

前書き
会社でドローンが欲しいと部長にダメもとで言ってみたら、技術的に何か面白いことできるならいいよって。
ということで買ったのがコレ。Parrot ドローン Mambo。プログラマブルでお手頃価格のドローンを購入。
ということで試してみました。
目的とゴール
何事も目的大事。改めて明確に。
- 会社で購入したドローンで技術的チャレンジをする。
そのために達成すべき3つのゴール。
- 音声でコントロールする
- クラウドを使う
- IoTと言えることをやる
実現案
Raspberry piから音声コントロールでドローンを飛ばす!
なんだか良い感じ![]()
仕様
- ボタンを押すと音声を認識
- 音声認識中はLEDが光ってお知らせ
- 認識した音声をAzureのBing Speech APIでテキスト化
- 決められた音声コマンドでドローンを飛ばす
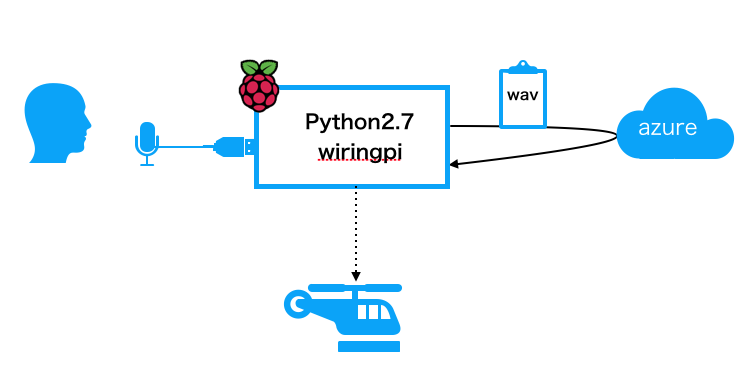
全体像
絵にしてみるとこんな感じになる。
マイクから拾った音声をwav形式にしてBing Speech APIでテキスト化。
テキストが決められた内容(例:離陸、着陸、など)の場合、それに応じたドローンの制御を行う。
必要なもの
ハードウェア
- Parrot ドローン Mambo
- raspberry pi3
- USBマイク
- LED
- プッシュボタン
- ブレッドボード
- 抵抗 10kΩ 2個
ソフトウェア
- Python2.7
- wiringpy (GPIOを操作するためのpythonモジュール)
- pymambo
- bluepy
- bluez
- Bing Speech APIのAPI key
OSにRASPBIAN STRETCH LITEを使いましたが、上記以外でOS標準 or 一般的なものは割愛。
ハードウェア的設計
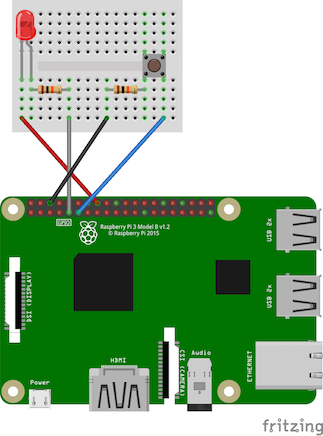
raspberry pi環境設定
sudo apt-get install bluetooth python-bluez
pip install untangle bluepy wiringpi
git clone https://github.com/amymcgovern/pymambo.git
python実装
pymamboのディレクトリ内にファイルを作成する前提です。
今回は「離陸」と「着陸」に反応するように実装。
parrot ドローン mamboのMACアドレスは、pymambo付属のfindMambo.pyを使えば簡単に見つけられます。
# coding: utf-8
import requests
import urllib
import json
import subprocess
from subprocess import Popen
import wiringpi
from Mambo import Mambo
# for azure api key
apikey = "{API KEY}"
mamboAddr = "{DRONE MAC ADDRESS}"
button_pin = 17 # No.11 pin
led_pin = 23
def record( filepath="command.wav" ):
# マイクボリュームの調整
p = Popen( "amixer sset Mic 16 -c 1", shell=True )
p.wait()
# arecordコマンドで2秒間録音する
# plughwはarecord -lコマンドで調べる
cmd = "arecord -d 2 -D plughw:1,0 " + filepath
popen = Popen( cmd, shell=True )
wiringpi.digitalWrite( led_pin, 1 )
popen.wait()
wiringpi.digitalWrite( led_pin, 0 )
return filepath
def recognize_speech_from_wav( filepath="command.wav" ):
with open(filepath, 'rb') as infile:
raw_data = infile.read()
token = _authorize()
txt = _speech_to_text( raw_data , token, lang="ja-JP", samplerate=8000, scenarios="ulm")
return txt
def _authorize():
url = "https://api.cognitive.microsoft.com/sts/v1.0/issueToken"
headers = {
"Content-type": "application/x-www-form-urlencoded",
"Content-Length": "0",
"Ocp-Apim-Subscription-Key": apikey
}
response = requests.post(url, headers=headers)
if response.ok:
_body = response.text
return _body
else:
response.raise_for_status()
