勾配消失問題
勾配消失問題とは
→誤差逆伝番法が下位層に進んでいく(出力層から入力層の向き)に連れて、勾配が緩やかになっていく
勾配が無くなると、パラメーターの更新がかからなくなる
勾配消失に気づくためには、データを可視化する(グラフ化など)ことが有効である
シグモイド関数
0~1の間を緩やかに変化する。
出力の変化が小さいため、勾配消失問題が発生しやすい
シグモイド関数を微分した時、最大値は0.25(入力値が0の時)
→0.25という値が、どんどん小さくなり、勾配が無くなっていく
勾配消失の解決方法
・活性化関数の選択
→ReLU関数が最も使われている活性化関数(勾配消失問題が発生しにくい)
・重みの初期値設定
→重みの初期値を0にすると、全ての値が0で伝わっていくため、パラメーターのチューニングが行われない
・バッチ正規化
→入力データが学習の度に大きく変わることを防ぐ効果があり、それによって中間層の学習が安定化する
計算の高速化のメリットもある
→勾配消失問題が発生しにくくなる
実装
・シグモイド関数では、勾配が小さく、学習が進んでいない
・ReLU関数では、500以降、勾配が大きくなった(学習が進んでいる)
・Xavierは、ReLU関数よりも早く勾配が大きくなった
・Heでは、当初より高い値だが、あまり勾配差はない
→活性化関数を変更することで、大きな違いが発生
学習率最適化手法
データの集め方や、自身でデータを取りに行くためのプロダクトが必要。
学習率
大きい場合→最適解にたどり着かず、発散する
小さい場合→収束までに時間がかかる。
また、大域局所最適値に収束しづらくなる
学習率最適化手法
・モメンタム
→慣性は0.5~0.9の範囲内が多い
学習率が小さい場合のデメリットである局所的最適解に、ならない
勾配が同じ方向に向いている次元に向けて増加。
そして、勾配が方向を変える次元に向けての更新を減少させる。結果的に収束が早まり、振動を抑制することができる。
→学習率を0.01から0.05に変更したところ、600以降から勾配が大きくなった
・AdaGrad
→緩やかな斜面に対して、最適解に近づける
鞍点問題を引き起こすことがある(ある方向で見ると極大値だが、他の方向から見ると極小値)
学習率をパラメータに適応させる。まれなパラメータに対してはより大きな更新を、頻出のパラメータに対してはより小さな更新を実行。
このような理由から、スパース(少ない)なデータを扱うのに適している。
「Adagradは急速に学習率が低下する」という問題を解決する必要から開発された
・RMSprop
→パラメーターの調整が少なくて済む
局所的最適解にならない
・Adam
→モメンタムの、過去の勾配の指数関数的減衰平均
RMSpropの、過去の勾配の二乗の指数関数的減衰平均
使用されることが多い
・SGD
→学習率を変えると、勾配が少し大きくなる
過学習
→テスト誤差と訓練誤差で学習曲線が乖離
・リッジ回帰
→ハイパーパラメータを大きな値に設定すると、全ての重みが限りなく0に近づく
