CVPR 2018 Tutorial on GANsにおけるPart3 Ming-Yu Liuのパートの読解メモ。Ming-Yu LiuのECCV 2018での採択論文、Multimodal Unsupervised Image-to-image Translation (MUNIT)の解説です。本記事はYoutube動画とスライドの読解メモをスライドに沿って日本語で書き留めたものです。理解に誤りもあるかと思います。その際はぜひコメントなどでご教授頂けましたら幸いです。
出典
チュートリアルホームページ
発表資料
発表者
Ming-Yu Liu, NVIDIA
概要
Image to Image translationにおいてMultimodal(唯一の結果を出力する(Unimodal)ではなく複数の多様性のある生成結果を出力)で、且つUnsupervised(学習時に正解として入力画像と正解出力画像のペアを必要としない)な手法。
従来のUnimodalなUnsupervised手法(Cycle GAN, UNIT(Unsupervised Image-to-Image Translation Networks))に比べてMultimodalを実現しつつ、Qualityも向上させることに成功。
技術的なポイントは本発表者のNIPS2017で発表したUNITをMultimodal化するにあたり、UNITではdomain-invariantな内容(contents)もdomain-specificな画風(style)もごっちゃになっている単一のlatent space(潜在変数空間)であったのをcontents spaceとstyle spaceに分離したこと。これにより任意のcontents space上の変数とstyle space上の変数を組み合わせて多様な出力を実現できるようにした。
内容
Image-to-Image Translation
domain Aに属する入力画像をdomain不変な内容を維持しつつdomain Bに属する画像に変換する関数Fを導くこと。(図1)
domain A→Bの例(晴れ→雨, 昼→夜, エッジ画像→実写画像...)応用例(図2)
 図1
図1
 図2
図2
Supervised vs Unsupervised
学習時にdomain変換前の入力画像と、その入力画像に対するdomain変換後の画像のペアを多数使用する方式をSupervisedと呼ぶ。図3左側
学習時にペアではなく単にdomain Aの多数の画像とdomain Bの多数の画像を使用する方式をUnsupervisedと呼ぶ。図3右側
 図3
図3
Unimodal vs Multimodal
出力画像として単一例しか出力しない方式をUnimodalと呼ぶ。図4上側
出力画像として多様な複数例を出力する方式をMultimodalと呼ぶ。図4下側

従来手法とその分類
Supervised vs Unsupervised、Unimodal vs Multimodalという観点でImage to Image translationに関する従来技術を分類。図5
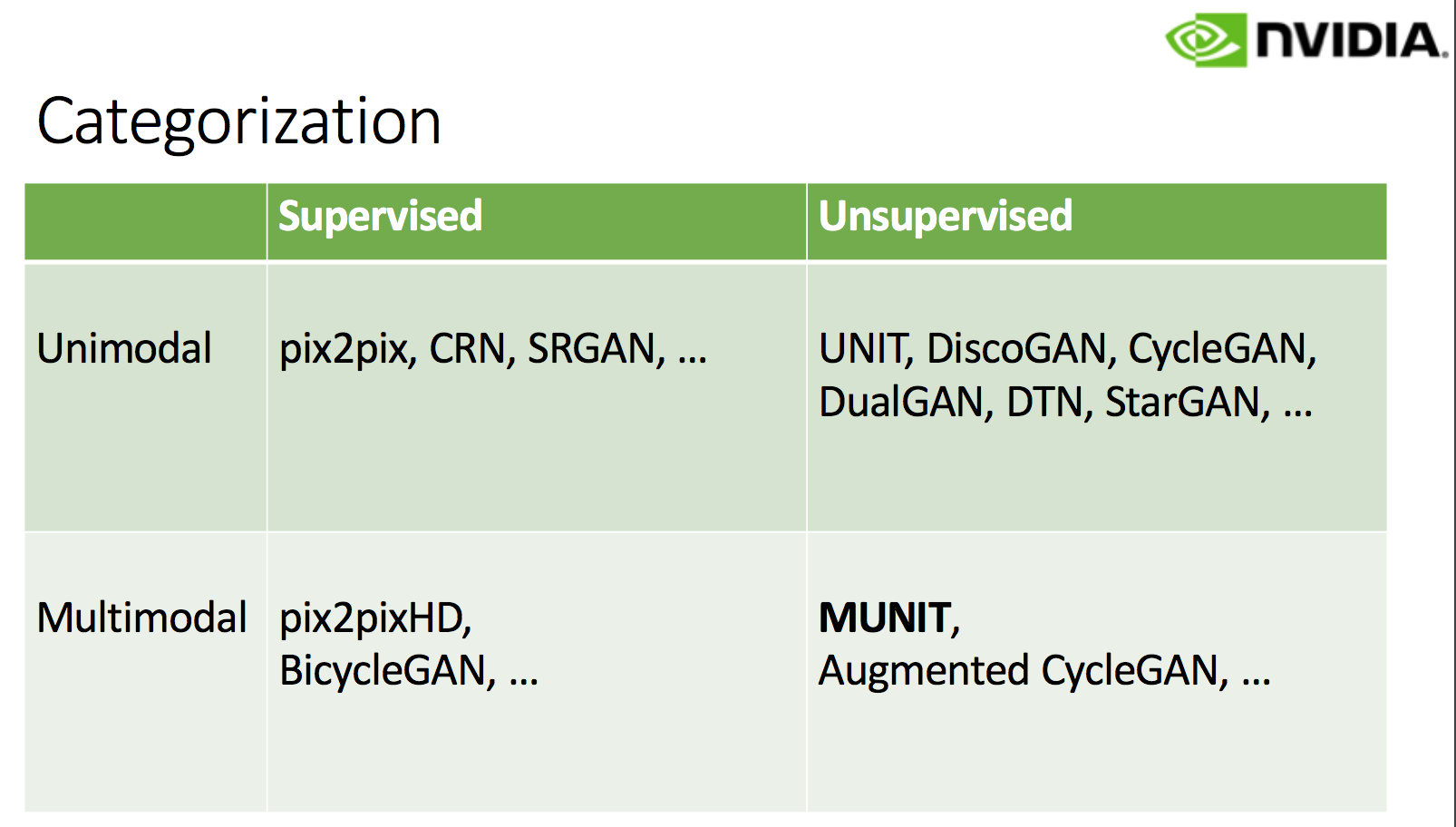 図5
図5
Cycle-Consistency Constraint
GANをImage to Image translationに適用する場合はcontentを保存した生成を行わせるために工夫が必要。
Supervisedの時はdiscriminatorの入力をペア画像とすることで解決(pix2pix)。
以降はUnsupervisedの時を考える。Unsupervisedの時には少なくともCycle-Consistency Constraintを導入することが必要。
Cycle-Consistency Constraintとはdomain Aに属する入力画像$x$をdomain A→domain Bに変換するGenerator A→Bと逆変換のGenerator B→Aに順次かけて生成した画像$\hat{x}$と元の入力画像$x$との差(L1ノルム)。
