RDFデータを格納し、SPARQLで検索できるRDFストアとしてApache Jena Fuseki(以下、Fuseki)があります。本稿ではFusekiにRDFデータをロードしてSPARQL検索を試す方法を記述します。Fusekiのインストールおよび立ち上げについては、こちら(Mac OS X)あるいはこちら(Windows)を参考にしてください。なお、Fusekiのバージョンは2.6.0および3.8.0で動作確認しています。また、JavaについてはOracleおよびOpenJDKでの動作確認をしています。
注意事項
3.4.0ではSPARQL更新系クエリ(LOAD)を用いたDBpedia Japaneseのデータロードが失敗するので、下記の例を適切に実行できません。
データのロード
-
Fusekiを立ち上げ、http://localhost:3030/にアクセスします。
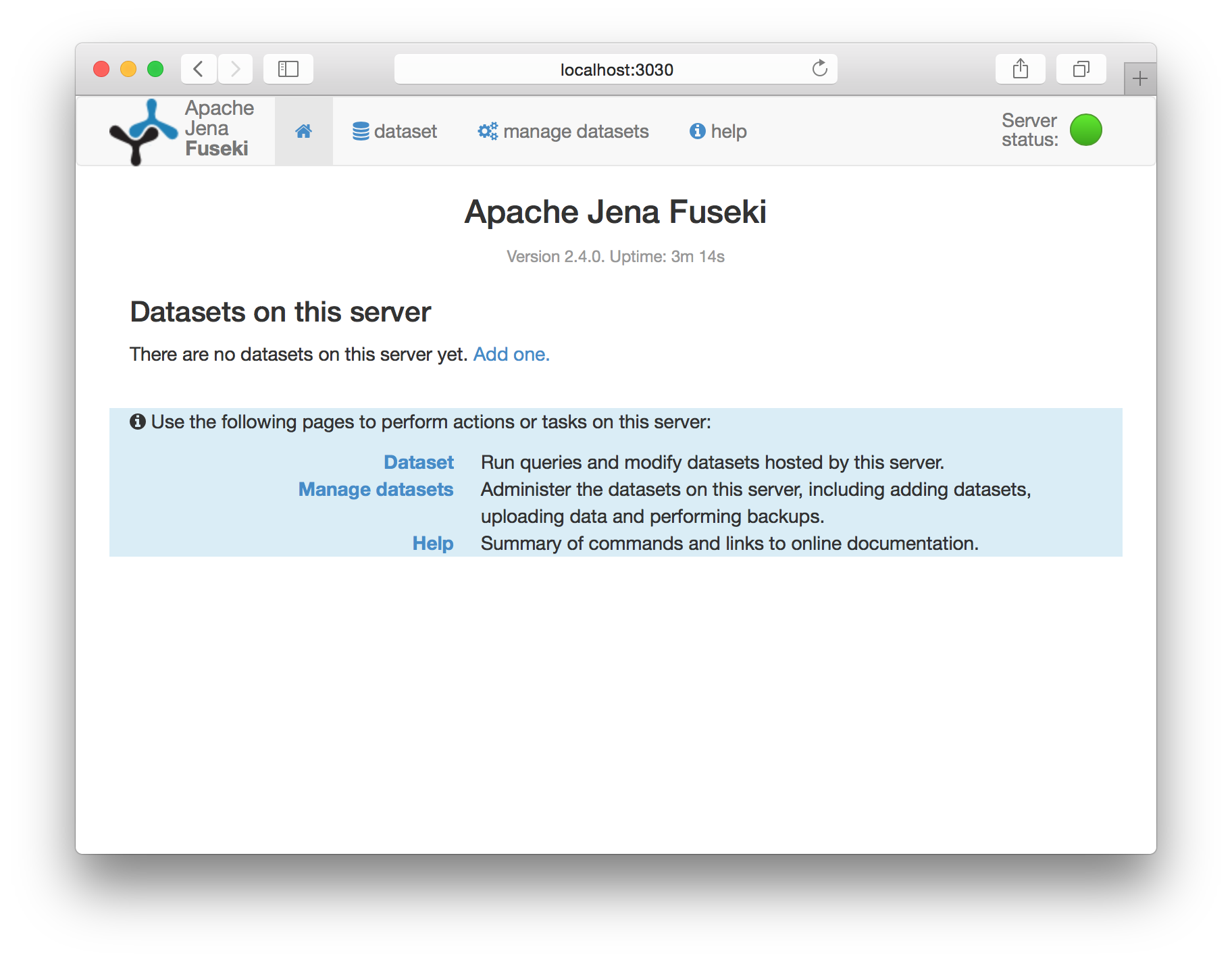
-
「manage datasets」をクリックし、続いて「add new dataset」タブをクリックします。
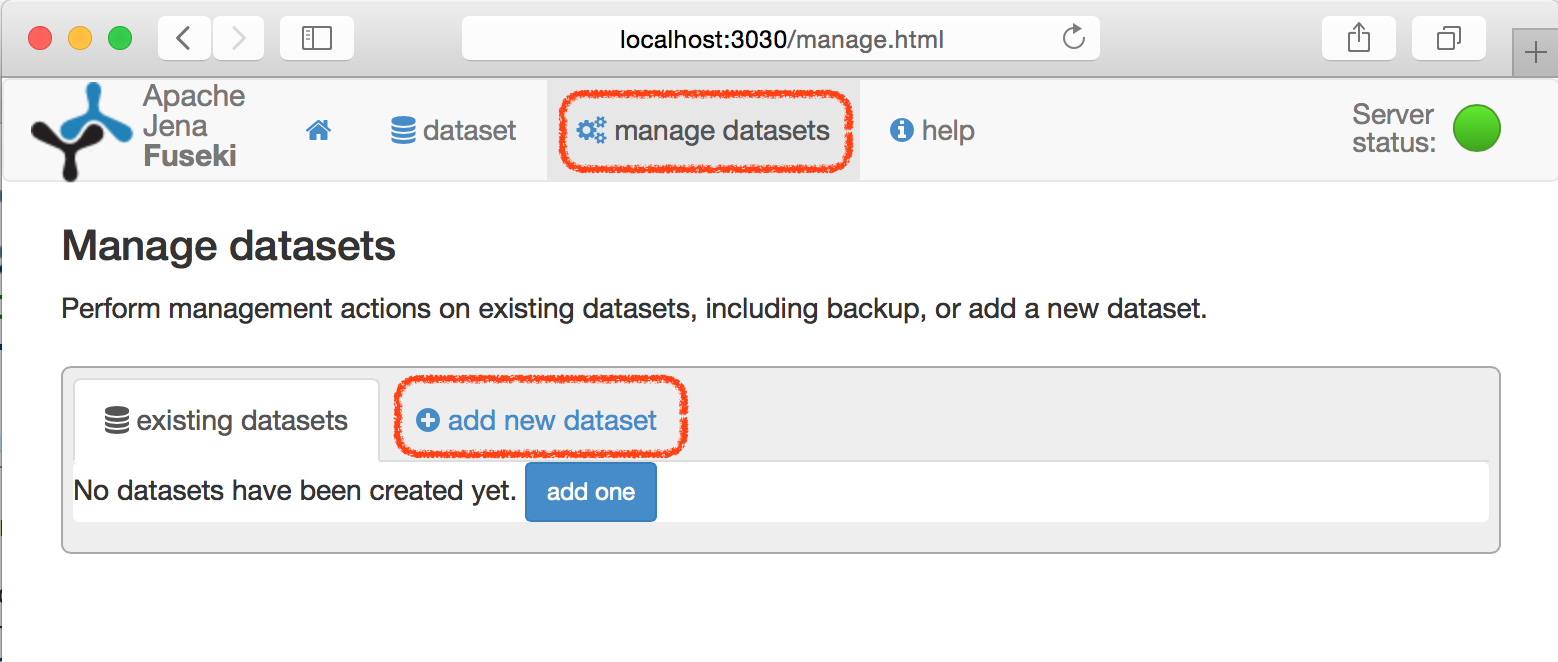
-
「Dataset name」に適当な名前を記入し、「create dataset」をクリックします。