VR法人HIKKYでバックエンド開発を担当しているいけがやです。
HIKKYのアドベントカレンダー2023の18日目の記事になります。
バックエンドチームでは一部のWebAPIやバッチ処理をGoで実装していますが、今回はGoのプロジェクトをクリーンアーキテクチャに沿って実装した事例を書いてみます。
クリーンアーキテクチャの実践で考慮すべき問題、例えば
- クリーンアーキテクチャのレイヤーに沿ったフォルダ分割をどうするか
- それぞれのフォルダやファイル名、コードの命名をどうするか
- コードを実際にどうそれぞれのフォルダに分割していくか
という問題に対しては議論が活発で様々なアプローチがあると思いますがそのうちの1つの方法として参考にしていただければと思います。
クリーンアーキテクチャとは?
クリーンアーキテクチャについて有名な以下の図を参照しながら解説していきます。
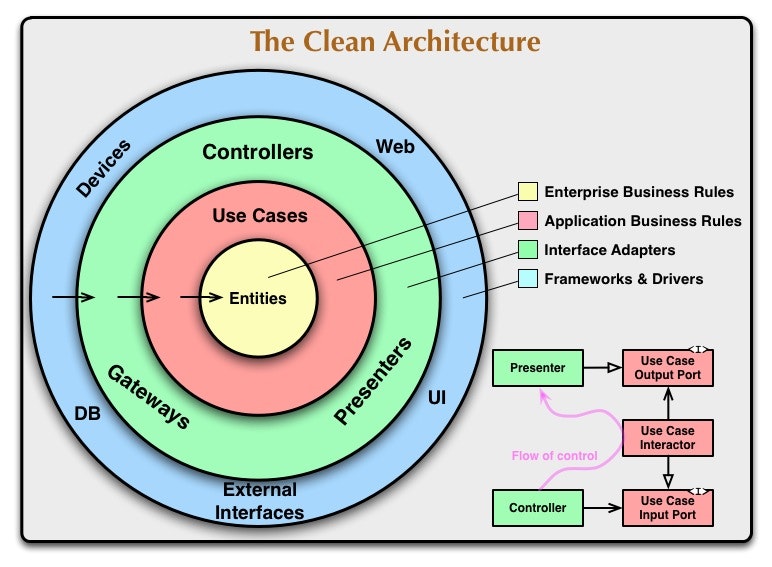
4つのレイヤー
Frameworks & Drivers層(青)
DBへのアクセス、別デバイスへのドライバ、HTTPクライアントの組み立てなどドメイン知識に関係のない技術ロジックが記述されます。
Interface Adapters層(緑)
外部との橋渡しを担当するレイヤーです。Controller、Presenter、Gatewayの3つに区分されます
- Controllerは外部から受け付けたコマンドやリクエストを解釈します
- Presenterは外部に向けてデータ形式を変換します
- Gatewayはデータの読み出しと保存を担当します
Application Business Rules層(赤)
アプリケーションとしての機能を記述します
Enterprise Business Rules層(黄)
ビジネス固有のドメインロジックを記述します
これだけではわからないと思うので次に実例を挙げながら解説していきます。
実例を用いた解説
ここからはGoのサンプルコードを使って解説していきます。
今回は実際にHIKKYで開発されている「アセットアップローダー」というサービスで実装されている「Zipファイルの展開&アップロードバッチ処理」を例に説明していきます。
処理の流れを説明する前に簡単にHIKKY固有の用語の説明をします。
- 「アセット」はVR空間で使用する3Dモデルや音声や画像の情報と思ってください
- アセットにはバージョンが存在しバージョンごとにアセットの情報が記録されています
- HIKKYでは自社開発のメタバース開発SDKやメタバースプラットフォームなど様々なプロダクトが開発されており、アセットアップローダーはそれらと連動して動作するサービスです
Zipファイルの展開&アップロードバッチ処理の流れ
処理の流れ
- AWS LambdaのイベントとしてアセットのバージョンIDを受け取る
- アセットのバージョン情報をMySQLから取得する
- 取得した情報の中にS3オブジェクトのキーが含まれているのでそれを元にAWS S3からアセットが含まれたzipファイルをダウンロードする
- ダウンロードしたzipファイルを解凍してS3の別バケットにアセットをアップロードする
- アップロードしたアセットの情報を社内の別サーバにPOSTする
実際の処理からいくつか省略している部分はありますがこのようなバッチ処理がHIKKYのバックエンドチームで開発されています。
このバッチ処理の実装をクリーンアーキテクチャに沿って分割したフォルダに落とし込んでいきます
├── infrastructure # 青の層 Frameworks & Drivers
├── adapter # 緑の層 Interface Adapters
├── usecase # 赤の層 Application Business Rules
├── domain # 黄の層 Enterprise Business Rules
Frameworks & Drivers層(青)の実装
Frameworks & Driversのフォルダは「infrastructure」としています。
このレイヤーにはMySQLやS3への接続処理を書いていきます。
今回はクリーンアーキテクチャの説明に必要な実装箇所のみ紹介していきます。
├── infrastructure
├── mysql.go
├── s3.go
MySQLへの接続処理。bunというORマッパーを使用した例です。
func NewDB() *bun.DB {
databaseUrl := os.Getenv("DATABASE_URL")
engine, err := sql.Open("mysql", fmt.Sprintf("%s?charset=utf8mb4", databaseUrl))
if err != nil {
panic(err)
}
db := bun.NewDB(engine, mysqldialect.New())
db.AddQueryHook(bundebug.NewQueryHook(bundebug.WithVerbose(true)))
// check connection
if err := db.Ping(); err != nil {
panic(err)
}
return db
}
S3への接続処理
type S3ClientInterface interface{}
type S3ClientImpl struct{}
func NewS3() *S3ClientImpl {
return &S3ClientImpl{}
}
func (s3impl *S3ClientImpl) InitS3Client() (*s3.S3, error) {
forthPathStyleStr := os.Getenv("FORCE_PATH_STYLE")
forthPathStyle, err := strconv.ParseBool(forthPathStyleStr)
