は下図のよに構成される:

CEC:
勾配消失および勾配爆発の解決方法として、勾配を1つに変える手法。
CECは以下3つのゲートに構成される。
・入力ゲート、出力ゲート
ゲートへの入力値の重みを、重み行列W,Uで可変可能とする
・忘却ゲート
過去の情報が要らなくなった場合、そのタイミングで情報を忘却する
2.実装演習の考察
なし
3.確認テストの考察
新しいセルの計算プログラムを埋めてみる
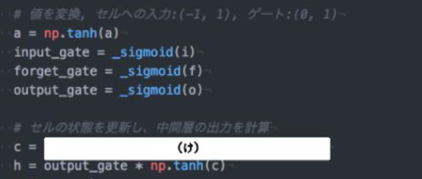
新しいセルの状態は、計算されたセルへの入力と1ステップ前のセルの状態に入力ゲート、忘却ゲートを掛けて足し合わせたものと表現される。
c = input_gate * a + forget_gate * c
GRU
1.要点
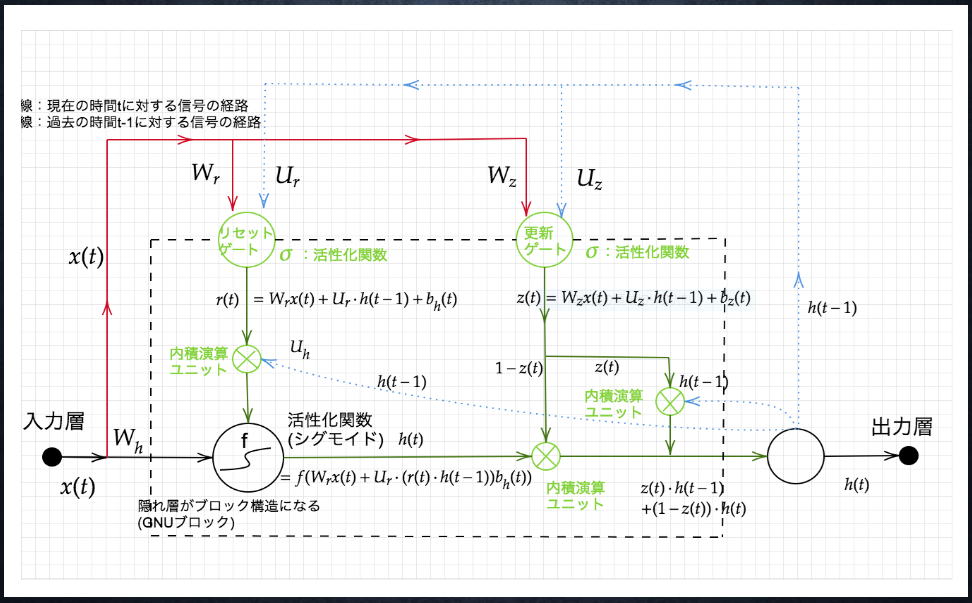
従来のLSTMでは、パラメータが多数存在していたため、計算負荷が大きかった。しかし、GRUでは、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった構造。
LSTMはCEC(メモリセル)をなくして忘却ゲートと入力ゲートを合体させたモデル。ゲートが更新ゲートとリセットゲートの二種類になる。
2.実装演習の考察
なし
3.確認テストの考察
LSTMとGRUの違いを簡潔に述べよ。
- 構造の違い
- LSTM:入力ゲート、忘却ゲート、出力ゲート
- GUR :更新ゲート、リセットゲート
- 表現力の違い
- LSTMのほうが複雑な表現ができる
- 計算負荷の違い
- GURの計算負荷が少ない
双方向RNN
1.要点
双方向RNNとは過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデル。双方向RNNモデルは文章の推敲や、機械翻訳等使われている。双方向から処理することで,各単語に対応する隠れ状態ベクトルは,左と右の両方向からの情報を集約することができる。
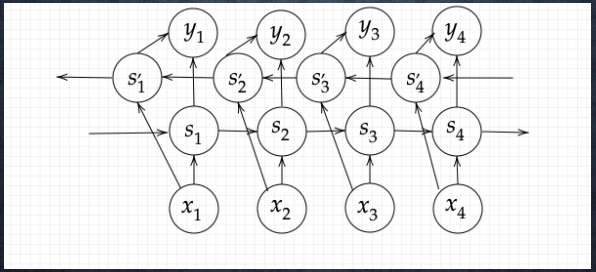
2.実装演習の考察
なし
3.確認テストの考察
以下双方向RNNの順伝播を行うプログラムを埋める

双方向RNNでは、順方向と逆方向に伝播したときの中間層表現をあわせたものが特徴量となるので、np.concatenate([h_f, h_b[::-1]], axis=1)である。
Seq2Seq
1.要点
Seq2seqはEncoder-Decoderモデルの一種であり、械対話や、機械翻訳などに使用されているモデル。
・Encoder RNN
ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造。
・Decoder RNN
システムがアウトプットデータを、単語等のトークンごとに生成する構造。
・HRED
過去n-1 個の発話から次の発話を生成する。
・VHREDVHRED
HREDに、VAEの潜在変数の概念を追加したもの。
・VAE
通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているものの、その構造がどのような状態かわからない。VAEはこの潜在変数zに確率分布z∼N(0,1)を仮定したモデル。
2.実装演習の考察
なし
3.確認テストの考察
seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ。
HREDはSeq2seqの課題(1問1答しか出来ない)を改良したモデル。
VHREDはHREDの課題(同じ文脈だと毎回同じ答えしか出ない)を改良したモデル。
Word2vec
1.要点
RNNの課題としては単語のような可変長の文字列をNNに与えることはできないため固定長形式で単語を表す必要がある。
単語をベクトルで表現することができれば単語の意味を定量的に把握することができるため、様々な処理に応用することができる。Word2Vecも単語の分散表現の獲得を目指した手法である。
2.実装演習の考察
外部のライブラリgensimを使用する場合、Word2vecモデルを簡単に定義できる。
from gensim.models import word2Vec
model = word2vec.Word2Vec(sentences, size=200, min_count=20, window=15)
3.確認テストの考察
なし
Attention Mechanism
1.要点
seq2seqでは、2単語でも100単語でも、固定次元ベクトルの中に入力しなければならないため、長い文章への対応が難しいとう課題がある。
解決策として、Attention Mechanismは「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みがある。
