初投稿です。
この度、初めてのAlexaスキルをストアに出しました。
今回は、画面付きのデバイスが増えている背景もあり画面付きデバイスに対応したスキルを開発したのですが、実装時にハマったポイントを共有しようと思います。
どんな人が書いたの?
・Alexaスキルの開発は初めて
・個人でのWebアプリやスマホアプリ開発経験あり
・業務としての開発経験無し
・使える(触ったことある)言語はC#,F#,js,python,ruby,C,Dart,etc...
対象読者
・Alexaスキルをこれから作ってみたいと思ってる人
・画面付きデバイス(Echo Show 5 等)用のスキルを開発したい人
・javascriptが読める人or何かしらプログラミングしたことある人
作ったスキル
マッチ売りの少女をモチーフとした様々な物語を毎日一話ずつ(スキル内課金すればいくつでも)聴くことが出来るスキルです。
また、物語の途中で選択肢が現れ、その選択肢によって後半のストーリーが変わるというアドベンチャーゲームのような要素もあります。
「マッチファンタジー」という名前で現在Amazonのスキルストアにて公開中なので興味ある方はぜひ!
https://www.amazon.co.jp/Acerola-Production-%E3%83%9E%E3%83%83%E3%83%81%E3%83%95%E3%82%A1%E3%83%B3%E3%82%BF%E3%82%B8%E3%83%BC/dp/B07YNCVQZH
画面イメージ

スキルのアイコン

ハマった5つのポイント
まず、ハマったポイントの一覧をあげておきます。
- 音声ファイルの個数制限
- 外部サイトの音声ファイル利用の制限
- ユーザーが選択した選択肢の統計情報の保持
- 適切なタイミングでの画面遷移
- 各ストーリー用文章の構造化
1. 音声ファイルの個数制限
マッチファンタジーの性質上、登場人物の話し言葉や背景音等が必要だったため
自前またはAlexaのサウンドライブラリの音声ファイルをAlexaのデフォルトの読み上げの間に埋め込む必要があったのですが、
スキルからの一度のレスポンスに埋め込める音声の個数が5個という制限がありました。
そこで、複数の音声ファイルが必要な箇所をまとめて1つのファイルにしたり、そもそも音声ファイルが必要ないように工夫するなど、ストーリーの構造を変更することで制限を回避しました。
2. 外部の音声ファイル利用の制限
これはAlexaのサウンドライブラリのみを使えば特に起きない問題なのですが、Alexaスキルでは外部ファイルを利用する場合はファイルのホストがHTTPSかつ自己署名NGという制約があります。
ただし、Alexaスキルプロジェクトごとに自動で用意してもらえるS3容量があるので、配置できない理由がない限り(特に開発初期は)そこにファイルを配置するのがよいかと思います。(Alexaスキルの開発プロジェクト立ち上げる時の設定でバックエンドリソースをAlexa-Hostedのどちらか(Node.jsかPython)を選ぶ必要あり?)
3. ユーザーが選択した選択肢の統計情報の保持
マッチファンタジーでは上記の通りストーリーの途中で選択肢が出てくるのですが、それに関連して、他のユーザーがどの選択肢を選んだかの統計情報をグラフ等で示すという機能があります。
このような機能を実現するためにはDBを利用したデータ永続化が必須です。
もちろん自前でDBを用意してやればそれほど複雑な実装では無いんですが、プロジェクトの制約上、実装コストを落として(極力無料)かつ素早く実装する必要があったため、
今回は、上記の2.で触れた自動で用意されるS3を利用して永続化できる ask-sdk-s3-persistence-adapter というライブラリを利用しました。
このライブラリをそのまま使うだけでも、ユーザー毎のセッション情報の保存/読込することは出来るのですが、統計データのようにユーザー間をまたいでの保存/読込は出来ないので、
上記のライブラリのソースコードを参考にして、統計情報の保存、読込をするメソッドを実装しました。
以下、実際のコードを公開します。1ファイルとしてモジュール化しています。
const AWS = require( 'aws-sdk' );
// S3上で統計情報を保持するJSONファイルの保存先ディレクトリパス
const TOTALING_PATH = 'totalings'
// ストーリー毎に統計情報を保存するためにストーリー毎のキーを不可して各ファイルパスを生成
const _getTotalignPath = ( storyKey ) => `${TOTALING_PATH}/${storyKey}`;
const s3Client = new AWS.S3( {
apiVersion: 'latest'
} );
// 統計情報を取得するメソッド storyKey:ストーリーに割り当てられたキー
module.exports.getStore = async function getStore( storyKey ) {
const bucketName = process.env.S3_PERSISTENCE_BUCKET;
try {
const params = {
Bucket: bucketName,
Key: _getTotalignPath( storyKey ),
};
// S3からstoryKeyに応じた統計情報ファイル(JSON)を取得する
const data = await s3Client.getObject( params ).promise();
const json = JSON.parse( data.Body );
return json
} catch ( err ) {
console.log( err );
return undefined;
}
}
// ユーザーが選択した結果を統計情報に反映させるメソッド choiceNum:ユーザーが選択した選択肢の番号
module.exports.addCount = async function addCount( storyKey, choiceNum ) {
const bucketName = process.env.S3_PERSISTENCE_BUCKET;
try {
if ( choiceNum !== 1 && choiceNum !== 2 ) throw ReferenceError( `choiceNum ${choiceNum}: Invalid number` );
const params = {
Bucket: bucketName,
Key: _getTotalignPath( storyKey ),
};
// S3からstoryKeyに応じた統計情報ファイル(JSON)を取得する
const data = await s3Client.getObject( params ).promise();
const json = JSON.parse( data.Body );
// 統計情報ファイルの該当する選択肢のcount値を+1
json[ choiceNum ].count = parseInt( json[ choiceNum ].count ) + 1;
params.Body = JSON.stringify( json );
// S3に保存
await s3Client.putObject( params ).promise();
return json;
} catch ( err ) {
console.log( err );
return undefined;
}
}
この場合のS3の構造は以下のようになります。
├──[スキルID]
│ └── totaling
│ │ ├── storyKey1
│ │ ├── storyKey2
│ │ ├── ...