if err != nil {
return nil, fmt.Errorf("Failed to init forthPathStyleStr err: %s", err)
}
awsAccessKeyID := os.Getenv("AWS_ACCESS_KEY_ID")
awsSecretAccessKey := os.Getenv("AWS_SECRET_ACCESS_KEY")
endPoint := os.Getenv("S3_ENDPOINT")
region := os.Getenv("AWS_REGION")
sess, err := session.NewSession(
&aws.Config{
Credentials: credentials.NewStaticCredentials(awsAccessKeyID, awsSecretAccessKey, ""),
Endpoint: aws.String(endPoint),
Region: aws.String(region),
S3ForcePathStyle: aws.Bool(forthPathStyle),
})
if err != nil {
return nil, fmt.Errorf("Failed to create NewSession err: %s", err)
}
s3Client := s3.New(sess)
return s3Client, nil
}
このようにこのレイヤーはアプリケーションの仕様やドメイン知識から隔離された実装を担当します。
Interface Adapters(緑)
データベースや外部サーバなど外部との橋渡しを担当するレイヤーです。
このレイヤーは図の用語に沿って「adapter」というフォルダの下に「presenter」、「controller」、「gateway」の3つの階層を作っています。
├── adapter
├── presenter
├── contents_publish_presenter.go # 外部サーバに送信するJSONの生成
├── controller
├── extract_zip_controller.go # lambda eventの受け取り
├── gateway
├── asset_version_repository.go # MySQLデータの読み取りと保存
presenterの例
「presenter」層は外部に向けてデータを整形するような処理を実装します。例えば
- Ruby on Railsのerbのようなテンプレートエンジンを元にHTMLを生成する処理
- Webサーバーのデータベースの内容や構造体を元にJSONやProtobufに変換する処理
- データベースの内容や構造体を元にQRコードを発行する処理
などです
今回はS3にアップロードしたアセットの情報を外部サーバに送信していますがその際のJSONの組み立てはpresenterに属します。
type ContentsPublisherPostParam struct {
ContentLabel string `json:"content_label"`
Target string `json:"target"`
Name string `json:"name"`
Description string `json:"description"`
}
type ContentsPublishPresenter struct{}
func (c *JSONPresenter) RenderJSON(data ContentsPublisherPostParam) ([]byte, error) {
result, err := json.Marshal(data)
if err != nil {
return nil, err
}
return result, nil
}
controllerの例
controllerはユーザからの入力を受け取りその入力に対してApplication Business Rules(usecase)に伝える役割を果たします。
次のコードではAWS LambdaのeventとしてアセットのバージョンIDを受け取りusecaseのメソッドで処理をしていきます。
type ExtractZipController struct {
AssetVersionApplication usecase.AssetVersionApplicationInterface
AssetZipApplication usecase.AssetZipApplicationInterface
ContentsPublisherApplication usecase.ContentsPublisherApplicationInterface
}
func NewExtractZipController(
assetVersionApplication usecase.AssetVersionApplicationInterface,
assetZipApplication usecase.AssetZipApplicationInterface,
contentsPublisherApplication usecase.ContentsPublisherApplicationInterface) ExtractZipController {
return ExtractZipController{
AssetVersionApplication: assetVersionApplication,
AssetZipApplication: assetZipApplication,
ContentsPublisherApplication: contentsPublisherApplication,
}
}
type ExtractZipEvent struct {
