このシリーズでは、商談の管理をTrelloで行いその分析をGoogle Colaboratoryで行うことを考えていきます。
- 1回目の記事(https://qiita.com/yazn/items/9368cc9e442eae85e5da )
- 2回目の記事(https://qiita.com/yazn/items/ea44ab987d1709c77d9f )
- 3回目の記事(本記事、最終回)
1. 前回までのおさらいと本記事でのゴール
前回までの記事(商談をTrello + Google Colaboratoryで管理(その1) 、 商談をTrello + Google Colaboratoryで管理(その2) )では、以下のトピックを扱いました。
- 商談フェーズ管理の運用例について
- 商談フェーズ管理を行うために、ここではTrelloとGoogle Colaboratoryを使って行うこと
- 必要なボードを作成
- API keyやtokenを取得し、Pythonからボードの情報を取得すること
- Google Colaboratoryを準備し、ボード情報を取得します。
- 商談レポートを作成
本記事では以下をゴールとします。
- 営業ミーティング(フォーキャストミーティングやパイプラインミーティング)での目的を考えます。
- 営業ミーティングに即したダッシュボードをPlotly Dashを使って作っていきます。
2. 営業ミーティングでの目的
高い精度のフォーキャストは経営の意思決定をする上で重要な要素になり得ます。そのため、フォーキャストミーティングではフォーキャストの妥当性やその精度について議論する必要があります。
営業プロセスが正しく運用されていない組織の一担当者だと実感はわかないかもしれませんが、精度が甘いと大事な投資チャンスを逃すことになります。
具体的には、
- パイプラインに比べてフォーキャストや実績が大きい場合(案件勝率が高い場合)、パイプライン開拓のために営業要員を増やさないといけません。
- パイプラインに比べフォーキャストが低い場合、パイプラインの見直しだけでなく製品開発についても見直しが必要になってくるでしょう。
- フォーキャストも小さくパイプラインも小さい場合そのマーケットへの撤退を検討しなければいけません。
一概にこの通りである必要はありませんが、フォーキャスト精度が甘いと経営者は乱気流で飛行機を運転するようになってしまいます。また、誤ったヨミの上でクビ切りの意思決定を下してしまうこともあるでしょう。
営業ミーティングでフォーキャストについて精査することが重要でしょう。
3. ダッシュボードの作成
- DataTableについて参考にしたサイト: https://zenn.dev/yassh_i/articles/ec5eaa06a83a69
- BarChartについて参考にしたサイト: https://plotly.com/python/bar-charts/
必要なライブラリをインストール
以下のライブラリが必要です。
- py-trello(前回に引き続き利用します)
- Jupyter_dash (Plotly DashのJupyterインタフェース)
- plotlyの更新
! pip install py-trello
! pip install jupyter_dash
! pip install --upgrade plotly
trelloに接続しボードを取得します。
キーやトークンの取得方法は1回目の記事で紹介しています。前提とするボードは下記リンク先に共有したのでご参考ください。ボードの設計意図は、1回目の記事で触れています。
https://trello.com/b/rNSWxDwK/opportunities
from trello import TrelloClient
trello_client = TrelloClient(
# trelloから取得したキーとトークンを記載
api_key = '',
token = ''
)
# 対象のボードである'Opportunities'ボードを取得(ボードの名前がユニークでない場合は困る)
opps_board = [x for x in trello_client.list_boards() if x.name == 'Opportunities'][0]
ダッシュボードの準備
ダッシュボードで処理対象とするデータをDataFrameに格納します。
import pandas as pd
import numpy as np
from datetime import datetime, timezone
# py-trelloオブジェクトのうち案件カードを抽出しdataframeを作成
opp_df = pd.DataFrame({'opp_card': [x for x in opps_board.get_cards() if not x.name.startswith('.')]})
# カード名の列を追加
opp_df['card_name'] = opp_df.apply(lambda x: x['opp_card'].name, axis=1)
# 顧客名、案件名 列の追加
_df = opp_df['card_name'].str.split('_', expand=True)
_df.columns = ['顧客名', '案件名']