ここでは「MyData」としています。なお、初期設定ではロードされる全てのデータはメモリ内にのみ格納されるので、立ち上げたFusekiを終了すると消えてしまいます。永続性を持たせるには「Dataset type」を「In-memory」から「Persistent」に変更します。
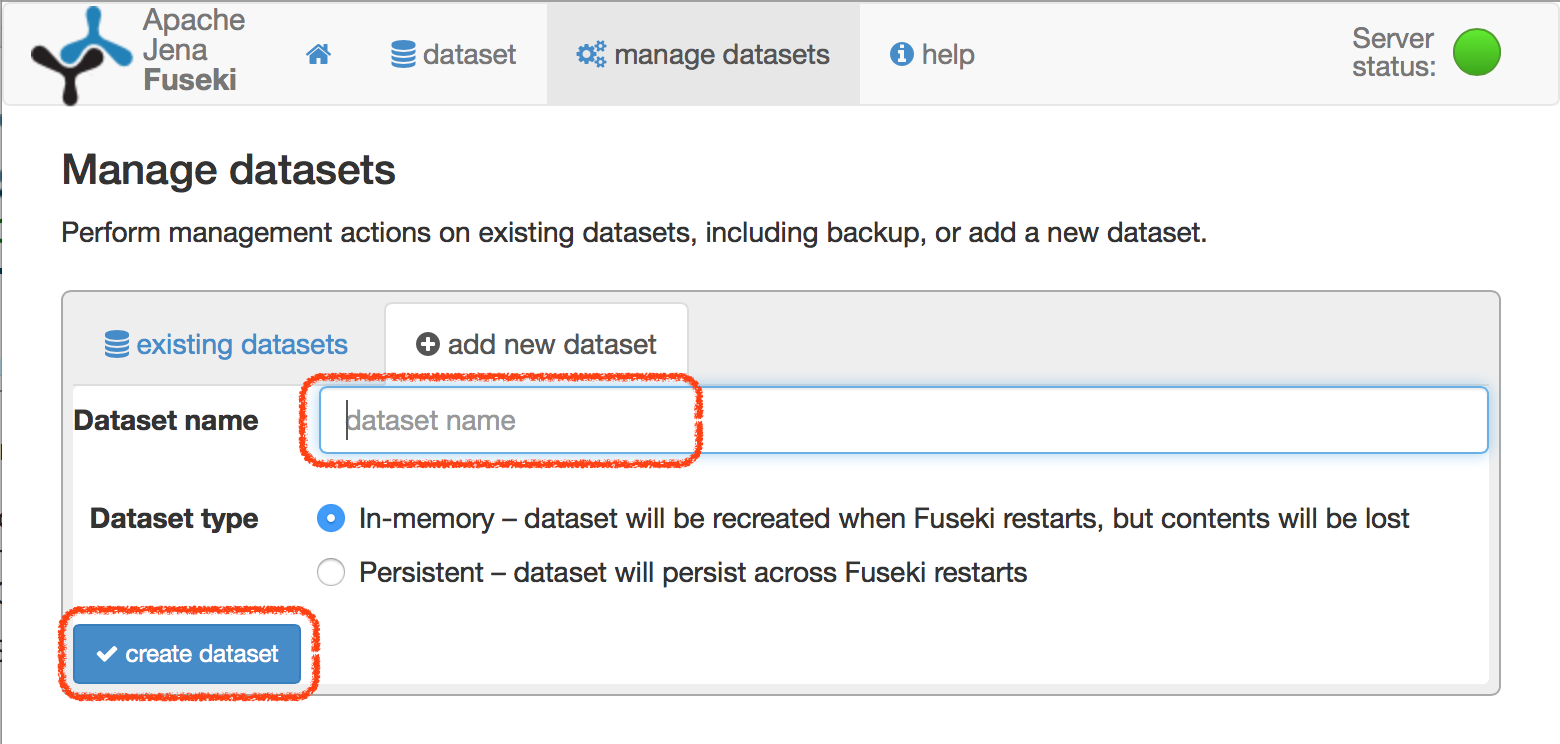
-
以上でRDFデータを格納するデータベースが構築できたので、続いてそこにデータをロードします。ページ上部のバーにある「dataset」をクリックし、続いて、「info」タブをクリックします。
