概要
普段は業務でPython、PyTorchを使うことがどうしても多いですが、学生時代に研究で使っていたJuliaも恋しいものです。せっかくJuliaにもFlux.jlなる深層学習フレームワークがあるとのことなので、使ってみようという記事です。全てにおいて初心者なので、間違いやもっとこうしたらいいなどありましたら、ぜひコメントを書いていただけるとありがたいです。
環境
Julia v1.93
Flux v0.14.7
問題設定
KDD Cup 1999データセットというネットワーク侵入検出に関するデータセットを用いて、通信異常検知を行うことにします。通信異常検知は、DDOSなどの攻撃(異常通信)の検知を目的とします。
インプットデータ
データセットは上記リンクからダウンロードして適当な場所においておくことにします。今回は横着したいので数値型の列だけ使います。通信異常検知では教師なし学習が多いので、学習データは正常通信のみになるようにします。
# 使うライブラリ
using CSV
using DataFrames
using Flux
using Flux: mse, DataLoader
using Statistics
using Statistics: mean, std
using CUDA
using PyPlot
# KDD Cup 99データセットを読み込む
# データセットは https://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html からダウンロードできる
column_names = [
:duration, :protocol_type, :service, :flag, :src_bytes, :dst_bytes,
:land, :wrong_fragment, :urgent, :hot, :num_failed_logins,
:logged_in, :num_compromised, :root_shell, :su_attempted,
:num_root, :num_file_creations, :num_shells, :num_access_files,
:num_outbound_cmds, :is_host_login, :is_guest_login,
:count, :srv_count, :serror_rate, :srv_serror_rate,
:rerror_rate, :srv_rerror_rate, :same_srv_rate, :diff_srv_rate,
:srv_diff_host_rate, :dst_host_count, :dst_host_srv_count,
:dst_host_same_srv_rate, :dst_host_diff_srv_rate,
:dst_host_same_src_port_rate, :dst_host_srv_diff_host_rate,
:dst_host_serror_rate, :dst_host_srv_serror_rate,
:dst_host_rerror_rate, :dst_host_srv_rerror_rate,
:label
]
# CSV.readを使用してCSVファイルを読み込む
df = CSV.read("../datasets/kddcup.data_10_percent", DataFrame, header=column_names)
# label列で"normal."を0、それ以外を1にする
df[!, :label] = [label == "normal." ? 0 : 1 for label in df[!, :label]]
# 数値型の列名を取り出す
numeric_columns = filter(col -> eltype(df[!, col]) <: Number, names(df))
データを正規化する用の関数をつくって適用します(sklearn.preprocessingのStandardScalerに該当するものがあるんでしょうか...)。
function normalize_columns(df::DataFrame, columns::Vector{String})
normalized_df = select(df[!, columns], Not(:label))
# 削除する列を保持するための配列
cols_to_remove = []
for col in names(normalized_df)
if eltype(normalized_df[!, col]) <: Number
col_std = std(normalized_df[!, col])
# 標準偏差が0の場合は列を削除リストに追加
if col_std == 0
push!(cols_to_remove, col)
else
# 標準偏差が0でなければ正規化を行う
col_mean = mean(normalized_df[!, col])
normalized_df[!, col] = (normalized_df[!, col] .- col_mean) ./ col_std
end
end
end
# 削除された列名を表示
if length(cols_to_remove) > 0
println("削除された列名: ", join(cols_to_remove, ", "))
else
