はじめに
Futureアドベントカレンダー15日目を担当させて頂きます。
昨今ビッグデータという言葉もすっかり浸透し、エンタープライズで"NoSQL"を耳にすることが増えました。
本記事ではNoSQLネタとして"Cassandra"を紹介しつつ、NoSQL(KVS)のデータモデルの検討ポイントを伝えられたら良いなと思います。
そもそも"NoSQL"とは何者か考えてみる
Cassandraの話をする前に、まずはそもそも"NoSQL"とは何者なのかを考えてみましょう。
NoSQLとは **「Not only SQL」**を語源としており **「SQLだけでない = 非RDB」**という意味で解釈されることが多いです。
エンタープライズシステムではRDB(リレーショナルデータベース)が多く採用されています。
その理由は一言では言い尽くせませんが、テーブル結合によってSQLで複雑なビジネスロジックを
表現出来たり、厳格なトランザクション管理ができたりなどが理由に当たります。
しかし、近年ビッグデータ時代到来と共に下記のようなニーズが発生し、RDBだけでは対応しきれなくなってきました。
-
構造的なデータだけでなく非構造的なデータも扱いたい
⇒ RDBは扱うデータを事前に定義しておく必要がある -
データを長期間蓄積してデータサイズが大きくなったとしても高速に処理したい
⇒ RDBはサーバースペックをスケールアップさせるアーキテクチャのため容量・性能共に限界がある
このように「Volume(量)」「Velocity(処理速度)」「Variety(多様性)」のニーズを受けそれらを満たせるよう、
NoSQLは基本的にスキーマレスかつスケールアウト可能な**「分散アーキテクチャ」**を採用しています。
とはいえ、結合処理を排除していたりトランザクション機能がないなど従来RDBが当然満たしていた機能をNoSQLは苦手とします。
つまり、データの特性・扱い方に応じてRDBを採用するべきか、NoSQLを採用するべきか、
はたまた両方採用するべきかを考える必要があります。
エンタープライズ領域からRDBを完全に排除することは難しいのでこれが**「Not only」**と呼ばれる所以と思っています。
Cassandraはどんなデータベースなのか
CassandraはもともとAmazonのDynamoの概念とGoogleのBigtableのアーキテクチャを組み合わせて
Facebookによって開発され、2008年にオープンソース化されたデータベースです。

CassandraはNoSQLの中でもアプリケーション利用を意識した作りになっており、
NoSQLは一般的にスキーマレスを採用することが多いのですがアプリケーション側から見るとデータは
構造的に見える方が開発・運用・管理していく上ではメリットがあるのでスキーマ定義を前提としています。
カラム型にListやMapのような配列型をサポートしているため、定義しても柔軟で流動的なデータモデルを実現することができます。
その他にも下記のような特徴を持っており、スケーラビリティ・アベイラビリティに重きを置いたデータベースと言えます。
- データをクラスタ内の複数ノードで分散保持しているため、性能・容量のリニアにスケール可能
- マスタレスアーキテクチャで、単一障害点がなくノード障害時のマスタ切り替え不要で可用性を厳格に保証
- データセンターを跨ぐクロスリージョン構成を取ることができるため広域災害などBCP要件を満たすことが可能
本記事はデータモデルについて書くのでこの辺のアーキテクチャ説明は追々どこかでできたら。。。
Cassandraのデータモデルを理解する
CassandraではRDBと同様にデータを「テーブル」という単位で管理を行います。
テーブルは「キースペース」と呼ばれる領域に作成されます。Oracleでいうところの「スキーマ」にあたります。
先述しましたが、Cassandraはスキーマ定義を前提としているためテーブル作成時にカラムと型を予め宣言する必要があります。
ちなみにCassandraではCQLという独自のクエリ言語をサポートしており、SQLライクに記述できるためRDB脳でも直感的に扱えます。
CREATE TABLE test_table (
id text
, body text
, tag list<text>
, keyword map<text, text>
, PRIMARY KEY(id)
);
RDBとの違いはListやMapなどの配列型をサポートしているところです。
これによってスキーマ定義しつつもJsonなど半構造体データなどの扱いも柔軟に行えるというのが特徴ですね。
INSERT INTO test_table (
id
, body
, tag
, keyword
) VALUES (
'01'
, 'AdventCalendar15日目'
, ['Future','NoSQL','AdventCalendar']
, {'name': 'Iwasaki', 'age':'26'}
);
-- ListとMapの要素数を増やしてみる
INSERT INTO test_table (
id
, body
, tag
, keyword
) VALUES (
'02'
, 'AdventCalendar99日目'
, ['Future','NoSQL','AdventCalendar','Cassandra']