ハイパーパラメータを0に設定すると、線形回帰となる
バイアス項は正則化されない。
誤差関数に対して、正則化項を加える
・Weight decay
→重みが大きいと重要度が高いと判断されるため、過学習が発生しやすい
過学習が起こりそうな重みの大きさ以下で重みをコントロール
・ドロップアウト
→閾値を超えなかったノードは、不活性化させる
・overfiting
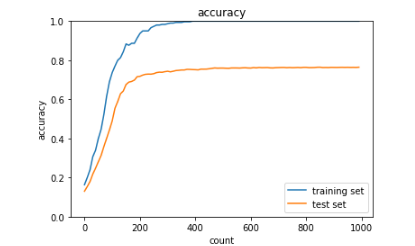
→過学習が起こっている
・L2
→過学習は起きてはいるが、先ほどよりもよい
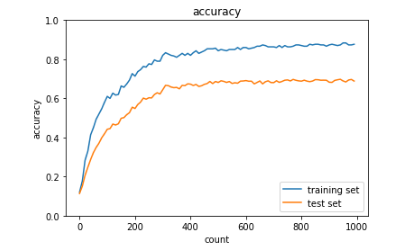
・L1
→抑制ができている
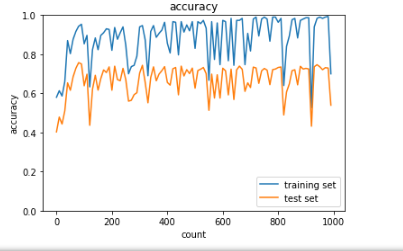
・L2のweight_decay_lambda = 1に変更
→過学習が抑制されるが学習が進まなくなる
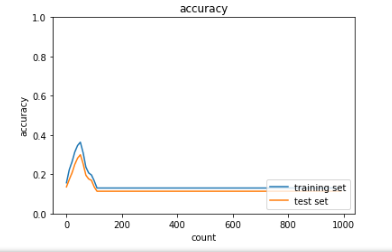
・Dropout
dropout_ratio = 0.15を0.1に変更
→勾配が緩やかになった
↓
畳み込みニューラルネットワークの概念
全結合層では奥行の学習(空間の学習)ができず、一次元のデータとなる
→畳み込み層では可能
フィルターと組み合わせる入力画像の範囲をずらしていく
・パティング
→ゼロパティング
入力画像のデータをそのまま使うためには0が向いている
(影響が無いため)
・ストライド
→ずらす
・チャンネル
→入力値を分割した層の数をチャンネル数という
チャンネル数と同じ数だけ、フィルターは必要となる
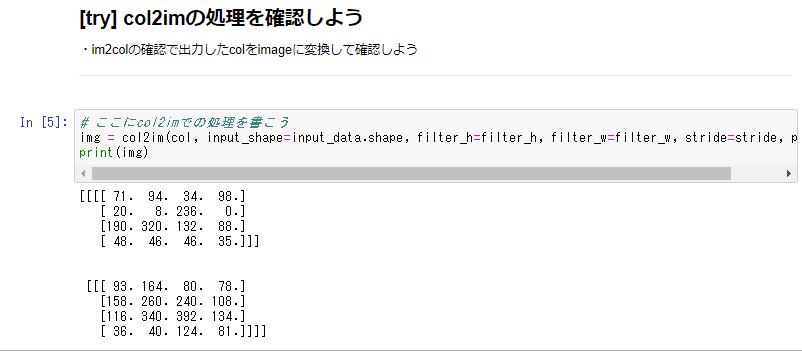
・im2col
→多次元データを2次元にする

↓
最新のCNN
・R-CNN
1. 物体らしさ(Objectness)を見つける既存手法を用いて、画像から物体候補を探す
2. 物体候補の領域画像を全て一定の大きさにリサイズしてCNNにかけてfeaturesを取り出す
3.取り出したfeaturesを使って複数のSVMによって学習しカテゴリ識別、regressionによってBounding Boxを推定
・GoogleNet
→Inception moduleはSparceな畳み込みによって、モデルの表現力と計算時間のトレードオフの関係性を改善したと言える。
→auxiliary lossを追加することで、ネットワークの中間層に直接誤差を伝搬させ、勾配消失を防ぐとともにネットワークの正則化を実現
・ResNet
→残差ブロックとShortcut Connectionを導入することで、
ある層で求める最適な出力を学習するのではなく、層の入力を参照した残差関数を学習する」 ことで最適化しやすくしている。
残差ブロック
畳込み層とSkip Connectionの組み合わせ
2つの枝から構成されていて、それぞれの要素を足し合わせる。残差ブロックの一つはConvolution層の組み合わせで、もう一つはIdentity関数