お久しぶりです。最近たまたまネットで自己組織化マップ(SOM)というクラス分類の手法があることを知ったので、試しに剣盾までのポケモンを分類してみました。
自己組織化マップ(SOM)について
この辺りの記事が参考になります。
要するに、分析したいデータを2次元のマップに写像して、マップの中の色である程度クラス分けができる、という手法のようです。それぞれのデータ(Xn)に最も近いデータ(ノードkn)を、さらにXnに近づけていくように学習させていき、その結果、最終的にはある程度色でクラス分けがされる、というものらしいです。(間違えていたらすみません。)
ライブラリsomocluについて
こちらの記事 https://www.haya-programming.com/entry/2018/04/07/161249
で紹介されていた、somocluというPythonのライブラリを使ってみました。
必要なコード数が少なく、付けられるオプションも豊富なので、割と使いやすかったです。でも、ネット情報が少ないので、細かい調整はしづらかったです。
分析
使用データ
https://smart-hint.com/poke-data/introduction/
こちらから拝借しました。PokeAPIというものを使って取得されているようです。
使用環境
・Windows10
・Google Colaboratory
コード
まずは、必要なライブラリ等を一通り取得します。
!pip install somoclu
!pip install japanize-matplotlib
import japanize_matplotlib
import numpy as np
import pandas as pd
from somoclu import Somoclu
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
GoogleColaboratoryを使っているので、ドライブにマウントして、データを取得します。データのパスは適宜変更してください。
from google.colab import drive
drive.mount('/content/drive')