なお、Fusekiにデータをロードするには大きく分けて2通りあり、一つは手元にあるRDFファイルをアップロードするもので、もう一方はネット上にあるデータを直接ロードするものです。ここでは後者を紹介します。というのは、手元にすでにRDFデータがある読者は少ないと想定していることと、SPARQLの仕様がバージョン1.0から1.1に更新された際に追加された、データを更新するためのクエリを試すことができるからです。
「info」タブをクリックすることで表示される「Available services」の中に、「SPARQL Update」としてhttp://localhost:3030/MyData/updateが書かれています。このエンドポイントURIに対して更新用のクエリを発行できます。
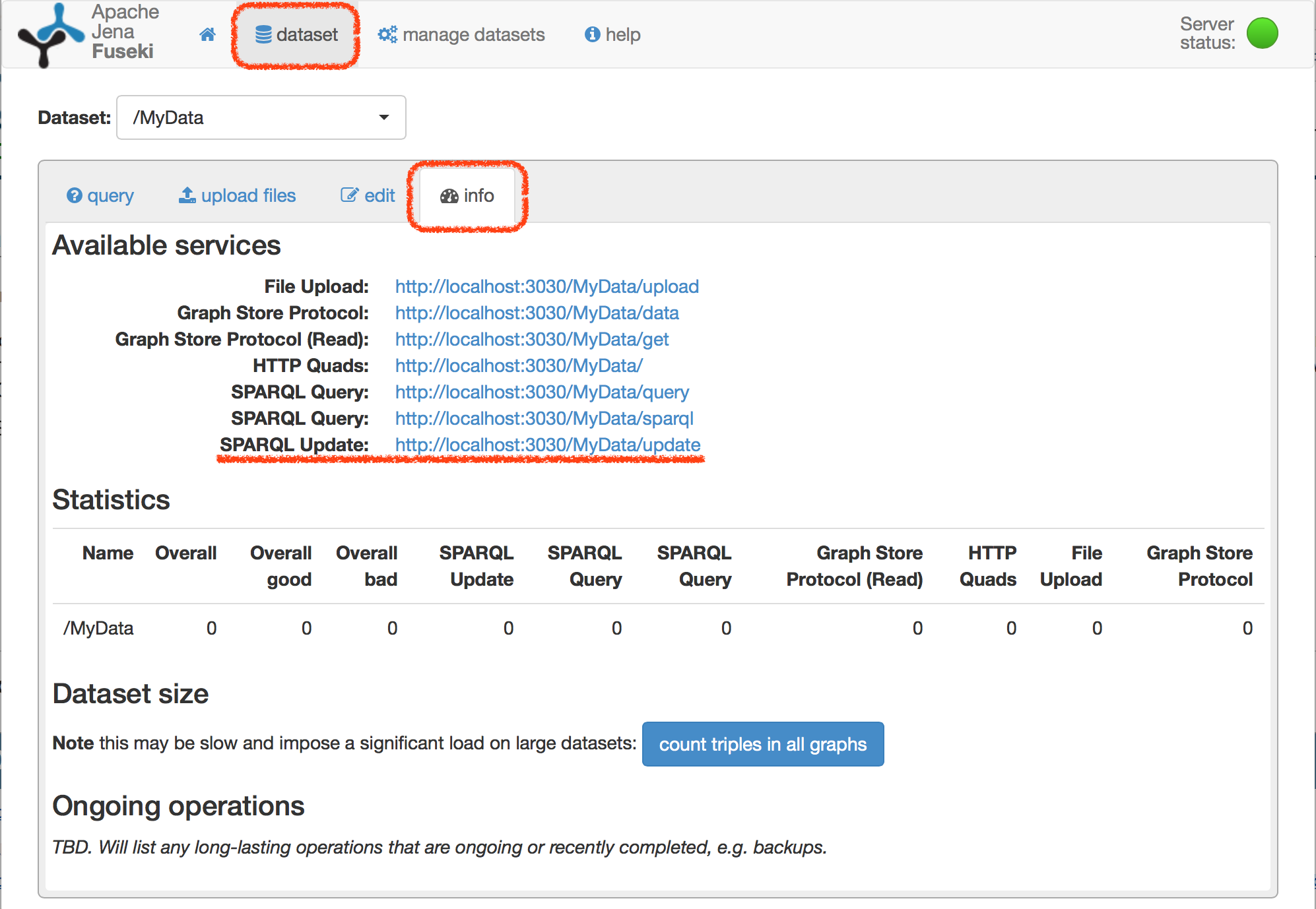
-
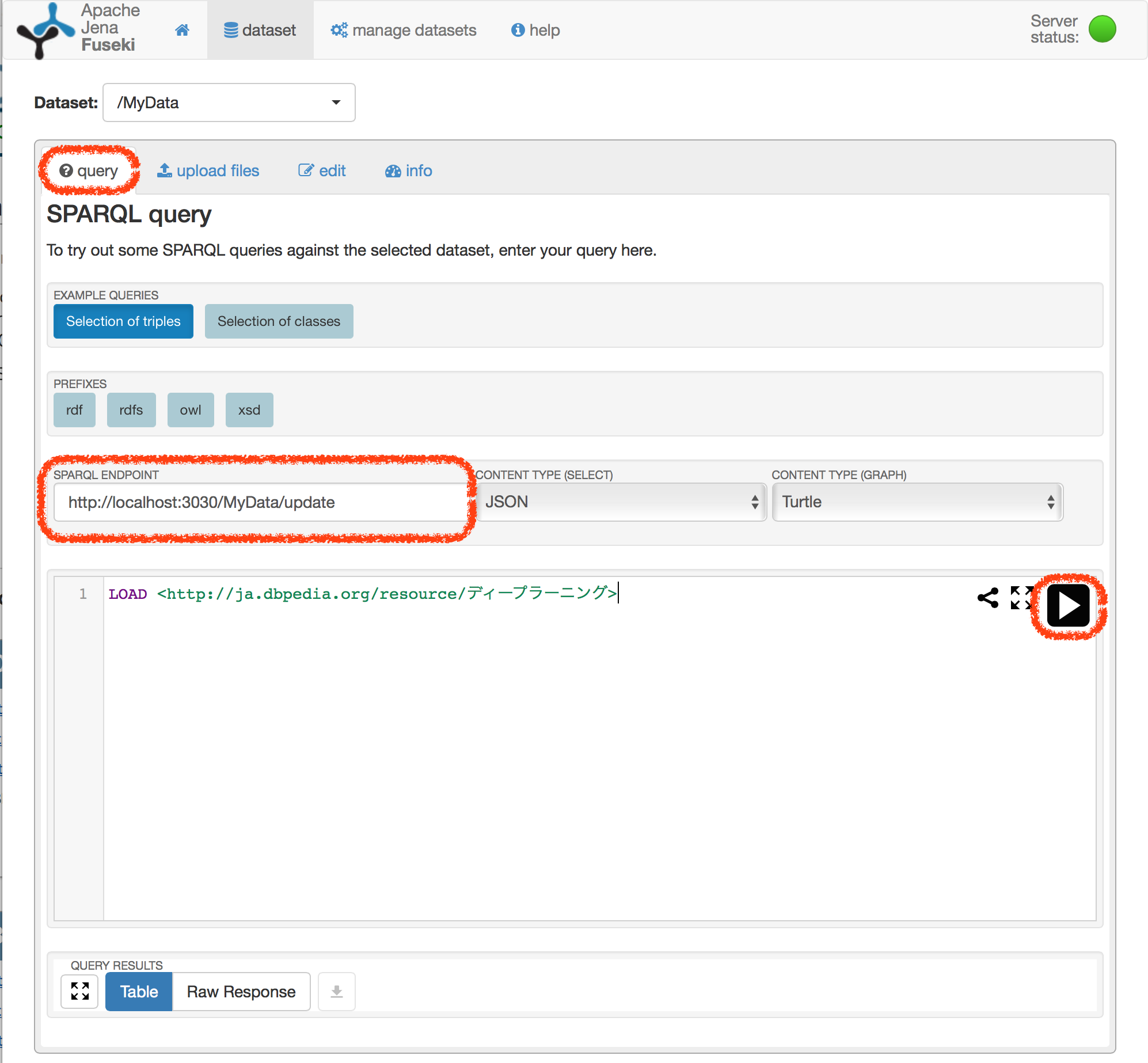
「query」タブをクリックし、「SPARQL ENDPOINT」に上記の更新用エンドポイントのURIを記入します。続いて、その下の欄に、
LOAD <http://ja.dbpedia.org/resource/ディープラーニング>と記入します。その後、右側の矢印アイコンをクリックし、クエリをエンドポイントに向けて発行します。
-
