1. モデルの背景と動機
OpenAI o1 は、科学、プログラミング、数学などの複雑なタスクにおいて、推論能力を強化し、より多くの時間をかけて問題を解決できる全く新しいシリーズの AI モデルです。o1 の命名規則は、従来の OpenAI モデルとは異なり、従来シリーズとの差別化を示しています。GPT-3 や GPT-4 シリーズが自然言語処理に重点を置いていたのに対し、OpenAI o1 は主に推論能力の最適化を目指しており、この命名規則はモデルの目標やアーキテクチャが全く新しい方向性であることを示唆しています。
OpenAIのレポートにある興味深い実験結果
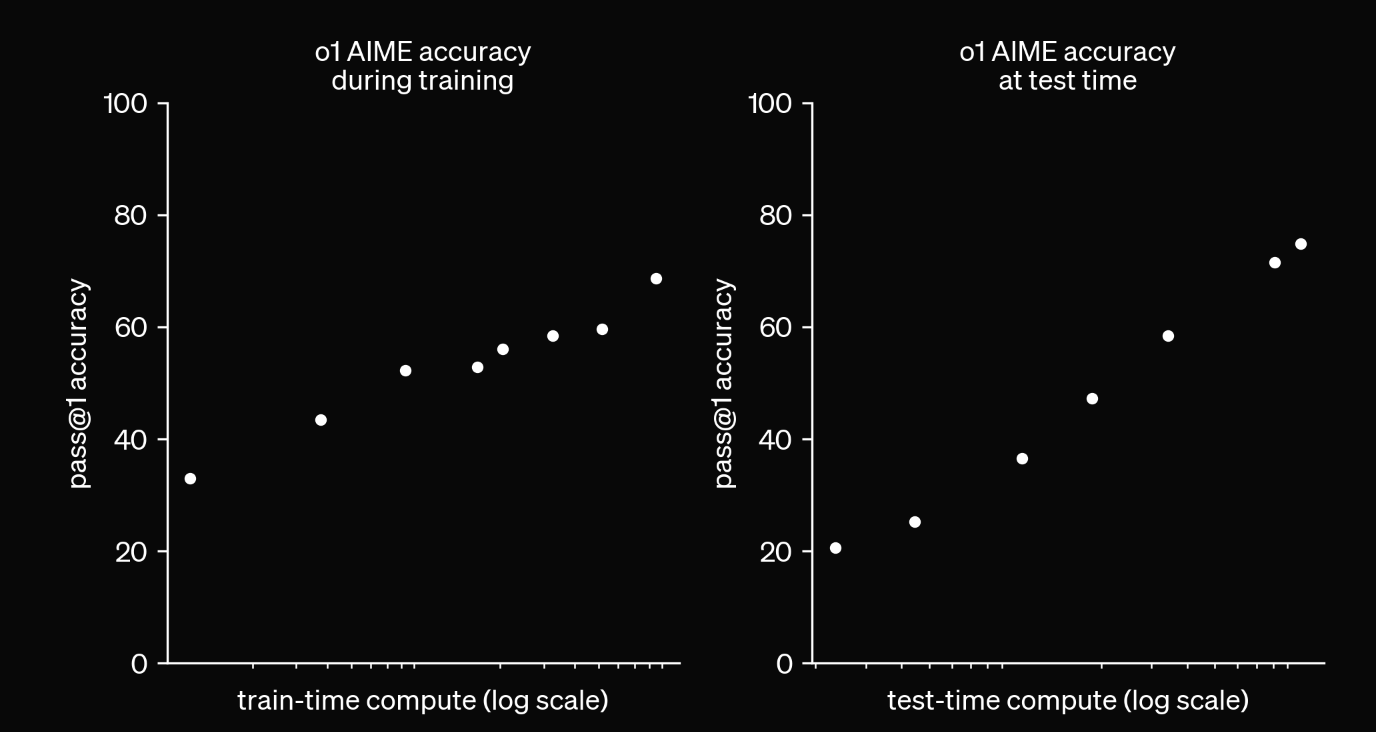
上記の結果は、トレーニング時もテスト時も、計算量を増やすことでモデルの正確性が効果的に向上することを示しています。o1 モデルは、複雑な問題に取り組む際に、より長い時間をかけて思考することで、より良い結果を得ることができるのです。
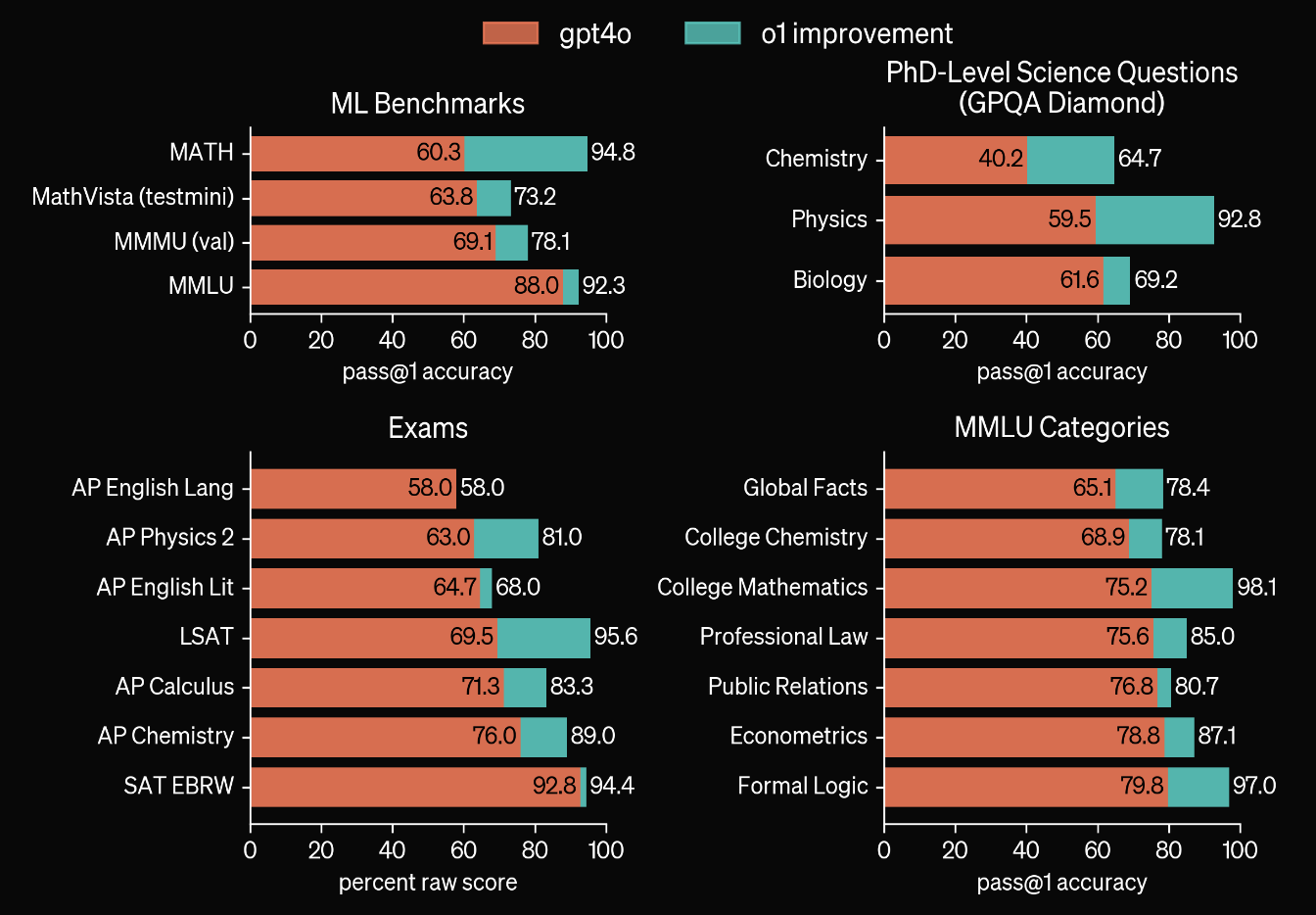
o1 モデルは、数学、物理、論理推論、学術試験などの複数のベンチマークテストで顕著な向上を示しており、特に GPT-4o よりも優れた成績を収めています。また、o1 は博士レベルの科学的問題(GPQA Diamond など)でも強力な推論能力を発揮し、特に物理や化学分野で卓越した結果を示しています。さらに、o1 は AP や SAT などの標準化試験でも明確な進歩を遂げており、学術的および複雑なタスクにおける広範な応用可能性を示しています。
