はじめに
タイトルにもありますが、本日取り上げる話はSQLonHadoopです。
ある案件で基幹系業務にApacheDrillを導入したのですがどう設計すれば
良いのかわからず悪戦苦闘したのでSQLonHadoopを導入する際のノウハウをまとめてみました。
SQLonHadoopとは
SQLonHadoopとはHDFS上に保存されたデータに対してSQLライクに問い合わせて
データを処理することを意味します。
SQLonHadoopはHiveが主流ですが、HiveQLというSQLとはやや異なる文法を用いて記述します。
しかしDrillならANSI準拠で記述することができるのでほぼSQLと思ってもらって問題ありません。

Drillの特徴
SQLonHadoopのプロダクトは色々存在しますがその中でもDrillの特徴をまとめてみました。
1. スキーマ定義不要
2. アドホックな分析が可能
3. クラスタリング可能
4. ANSI準拠でクエリ実行可能
5. Jsonをはじめとする多様なデータソース対応
詳細な内容まで触れてしまうとこの記事では書き切れないので公式ドキュメントで割愛します。
https://drill.apache.org/docs/
HDFS設計のポイント
SQLonHadoopを導入する上で一番大切なのはHDFSのディレクトリ構成です。
FROM句に参照したいデータがあるHDFSのディレクトリパスを指定するので
HDFSのディレクトリはDBでいうところのテーブルに相当します。
今回の案件ではOracleで持ちきれなくなったデータをHDFSに流し
そのデータに対してDrillで分析したいという要件だったので
DBのテーブル名と同じ命名規約で親ディレクトリを切りその下に
YYYYMMの形式で日付ディレクトリを切る設計にしました。
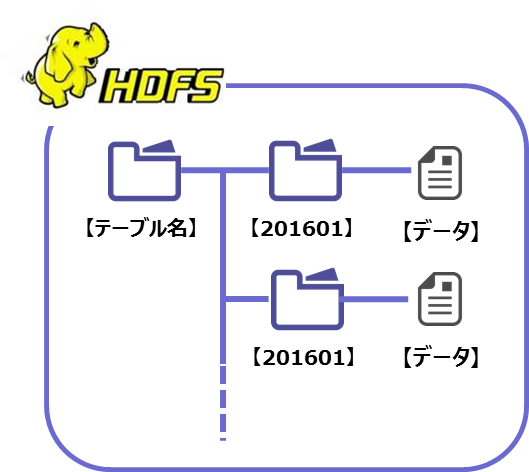
テーブル名をFROM句に指定するとフルスキャンと同様に全期間のデータに対してアクセスします。
FROM句に日付ディレクトリを指定すると指定した期間のみアクセスするのでレンジスキャンと
同等の効果が期待でき、パフォーマンス向上に繋がります。
またDrillではFROM句に正規表現を用いてディレクトリパスを指定できるので
WHERE句で条件指定しなくてもFROM句で複数期間のデータを参照することが可能になり
クエリの簡略化にも繋がります。
このようにHDFS設計によって大きく影響を受けてしまうのがSQLonHadoopの特徴です。
仮にSQLonHadoopを使う要件が無くてもHadoop基盤構築時に今後の拡張性を考慮して
SQLonHadoopでHDFSのアクセスを行うことを想定して設計を行うのがベターだと私は考えます。
ファイルフォーマットによる性能差
HDFS設計と同じくらい大切なのがファイルフォーマットです。
SQLonHadoopの謳い文句として多種多様なファイルフォーマットに対応可能と言っていますが、
ファイルフォーマット毎に性能面で大きな差が出ることが今回検証して分かりました。
以下が5台のクラスタ構成で検証したフォーマット別の性能結果です。
データサイズはCSVで約40GBです。
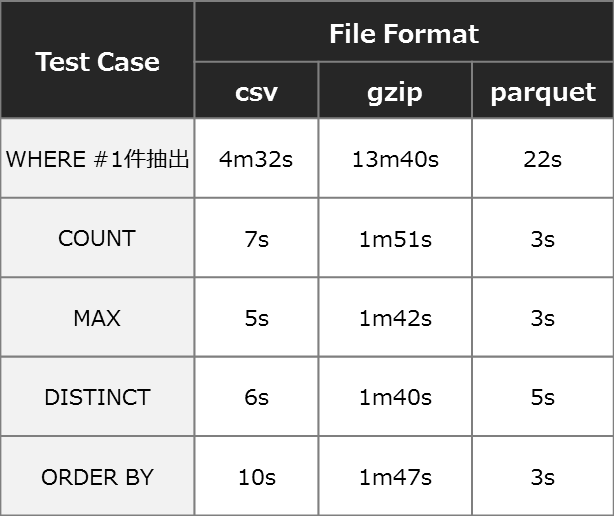
この結果を見るとgzip圧縮は非常にパフォーマンスが悪いことが分かります。
