はじめに
どうも、お久しぶりです。
今回、SIGNATEの第2回 金融データ活用チャレンジというコンペに参加しましたので、その分析内容などを載せようと思います。
結果は大したことないですが、自分が今までにやったコンペの中では色々面白いことを試せたので、せっかくなので記録として残しておこうかなと思いました。
コンペの概要
| 項目 | 詳細 |
|---|---|
| 名称 | 第2回 金融データ活用チャレンジ |
| 期間 | 2024年1月18日19時~2024年2月15日 23時59分59秒 |
| 参加人数 | 1,562人 |
| 投稿人数 | 1,152人 |
| 総投稿 | 22,069件 |
| 賞金 | あり |
| 内容 | 企業向けローンの返済可否予測(AIによる人工作成データ) |
| 評価指標 | MacroF1Score |
| 結果 | 140 / 1,152 位 |
分析内容概要
- とにかく色んな視点からモデルを作ってみる!その上でアンサンブル
- 異常検知の手法も試してみた
- モデル作成前のデータ理解、モデルの管理表作成も今回は真面目に行った
- ハイパーパラメータチューニング、しきい値調整も真面目に実施
- スタッキングも初めて実践
とまぁこんな感じで、大したことはしてないです。
それでは、①データ理解→②案出し→③モデルの作成→④精度評価、精度向上
の流れで、順に説明させていただきます。
① データ理解
各変数について
与えられた説明変数と目的変数は、以下のとおり
| 変数名 | 説明 |
|---|---|
| MIS_Status | ローンの状態(目的変数) *0 = 債務不履行、1 = 完済目的変 |
| Term | 融資の期間(月) |
| NoEmp | 融資を受ける前の事業の従業員数 |
| NewExist | 新規ビジネスかどうか *1 = 既存のビジネス、2 = 新規ビジネス |
| CreateJob | 企業が融資資金を使用して創出すると予想される雇用の数 |
| RetainedJob | 融資を受けたことで企業が維持すると予想される雇用の数 |
| FranchiseCode | どのブランドのフランチャイズであるかを識別する一意の5桁のコード *0または1は非フランチャイズを意味する |
| RevLineCr | リボルビング信用枠か *Y = はい、N = いいえ |
| LowDoc | 15 万ドル未満のローンを 1 ページの短い申請で処理できるプログラムか *Y = はい、N = いいえ |
| DisbursementDate | 融資の支払日 |
| Sector | 産業分類コード (卸売業、小売業、製造業、公共事業、公共行政など) |
| ApprovalDate | 米国中小企業庁の承認日 |
| ApprovalFY | 承認された財務年度 |
| City | 借り手の会社の所在地(市) |
| State | 借り手の会社の所在地(州) |
| BankState | 貸し手の所在地(州) |
| DisbursementGross | 支払総額 |
| GrAppv | 銀行によって承認されたローンの総額 |
| SBA_Appv | SBAが保証する承認されたローンの金額 |
| UrbanRural | *1 = 都市部、2 = 田舎、0 = 未定義 |
分布調査
主に分かったことは、以下のとおりです。
-