opp_df = pd.concat([opp_df, _df], axis=1)
# フェーズ列の追加
opp_df['フェーズ'] = opp_df.apply(lambda x: x['opp_card'].get_list().name.split()[0], axis=1)
# クローズ時期や金額の記載があるdescriptionの列を追加
opp_df['desctiption'] = opp_df.apply(lambda x: x['opp_card'].description, axis=1)
# 金額列の追加
def get_budget(s):
s_list = s.split('\n')
for i in range(len(s_list)):
if '# 予算' in s_list[i]:
return s_list[i + 1]
def budget_str2int(s):
multiplier = 1
if s.endswith('M'):
multiplier = 1000000
s = s[:-1]
return int(s) * multiplier
opp_df['金額'] = opp_df.apply(lambda x: budget_str2int(get_budget(x['desctiption'])), axis=1)
# 受注予定日列を追加
def get_close_date(s):
s_list = s.split('\n')
for i in range(len(s_list)):
if '# クローズ時期' in s_list[i]:
return s_list[i + 1]
opp_df['受注予定日'] = opp_df.apply(lambda x: get_close_date(x['desctiption']), axis=1)
# カード作成日の追加
opp_df['created_date'] = opp_df.apply(lambda x: x['opp_card'].created_date, axis=1)
# カード移動日の追加(カード移動していなければNaT)
opp_df['moved_date'] = opp_df.apply(lambda x: x['opp_card'].listCardMove_date()[0][2] if len(x['opp_card'].listCardMove_date()) else np.nan, axis=1)
# 商談日数の追加
opp_df['商談日数'] = (datetime.now() - opp_df['created_date'].dt.tz_convert(None)).dt.days
# 滞留日数
opp_df['滞留日数'] = (datetime.now() - opp_df['moved_date'].dt.tz_convert(None)).dt.days
opp_df['滞留日数'] = opp_df.apply(lambda x: x['商談日数'] if pd.isnull(x['滞留日数']) else x['滞留日数'], axis=1)
# ネクストステップ列の追加
opp_df['comments'] = opp_df.apply(lambda x: x['opp_card'].comments, axis=1)
def get_next_action(c):
def _get_next_action(t):
t_list = t.split('\n')
for i in range(len(t_list)):
if '# Next Action' in t_list[i]:
return t_list[i + 1]
date_text_list = [(x['date'], x['data']['text']) for x in c]
date_text_list.sort(key=lambda x: x[0], reverse=True)
for x in date_text_list:
r = _get_next_action(x[1])
if r:
return r
opp_df['ネクストステップ'] = opp_df.apply(lambda x: get_next_action(x['comments']), axis=1)
# 分類列の追加
def is_commited(s):
s_list = s.split('\n')
for i in range(len(s_list)):
if '# Committed' in s_list[i]:
return True
return False
opp_df['分類'] = opp_df.apply(lambda x: 'Pipeline' if x['フェーズ'] in ['Ph.1', 'Ph.2'] else 'Commit' if is_commited(x['desctiption']) else 'Upside', axis=1)
opp_df = opp_df[['顧客名', '案件名', '分類', 'フェーズ', '受注予定日', '金額', '商談日数', '滞留日数', 'ネクストステップ']]
# opp_df
ダッシュボードを実装します。
from jupyter_dash import JupyterDash
import dash