gzip圧縮はスプリット不可の圧縮フォーマットの為アクセス効率が非常に悪いことが原因です。
HDFSでデータを蓄積する際に圧縮率の高いgzip圧縮を採用することが多いと思われます。
しかしSQLonHadoopを利用することを想定した場合、圧縮フォーマットはlz4などスプリット可能な
圧縮フォーマットを選択するのが良いことが分かります。
メタデータ管理
クエリを実行する際には必ずカラムを指定するはずですし
もちろんそれはSQLonHadoopでも同じです。
しかしSQLonHadoopで実際に参照しているのはHDFS上にあるファイルデータの為
一般的なファイルフォーマットだとメタデータが付与されていません。
そのため実際に運用していくためにはメタデータの付与を考える必要があります。
方法はいくつかありますが、Drillの場合ファイルに対してVIEWを作成することで
メタデータを付与することが出来ます。
しかし、ファイルごとにVIEWを作成するというのはちょっとしんどいです。
そこで登場するのがHadoop用ファイルフォーマットである「parquet」です。
parquetはメタ情報とデータの両方を保持しています。
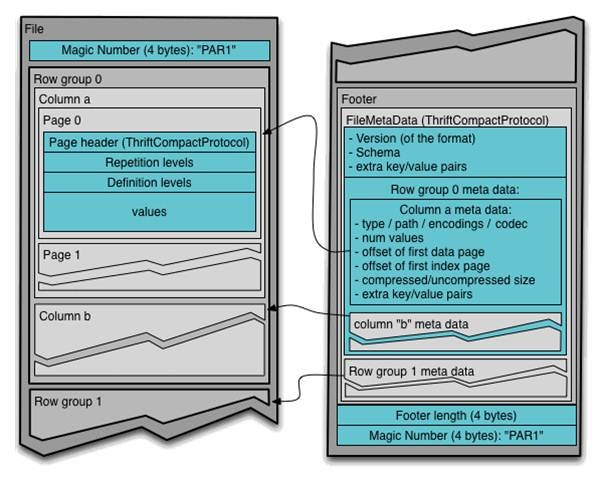
SQLonHadoopを導入する際にはこのparquetを利用することでメタと合わせて管理が
出来るため非常に便利です。
さらにparquetはカラムナー型のファイルフォーマットの為、パフォーマンス向上にも貢献します。
先述したファイルフォーマット別の性能結果を見れば分かると思いますが
CSVに比べ非常に良い性能が出ているため私が担当した案件ではparquetを採用しました。
認証認可
個人で利用する際には気にする必要ありませんが企業に導入するとなると
認証認可ができないと困ってしまいます。
DrillではLinux PAMによるユーザ名/パスワードをベースにした認証がサポートされています。
設定方法は下記のサイトを参考にすると良いです。
http://nagix.hatenablog.com/entry/2015/12/24/235900
パーミッション設計
SQLonHadoopではCTASやDROPでディレクトリの作成や削除を行うことが出来ます。
Drillユーザーが好き勝手にこれらのクエリを発行されたらたまったものじゃありません。
Drill にはクライアントから要求されたアクションを、クライアント自身の権限で実行する
「インパーソネーション(Impersonation)」機能があります。
先述したPAM認証と合わせて利用することでDrillで実行できる権限を
ユーザー別に制御することができます。
PAMの認証で利用するユーザーはOSユーザーに紐づいています。
そのため、CTASやDROPを自由にさせないためにパーミッションで制限をかけます。
リード権限を与えなければデータの参照も制御できます。
おわりに
近年ビッグデータは貯めるではなく利用することに価値が高まっています。
Hadoopに蓄積されたデータを慣れ親しんだSQLで分析したいというニーズは今後間違いなく
高まってきます。しかし、DBと違いまだまだ設計のノウハウやナレッジが足りないため
いざ導入しようと思っても情報が少ないのが現実です。
本記事がSQLonHadoopを導入しようとする方々のお役に立てれば幸いです。