│ │ ...
尚、参考にしたライブラリのソースは以下です。ライブラリのgetAttributesがgetStoreと、saveAttributesがaddCountと対応しています。
https://github.com/alexa/alexa-skills-kit-sdk-for-nodejs/blob/2.0.x/ask-sdk-s3-persistence-adapter/lib/attributes/persistence/S3PersistenceAdapter.ts
4. 適切なタイミングでの画面遷移
Alexaスキルでは、APL(Alexa Presentation Language)という独自の画面用フォーマットで記述したものをレスポンスとしてデバイスに送信することで画面表示をコントロールするのですが、ユーザー発話のレスポンスとして返す構造上、基本的にはユーザー発話のタイミングでしか画面を切り替えることが出来ません。
本来はマッチファンタジーでは物語の展開に応じて画面を切り替えたかったのですが、この仕様があるためにかなり枚数を減らすことになってしまいました。
また、動画の再生終了イベントをトリガーとしてデバイスからスキルに対してリクエストを送れるので、動画を上手く入れることで画面の切り替えを増やす工夫もしました。
他のイベントをトリガーしたりイベントのdelayオプションを駆使する等すれば、もっと柔軟に画面をコントール出来るかもしれませんが、少し複雑化するため今回は断念しました。
この問題はリッチな画面を提供したいスキルでは比較的起こりやすそうな気がするので、画面遷移を柔軟にコントロールできる機能がそのうち追加されないかと期待しています。
5. 各ストーリー用文章の構造化
これはハマったというより、やらないと後々大変になってただろうなあというポイントなんですが、
早い段階でストーリーのテキストを物語上出てくる地の文や登場人物の声、音声ファイル等ごとに識別できるようにJSONファイルに構造化して記述しておいたので、ストーリーごとに手動でタグや属性値を付加する必要がなくなり、ストーリーの追加や変更がかなり楽でした。
以下、構造化JSONファイルの一部です。
// スキル起動して最初の読み上げ
"intro": {
// builderのspeakに対応
"speak": [
// seはAlexaのサウンドライブラリ valueがパス
{
"type": "se",
"value": "weather/wind/wind_10"
},
// narratorは地の文
{
"type": "narrator",
"value": "一人の少女が薄暗い寒空の下、 マッチを売っている、"
},
// audio_outer はS3以外の音声ファイル descriptionはわかりやすいように付加してあるだけで実行時には無視される
{
"type": "audio_outer",
"value": "自前の音声ファイルのパス",
"description": "はーさむいなあ"
}, {
"type": "narrator",
"value": "寒さに耐えかねた少女は、 マッチに火をつけたいようです、"
}, {
"type": "narrator",
