GetMediaForFragmentList, GetClip または GetImages API を使い、動画や画像を取得して処理する方法です。
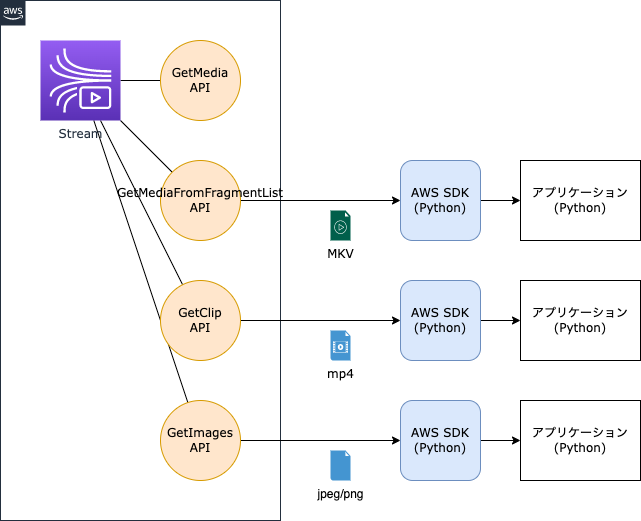
関連
HLS から受信して処理 (OpenCV+ffmpeg)
Amazon Kinesis Video Streams から HLS URL を取得し、VideoCapture に指定することで、HLS から受信することができます。
- LIVE(最新映像)/LIVE_REPLAY(指定日時以降の過去映像)/ON_DEMAND(指定区間の過去映像)のいずれかを指定して再生可能。
- HLS の仕組み上、セグメント長(1s~10s)ごとに映像が更新されるため、元映像のセグメント長に応じて遅延が発生する。
- フレームごとの日時などのメタデータが取得できない。(と思われる)
import os
import boto3
import cv2
OUTPUT_DIR = "output"
def get_data_endpoint(stream_name: str, api_name: str) -> str:
"""
call GetDataEndpoint API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_GetDataEndpoint.html
"""
kinesis_video = boto3.client("kinesisvideo")
res = kinesis_video.get_data_endpoint(StreamName=stream_name, APIName=api_name)
return res["DataEndpoint"]
def get_hls_streaming_session_url(stream_name: str) -> str:
"""
call GetHLSStreamingSessionURL API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_reader_GetHLSStreamingSessionURL.html
"""
res = boto3.client(
"kinesis-video-archived-media", endpoint_url=get_data_endpoint(stream_name, "GET_HLS_STREAMING_SESSION_URL")
).get_hls_streaming_session_url(
StreamName=stream_name,
PlaybackMode="LIVE"
)
return res["HLSStreamingSessionURL"]
def process(stream_name: str):
hls_url = get_hls_streaming_session_url(stream_name)
cap = cv2.VideoCapture(hls_url)
for i in range(300):
ret, frame = cap.read()
if frame is None:
break
file_path = os.path.join(OUTPUT_DIR, f"{i:04d}.png")
cv2.imwrite(file_path, frame)
print(f"Saved: {file_path}")
cap.release()
指定期間のセグメントデータを取得して処理
ListFragments + GetMediaFromFragmentList API でセグメント単位で受信し、一旦ファイルに保存してから各フレームを取得して処理します。
- 指定区間の過去映像のみ取得可能
OpenCV+ffmpeg の場合
import operator
import os
from datetime import datetime
from tempfile import NamedTemporaryFile
import boto3
import cv2
from botocore.response import StreamingBody
OUTPUT_DIR = "output"
READ_FRAGMENTS = 1 # いちどに読み込むフラグメントの数
def get_data_endpoint(stream_name: str, api_name: str) -> str:
"""
call GetDataEndpoint API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_GetDataEndpoint.html
"""
kinesis_video = boto3.client("kinesisvideo")
res = kinesis_video.get_data_endpoint(StreamName=stream_name, APIName=api_name)
return res["DataEndpoint"]
def list_fragments(stream_name: str, start_time: datetime, end_time: datetime) -> list[dict]:
"""
call ListFragments API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_reader_ListFragments.html
"""
res = boto3.client(
"kinesis-video-archived-media", endpoint_url=get_data_endpoint(stream_name, "LIST_FRAGMENTS")
).list_fragments(
StreamName=stream_name,
FragmentSelector={
"FragmentSelectorType": "PRODUCER_TIMESTAMP",
"TimestampRange": {
"StartTimestamp": start_time,
"EndTimestamp": end_time
}
}
)
return res["Fragments"]
def get_media_for_fragment_list(stream_name, fragment_numbers: list[str]) -> StreamingBody:
"""
call GetMediaForFragmentList API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_reader_GetMediaForFragmentList.html
"""
res = boto3.client(