, {'name': 'future-taro', 'age':'30','gender':'male'}
);
List型のtagとMap型のkeywordの要素数違いでも問題なくデータ投入できるので柔軟なデータモデルであるといえますね。
SELECT * FROM test_table ;
id | body | keyword | tag
----+----------------------+--------------------------------------------------------+----------------------------------------------------
02 | AdventCalendar99日目 | {'age': '30', 'gender': 'male', 'name': 'future-taro'} | ['Future', 'NoSQL', 'AdventCalendar', 'Cassandra']
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future', 'NoSQL', 'AdventCalendar']
そしてもう一つCassandarのデータモデルで抑えておくべきことは、データアクセスの仕方です。
CassandraはKVS(正確にはワイドカラム型)なので、プライマリーキー以外のカラムを絞り込み条件にすることができません。
例えばカラム"body"をWHERE句の条件に指定してみましょう。
SELECT * FROM test_table WHERE body = 'AdventCalendar15日目' ;
-- エラー発生
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
エラーが発生してデータ取得に失敗しました。
Cassandraのデータアクセス時には必ずプライマリーキーを指定する必要があります。
SELECT * FROM test_table WHERE id = '01' ;
id | body | keyword | tag
----+----------------------+----------------------------------+---------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future', 'NoSQL', 'AdventCalendar']
ちなみにエラー文をよくよく読んでみると「ALLOW FILTERING」を使ってくれとありますが、
これは性能を気にしなくてもいいなら"ALLOW FILTERING"オプションをつければ実行できるというものです。
なぜ、プライマリーキー以外のカラムをWHERE句に指定すると性能劣化を引き起こすのか考えてみましょう。
Cassandraは基本的に複数ノードでクラスタ構成を取り、データはパーティションキーのハッシュ値を基に分散配置されます。
テーブル作成時にデフォルトで「プライマリーキー=パーティションキー」となるため上記の例では"id"を
パーティションキーとして分散配置されることになります。
テーブルにデータ格納時はパーティションキーのインデックスのみ作成されるので、パーティションキーをもとにデータが
どのノードに存在するのかを探しに行くという流れになります。
言い換えれば、パーティションキーを指定しないアクセスは全ノードの全レコードを舐めないと条件に一致するかを
評価できないので"ALLOW FILTERING"によるデータアクセスは性能劣化を伴うアンチパターンなアクセスになると言えます。
テーブルに対してセカンダリインデックスを作成することで任意のカラムに対してインデックスを作成することもできます。
CREATE INDEX body_idx ON test_table (body);
SELECT * FROM test_table WHERE body = 'AdventCalendar15日目' ;
id | body | keyword | tag
----+----------------------+----------------------------------+---------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future', 'NoSQL', 'AdventCalendar']
DynamoDBではセカンダリインデックスを張れる数に制約がありましたが、Cassandaraには無いというのもちょっとした特徴です。
Cassandraのデータモデル設計ポイントを考える
なんとなくCassandraのデータモデルがイメージできるようになったと思いますがどのように設計するのが良いかを考えていきます。
下記にデータモデル設計時のポイントについて箇条書きしてみました。
ベストプラクティスと謳いたいところですが、私も現在進行形で検討中なのでその一部を紹介する感じになりますがご了承下さい。
- データモデルのネストを深くしすぎない
- インデックス使用を前提としたテーブル設計にしない
- リレーションは非正規化するか疑似結合するか検討する
- ロックはなるべく取得しない(後勝ち)ように設計する
1. データモデルのネストを深くしすぎない
Cassandraはテーブルを事前に定義するため、アプリケーションから受け取るデータの形を事前に決めておく必要があります。