2. 思考の連鎖(CoT)
思考の連鎖(CoT, Chain of Thought) とは、大規模なモデルが複雑な問題を段階的に複数のサブ問題に分解し、それを一歩ずつ解決する推論プロセスを指します。CoT の特徴は以下の通りです:
- エラー分析とデバッグ:CoT はモデルの推論プロセスを観察するための窓を提供し、モデルがなぜ誤りを犯すのかを分析し、デバッグする機会を提供します。
- Zero-shot / Few-shot:これらの違いは、問題解決の手順例を提供するかどうかにあります。
なお、CoT の概念は「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」という論文で最初に提唱され、Zero-shot CoT は「Large Language Models are Zero-Shot Reasoners」という論文で初めて紹介されました。
強化学習とCoT
OpenAIが公開した記事「Learning to Reason with LLMs」では、o1モデルが強化学習(RL)を通じて、思考の連鎖(Chain of Thought)を効果的に活用して問題を推論する方法を学ぶことが言及されています。RLを通じて、モデルは推論過程に関するフィードバックを受け取り、それに基づいて推論戦略を徐々に最適化していきます。
3. デメリット
OpenAI o1モデルは推論能力において顕著な向上を示している一方で、いくつかの欠点も存在します。まず、各出力には不可視の Reasoning Tokenが含まれているため、推論時間や計算リソースの増加を引き起こします。このため、OpenAI は max_completion_tokens パラメーターを導入しました。これは従来の max_tokens と区別され、生成される推論および回答に使用されるトークンの総数を制御するためのものです。
下図は、モデルの思考と推論のプロセスを示しています。
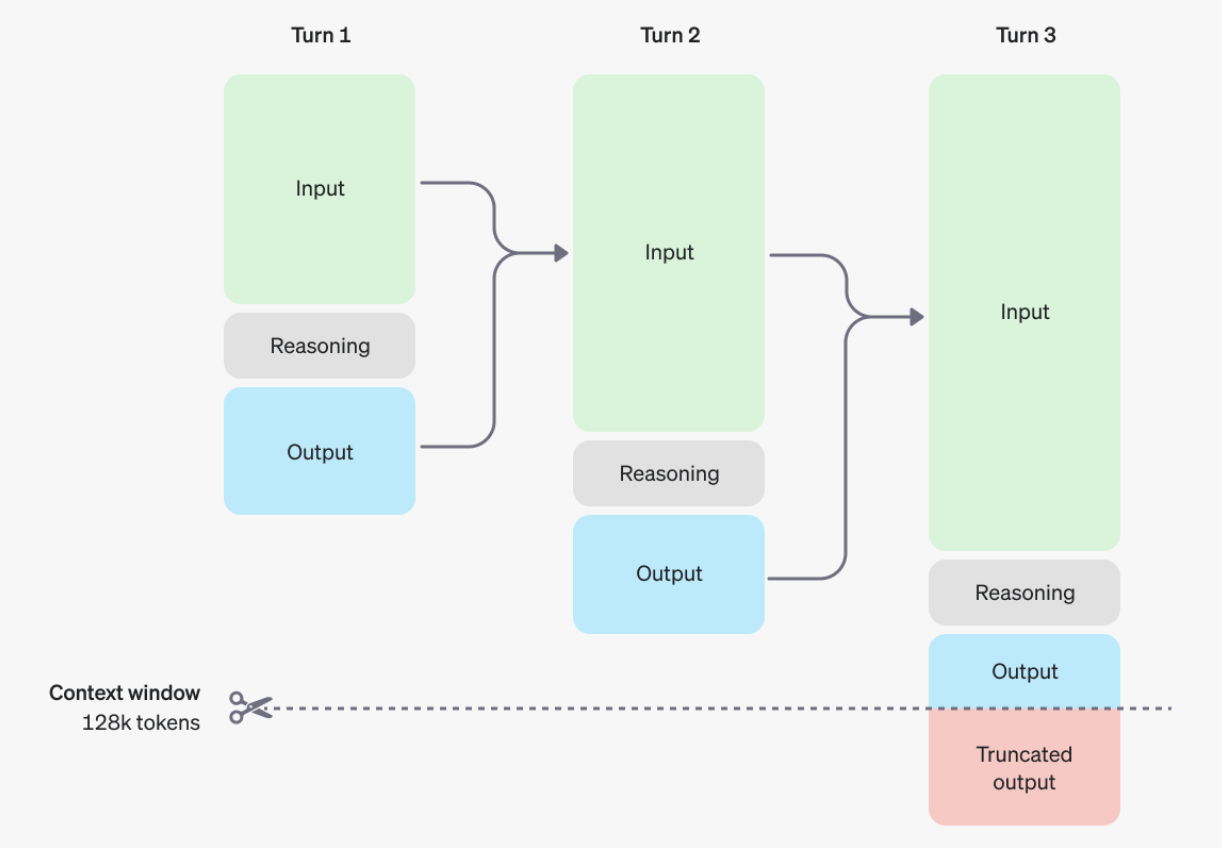
さらに、OpenAIの公式ドキュメントから、o1モデルは複雑なプロンプトエンジニアリングには適していません。特に、few-shotプロンプトやモデルに逐次的に思考させるような指示を使用すると、性能が向上しないばかりか、逆に悪影響を及ぼす可能性があります。このモデルは、シンプルで明確なプロンプトに適しており、過度な誘導や複雑なコンテキストは推論プロセスに影響を与える可能性があります。
4. GPTモデルとの比較と適用シーン
| 特徴 | GPT モデル | OpenAI o1 モデル |
|---|---|---|
| 主なタスク | 自然言語処理と生成タスク(例:テキスト生成、対話、翻訳など) | 複雑な推論タスク(例:数学の問題解決、プログラミング、科学的推論) |