# データを読み込む
df_pokemon = pd.read_csv('/content/drive/MyDrive/MyWorks/data/pokemon_data.csv', encoding='shift_jis')
df_pokemon
SOMモデルを構築します。ほぼ、こちらの記事のとおりです。
X = df_pokemon.drop(['id', '名前', '画像URL'], axis=1)
X = pd.get_dummies(X)
y = df_pokemon['名前']
# SOMに入れる前にPCA(主成分分析)して計算コスト削減を測る
pca = PCA(n_components=5)
X = pca.fit_transform(X)
# SOMの定義
n_rows = 16
n_cols = 24
som = Somoclu(n_rows=n_rows, n_columns=n_cols,
initialization="pca", verbose=2, compactsupport=False)
学習をします。
# 学習
%%time
som.train(data=X, epochs=1000)
私の環境では、このくらいの処理時間でした。(型でWarningがでていますが、今回はカンベンしてください汗)
行数が多いデータだと、5分以上時間がかかります。
Warning: data was not float32. A 32-bit copy was made
CPU times: user 46 s, sys: 458 ms, total: 46.5 s
Wall time: 46.4 s
最後に、結果を可視化してみました。
# U-matrixをファイル出力
%%time
som.view_umatrix(figsize=(24, 16), labels=y, bestmatches=True,
filename="umatrix.png")
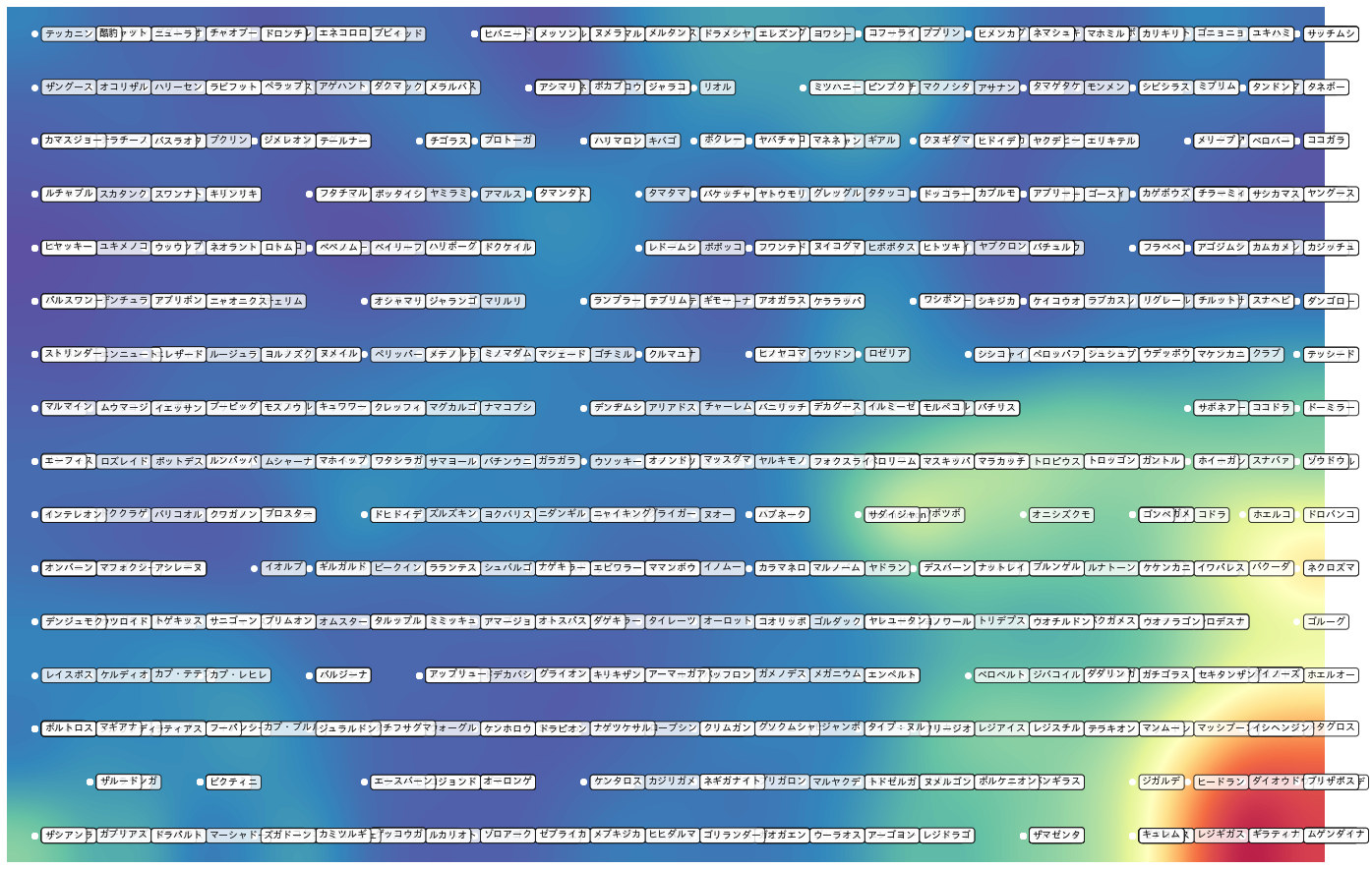
赤いところほど距離が遠くなるそうなので(『自己組織化マップ入門』 参照)、赤い部分は他より断絶された孤島のような部分です。ここに伝説のポケモンなどが終結していますね。個人的には、テッカニンやホエルオーが端の方にいたり、ナットレイとブルンゲル、ヒバニーとメッソンが同じような位置にいるのが直感とマッチしていて良かったなと思います。