柔軟なデータモデルに対応するため、ListやMapなどの配列型を利用することができると先述しましたが、
下記のようなMapのネストなど多階層のデータを扱いたくなることが往々にしてあると思います。
{
"address" : {
"country": "japan",
"city": "saitama"
}
}
Cassandraでも配列に対するネストを扱うことができるのですがテーブル定義時に**"frozen"**と指定する必要があります。
CREATE TABLE test_table2 (
id text PRIMARY KEY,
f_map map<text, frozen<map<text, text>>>
);
INSERT INTO test_table2 (
id
, f_map
) VALUES (
'01'
, {'address': {'city': 'saitama', 'country': 'japan'}}
);
SELECT * FROM test_table2;
id | f_map
----+------------------------------------------------------
01 | {'address': {'city': 'saitama', 'country': 'japan'}}
このように深いネストを表現する際にfrozenはとても便利なのですが使用時に下記のような注意点もあります。
- Map,Listのように要素に対する更新、追加、削除処理が行えない
MapやListであれば下記のように要素に対する操作を行うことが出来ます。
SELECT * FROM test_table WHERE id = '01';
id | body | keyword | tag
----+----------------------+----------------------------------+---------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future', 'NoSQL', 'AdventCalendar']
-- tagの要素'Future'を'future architect'に変更してみる
UPDATE test_table SET tag[0] = 'Future Architect' WHERE id = '01';
id | body | keyword | tag
----+----------------------+----------------------------------+-------------------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future Architect', 'NoSQL', 'AdventCalendar']
-- tagの要素を追加してみる
UPDATE test_table SET tag = tag + ['append'] WHERE id = '01';
id | body | keyword | tag
----+----------------------+----------------------------------+-----------------------------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future Architect', 'NoSQL', 'AdventCalendar', 'append']
このような操作がfrozen項目には行うことが出来ません。
frozen項目に対して更新を行うには要素全体を置き換える必要があります。
UPDATE test_table2 SET f_map = {'address': {'city': 'tokyo', 'country': 'japan'}} WHERE id = '01';
SELECT * FROM test_table2;
id | f_map
----+----------------------------------------------------
01 | {'address': {'city': 'tokyo', 'country': 'japan'}}
配列のネスト項目に対する部分更新がアプリケーションから想定される場合、frozenで定義していると
更新対象以外の項目もまとめて転送する必要があるので転送サイズが肥大化し、同時更新時も不整合が発生する可能性があります。
- Mapのキーやエントリ値を条件句に使用することが出来ない
Map項目に対して下記のようにインデックスを付与することで検索条件に利用することが出来きるのですが
frozenされた項目に対してはインデックスを張ることが出来ません。
SELECT * FROM test_table;
id | body | keyword | tag
----+----------------------+--------------------------------------------------------+-----------------------------------------------------------