しかし、Cycle-Consistency ConstraintだけではImage to Image translationを学習するのに十分ではない。
例えば図6のような変換を行えるようなGeneratorを学習したいとする。
 図6
図6
ここでなにかの拍子でGeneratorが図7のように学習をしてしまってもConsistency Constraintだけではそれを正すことはできない。(なぜなら図7においても入力画像を二つのGeneratorに順次かけると元の画像に戻るという条件は満たされているため。)
 図7
図7
このようにImage to Image translationにおいてCycle-Consistency Constraintは必要ではあるが十分ではない。つまりUnsupervisedの時にGeneratorを学習するにはCycle-Consistency Constraintという考え方と+αが必要。
Shared-latent Space for Unsupervised Imageto-Image Translation
Unsupervisedの時にCycle-Consistency Constraint+αで(Unimodalな)Generatorを学習する手法にはCycle GANとUNITがある。
両者ともCycle-Consistency Constraintに加えて+αとしてGANのフレームワークを導入することで学習できるようにしている点では一緒。Cycle GANとUNITとの差異はlatent spaceを明に設けているか否かと言える。で、設けている方がUNIT。(図8)
 図8
図8
Shared-latent Space for Multimodal Unsupervised Image-to-Image Translation (MUNIT)
そしてこの発表の本題であるUnsupervised手法のMultimodal化。本発表の発表者らはUNITをMultimodal化した手法であるMUNITを提案。
UNITでは単一のlatent spaceであった$Z$を、MUNITではcontent space $C$と、各styleのstyle space $S$に分離している。(図9)
 図9
図9
Model
MUNITのモデルは各ドメインにおけるドメイン内再構成モデル(図10(a))とクロスドメイン変換モデル(図10(b))から構成される。
 図10
図10
ドメイン内再構成モデルは各ドメインにおいて定義されるauto encoderのことを指す。図10(a)の左側赤線で書かれた矢印がそれぞれdomain 1のauto ancoderに相当する。同様に青矢印がdomain 2のauto encoderに相当する。
クロスドメイン変換モデルは先ほどのドメイン内再構成モデルに出てきたencoder, decoderを組み合わせることでドメイン変換を行うもので例えばdomain 2からdomain 1への変換は図10(b)の左側のようにdomain 1のスタイル変数$s1$とdomain 2の画像$x_2$からencodeしたコンテンツ変数$c_2$をdomain 1のdecoderにかけることでdomain 2からdomain 1に変換した画像
$x_{2\rightarrow1}$を生成する。さらにこの$x_{2\rightarrow1}$をdomain 1のstyle encoder, content encoderにかけることで再度スタイルコード$\hat{s}_{1}$,
$\hat{c}_{2}$に戻す。
Bidirectional Reconstruction loss
このモデルにおいてまずドメイン内再構成モデルのauto encoderにおいて次のような画像$x$に関する再構成誤差が定義できる。
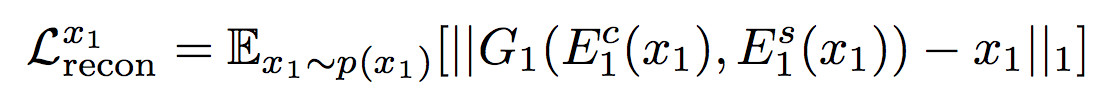