ちなみに、
X = df_pokemon.drop(['id', '名前', '画像URL', 'タイプ1'], axis=1)
X = pd.get_dummies(X)
y = df_pokemon['タイプ1']
# SOMに入れる前にPCAして計算コスト削減を測る(iris程度では無駄)
pca = PCA(n_components=5)
X = pca.fit_transform(X)
# SOMの定義
n_rows = 16
n_cols = 24
som = Somoclu(n_rows=n_rows, n_columns=n_cols,
initialization="pca", verbose=2)
として、タイプ毎に出力してみたのがこちらになります。
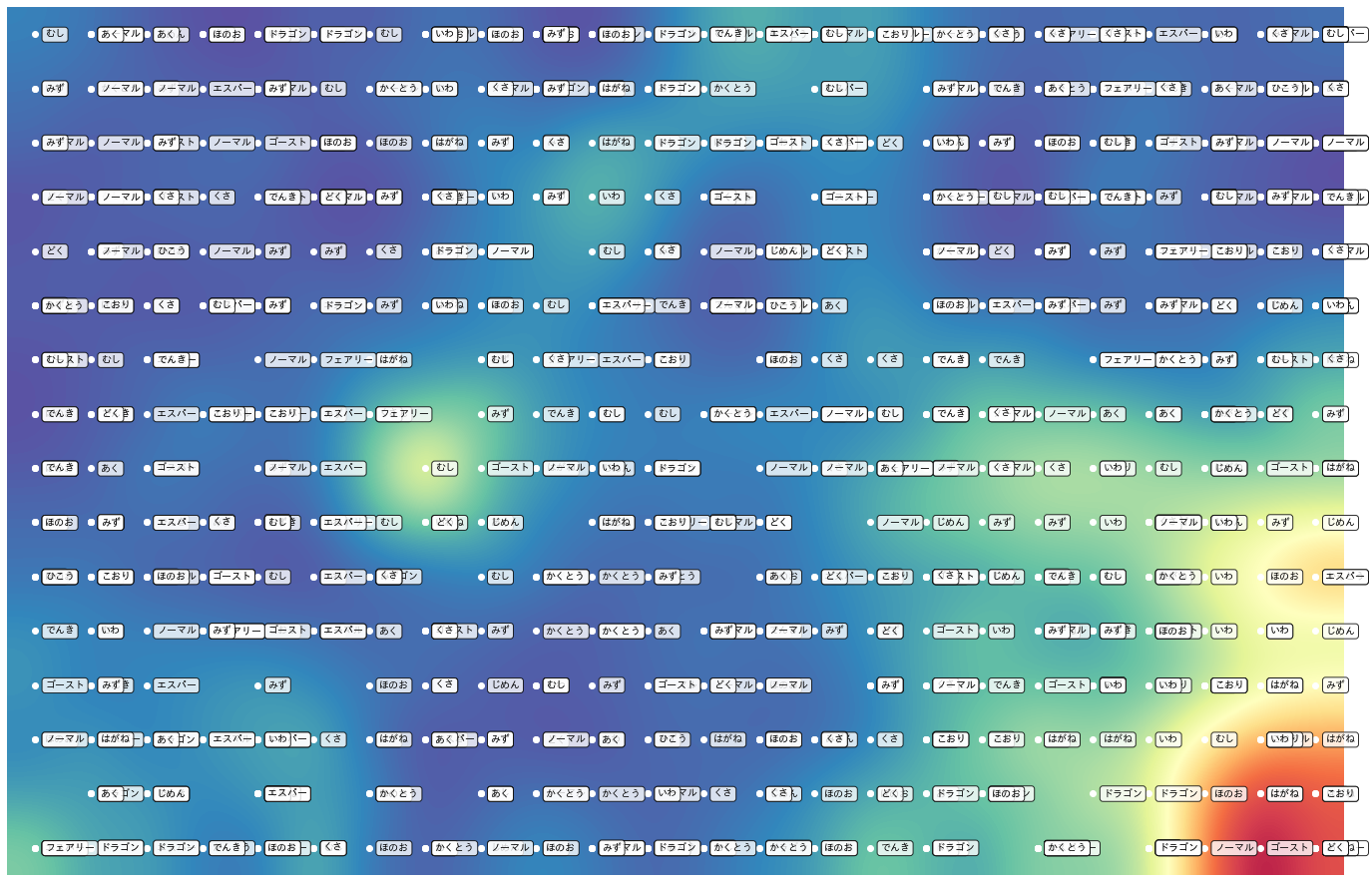
あまりタイプ毎に分かれている感じはしませんが、なんとなくエスパーは中央付近、みずタイプは端の方に集まっている気もしないでもありません。なんとなく...。
他にも、こちらの記事を参考に、k-meansで一度クラスタリングしてからマップに写像したりもしてみました。その結果がこちらです。

孤島の位置が右下から左上に変わっていますが、伝説が多く孤島にいたり、ツボツボ(中央上付近の黄色い部分)やハピナス(左下の方の黄色い部分)がやや他と分断されているなど、こちらもある程度妥当な結果になっていそうです。
後は、
som.view_similarity_matrix(figsize=(12, 12))
とすることで、相関行列(?)が出せるようですが、今回はデータ数が多いためかカオスな画像になってしまいました。
感想
結構使っていて楽しかったです。久々に新しい技術を試してみる悦びを体験することができました。kaggleなどで直接使えるかは分かりませんが、クラス分けをする際に可視化する手法としてはとても有用に思えました。他のデータでも色々やってみたら面白そうだなと思いました。
では ばいばいき~ん
参考記事
SOMの概要、ライブラリについて
コード作成に関して