02 | AdventCalendar99日目 | {'age': '30', 'gender': 'male', 'name': 'future-taro'} | ['Future', 'NoSQL', 'AdventCalendar', 'Cassandra']
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future Architect', 'NoSQL', 'AdventCalendar', 'append']
-- keywordのKEY値に対してインデックスを作成する
CREATE INDEX key_idx ON test_table ( KEYS (keyword) );
SELECT * FROM test_table WHERE keyword CONTAINS KEY 'gender';
id | body | keyword | tag
----+----------------------+--------------------------------------------------------+----------------------------------------------------
02 | AdventCalendar99日目 | {'age': '30', 'gender': 'male', 'name': 'future-taro'} | ['Future', 'NoSQL', 'AdventCalendar', 'Cassandra']
-- keywordのエントリ値に対してインデックスを作成する
CREATE INDEX ent_idx ON test_table ( ENTRIES (keyword) );
SELECT * FROM test_table WHERE keyword['name'] = 'Iwasaki';
id | body | keyword | tag
----+----------------------+----------------------------------+-----------------------------------------------------------
01 | AdventCalendar15日目 | {'age': '26', 'name': 'Iwasaki'} | ['Future Architect', 'NoSQL', 'AdventCalendar', 'append']
このようにデータモデルのネストを深くしていくと検索条件に利用できなかったり、部分更新ができず
更新時に思わぬサイズのデータ転送が必要になったりするのでなるべくfrozenを利用しないデータモデル設計を心掛けましょう。
2. インデックス使用を前提としたテーブル設計にしない
RDBでも同じですが、インデックスを張れば何とかなるという前提でデータモデルを適当にして設計してはいけません。
特にKVSではどのカラムをパーティションキーにするかで、インデックスがないとデータアクセスさえできないということになりかねません。
Cassandraではセカンダリインデックスを作成することで任意のカラムを条件指定した検索が可能になりますが、
RDB同様にどのようなアクセスになるのかちゃんと意識して張る必要があります。
例えば下記のようなテーブルとレコードがあったとしてidがパーティションキーで5ノードにレコードが分散格納されているとします。
dateカラムを条件に絞り込みを行うにはインデックスが必要になるのでdate_idxを作成します。
これで日付を指定した検索が可能になりますが、例えば「2018-01-01」を条件に指定して検索を行うと
「id=02」と「id=04」の計2パーティションへのアクセスが必要になることが分かります。
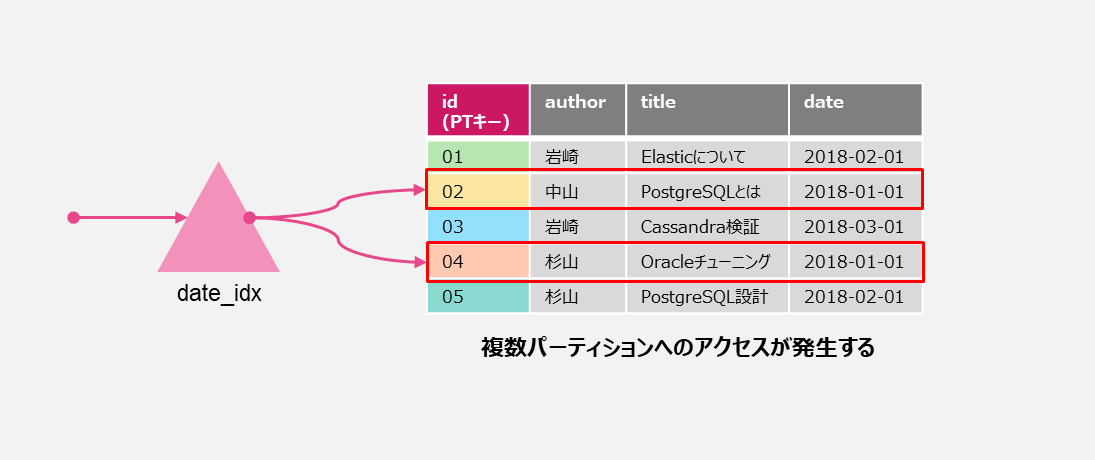
「2018-01-01」のカーディナリティが低ければ問題ありませんが、「2018-01-01」のカーディナリティが高くなると
大量のパーティションアクセスが発生し、分散処理を行う上でボトルネックになる可能性が高くなります。
そのため、日付を指定する検索が既に要件として固まっているのであればdateをパーティションキーとして構成してやれば
そもそもインデックスも不要になり、日付指定のアクセスは常に1パーティションになるので検索効率が良くなり性能も安定します。
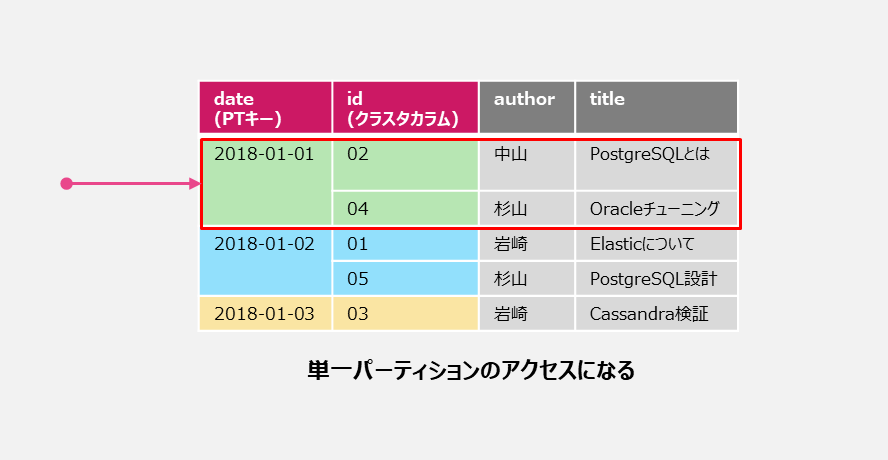
このようにアプリケーションの検索要件及び検索に利用する項目を整理してデータモデルを検討するのが良いです。
NoSQLはデータ容量を気軽にスケールできるので、検索条件ごとに最適なテーブルを作るというのも意外と現実解として考えられます。
ちなみにCassandraでは新しいプライマリーキーとカラムを指定してマテリアライズド・ビューとして再構築することも可能です。
便利な機能ですが、ビューに対する直接更新はできず、元テーブル更新時は非同期で連携されるという点には注意が必要です。
3. リレーションは非正規化 or 疑似結合を検討する
KVSは基本的にキーアクセスを前提としているため、単一テーブルに対するデータアクセスとなります。
つまりRDBで当たり前に行っていたテーブル結合自体、そもそもの思想から反しておりサポートされていません。