"value": "火をつける、と言ってください、"
}
],
// builderのrepromptに対応(ユーザーからの発話がなかった場合に再読み上げする際の文言)
"reprompt": [ {
"type": "narrator",
"value": "火をつける、と言ってみてください、"
} ]
},
他にも'man'や'boy','old_woman'といったtypeを用意してあり、プログラム側でタイプに応じてssml(読み上げ用のフォーマット)のタグや属性を付加するメソッドを用意することで音量やピッチ、話す速度等の指定をしやすくしています。
ssmlの文法エラーが出た場合、間違っている箇所がログでは追いづらいため、エラーを減らせるのも構造化しておくことメリットの1つです。
その他
Alexaスキルに限らず音声デバイスでは、いかにVUI(音声ユーザーインターフェース)を設計するかがよりよいユーザー体験を目指す上でかなり重要なポイントです。
というのも、一般的なアプリやPCのような画面で操作するデバイスと違い、ユーザーのアクションを制限することが出来ないからです。(例えば、アプリではボタンを開発者が設置しない限りボタンを押すというアクションはできません。)
つまり、ユーザーが行うであろうあらゆる行動(発話)に柔軟に対応できるように設計する必要があります。
マッチファンタジーでは、VUIを考えるにあたり、以下のようなフローチャートを使いました。(画面遷移を考える上でも利用しています。)
フローチャートは特に状態管理が必要な場合に有効だと思います。
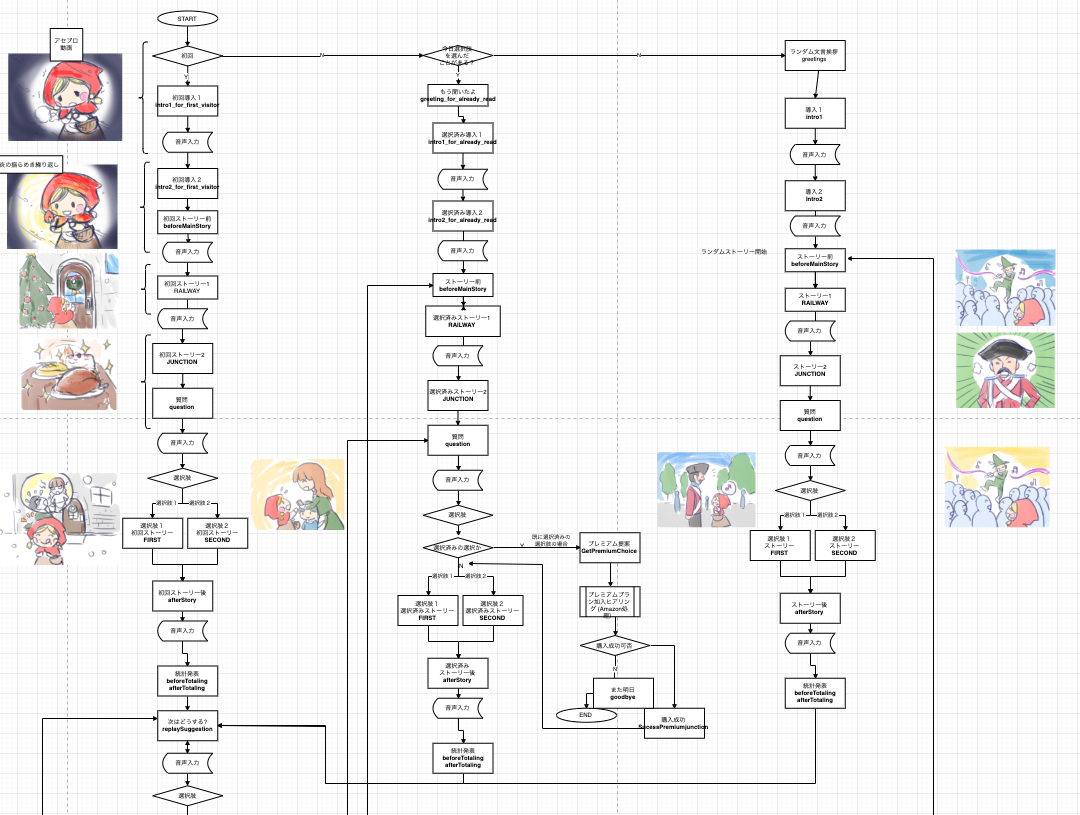
このフローチャートは正常系(ユーザーが期待通りの行動(発話)をした場合)のみしか記載していませんが、ユーザー体験を向上させるには異常系でのレスポンスもリッチにする必要があります。
また、VUIを考える際は、ユーザーの発話とスキルからのレスポンスを1セットとして組み立てていくのが良いかと思います。
今後やりたいこと
今回は、「Alexaスキルのコンテストに出す」という目的があり期限が限られていたため、まだまだ実装不十分な部分があります。
・すべてのストーリーの登場人物の声をAlexaの読み上げ音声ではなく肉声に(現在は自作の音源を一話分だけ実装済み。出来れば声優さんに頼みたい)
・すべてのストーリーにイラストを入れる&場面を追加する
・ストーリー数を増やす(現在10話)
・選択するフェーズで画面を切り替える(出来ていないのは、ハマったポイントの4番目が理由)
etc.
まとめ
ここまでハマったポイントを色々説明してきましたが、Alexaスキル開発を一通りしてみた上で、難易度はそれほど高くないように感じます。
マッチファンタジーは企画から含めて約一ヶ月程度で公開していますが、プログラムの実装自体は学習も含めて1~2週間程度で、むしろ企画や音源やイラスト等の素材作りのほうが時間がかかりました。
また、スキル公開のための審査提出のレスポンスが早く(私達の場合は営業日で1~2日程度でした)、審査が通らない場合でもどこをどう直せばよいのかをとても丁寧に教えてくれるので、
Alexaスキルに興味ある方は、とりあえず1つスキル作って審査出してみるのがおすすめです。
以上です!