例えば英語「I have a pen」を日本語に翻訳する場合、「a」についてはそもそも関連度が低く、「I」については「私」との関連度が高いなどが学習することが可能。
2.実装演習の考察
なし
3.確認テストの考察
RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
RNN:データ量が多い(ボキャブラリ×ボキャブラリだけの重み行列)
word2vec:データ量が少ない(ボキャブラリ×任意の単語ベクトル次元で重み行列)
seq2seq:固定次元ベクトルのため長い文章への対応が難しい
Attention:入力と出力の関連度を学習することで長い文章への対応が可能となる。
強化学習
強化学習は長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野であり、行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組みである。
強化学習のイメージ:

強化学習の応用例:
環境:会社の販売促進部
エージェント:プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。
行動:顧客ごとに送信、非送信のふたつの行動を選ぶことになる。
報酬:キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受けるマーケティングの場合
強化学習と通常の教師あり、教師なし学習との違い:
<目標が違う>
・教師なし、あり学習では、データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標
・強化学習では、優れた方策を見つけることが目標
AlphaGo
AlphaGoは米国グーグルディープマインド社が開発した囲碁対局用の人工知能モデル。
AlphaGoの学習ステップ:
1、教師あり学習によるRollOutPolicyとPolicyNetの学習
2、強化学習によるPolicyNetの学習
3、強化学習によるValueNetの学習
モンテカルロ木探索はコンピュータ囲碁ソフトでは現在もっとも有効とされている探索法であり、AlphaGo別バージョンのAlpha Go (Lee) とAlpha Go Zeroとも用いられている。
AlphaGo(Lee) とAlphaGoZeroの違い:
1、教師あり学習を一切行わず、強化学習のみで作成
2、特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3、PolicyNetとValueNetを1つのネットワークに統合した
4、Residual Net(後述)を導入した
5、モンテカルロ木探索からRollOutシミュレーションをなくした
軽量化・高速化技術
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。
複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行うために、データ並列化、モデル並列化、GPUによる高速技術は不可欠である。
データ並列化
・親モデルを各ワーカーに子モデルとしてコピー
・データを分割し、各ワーカーごとに計算させる
モデル並列化
・親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
・モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い
GPUによる高速化
・比較的低性能なコアが多数
・簡単な並列処理が得意
・ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
量子化
ネットワークが大きくなると大量のパラメータが必要なり学習や推論に多くのメモリと演算処理が必要となる、量子化は通常のパラメータの64 bit 浮動小数点を32 bit など下位の精度に落とすことでメモリと演算処理の削減を行う。
量子化は計算の高速化や省メモリ化の利点があるが精度の低下の欠点がある。
蒸留
蒸留とは学習済みの精度の高いモデルの知識を軽量なモデルへ継承させること。
知識の継承により、軽量でありながら複雑なモデルに匹敵する精度のモデルを得ることが期待できる。
プルーニング
ネットワークが大きくなると大量のパラメータなるが全てのニューロンの計算が制度に寄与しているわけではない。
プルーニングはモデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化を目的とする手法。
応用モデル
MobileNet
