はじめに
フューチャーAdventCalender2 2019の22日目です。
ちなみにアドベントカレンダー1の記事はこちらから。
今年で入社5年目になりますが、毎年この時期になると自分がこの1年どんな業務・技術と向き合ってきたのかを
考え直す良いきっかけでもありつつ、師走の名にふさわしいプロジェクトばかりなので貴重な休日を使わないと
記事を書くことができないのでなかなかツライです。。。と、最初に記事のクオリティには保険をかけておく。
概要
2019年はKVSなどNoSQLデータベースを用いたアプリケーションの設計・開発をリードしてきました。
思い返すとCassandraの記事ばかり書いていたので今回はgRPCにフォーカスして記事を書きたいなと思います。
いままでインフラ・ミドルウェア設計・構築が中心でAPI設計・開発を真面目に行ったことがなく苦戦してきましたが、gRPCの設計・開発を通じて得た知見を少しでも皆様に還元できれば幸いです。
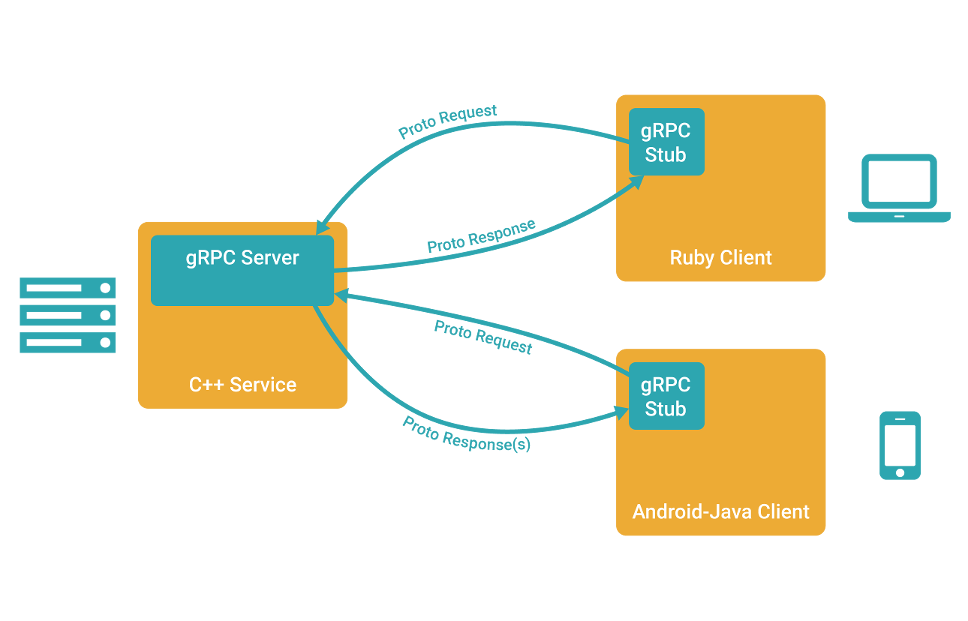
gRPCとは
gRPCはGoogleが開発したオープンソースでProtocolBuffersを利用してデータをシリアライズし、
RESTよりも高速な通信を実現できるという点が特徴です。
またgRPCではprotoファイルと呼ばれる定義ファイルにIDL(インターフェース定義言語)でAPI仕様を
定義することでクライアント/サーバーに必要なソースの雛形をJava,C++,Python,Goなど異なる言語間であっても
それぞれに合わせたIFをprotoファイルから自動で生成することができるというのも特徴の一つです。
protoファイルはproto3の言語仕様に沿って定義を行います。
gRPCを採用するポイント
APIとしてgRPCを採用する上でよく比較されるのはRESTです。
今回私が設計・開発を担当したAPIサーバーはバックエンドのデータストア層へのCRUDを行うためのAPIであり、
KVSなどから取得したデータをprotoによって構造的に定義しRESTよりも高速に通信できるという点が
データストアAPIとして採用するメリットが一番大きかったです。
また、マイクロサービスアーキテクチャを実現する上でAPI仕様を合わせるというのは非常にコストが
かかる作業でありgRPCならインターフェースを厳格なルールで保つことができるというのも
自由な設計ができるRESTと比べて採用するメリットは高いと言えます。
しかし、RESTと比べて絶対的な優位性は無いので上記のメリットが享受できるかという観点で
case-by-caseで選択するのが良いと考えます。
gRPC設計・開発の勘所
1. protoファイルの管理方法
1-1. ネストの深い構造的なデータはprotoファイルを分割して定義する
データストアにCassandraを採用していたため、扱うデータはフラットなデータ階層ではなく、
ネストの深い構造データでした。そのため、1つのprotoファイルにネストの深い構造データを定義することも
できますが、可読性・保守性が悪かったため、下記のようにprotoファイルを分割して定義を行いました。
1つのファイルで定義する例
階層構造を1ファイルで定義することも可能ですが、1つのprotoの中に複数階層モデルを表現したり
2層、3層とネストが深くなってくると可読性・保守性共に悪くなってきます。
syntax = "proto3";
option java_package = "jp.co.sample.datastore.common.model";
package common;
message ParentModel {
string parentId = 1;
string parentNm = 2;
ChildModel child = 3; // ファイル内に定義したChildModelを型に指定
}
message ChildModel {
string childId = 1;
string childNm = 2;
}
複数ファイルで定義する例
ChildModelとParentModelを別ファイルで分割して定義することができるので
今回は構造単位でファイルを分けて管理しました。後続でも話しますが、Cassandraはユーザー定義型
(UDTとよばれる任意の構造体をDDLで定義することができるのでUDT単位でprotoのモデルも分割しました。
syntax = "proto3";
option java_package = "jp.co.sample.datastore.common.model";
package common;
message ChildModel {
string childId = 1;
string childNm = 2;
}
syntax = "proto3";
option java_multiple_files = true;
option java_package = "jp.co.sample.datastore.common.model";
package common;
import "common/child_model.proto"; // ChildModelを定義したprotoを指定
message ParentModel {
string parentId = 1;
string parentNm = 2;
ChildModel child = 3;
}
1-2. protoファイルはDDLと合わせて管理する
gRPCではprotoファイルにAPI仕様を定義して管理するため、基本的にはこのprotoファイルをGitなどで
バージョン管理することで常にAPI仕様を最新に保つことができると言えます。
しかしデータストアAPIとして利用するにあたり、アプリケーションからのリクエスト・レスポンス