といっても、結合でリレーションを表現できないというのはアプリケーションを作るうえで頭を悩ませる要因になります。
この問題に対する解決案はNoSQLらしく諦めて非正規化してデータを冗長に持つというのが手っ取り早く性能も担保できます。
が、実際には非正規化でデータを持ちきるには厳しいケースも勿論存在します。
NoSQLの思想からは反しますがケースによっては下記のように疑似的に結合を表現する手段を取ることも選択肢にあります。
例えば下記のようにListもしくはMapの配列型でリレーションを表現する方法があります。
authorからarticleのrelationsをListで取得してその要素数分ネステッドループ的にキーアクセスして値を取得することで
疑似的な結合を表現することができます。
SELECT * FROM author;
id | author | relations
----+---------+-----------------------
01 | Iwasaki | ['aaa', 'bbb', 'ccc']
SELECT * FROM article ;
id | body | title
-----+----------+--------------------------------------------------
aaa | hogehoge | SQLonHadoop(ApachDrill)を導入する際のポイント
bbb | hugahuga | Tableau × R で時系列分析をやってみる
ccc | hugehuge | CassandraからKVSのデータモデルについて考えてみる
1キーアクセスはミリ秒単位のアクセスなので紐づく要素数が10~20程度であればアンチパターンですが
現実的なスピードでレスポンスを返せるのでデータモデル設計時の1つの選択肢になることがあります。
勿論、キーアクセスがセカンダリインデックス経由だったり、要素数が千や万を超すようなアクセスには利用するべきではありません。
基本は非正規化路線で検討し、どうしてもリレーションを表現したいときだけ疑似結合を利用するというのが考え方になると思います。
そもそも概念データモデル時点で紐づくエンティティが多い場合はNoSQLでなくRDBを採用した方が幸せになれる可能性もあります。
4. ロックはなるべく取得しないように設計する
RDBでは必須機能のトランザクションですが、NoSQLではサポートされていないことが多いです。
その理由はやはり、そもそもNoSQL自体テーブルを結合するという思想を排除しているからに尽きます。
Cassandraでは単一レコードに対してのみ軽量トランザクションという機能を提供しています。
この軽量トランザクションを利用することでレコードの挿入もしくは更新時に最新の値をチェックしてから処理を実行できます。
UPDATE test_table SET body = '軽量トランザクションを利用' WHERE id = '01' IF keyword['name'] = 'Iwasaki';
[applied]
-----------
True
SELECT * FROM test_table WHERE id = '01';
id | body | keyword | tag
----+----------------------------+----------------------------------+-----------------------------------------------------------
01 | 軽量トランザクションを利用 | {'age': '26', 'name': 'Iwasaki'} | ['Future Architect', 'NoSQL', 'AdventCalendar', 'append']
ロックフラグなどの制御項目を持たせておけば軽量トランザクションを利用して楽観ロック的な更新が可能になります。
ロックテーブルに切り出し、ロックテーブルを見てから更新するように作りこめば悲観ロック的な実装も可能になります。
しかし、軽量トランザクション利用時には最新の結果を読み取ってから更新を行うため、書き込みの前にリードが発生するので
操作のレイテンシーが通常の更新に比べて4倍近くかかると言われているので使用は最小限に抑えることが大切です。
Cassandraでは読み込み及び書き込み時の整合性レベルをクエリ毎に変更できるのでQuorum(過半数)に設定することで
結果整合性を担保することが可能になるため、ロックを取得せず常に後勝ちとすることでシンプルなつくりになります。
Cassandraに限らずNoSQLでトランザクション管理をサポートしていると謳っている製品もありますが、性能問題を引く可能性は
十分ありうるので念入りにPoCをしてから選定することを推奨します。
まとめ
まとまりなくつらつらと思いの丈を書いてしまいましたがNoSQLの採用を考えている
もしくはデータモデルを検討している方々に本記事が役に立てば幸いです。
追記
後日、社内の技術ブログにcassandraネタを投稿しました。
本稿よりも詳しく書いているのでご一読頂けると幸いです。
https://future-architect.github.io/articles/20190718/
更に新規記事追加しました。
https://future-architect.github.io/articles/20210412a/