これはすなわち各ドメインにおいて入力画像$x$を当該ドメインのstyle encoderとcontent encoderでstyle code $s$, content code $c$にエンコーディングし、さらにstyle decoder, content decoderで画像$\hat{x}$に戻した時に$x$と$\hat{x}$のL1誤差である。上記式に表した添数字1はdomainの番号に相当し、各domainについてこのような再構成誤差を計算する。
次にドメイン内再構成モデルにおいて次のようなスタイルコード$s$, コンテンツコード$c$に関する再構成誤差が定義できる。
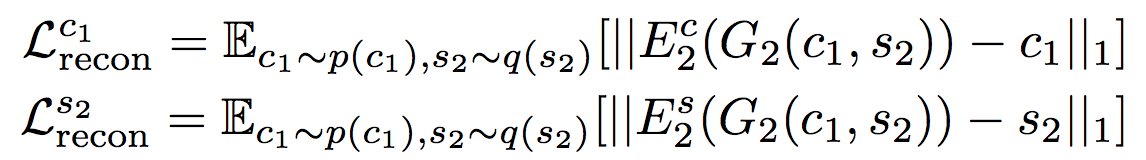
一行目は図11における$s_1$と$\hat{s}_1$とのL1誤差、二行目は図11における$c_2$と$\hat{c}_2$とのL1誤差である。上記式に表した添数字1はdomainの番号に相当し、各domainについてこのような再構成誤差を計算する。
 図11
図11
GAN Loss
以上の誤差だけだと先に説明した「Cycle-Consistency Constraintは必要ではあるが十分ではない」という話になり正しく学習できないのでさらに次のようにGAN lossを導入する。
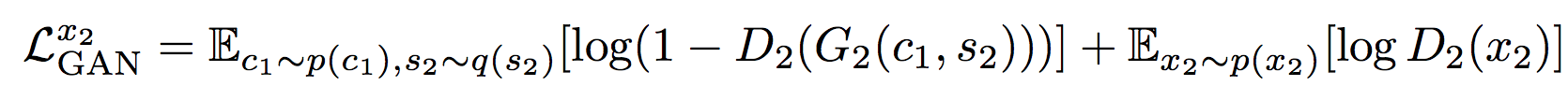
これは図12(b)において$x_1$と$x_{2\rightarrow1}$に対して真贋比較をするdiscriminatorを用意してdiscriminatorが騙されるほど値が大きくなるような一般的なGANのlossである。
 図12
図12
以上にあげた全てのlossの総和を最小化するようなencoder, decoder及びGAN lossを最大化するようなdiscriminatorを見つけるのが本問題における学習である。
実装上の具体的なArchitecture
encoderはcontent encoderと style encoderに分けている。またstyle encoderの出力$s$はさらにMLPを使ってAdaIN Parameterに変換してからContent codeと合流し、最後にアップサンプリングして結果画像にするということである。(図13)
MLPはMulti Layer Perceptionのことと思われる。 AdaINはこのMUNITの論文の1st authorであるX. Huangが以前発表した論文( https://arxiv.org/pdf/1703.06868.pdf )で提案したもののようだがここでは割愛。
 図13
図13
Example-Guided Image-to-Image Translation
本論文で提案する手法は例示画像を使って表す所望のスタイルに画像を変換することもできる。その場合は先に説明したArchitectureににおいてstyle encoderにはスタイルを指定するための例示画像を入力として入れればよい。(図14)
 図14
図14
結果
https://github.com/NVlabs/MUNIT
を参照。
評価
評価は著者のUnimodal, Unsupervisedな手法であるUNIT, 及びCycle GAN、そしてMultimodalなSupervisedな商法であるBicycle GANをベンチマークに評価している。
UNIT, Cycle GANに対してはMultimodalを実現しつつ、Qualityも向上させることに成功。Unsupervisedなのにも関わらずSupervisedな手法であるBicycle GANに肉薄するqualityを達成している。
詳しくは著者論文を参照のこと。
Github
本論文のコードはGithubで公開されている。
https://github.com/NVlabs/MUNIT
ライセンスは2018/10/15現在
Attribution-NonCommercial-ShareAlike 4.0 International
となっている。
 図15
図15