Term(返済期間)
- 短い方が、やや完済率が低い(不履行が多い)傾向にある
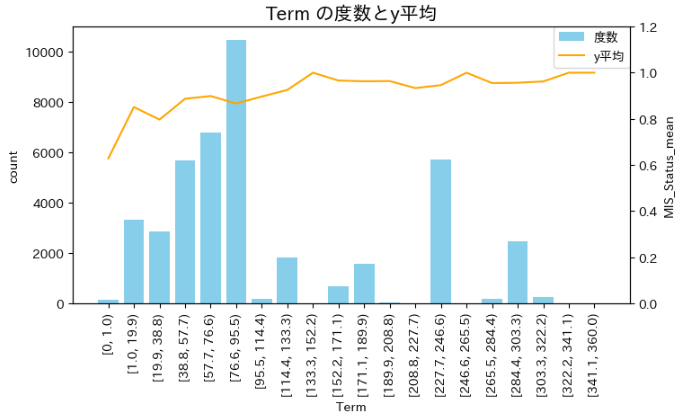
-
CreateJob(創出されると予想される雇用数)
- ある区間で、極端に完済率が低く(不履行率が高く)なっている。
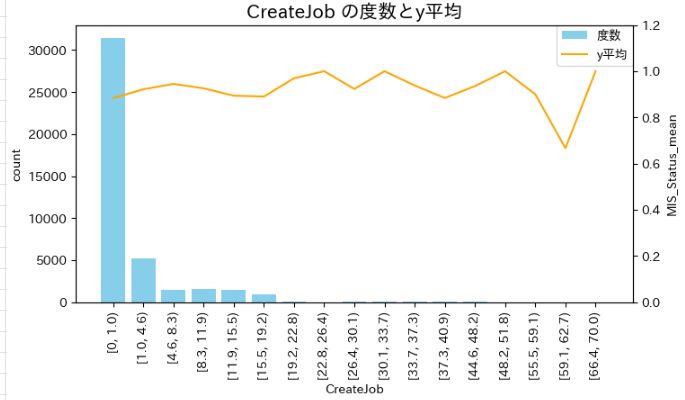
-
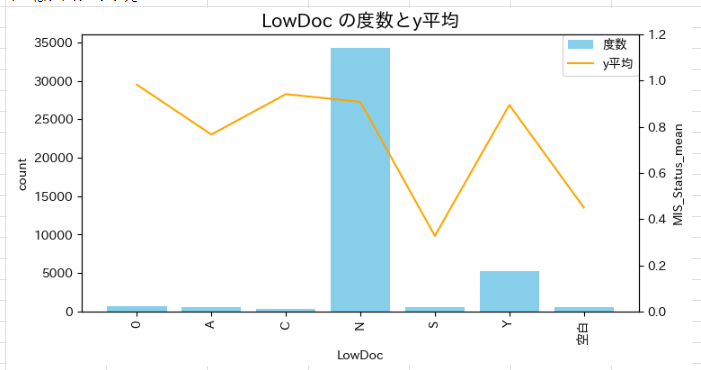
LowDoc(15万ドル未満のローンを、短い申請で処理できるプログラムか)
- 本来Y/Nの2種類のはずだが、他のカテゴリも混ざっている
- Y/N以外のカテゴリは、完済率にばらつきがある
外れ値
外れ値は、以下の2つくらいしか見つけられていませんでした。
- DisbursementDateに、「2073-12-06」がある
- ApprovalDateに、「2073-10-17」がある
その他
その他、分析中に気付いたことです。
- Cityは、アメリカのものがほとんどだが、一部イギリス(スコットランド)のものも入っている?
- 承認されたローン総額より支払額の方が多かったり、承認日が支払日よりも後に来ているものなどがある。返済が遅れて利子などを払い続けている?
- ローン総額を支払っているのに、不履行となっているデータもある
②案出し
以上を踏まえて、何ができそうか考えました。
結論
「とにかくしょうもないモデルでもなんでも、多様な視点でたくさん作って、それをアンサンブルすれば良いや!」
経緯
たまたま、コンペ開始当初の時期に、『多モデル思考』という本に出会い、そこで「一つのモデルで、現実世界の複雑な事象をすべて説明しきることはほぼ不可能である。いくつかのモデルを組み合わせることで、複雑な事象に対する説明が可能となる」といった趣旨のことが書かれていました。「確かに。なんで今までそれを実践しなかったんだろう」と思い、今まで一つのモデルに様々な工夫や説明変数を投入していたことに気が付きました。一つのモデルで色々なことをするのは無理があり、結局過学習していたのです。
そこで、今回は、普段とは少し方針を変えて、「一つのモデルの精度をひたすら上げていくというよりは、様々な観点で多様なモデルを作成し、そのうちどのような要素が予測に重要か調べたり、モデルをアンサンブルさせる」というやり方を実践しようと思いました。
幸い、今回のデータは扱いやすい2クラス予測で、不均衡データという面白い題材。また、説明変数も時系列データ、カテゴリカル変数、数値変数とバランスよく揃っていたので、自然と実践してみたいことが次々と湧いてきました。
そこで、「とりあえず最初のうちは、何でもかんでもモデルを作りまくってやろう!」という方針になったわけです(笑)
出した案
- ApprovalDateなど、時系列に関する変数が3つあるので、時系列解析のような予測モデルが作れないか
- City、Stateなど、地理情報に関する変数もあるので、それらを活用したモデルも作る
- 今回は不均衡データだから、異常検知の手法も使えそう
- 2つのカテゴリカル変数の組み合わせで、完済率の低いものに片っ端からフラグを立ててみよう
- カテゴリカルデータは次元削減してもよさそう
- AutoEncoderや教師なし学習などで次元圧縮したデータで、不履行データ(こちらも次元圧縮)との類似度を測れば、不履行を起こしやすいデータが分かるのでは?