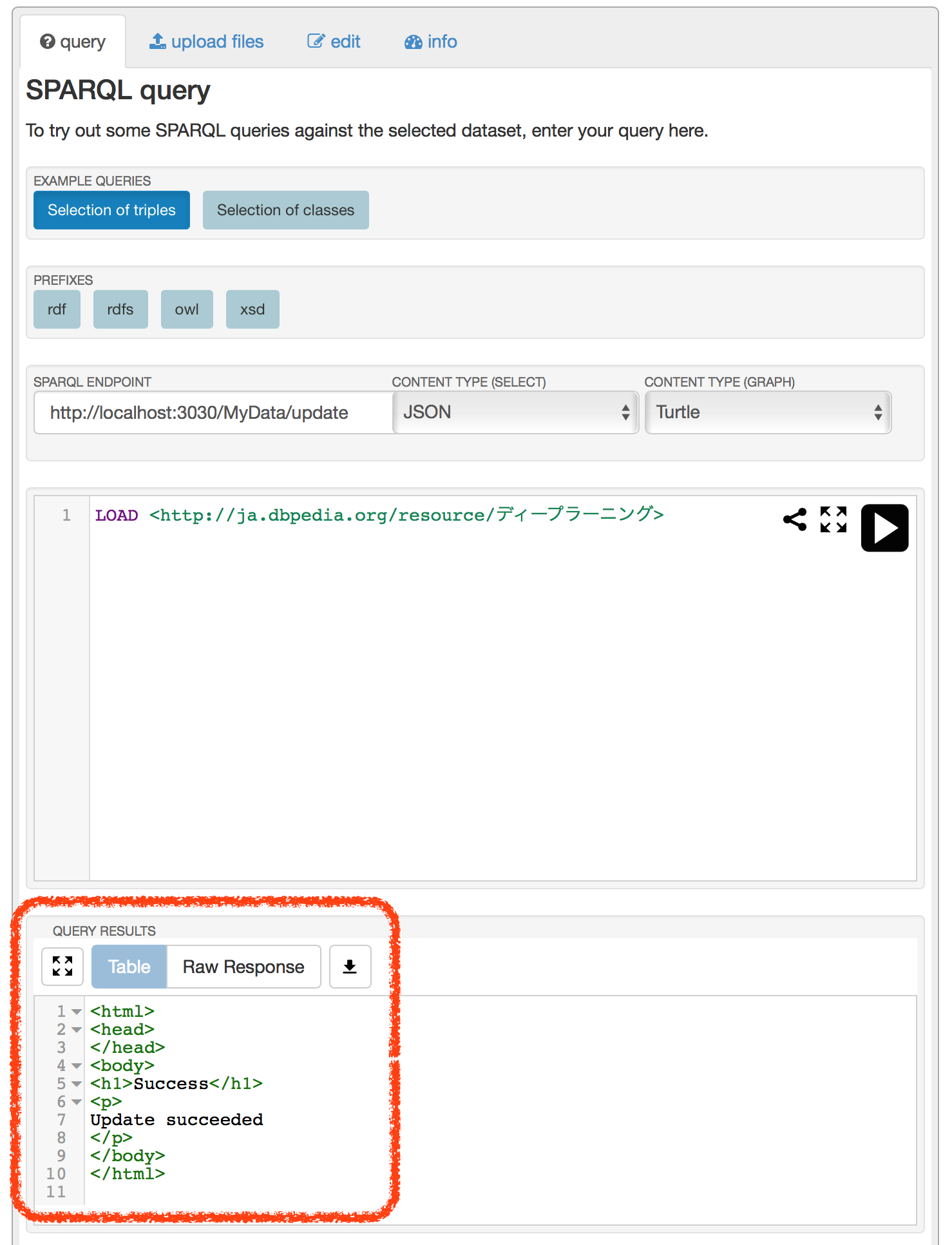
ページ下部にある「QUERY RESULTS」に「Update succeeded」の表示があるのを確認します。これで手元のFusekiにRDFデータがロードされました。
SPARQLでデータを検索
-
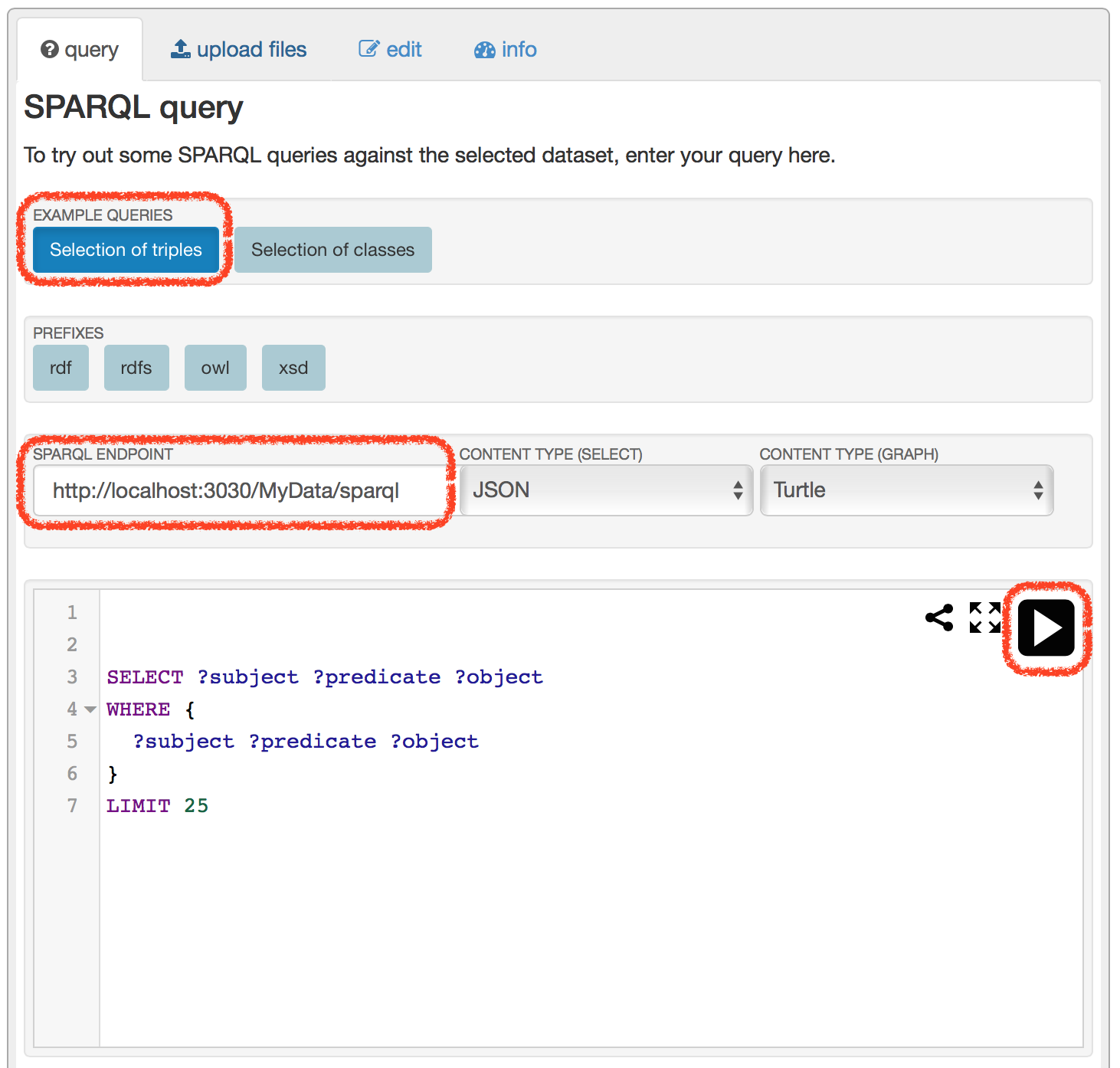
「SPARQL ENDPOINT」に参照用クエリ発行用エンドポイントhttp://localhost:3030/MyData/queryを記入します。続いて、「EXAMPLE QUERIES」の「Selection of triples」をクリックします。