| 推論能力 | 強力だが、複雑な多段階推論では限界がある | 高度に最適化され、複雑な問題の多段階推論に特に優れている |
| 時間と計算コスト | 高速で、計算コストは比較的低い | 複雑な問題の回答生成にはより多くの時間と計算リソースが必要 |
| プロンプト設計 | few-shot プロンプトや複雑なプロンプトで性能を向上できる | シンプルで明確なプロンプトに最適、複雑なプロンプトは性能を低下させる可能性がある |
| 適用シーン | 日常対話、テキスト生成、Q&A などの一般的なタスク | 数学の問題解決、プログラミング、科学的推論、論理推論 |
以上の情報により、OpenAI o1 は推論能力における GPT モデルの拡張に近く、強力な推論能力が GPT モデルと組み合わさることで、より複雑な生成タスクに適用できるようになっています。
5. 将来には
CoTと同様に、Promptの自動生成に基づく代表的なプロジェクトには、ToT、GoT、AoTなどがあります。Promptエンジニアリングは、効率と自動化を向上させることで、複雑なタスクの解決を迅速に進めることができます。しかし、長期的には、モデル自体の推論能力の向上が鍵となり、大規模モデルがより複雑なシナリオで優れたパフォーマンスを発揮できるようになり、推論を誘導するために過度にPromptに依存する必要がなくなるではないかと考えています。