println("削除された列はないよ。")
end
# 標準偏差が0の列を削除
normalized_df = select!(normalized_df, Not(cols_to_remove))
normalized_df = select!(normalized_df, [col for col in names(normalized_df) if eltype(normalized_df[!, col]) <: Number])
normalized_df[!, :label] = df[!, :label]
return normalized_df
end
# 正規化したデータをdataと名付ける
data = normalize_columns(df, numeric_columns)
データを分割します(sklearn.model_selectionのtrain_test_splitに該当するものがあるんでしょうか…)
function split_dataframe(df::DataFrame, train_size::Float64)
# データの行数を取得
n = nrow(df)
# トレーニングデータの行数を計算
train_rows = floor(Int, train_size * n)
# トレーニングデータとテストデータを分割
train_df = df[1:train_rows, :]
test_df = df[train_rows + 1:end, :]
return train_df, test_df
end
# 学習データとテストデータに分ける
train_data, test_data = split_dataframe(data, 0.5)
# 学習データとして正常通信(label列が0)のみを使う
train_data = train_df[train_df[!, :label] .== 0, :]
# 説明変数と目的変数に分ける
X_train = train_data[!, Not(:label)]
y_train = train_data[!, :label]
X_test = test_data[!, Not(:label)]
y_test = test_data[!, :label]
# DataFrameからArrayに変換
X_train_array = Float32.(transpose(Matrix(X_train)))
# Flux用のデータローダーの作成(gpuにのせる)
data_loader = Flux.DataLoader((X_train_array, X_train_array) |> gpu, batchsize=1024, shuffle=true)
モデルの設定
異常検知の手法として、今回はVAE(Variational Autoencoder)を用いることにします
エンコーダとデコーダの定義
エンコーダは、入力データを潜在空間のパラメーター(平均と分散)にマッピングします。デコーダは、潜在空間から入力データを再構成するようにします。
input_dim = size(X_train_array)[1] # -> 36
hidden_dim = 20
latent_dim = 10
output_dim = input_dim # -> 36
# エンコーダの定義
encoder = Chain(
Dense(input_dim, hidden_dim, tanh),
Dense(hidden_dim, latent_dim * 2) # 平均と分散のために2倍の次元
)
# デコーダの定義
decoder = Chain(
Dense(latent_dim, hidden_dim, sigmoid),
Dense(hidden_dim, output_dim) # 出力次元は入力次元と同じ
)
損失関数の定義
VAEの損失関数を作ります。最近、ゼロから作るDeep Learning5の公開レビューがされていてVAEを勉強したので、間違っていないとは思いますが、なにかおかしかったら指摘してください。
# 潜在変数のサンプリング関数
function sample_latent(mu_logvar)
# mu と logvar の抽出
mu = mu_logvar[1:latent_dim, :]
logvar = mu_logvar[latent_dim+1:end, :]
# 潜在空間のサンプリング
sigma = exp.(0.5 .* logvar)
epsilon = randn(size(mu))
return mu .+ sigma .* epsilon
end
# VAEモデル
function vae(x)
mu_logvar = encoder(x)
z = sample_latent(mu_logvar)
return decoder(z), mu_logvar
end
# 損失関数
function vae_loss(x)
recon, mu_logvar = vae(x)
recon_loss = Flux.mse(x, recon)
# mu と log_var の抽出
mu = mu_logvar[1:latent_dim, :]
log_var = mu_logvar[latent_dim+1:end, :]
# KLダイバージェンス
kl_div = -0.5 * sum(1 .+ log_var .- mu.^2 .- exp.(log_var))