AssetVersionID int64 `json:"asset_version_id"`
}
func (h *ExtractZipController) ExtractZipController(ctx context.Context, event ExtractZipEvent) error {
// usecase層のメソッドを呼び出す
// エラーハンドリングは今回は略
// アセットのバージョン関連情報取得
assetVersion, err := assetVersionApplication.GetAssetVersion(ctx, event.AssetVersionID)
// Zipの展開とS3へのアップロード
err = assetZipApplication.ExtractZipAndUpload(ctx, assetVersion.ID)
// 別サーバへのアセット情報POST
err = contentsPublisherApplication.Publish(ctx, assetVersion.ID)
return nil
}
gatewayの例
gatawayにはデータの読み取りや保存を抽象化したコードを実装していきます。
以下の例はORマッパーを使ったMySQLからのデータ読み込みの例です。
type AssetVersionRepositoryInterface interface {
FindAssetVersionByID(ctx context.Context, assetVersionID int64) (*model.AssetVersion, error)
}
type AssetVersionRepository struct {
db *bun.DB
}
func NewAssetVersionRepository(db *bun.DB) *AssetVersionRepository {
return &AssetVersionRepository{
db: db,
}
}
func (ar *AssetVersionRepository) FindAssetVersionByID(ctx context.Context, assetVersionID int64) (*model.AssetVersion, error) {
assetVersion := model.AssetVersion{}
if err := ar.db.NewSelect().
Model(&assetVersion).
Where("id = ?", assetVersionID).
Scan(ctx); err != nil {
return nil, fmt.Errorf("failed to find asset_version. err: %s", err)
}
return &assetVersion, nil
}
Application Business Rules(赤)
アプリケーションとしての機能、ふるまいを記述するレイヤーです。フォルダ名は「usecase」としています。
今回のケースにおいては
- アセットのバージョン情報を取得する
- アセットが圧縮されたzipをダウンロードして回答する
- 別サーバ(contents_publisher)にアセット情報を送信する
といったアプリケーションのふるまいを記述しています。
├── usecase
├── asset_version_application.go
├── asset_zip_application.go
├── contents_publisher_application.go
「アセットのバージョン情報を取得する」というふるまいを例にサンプルコードを書きます。
import (
//標準パッケージのimportは略
"asset-uploader/infrastructure/adapter/gateway"
)
type AssetVersionApplication struct {
assetVersionRepository gateway.AssetVersionRepositoryInterface
}
type AssetVersionApplicationInterface interface {
GetAssetVersion(ctx context.Context, assetVersionID int64) (*model.AssetVersion, error)
}
func NewAssetVersionApplication(assetVersionRepository gateway.AssetVersionRepositoryInterface) *AssetVersionApplication {
return &AssetVersionApplication{
assetVersionRepository: assetVersionRepository,
}
}
func (ar *AssetVersionRepository) GetAssetVersion(ctx context.Context, assetVersionID int64) (entity.AssetVersion, error) {
assetVersion, err := assetVersionRepository.FindAssetVersionByID(ctx, assetVersionID)
if err != nil {
return nil, fmt.Errorf("failed to find asset_version. err: %s", err)
}
return assetVersion, nil
}
このように内容はほとんど一つ内側の層で記述されたドメインロジックに基づいて一つ外側の層の外部との橋渡し処理を実行していくような内容になります。
