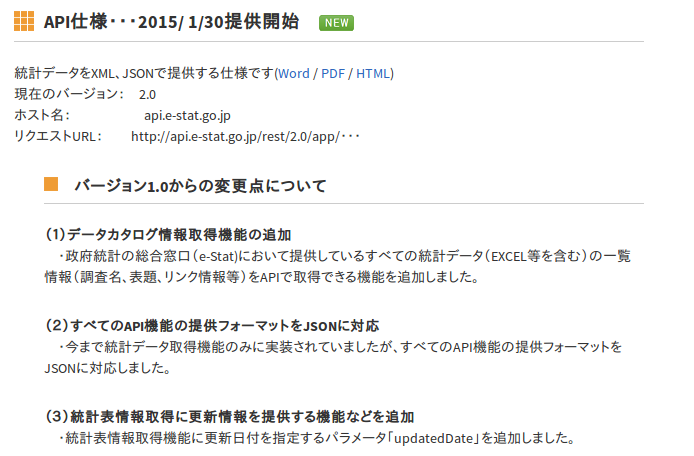
e-StatのAPI(ver.2)について
e-StatのAPI仕様がバージョンアップしました.
Pythonスクリプトの作成
先人の投稿を参考にver.2に対応したスクリプトを作りました(Python 2.7).
編集前のスクリプトは,引数にAPI IDを含んでいますが,毎回入力するのは面倒なので,コード内で書いています.
また,政府統計コードをstats_codeで入力するようにしています.
統計表情報の検索
getStatsListSample2015.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import urllib
import urllib2
from lxml import etree
import sys
import codecs
def main(argvs, argc):
if argc != 3:
print ("Usage #python %s api_key search_kind stats_code" % argvs[0])
return 1
api_key = '' #取得したAPI IDを入力
search_kind = argvs[1]
stats_code = argvs[2]
stats_code = urllib.quote(stats_code.encode('utf-8'))
url = ('http://api.e-stat.go.jp/rest/2.0/app/getStatsList?appId=%s&lang=J&statsCode=%s&searchKind=%s' % (api_key, stats_code, search_kind))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
result = root.find('RESULT')
data_list = root.find('DATALIST_INF')
table_infs = data_list.xpath('./TABLE_INF')
for table_inf in table_infs:
print ((u'--------------').encode('utf-8'))
for iterator in table_inf.getiterator():
if iterator.text is not None:
itag = iterator.tag.encode('utf-8')
itext = iterator.text.encode('utf-8')
if iterator.items() is not None:
if iterator.get('id') is not None:
print itag,iterator.get('id').encode('utf-8'),itext
elif iterator.get('code') is not None:
print itag,iterator.get('code').encode('utf-8'),itext
elif iterator.get('no') is not None:
print itag,iterator.get('no').encode('utf-8'),itext
else:
print itag,itext
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
使用例:
python getStatsListSample2015.py 1 00200521 > gSLS00200521.dat
結果:
gSLS00200521.dat
--------------
TABLE_INF 0000030001
STAT_NAME 00200521 国勢調査
GOV_ORG 00200 総務省
STATISTICS_NAME 昭和55年国勢調査 第1次基本集計 全国編
TITLE 00101 男女の別(性別)(3),年齢5歳階級(23),人口 全国・市部・郡部・都道府県(47),全域・人口集中地区の別
CYCLE -
SURVEY_DATE 198010
OPEN_DATE 2007-10-05
SMALL_AREA 0
MAIN_CATEGORY 02 人口・世帯
SUB_CATEGORY 01 人口
OVERALL_TOTAL_NUMBER 3651
UPDATED_DATE 2008-03-19
--------------
TABLE_INF 0000030002
STAT_NAME 00200521 国勢調査
GOV_ORG 00200 総務省
STATISTICS_NAME 昭和55年国勢調査 第1次基本集計 全国編
TITLE 00102 男女の別(性別)(3),年齢各歳階級(103),人口 全国・市部・郡部・都道府県(47),全域・人口集中地区の別
CYCLE -
SURVEY_DATE 198010
OPEN_DATE 2007-10-05
SMALL_AREA 0
MAIN_CATEGORY 02 人口・世帯
SUB_CATEGORY 01 人口
OVERALL_TOTAL_NUMBER 16365
UPDATED_DATE 2008-03-19
--------------
・
・
・
統計表をcsvにして出力
export_csv2015.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import urllib2
from lxml import etree
import csv
def export_statical_data(writer, api_key, stats_data_id, class_object, start_position):
"""
統計情報のエクスポート
"""
url = ('http://api.e-stat.go.jp/rest/2.0/app/getStatsData?limit=10000&appId=%s&lang=J&statsDataId=%s&metaGetFlg=N&cntGetFlg=N' % (api_key, stats_data_id))
if start_position > 0:
url = url + ('&startPosition=%d' % start_position)
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
row = []
datas = {}
value_tags = root.xpath('//STATISTICAL_DATA/DATA_INF/VALUE')
for value_tag in value_tags:
row = []
for key in class_object:
val = value_tag.get(key)
if val in class_object[key]['objects']:
level = '';
if 'level' in class_object[key]['objects'][val]:
if class_object[key]['objects'][val]['level'].isdigit():