MobileNetとはスマホなどの小型端末にも乗せられる高性能CNNを作りたいというモチベーションから生まれた軽量かつ(ある程度)高性能なCNNモデルである。
一般的な畳み込みレイヤーは計算量が多いが、MobileNetsはDepthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現できた。
以下MobileNetの論文
「MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications」
DenseNet
DenseNetはCNNアーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、DenseNetはDenseBlockと呼ばれるモジュールを用いて前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処したアーキテクチャ。
以下DenseNetの論文
「Densely Connected Convolutional Networks. G. Huang et., al. 2016」
Batch Norm
Batch Normは各層でのアクティベーションの分布を適度な広がりを持つように調整することで,学習促進,初期値依存度低下,過学習の抑制ができる。
Batch Normの問題点として、Batch Sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayer Normalizationなどの正規化手法が使われることが多い。
Layer Norm
Layer Normaでは、1つのサンプルにおける各レイヤーの隠れ層の値の平均・分散で正規化するため、Batch Normの問題点を解除できる手法である。
Instance Norm
Instance Normは各sampleの各チャネルをごとに正規化する手法であり(Batch Normalのバッチサイズが1の場合と等価)、コントラストの正規化に寄与・画像のスタイル転送やテクスチャ合成タスクなどで利用される。
Wavenet
WavenetはGoogle傘下のDeepMindが開発した生の音声波形を生成する深層学習モデルであり、Pixel CNN(高解像度の画像を精密に生成できる手法)を音声に応用したものである。
コンピュータによる音声合成・音声認識に対して大きな衝撃を与えた技術といわれる。
Transformer
前述にあったようにseq2seqでは長い文章への対応が難しいとう課題がある。
Attention Mechanismは「入力と出力のどの単語が関連しているのか」の関連度を学習することで上記課題を解決できる。
2017年に登場したTransformerはRNNを使わずAttentionのみ構成されたモデルであり、当時のSOTAをはるかに少ない計算量で実現できた。
TransformerはSelf-Attentionが肝であり、入力を全て同じにして学習的に注意箇所を決めていく手法である。
Transformerの主要モジュール:
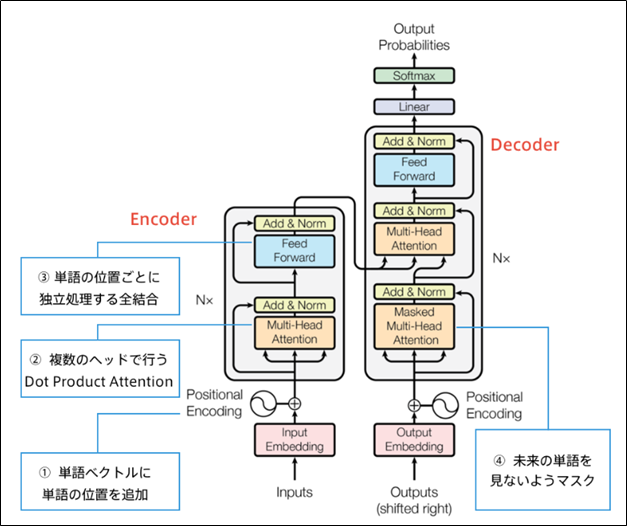
物体検知・セグメンテーション
物体検知
物体検知は入力された画像に対してBounding Boxを付ける手法である。
データセット:
物体検知の学習に代表的なデータセットにVOC12、ILSVRC17、MS COCO18、OICOD18などがある。
下図のように各データセットはクラス数やBox/画像が異なるため、目的に応じて選択することが大切である。

評価指標:
物体検知では以下3つの指標で評価を行う。
・IoU(Intersection over Union):
IoU = \frac{Area of Overlap}{Area of Union}
・AP(Average Precision)
AP = \int_0^1{P(R)dR}
・mAP(mean Average Precision)
mAP = \frac{1}{C}\sum_{i=1}^C{AP_i}
P:precision、R:Recall、C:クラス数
セグメンテーション
セグメンテーションとは,シーン画像に対して,画素ごとに独立して意味(Semantics)のクラス識別を行い,画像全体の意味的な領域分割を行う問題である.画素ごとに識別するクラスとして,例えば「道路」「人」「空」「海」「建物」などの,おおまかな意味単位をクラスとして用いる。セグメンテーションがよく用いられる場面として、自動運転での環境把握、医療での画像診断などがある。
参考文献
深層学習の勉強をしていく中で、Deep Learningの定番の本と言われている「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」が参考になった。