ここでこのレイヤーのコードが一つ外側のレイヤーに依存してしまっていることに違和感を覚えるかもしれません。
これは「依存関係逆転の法則」と呼ばれる原則に基づいた実装となっています。
依存関係逆転の法則
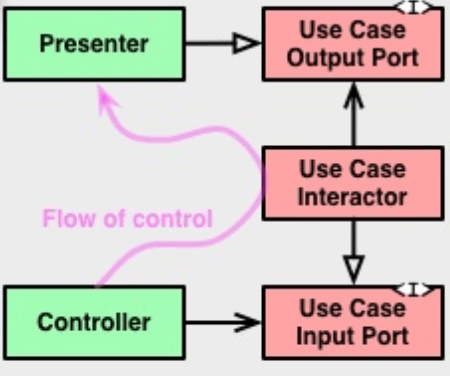
これは外側のInterface Adapters(緑)と内側のApplication Business Rules(赤)の依存関係が逆転していることを表現している図になります。
実装してみるとわかりますがこの2つのレイヤーに関しては依存関係を一方方向に保つことは現実的ではなくinterfaceを定義して下のレイヤーを上のレイヤーの抽象に依存させることで依存関係を逆転させることで実装を整理します。
先ほどのサンプルコードを用いて説明するとgatewayにはinterfaceが定義されておりAssetVersionApplicationの構造体はそのinterfaceに対して依存するという仕組みになっています。
type AssetVersionRepositoryInterface interface {
FindAssetVersionByID(ctx context.Context, assetVersionID int64) (*model.AssetVersion, error)
}
type AssetVersionApplication struct {
assetVersionRepository gateway.AssetVersionRepositoryInterface
}
これによって下のレイヤーは上のレイヤーの実装の変更に影響を受けることがなくなりテストコードにおいてもmockを使って上のレイヤーを気にせずに実装することができるようになります。
Enterprise Business Rules(黄)
コアビジネスロジックを実装するEnterprise Business Rules層はドメイン駆動開発を意識してフォルダ分けしています。
├── domain
├── value
├── entity
├── service
このレイヤーは中でvalue、entity、serviceと命名されたフォルダに分割していますがこの意味を理解するにはドメイン駆動開発についての知識が必要になります。
ドメイン駆動開発について
ドメイン駆動開発とアーキテクチャについて
クリーンアーキテクチャを語る文脈でドメイン駆動の話が挙がることが多いですがここで一旦ドメイン駆動とクリーンアーキテクチャの関連性について整理します。
クリーンアーキテクチャとドメイン駆動開発の関連を説明すると「クリーンアーキテクチャはドメイン駆動開発に影響を受けて発案されたアーキテクチャの1つ」です。
経緯
2003年にエリック・エヴァンス氏が「Domain-Driven Design」という書籍を出版しました。これは2011年に「エリック・エヴァンスのドメイン駆動設計」として日本でも翻訳、出版されます。
「エリック・エヴァンスのドメイン駆動設計」はビジネスサイドと円滑にドメイン知識を共有しビジネスサイドからの要求に強いシステムを開発する以下のような手法を紹介しました。
- ドメインエキスパートと開発者の間で共通言語となるユピキタス言語を定義し活用しましょう
- コードはレイヤー化してインフラへのアクセスを担当するレイヤー、ユーザとのインターフェイスを担当するレイヤー、アプリケーションの使用を明確にするレイヤービジネスロジックを実装するレイヤー、ビジネスロジックを担当するレイヤーに分けましょう
- ドメインモデルの性質を値オブジェクト、エンティティ、サービスに整理しましょう
などなど
ただ、エリック・エヴァンスのドメイン駆動設計で紹介された「レイヤードアーキテクチャ」ではドメイン知識とインフラレイヤーの実装が密結合になりやすいという問題があったためその問題を解決するべく「ヘキサゴナルアーキテクチャ」、「オニオンアーキテクチャ」など新たなアーキテクチャが発案されました。
クリーンアーキテクチャはそれらドメイン駆動開発に影響を受けて発案されたアーキテクチャの1つです。
詳しくは別のブログや書籍を参照してください
参考
https://zenn.dev/ayumukob/articles/ff183004d09ede
ドメインモデルについて
ここでHIKKYにおけるEntity層のフォルダ分割の話に戻りますがEntity層はドメイン駆動開発の手法の1つである「ビジネスモデルを値オブジェクト、エンティティ、サービスに分類する」という考えに基づいてフォルダを作っています。
混乱しそうですがクリーンアーキテクチャの文脈における「エンティティ」という言葉はドメイン駆動開発における値オブジェクト、エンティティ、サービスを内包した言葉です。
├── domain
├── value
├── entity
├── service
値オブジェクト、エンティティ、サービスについては「ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本」という書籍の言葉を借りて説明します。
値オブジェクトの性質
- 不変である
- 交換が可能である
- 等価性によって比較される
エンティティの性質
- 可変である
- 同じ属性であっても区別される
- 同一性により区別される
サービスの性質
- 複数の値オブジェクトやエンティティを組み合わせて利用される
- 値オブジェクトやエンティティに記述すると不自然なふるまいが記述される
先ほど紹介した書籍で紹介されている具体例を挙げると「ユーザ」というドメインモデルは同じユーザでもユーザ名やメールアドレス、パスワードが変わるなど「可変」であるためエンティティに分類されます
しかしユーザの性と名で構成される「氏名」というドメインモデルは値オブジェクトに区分されます。
このアプローチは奥が深い話ではありますが理解を深めて実践していくことで品質の高いコードを実現することができます。
サンプル