import dash_table
import dash_core_components as dcc
import dash_html_components as html
from dash.dependencies import Input, Output
import plotly.express as px
df = opp_df
phases_order = ['Closed', 'Ph.5', 'Ph.4', 'Ph.3', 'Ph.2', 'Ph.1']
df['_phase_order'] = df['フェーズ'].apply(lambda x: phases_order.index(x) if x in phases_order else -1)
df = df.sort_values(['_phase_order', '受注予定日']).drop(columns='_phase_order')
app = JupyterDash()
app.layout = html.Div([
dcc.Dropdown(
id="dropdown",
options=[{"label": x, "value": x} for x in ['all', 'pipeline', 'commit', 'upside']],
value='all',
clearable=False,
),
dcc.Graph(id="bar-chart"),
dash_table.DataTable(
id = 'table',
columns = [{"name": i, "id": j} for i,j in zip(df,df.columns)],
data = df.to_dict('records'),
page_size = 10,
sort_action = 'native'
)
])
@app.callback(
Output("bar-chart", "figure"),
[Input("dropdown", "value")])
def update_bar_chart(visual_target):
show_df = df
if visual_target == 'all': pass
if visual_target == 'pipeline': show_df = show_df[show_df['分類'] == 'Pipeline']
if visual_target == 'commit': show_df = show_df[show_df['分類'] == 'Commit']
if visual_target == 'upside': show_df = show_df[show_df['分類'] == 'Upside']
fig = px.bar(show_df, x="受注予定日", y="金額",
color="フェーズ", barmode="stack")
return fig
バーチャートを表示するデータの順番を調整するために、ソートしている箇所がありますが、完全ではないようです。plotly expressではなく、graph object使えばいい感じにできそうですが、データが詰まってきたら解消されそうなので一旦放置します。(何を課題意識としてるかは「諦めたこと」の節で後述します。)
ダッシュボードの表示
app.run_server(mode="inline")
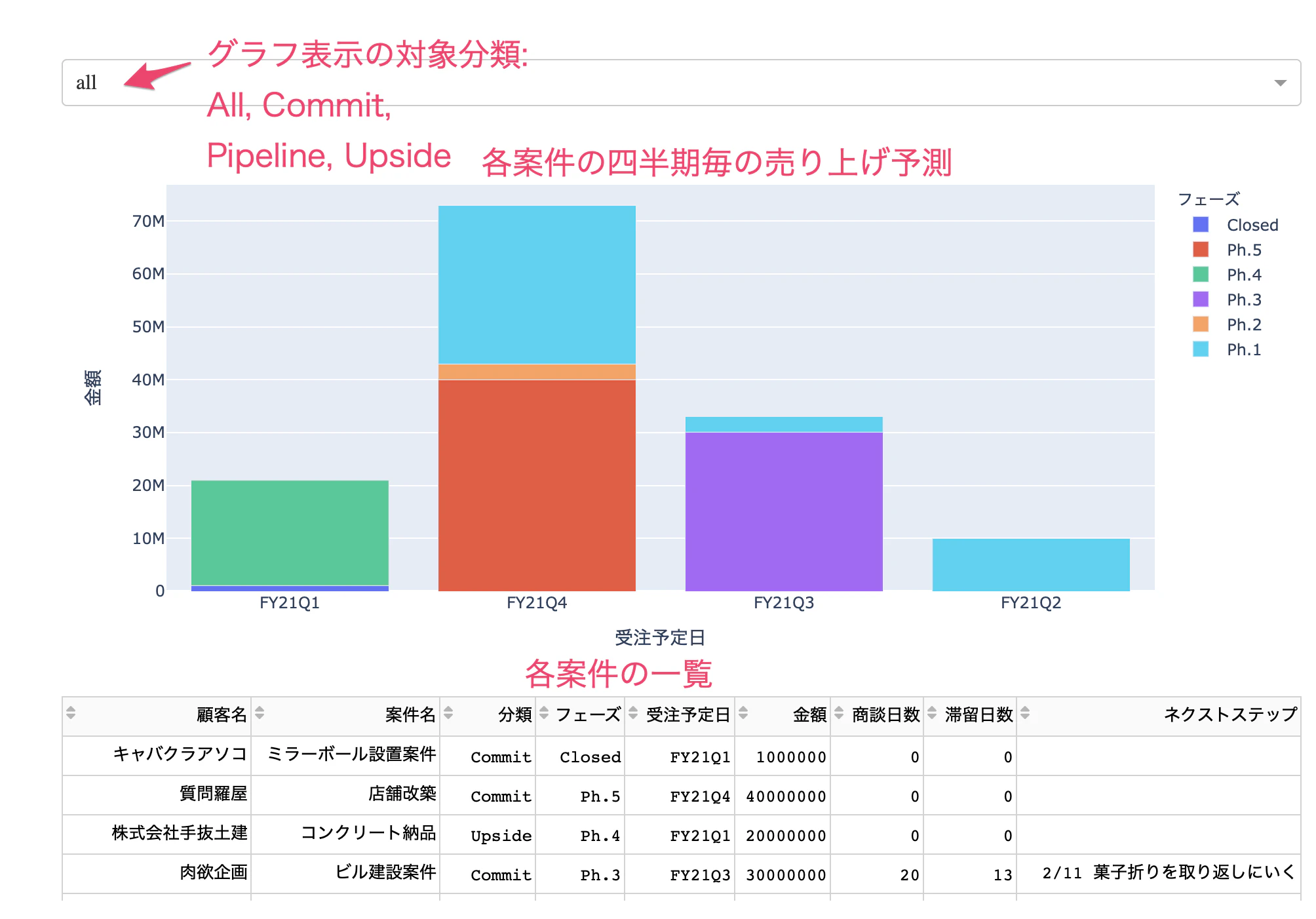
諦めたこと
以下の図で示したようにデータによっては気持ち悪い表現になっています。綺麗に描画するためにはgraph objectを使うことがいいと思うのですが、ちょっと記述が長くなってしまって大変だと思ってます。データが詰まってくれば解消される気がしてるので一旦諦めます。

4. シリーズ全体に対する振り返り
本シリーズを通して、商談管理を行うことを考え、最終的に意思決定に使えそうな可視化まで行うことをしました。利用したサービスは、TrelloとGoogle Colaboratoryで全て無償枠でここまで実施することができました。
5. 総括とTODO
ちょっとメンテナンスきつそうなので、おとなしくSFA導入した方がいいような気がしたました。しかし、少ない営業人員ならこれでやっていけるかもしれません。
現状はあくまで可視化することができたところなので、エンジニアリングの本領が発揮するのはこれからです。
そもそもこの記事を書いたのは、LGTMを多く集めているとある営業関連記事のコメントで以下のようなコメントを読んだことがきっかけです。
「エンジニア関係ないですね。」
Qiitaの規約上プログラミングのトピックである必要はありましたが、この方はエンジニアの定義もしくは営業プロセスについてひどく誤解されているようでした。
営業活動はアートのようなもので、定量的に評価・改善ができないものと誤解されている方が少しでも減ることを望んでおります。
TODO:
- APIキーの環境変数化またはファイル化
- Notebookの共有設定
- Google Spreadsheet連携
- Slackチャネルへの自動投稿
全体を通した振り返りは4章で議論しました。実運用を通して必要な情報管理や可視化に対しての改善策が見えてくると思います。思いついたらTODOで示した内容以外でも記事を更新していこうと思っています。