def _speech_to_text( raw_data, token, lang="ja-JP", samplerate=8000, scenarios="ulm"):
data = raw_data
params = {
"language": lang,
"format": "json",
"request_id": "request_id_999"
}
# Bing Speech API呼び出し(dictationモードを指定)
url = "https://speech.platform.bing.com/speech/recognition/dictation/cognitiveservices/v1?" + urllib.urlencode(params)
headers = {
"Content-type": "audio/wav; samplerate={0}".format(samplerate),
"Authorization": "Bearer " + token
}
response = requests.post(url, data=data, headers=headers)
if response.ok:
# 文字化け対策のためutf-8で処理する
response.encoding = "utf-8"
print(response.text)
result = response.json()["DisplayText"]
return result
else:
raise response.raise_for_status()
if __name__ == '__main__':
mambo = Mambo(mamboAddr)
print "trying to connect..."
success = mambo.connect(num_retries=3)
print "connected: %s" % success
# バッテリーや飛行状態などを取得
mambo.smart_sleep(2)
mambo.ask_for_state_update()
mambo.smart_sleep(2)
# GPIOの初期化とPINモード設定
wiringpi.wiringPiSetupGpio()
wiringpi.pinMode( button_pin, 0 )
wiringpi.pinMode( led_pin, 1 )
wiringpi.pullUpDnControl( button_pin, 2 )
print "ready"
while True:
if( wiringpi.digitalRead(button_pin) == 0 ):
print ("Switch ON")
wav = record()
txt = recognize_speech_from_wav(wav)
print txt
if txt == u"離陸":
print "taking off!"
mambo.safe_takeoff(5)
mambo.smart_sleep(2)
print "done!"
elif txt == u"着陸":
print "landing"
mambo.safe_land()
mambo.smart_sleep(5)
else:
print "NG"
else:
wiringpi.digitalWrite( led_pin, 0 )
mambo.smart_sleep(0.2)
ハマりどころ、ハマっていること
pymamboでコネクトすると何故かすぐに切断する。付属のサンプル(demoTricks.py)だと問題ないのに何故だろう、と思って調べていたところ、ループ処理中のtime.sleep()が問題だった。
pymamoboのReadMeにも書かれていることで、time.sleep()を使うとBluetoothの接続が切れる。これに気づかずハマった。
それ以降、うまくいくようになったけど、時々接続が切れることもある。接続が切れた場合に備えて、スマホに公式アプリを入れておけばドローンの制御を奪って着陸させることができる。
突如切れる原因として、bluepyの制限が影響しているという意見もあるみたいですが、詳細は不明。
終わりに
ゴールは一応達成したつもり。
今回は離陸と着陸だけで、種類を増やせばフリップや前進・後進などもできます。
Bing Speech APIを利用して気づきましたが、思った以上にちゃんと言葉を認識してくれる。
クラウドを使わず音声認識しようと思うと、よくあるのはJuliusなどのツールをインストールして、認識するための辞書を作る、という感じで一手間必要です。以前試したところ認識率はそれほど高くない印象なので、Azureの手軽さと認識率、さらには無料枠があるということもあって、かなり良い感じ。
あえてクラウド音声認識のデメリットをあげるとすると、
- 音声認識開始のアクションがなにか必要(今回だとプッシュボタン)
- wavファイルにしてからAPIにpostする必要があるのでオーバーヘッドが大きい
- 通信速度・容量が反応速度に大きく影響する
という感じでしょうか。
時と場合に応じてJuliusとの棲み分け、あるいは同居が必要かと思います。
「OK,google」みたいな認識を開始させるためのトリガーは常時Juliusで受け付けて、それ以降はクラウドと連携する、とかかな。
色々試すと可能性が広がるので面白そう。