すると、実際のSPARQLクエリが自動的に書き込まれるので、それを確認してから、更新時と同様に矢印アイコンをクリックします。
-
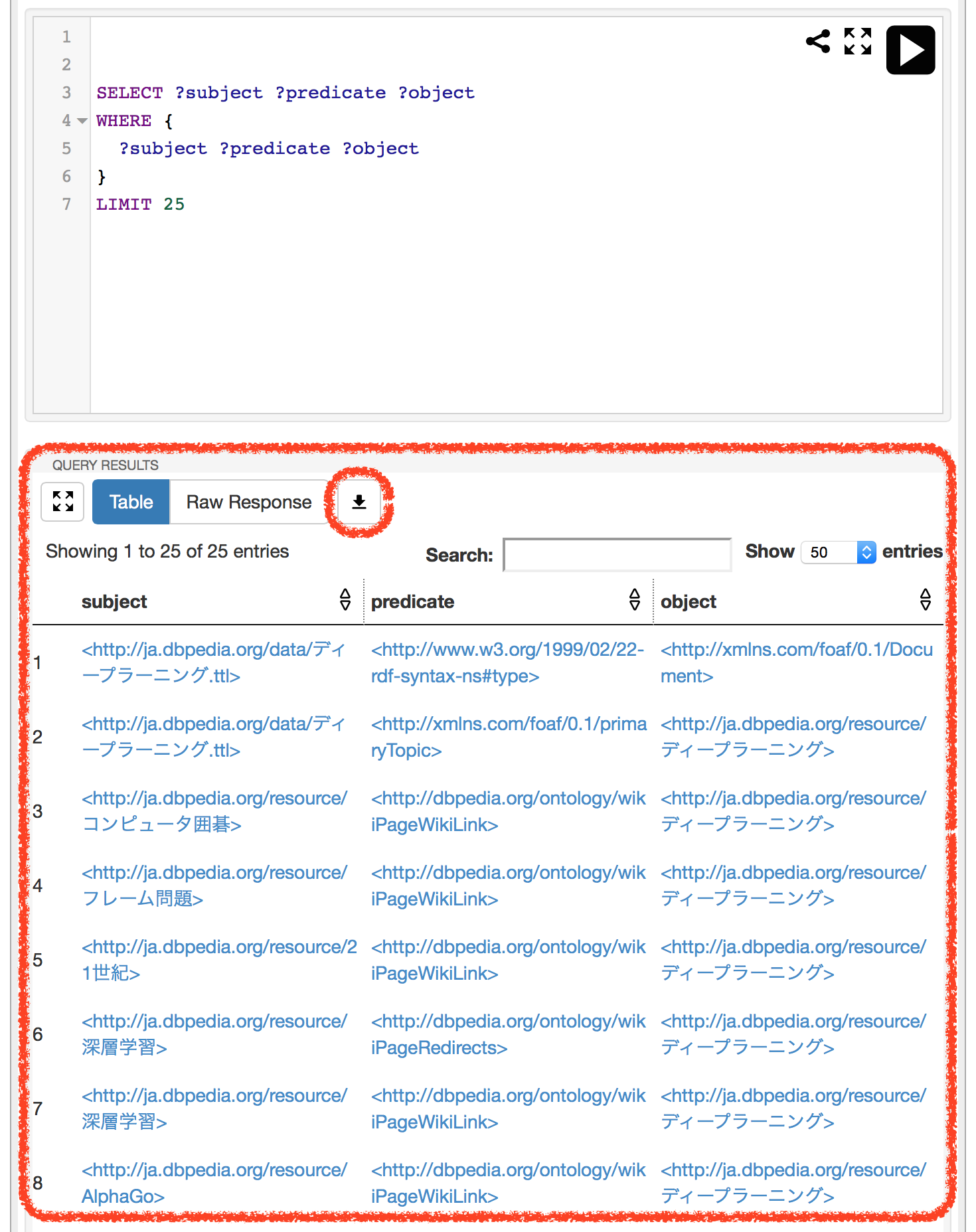
「QUERY RESULTS」に結果が表示されます。結果は、下矢印アイコンをクリックすることでCSV形式のファイルとして取得できます。
-
今実行したクエリを再現できるように、パーマリンクを取得したり、ターミナルを開いてcurlコマンドにより同じ結果を取得したりすることが簡単にできるようになっています。