パラメータの定義はprotoを管理すれば良かったのですが、Cassandraから取得したデータをprotoで
構造的に扱うためには、Cassandra側のテーブル定義と整合性を保つ必要がありました。
アプリケーション開発の中でDDLの変更や更新が発生するのは日常茶飯事です。
そのため、CassandraのDDLは社内標準フォーマットのテーブル定義書ファイルで管理していたので、
その定義書をインプットとしてprotoファイルも自動生成することでテーブル定義に変更がかかっても
両者の整合性が担保できるようになりました。
開発規模が大きくなるにつれてprotoとDDLの差異を吸収するのが辛くなるので
はじめのうちから仕組みを整えるのがベターです。
1-3. IFモジュール管理方法
protoファイルからprotoファイルからクライアント/サーバーに必要なインターフェースの
ソースを言語ごとに自動生成することができます。
しかし、毎回protoファイルから自動生成してソースをコミットするのは非常にめんどくさいし、
開発者数が増えると煩雑な作業になるため、最新のprotoファイルからインターフェースのモジュールを生成して
nexusでリポジトリに連携しパッケージ管理を行いました。
今回はクライアント/サーバーともにJavaによる開発だったのでgradle経由で
nexusからパッケージ取得するよう定義しました。
2. カスタムオプションを利用した共通処理の実装
API設計において、リクエストパラメータに対してバリデーション設計を行う必要があります。
gRPCではprotoファイルにデータ定義する際に必ずstringやintなど型を指定する必要があります。
mapやsetなどのコレクション型も定義して扱うことができます。
そのため、クライアントからのリクエストパラメータに対して型チェックを行う必要はありませんが、
そのほかの必須チェックや桁数チェックなどのバリデーションに対しては考慮が必要になります。
protoファイルではファイル、もしくはフィールドに対してCustom Optionsを利用して定義することで、
gRPCモデルからカスタムオプションを取り出して任意のハンドリングを実装することができます。
2-1. カスタムオプション定義例
syntax = "proto3";
option java_multiple_files = true;
option java_package = "jp.co.sample.datastore.option.model";
package option;
import "google/protobuf/descriptor.proto";
extend google.protobuf.FieldOptions {
bool required = 50000; // 必須チェックオプション
}
extend google.protobuf.FieldOptions {
int32 strlen = 50001; // 桁数チェックオプション
}
上記で用意したカスタムオプションを任意のフィールドに定義します。
syntax = "proto3";
option java_multiple_files = true;
option java_package = "jp.co.sample.datastore.common.model";
package common;
import "option/custom_option.proto"; // カスタムオプションを定義したprotoをimport
message User {
string user_id = 1[(required)=true,(strlen)=8]; // 複数オプション定義も可能
string user_name = 2[(required)=true];
}
2-2. カスタムオプションの取得方法(Java)
上記で定義したmessageモデルのUserからフィールドに設定したカスタムオプションを取得するサンプルです。
"User.getDescriptorForType().getFields()"でUserモデルのメタ情報であるFieldDescriptorが
取得でき、そのFieldDescriptorを取り回すことでオプション情報を取得することができます。
for(Descriptors.FieldDescriptor fds: User.getDescriptorForType().getFields()){
System.out.println(fds.getName())
for(Map.Entry<Descriptors.FieldDescriptor,Object> entry : fds.getOptions.getAllFields().entrySet()){
System.out.println("option:" + entry.getKey().getName() + "=" entry.getValue());
}
}
/* 出力結果 */
// user_id
// option:required=true
// option:strlen=8
// user_nm
// option:required=true
2-3. バリデーション実装例
MessageのFieldDescriptorに対して"hasExtension()"で存在チェックをかけることもできるので
gRPCのモデルからフィールドごとに任意のオプションのバリデーション処理を実装する、ということが
可能になります。また、gRPCのモデルはMessage型という共通のインターフェースクラスを継承しており
Message型にキャストしてFieldDescriptorを取り回すことでモデルに依存せず汎用的な処理を実装できます。