- ChatGPTに聞いたところ、アメリカで起こった、債務に関係がありそうな事件はリーマンショック、オイルショック、ハリケーンなどなので、それらのフラグを作成してみよう
- ChatGPTに聞いたところ、消費者物価指数、株価指数、GDPなどといった指標が効くかもしれないので、それも入れてみよう
- 人口、企業数、緯度・経度など、各都市に関する情報も入れられないか
- スタッキングもやってみよう
③モデル作成
以下のようなモデルを実際に作りました。
アルゴリズム
| アルゴリズム | 詳細 |
|---|---|
| ロジスティック回帰 | 最初のうちは、とりあえずこれだけ使っていました。 |
| lightGBM | 精度を上げるなら定番。ひととおりやりたいことを試してから使い始めました。 |
| ランダムフォレスト | lightGBMをひととおり試してから実践 |
| KNN | そのままだと精度が微妙なので、バギングしたりスタッキングしたり |
| ナイーブベイズ | 0,1の割合を指定できる。バギングも実施 |
| ニューラルネットワーク | 精度向上を期待して。 ドロップアウト、バッチ正規化などを実施 |
| tf-idf | 自然言語処理の手法。 なぜかカテゴリカル変数を次元圧縮するのに使用 |
| lda(線形判別分析) | クラスを分離できるように次元圧縮する手法 |
| LOF(局所外れ値因子法) | 異常検知の手法の一つ |
| isoration forest | 決定木を使った異常検知の手法 |
| AutoEncoder | 中間層の次元が圧縮されるニューラルネットワーク。 次元圧縮と異常検知に活用 |
| k-means | 完済データの中心からの距離で、異常度を測ってみた |
作成した変数
| 変数 | 説明 |
|---|---|
| 融資期間に対する、実際の支払期間の割合 | (DisbursementDate - ApprovalDate) / Term |
| ローン総額÷融資期間 | どのくらい負債の負担があるか表せると思い作成 |
| 新規創出従業員数÷元々の従業員数 | 会社の規模などを表現 |
| フランチャイズフラグ | FranchiseCodeが0または1のもの。あまり効かなかった |
| FranchiseCodeの頭1文字 | あまり意味なかった |
| 融資銀行と借り手の会社の州が一致しているか | あまり効かなかった |
| 時系列変数のラグ特徴量など | ApprovalDateなどの時系列変数のラグ、移動平均などを取ったもの |
| tsfreshで作成した特徴量 | tsfreshで、時系列変数についての変数をたくさん作成 |
| カテゴリ変数ごとの集約特徴量 | カテゴリー変数でgroupbyして、各数値変数の平均、分散などを算出 |
| 完済率の低いクロスカテゴリーのフラグ | 2カテゴリカル変数の組み合わせについて、完済率が一定以下のものにすべてフラグを立てた |
| 順序エンコーディング | カテゴリカル変数を、目的変数の順位でエンコーディング。Cityの順序エンコーディングが効いていたが、過学習? |
| 異常度 | WoE(Weight of Evidence)という一般的な異常度の指標、LOFやisoration forestで作成した異常スコアなど |
| 次元圧縮後のベクトル | lda(線形判別分析)、AutoEncoderなどで次元圧縮したもの |
| tf-idfしたベクトル | カテゴリカル変数を文章のようにつなげて、ベクトル化したもの |
| マクロ経済指標 | GDP、消費者物価指数、株価指数、M1、M2、M3などの情報や、それらのラグ特徴量など |
| 各州に関する情報 | 各州の人口、面積など |
| ハリケーンフラグ | ハリケーンが起こった年と州に一致するデータにフラグ |
| コロナフラグ | ApprovalDateがコロナ後はすべて1 |
④ 精度評価、精度向上
- 精度の良かったモデル
| モデル | 説明 | 精度 |
|---|---|---|
| アンサンブル | 作成した多くのモデルの予測値の平均を取り、その値で0か1かを決めた | リーダーボード: 0.6833203 最終スコア: 0.6830683 |