クエリを記述する欄の右上にある<の形をしたアイコンをクリックします。最初に表示されるのはブラウザに直接コピペできるようなURIで、さらに右側の「CURL」ボタンをクリックすることで、CURLコマンド用の記述に書き換えられます。
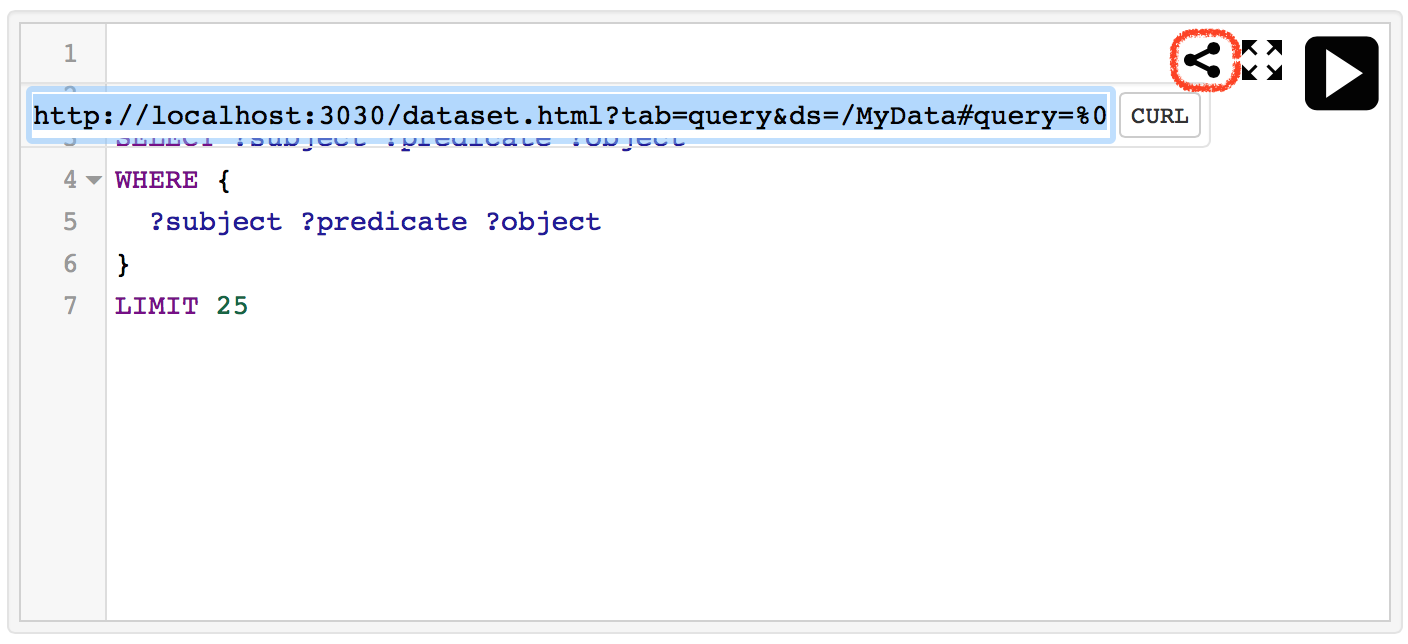
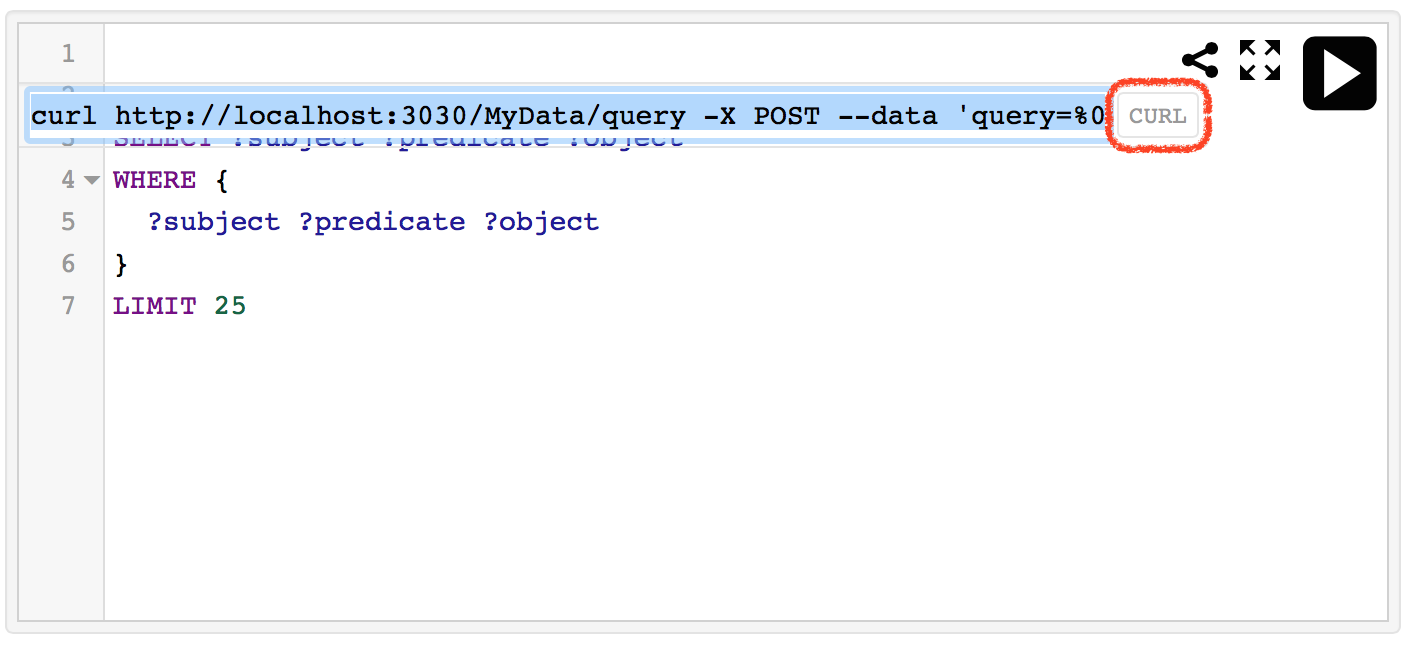
以上でFuseki上でのSPARQLクエリによるRDFデータの検索を確認できたと思います。SPARQLを用いることで様々な条件でRDFデータを検索できます。より詳細は筆者を含む有志が執筆した書籍を参考するなどしてください。