サンプルコードを書く前にアセットアップローダーの仕様を説明します
- アセットには「vrm」、「avatar」、「furniture」など用途を指定するラベルがつけられています
- その中に「sdk」というラベルがありsdkラベルが付与されたアセットは今回のバッチ処理の中で別サーバに情報が伝達されます
- HIKKYはVR空間を開発するための「VketCloud」というUnity SDKを提供しておりそのSDKで使われるアセットに「sdk」ラベルがつけられています
- SDKのバージョンによってHTTPリクエストを送るときのエンドポイントが分岐します
このドメインモデルを「ContentsPublisherDestination」という送信先のURLを表現する値オブジェクトとして定義し、ビジネスロジックを表現したコードが次のサンプルになります。
func ContentsPublisherDestination(sdkVersion float64, label, licenseId, worldId string) (string, error) {
var destination string
if label != "sdk" || sdkVersion < 4.1 {
destination = "/"
} else {
destination = licenseId + "/worlds/" + worldId
}
return destination, nil
}
このコードは次のようにApplication Business Rules層から呼び出されます
func (c *ContentsPublishApplication) GetDestination(ctx context.Context) (string, error) {
// sdkVersion、label、licenseId、worldId取得処理は略
destination, err := entity.ContentsPublisherDestination(
sdkVersion,
label,
licenseId,
worldId,
)
if err != nil {
return "", fmt.Errorf("failed to get destination. err: %s", err)
}
return destination, nil
}
ここまでを踏まえた全体のフォルダ構成
これら全てを踏まえた全体のフォルダ構成です。
├── infrastructure
├── adapter
├── presenter
├── controller
├── gateway
├── usecase
├── domain
├── value
├── entity
├── service
これは1つの方法でありプロジェクトメンバー間で合意が取れていれば別の命名、構成でも構いません。
例えばクリーンアークテクチャの図の用語に沿って「usecase」というフォルダ名を「application_business_rules」とする命名も考えられます。
結局クリーンアーキテクチャの何が嬉しい?
- システムの保守性、可読性が向上する
- ドメインモデルに変更があった場合どういった対応をすればいいのか影響を調査しやすくなりバグのリスクも抑えられる
- ドメイン知識、アプリケーションの振る舞いに関係しない技術コードをFrameworks & Driversに集約することで採用技術の変更に対応しやすくなる
- 例えば使っているデータベースを有償のものからOSSに変更する場合など
- コードをレイヤー化し疎結合にすることでテストコードを実装しやすくなる
特にシステムの保守性、可読性を向上させることは重要です。
例えば社内で開発しているSDK「VKetCloud」の新しいバージョンがリリースされアセットアップローダーで対応が求められたとします。
この時にきちんとコードがレイヤー分けされてドメインモデルがEntity層に集約されていればどの処理がVKetCloudのバージョンに依存しているのかすぐに把握し素早く対応することができます。
しかしアーキテクチャが整理されておらずVKetCloudのバージョンに依存したロジックが分散配置されていると影響調査にも時間がかかりますし予想できないバグが生まれやすくなります。
補足
ここまでの内容で議論になりそうな部分について補足説明をします。
補足1 外部サーバへのHTTPリクエストの実行はどのレイヤーで実装すべき?
HTTPリクエストの送信はアプリケーションの振る舞いやドメイン知識とは関係ないので厳密にはFrameworks & Driversに実装すべきですが現実的にはApplication Business RulesからPresenterのJson生成メソッドを呼び出して実行する形が自然かと思います。
補足2 gatewayに実装しているrepositoryメソッドは特定のデータベースに依存していないか?
gatewayに実装しているrepositoryメソッドはORマッパーbunのメソッドを使って実装されているのである意味bunの対応するデータベース(MySQL or PostgreSQL)に依存してしまっていると言えます。
これもクリーンアークテクチャを厳密に実現するのであればデータベースが例えばMySQLからDynamoDBなどのNoSQLデータベースに差し替えられても耐えうる構成にすべきかと思いますが実装上自然な形に収めるのであればInterface AdaptersにはRDB向けのORマッパーのロジックを実装するくらいがちょうどいいかと思います。
終わりに
クリーンアーキテクチャやドメイン駆動開発を導入することでシステムを変更に強く保守性の高いに状態に保つことができます。
非常に奥が深い分野ですのでこれからも様々な経験、議論を取り入れて進化していくことと思います。
ここまでお読みいただきありがとうございました!