| ランダムフォレスト | 様々な異常検知の手法で作成した異常スコアと、lda(線形判別分析)で作成した変数を使用 | リーダーボード: 0.6845870 最終スコア: 0.6800749 |
| lightGBM | 2次までの交互作用項を投入 | リーダーボード: 0.6840174 最終スコア: 0.6806484 |
| ランダムフォレスト | 1クラスk-meansで、完済データのみを学習させて、その中心からの距離の変数も投入 | リーダーボード: 0.6829779 最終スコア: 0.6750804 |
| ニューラルネットワーク | 2次までの交互作用項を投入 | リーダーボード: 0.6666093 最終スコア: 0.6635609 |
| ニューラルネットワーク | 様々な異常度、完済率の低い2変数のカテゴリ変数のフラグを投入 | リーダーボード: 0.6643834 最終スコア: 0.6628276 |
- あまり精度が出なかったモデル
| モデル | 説明 | 精度 |
|---|---|---|
| ナイーブベイズ | 数値変数のみを使用 | リーダーボード: 0.5536168 最終スコア: 0.5589399 |
| ナイーブベイズ | 離散変数やカウント変数を使って、多項式ナイーブベイズ。バギングも実施 | リーダーボード: 0.5706836 最終スコア: 0.5824888 |
| スタッキング | KNNのバギング、勾配ブースティング決定木でバギング。 | リーダーボード: 0.5706836 最終スコア: 0.5824888 |
| スタッキング | ナイーブベイズのスタッキング、ランダムフォレスト、勾配ブースティング決定木でスタッキング | リーダーボード: 0.6490487 最終スコア: 0.6481607 |
| AutoEncoder | 次元圧縮したベクトルを説明変数として投入 | リーダーボード: 0.6243979 最終スコア: 0.6221188 |
| AutoEncoder | 会社に関する情報をAutoEncoderで次元圧縮し、そのベクトルを使って不履行データとの類似度が高いものを目的変数0とした | リーダーボード: 0.5307479 最終スコア: 0.5262703 |
| AutoEncoder | AutoEncoderによる異常検知 | リーダーボード: 0.4715742 最終スコア: 0.4712963 |
| LOF(局所外れ値因子法) | LOFによる異常検知 | リーダーボード: 0.4869405 最終スコア: 0.4926042 |
| isolation forest | isolation forstによる異常検知 | リーダーボード: 0.5448622 最終スコア: 0.5503058 |
| k-means | k-meansで完済データに関して1クラスクラスタリングを行い、中心からの距離が遠いものを不履行データとした | リーダーボード: 0.5397915 最終スコア: 0.5452825 |
| lightGBM | 時系列変数のラグ特徴量などを投入 | リーダーボード: 0.6367339 最終スコア: 0.6283358 |
| lightGBM | tsfreshで、ApprovalDateに関する特徴量を作成 | リーダーボード: 0.6453649 最終スコア: 0.6377426 |
| lightGBM | GDP、消費者物価指数などといったマクロ経済指標のラグ特徴量、コロナフラグ、ハリケーンフラグを追加 | リーダーボード: 0.6480192 最終スコア: 0.6422493 |
総括
- もっとデータの中身をよく見ればよかった
- 類似コンペの解法を研究するのを、そういえば忘れてた
- 外部データは効かないね
- ChatGPTをもっと有効活用したいね
- アンサンブルで過学習は防げた
- 異常検知の手法を覚えられた
参考文献
- ミシガン大学教授 Ph.D. スコット・E・ペイジ(2020).『多モデル思考
データを知恵に変える24の数理モデル』.森北出版,p.432,https://www.morikita.co.jp/books/mid/085501 - 藤原 幸一(2022).『スモールデータ解析と機械学習』.オーム社,p.296,https://www.ohmsha.co.jp/book/9784274227783/
ではさらば