return recon_loss + kl_div
end
訓練
うおー訓練しろー。
# エンコーダとデコーダのパラメータを取得
params = Flux.params(encoder, decoder)
# 訓練するエポック数を設定
epochs = 500
# 各エポックの損失を保存するための配列
losses = []
# オプティマイザの定義(RAdamを使用し、学習率は1e-5)
optim = RAdam(1e-5)
# 訓練ループ開始
for epoch in 1:epochs
# 現在のエポックの損失を保存するための配列
epoch_losses = []
# データローダーを使用してバッチ処理
for (x_batch, _) in data_loader
# 損失関数とその勾配を計算
loss, grads = Flux.withgradient(() -> vae_loss(x_batch)[2], params)
# オプティマイザを使用してパラメータを更新
Flux.Optimise.update!(optim, params, grads)
# 現在のバッチの損失をエポックの損失リストに追加
push!(epoch_losses, loss)
end
# エポックの平均損失を計算
epoch_loss = mean(epoch_losses)
# エポックの平均損失を保存
push!(losses, epoch_loss)
# 100エポックごとに現在のエポックと損失を出力
if epoch % 100 == 0
println("Epoch $epoch: Loss = $epoch_loss")
end
end
Lossをプロットするとこんな感じです。
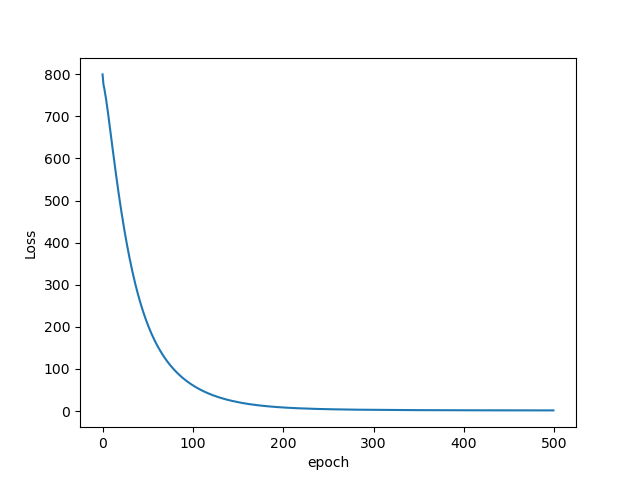
うまく学習できてそうです。
テストと評価
# DataFrameからMatrixへの変換
X_test_array = Matrix(X_test)
# 異常スコアの計算
y_score = [Flux.mse(vae(X_test_array[i, :])[1], X_test_array[i, :]) for i in 1:size(X_test_array, 1)]
PR曲線・PRAUCを求めるライブラリをみつけることができなかったので、自分でつくりました。もっと適切なものがあれば教えてください。
function calculate_precision_recall(predicted_probs, true_labels, thresholds)
precisions = []
recalls = []
for threshold in thresholds
predicted_labels = [ifelse(prob >= threshold, 1, 0) for prob in predicted_probs]
tp = sum((predicted_labels .== 1) .& (true_labels .== 1))
fp = sum((predicted_labels .== 1) .& (true_labels .== 0))
fn = sum((predicted_labels .== 0) .& (true_labels .== 1))
precision = tp / (tp + fp)
recall = tp / (tp + fn)
push!(precisions, precision)
push!(recalls, recall)
end
return precisions, recalls
end
function calculate_prauc(recalls, precisions)
area = 0.0
for i in 1:length(recalls)-1
width = recalls[i] - recalls[i+1]
height = (precisions[i+1] + precisions[i]) / 2
area += width * height
end
return area
end
# 異なる閾値
thresholds = minimum(y_score):0.5:maximum(y_score)
# 適合率と再現率の計算
precisions, recalls = calculate_precision_recall(y_score, y_test, thresholds)
# PRAUCの計算
pr_auc = calculate_prauc(recalls, precisions)
println("PR-AUC: $pr_auc")
# PR曲線をプロット
plt.plot(recalls, precisions)
plt.ylim(0,1)
plt.xlim(0,1)
plt.ylabel("Precision")
plt.xlabel("Recall")
今回PRAUCは0.87でした。また、PR曲線はこんな感じになりました。
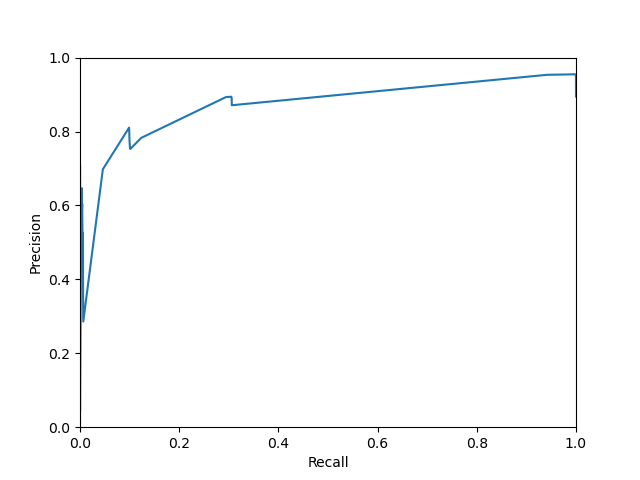
まずまずじゃないでしょうか。
最後に
本記事ではFlux.jlを用いてVAEを実装し、異常検知をやってみました。なかなかFlux.jlの使い方がよくわからない&実装の参考例があまりなく苦労しましたが久しぶりにJuliaを書けて楽しかったです。仕事でも書けたらいいなあ。