"kinesis-video-archived-media", endpoint_url=get_data_endpoint(stream_name, "GET_MEDIA_FOR_FRAGMENT_LIST")
).get_media_for_fragment_list(
StreamName=stream_name,
Fragments=fragment_numbers
)
return res["Payload"]
def process_media(start_dt: datetime, media: StreamingBody):
print(f"--> {start_dt}")
with NamedTemporaryFile(suffix=".mkv") as f:
f.write(media.read())
cap = cv2.VideoCapture(f.name)
i = 0
while True:
ret, frame = cap.read()
if frame is None:
break
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
file_path = os.path.join(OUTPUT_DIR, f"{start_dt}.{i:02d}.png")
cv2.imwrite(file_path, frame)
print(f"Saved: {file_path}")
i += 1
cap.release()
def chunks(lst: list, n: int) -> list:
for i in range(0, len(lst), n):
yield lst[i:i + n]
def process(stream_name: str, start_dt: datetime, end_dt: datetime):
all_fragments = list_fragments(stream_name, start_dt, end_dt)
sorted_fragments = sorted(all_fragments, key=operator.itemgetter("ProducerTimestamp"))
for fragments in chunks(sorted_fragments, READ_FRAGMENTS):
fragment_numbers = list(map(lambda x: x["FragmentNumber"], fragments))
media = get_media_for_fragment_list(stream_name, fragment_numbers)
process_media(fragments[0]["ProducerTimestamp"], media)
imageio+ffmpeg の場合
def process_media(start_dt: datetime, media: StreamingBody):
print(f"--> {start_dt}")
with NamedTemporaryFile(suffix=".mkv") as f:
f.write(media.read())
reader = imageio.get_reader(f.name, "ffmpeg") # class imageio.plugins.ffmpeg.FfmpegFormat.Reader
metadata = reader.get_meta_data()
print(json.dumps(metadata))
for i, frame in enumerate(reader):
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
file_path = os.path.join(OUTPUT_DIR, f"{start_dt}.{i:04d}.png")
cv2.imwrite(file_path, frame)
print(f"Saved: {file_path}")
reader.close()
画像を取得
GetImages API を使用して、指定期間の画像を JPEG/PNG 形式で取得できます。
import base64
from datetime import datetime
import boto3
def get_data_endpoint(stream_name: str, api_name: str) -> str:
"""
call GetDataEndpoint API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_GetDataEndpoint.html
"""
kinesis_video = boto3.client("kinesisvideo")
res = kinesis_video.get_data_endpoint(StreamName=stream_name, APIName=api_name)
return res["DataEndpoint"]
def get_images(stream_name: str, start_datetime: datetime, end_datetime: datetime, interval: int):
"""
call GetImages API
https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_reader_GetImages.html
"""
res = boto3.client(
"kinesis-video-archived-media", endpoint_url=get_data_endpoint(stream_name, "GET_IMAGES")
).get_images(
StreamName=stream_name,
StartTimestamp=start_datetime,
EndTimestamp=end_datetime,
SamplingInterval=interval,
ImageSelectorType="PRODUCER_TIMESTAMP",
Format="PNG",
)
return res
def process(stream_name: str, start_datetime: datetime, end_datetime: datetime, interval: int):
res = get_images(stream_name, start_datetime, end_datetime, interval)
for image in res["Images"]:
dt: datetime = image["TimeStamp"]
if "ImageContent" in image:
with open("{}.png".format(dt.strftime("%Y%m%d%H%M%S")), "wb") as f:
f.write(base64.b64decode(image["ImageContent"]))