level = ' ' * (int(class_object[key]['objects'][val]['level']) - 1)
text = ("%s%s" % (level , class_object[key]['objects'][val]['name']))
row.append(text.encode('utf-8'))
else:
row.append(val.encode('utf-8'))
row.append(value_tag.text)
writer.writerow(row)
next_tags = root.xpath('//STATISTICAL_DATA/TABLE_INF/NEXT_KEY')
if next_tags:
if next_tags[0].text:
export_statical_data(writer, api_key, stats_data_id, class_object, int(next_tags[0].text))
def get_meta_data(api_key, stats_data_id):
"""
メタ情報取得
"""
url = ('http://api.e-stat.go.jp/rest/2.0/app/getMetaInfo?appId=%s&lang=J&statsDataId=%s' % (api_key, stats_data_id))
req = urllib2.Request(url)
opener = urllib2.build_opener()
conn = opener.open(req)
cont = conn.read()
parser = etree.XMLParser(recover=True)
root = etree.fromstring(cont, parser)
class_object_tags = root.xpath('//METADATA_INF/CLASS_INF/CLASS_OBJ')
class_object = {}
for class_object_tag in class_object_tags:
class_object_id = class_object_tag.get('id')
class_object_name = class_object_tag.get('name')
class_object_item = {
'id' : class_object_id,
'name' : class_object_name,
'objects' : {}
}
class_tags = class_object_tag.xpath('.//CLASS')
for class_tag in class_tags:
class_item = {
'code' : class_tag.get('code'),
'name' : class_tag.get('name'),
'level' : class_tag.get('level'),
'unit' : class_tag.get('unit')
}
class_object_item['objects'][class_item['code']] = class_item
class_object[class_object_id] = class_object_item
return class_object
def export_csv(api_key, stats_data_id, output_path):
"""
指定の統計情報をCSVにエクスポートする.
"""
writer = csv.writer(open(output_path, 'wb'),quoting=csv.QUOTE_ALL)
class_object = get_meta_data(api_key, stats_data_id)
row = []
for key in class_object:
title = class_object[key]['name']
row.append(title.encode('utf-8'))
row.append('VALUE')
writer.writerow(row)
export_statical_data(writer, api_key, stats_data_id, class_object, 1)
def main(argvs, argc):
if argc != 2:
print ("Usage #python %s api_key stats_data_id output_path" % argvs[0])
return 1
api_key = '' #取得したAPI IDを入力
stats_data_id = argvs[1]
output_path = 'e-stat' + argvs[1] + '.csv'
export_csv(api_key, stats_data_id, output_path)
if __name__ == '__main__':
argvs = sys.argv
argc = len(argvs)
sys.exit(main(argvs, argc))
使用例:
python export_csv2015.py 0000030001
結果:
e-stat0000030001.csv
"全域・集中の別030002","年齢5歳階級A030002","男女A030001","時間軸(年次)","全国都道府県030001","VALUE"
"全域","総数","男女総数","1980年","全国","117060396"
"全域","総数","男女総数","1980年","全国市部","89187409"
"全域","総数","男女総数","1980年","全国郡部","27872987"
"全域","総数","男女総数","1980年","北海道","5575989"
"全域","総数","男女総数","1980年","青森県","1523907"
"全域","総数","男女総数","1980年","岩手県","1421927"
"全域","総数","男女総数","1980年","宮城県","2082320"
"全域","総数","男女総数","1980年","秋田県","1256745"
"全域","総数","男女総数","1980年","山形県","1251917"
"全域","総数","男女総数","1980年","福島県","2035272"
"全域","総数","男女総数","1980年","茨城県","2558007"
"全域","総数","男女総数","1980年","栃木県","1792201"
"全域","総数","男女総数","1980年","群馬県","1848562"
"全域","総数","男女総数","1980年","埼玉県","5420480"
"全域","総数","男女総数","1980年","千葉県","4735424"
"全域","総数","男女総数","1980年","東京都","11618281"
"全域","総数","男女総数","1980年","神奈川県","6924348"
"全域","総数","男女総数","1980年","新潟県","2451357"
"全域","総数","男女総数","1980年","富山県","1103459"
・
・
・
Python 3しか無い方
Python 2.7でないと動かないので,Python 3しか無い方は環境構築しておきましょう.