if(fds.getOptions().hasExtension(CustomOption.required)){
// hasExtensionでフィールドメタ情報から"required"オプションが存在するかチェック
Object value = fds.getOptions().getExtension(CustomOption.required); // getExtensionでオプションの中身を取り出す
// バリデーション処理実装
}
3. gRPCのモデルで空文字,0を明示的に取り扱えるようにする
protoファイル内でstringやintと定義して抽出されるモデルインターフェースに値がセットされていない
フィールドの値を取り出すとデフォルト値としてstirngなら空文字、int32/int64であれば0が取得されます。
例えばgRPCモデルをクライアントから受け取って、フィールドにセットされた値を基にデータストアに対して
更新をかける際にクライアントが意図して空文字や0を詰めて初期化したいのか、gRPCモデルのデフォルト値で
セットしていないだけ(更新不要)なのかをサーバー側で判定して処理することができないという問題があります。
その問題を解決するために、gRPCにはwrapperクラスが用意されておりそれらを定義することで判定可能になります。
3-1. wrapperクラスを用いたprotoファイル定義例
message Test{
string value1 = 1; // 空文字をセットしたのかデフォルト値なのか判定できない
int32 value2 = 2; // 0をセットしたのかデフォルト値なのか判定できない
StringValue value3 = 3; // 空文字をセットしたのかデフォルト値なのか判定できる
Int32Value value4 = 4; // 0をセットしたのかデフォルト値なのか判定できる
}
3-2. 値の存在チェック実装例
Test.Builder testBuilder = Test.newBuilder();
// 明示的に空文字,0をセットする
testBuilder
.setValue1("")
.setValue2(0)
.setValue3(StringValue.newBuilder().setValue(""))
.setValue4(Int32Value.newBuilder().setValue(0))
;
for(Descriptors.FieldDescriptor fds : testBuilder.build().getDescriptorForType().getFields()) {
if (testBuilder.hasField(fds)) {
System.out.println(fds.getName() + " has field");
} else {
System.out.println(fds.getName() + " has not field");
}
}
/*出力例*/
// value1 has not field
// value2 has not field
// value3 has field
// value4 has field
4. gRPCモデルからクエリを動的に生成する
データストアとしてCassandraを利用していたため、Cassandraのテーブルに対して
CRUD操作を行うためにはCQLと呼ばれる独自のクエリを実装する必要がありました。
CassandraのCQLは基本的にSQLをベースにしているため、比較的直感的に実装はできますが、
同時更新制御を行うためのCASを意識したクエリや構造階層の深い項目(frozen UDT)に対する
Update文やMap、Set要素の追加削除などSQLでは表現できないクエリを開発者が意識して
実装する必要があったためgRPCのモデルクラスを引数に渡せばデータストアにCRUDできるように
処理を隠蔽化しました。(KVS版OR/マッパー的な)
Modelクラスから動的にクエリを生成するポイントはカスタムオプションの例でも記載しましたが
Message型を利用してFieldDescriptorを取り回すことで汎用的に処理を実装できるという点です。
gRPCモデルに対して共通処理を設計する際には、Message型を利用することを意識しましょう。
4.1 cqlのSELECT文実装例
public BuiltStatement select(Message message) {
BuiltStatement select;
try {
// テーブル名セット
String table = message.getDescriptorForType().getOptions().getExtension(CustomOption.entityOptions)
.getTableName();
// CQL生成
Select.Selection selection = QueryBuilder.select();
Map<String, Object> partitionKeyMap = new HashMap<>();
for (Descriptors.FieldDescriptor fds : message.getDescriptorForType().getFields()) {
// SELECT句作成
if (fds.getName().equals("select_enum")) {
if (message.getRepeatedFieldCount(fds) > 0) {
IntStream.range(0, message.getRepeatedFieldCount(fds)).forEach(
i -> selection.column(message.getRepeatedField(fds, i).toString()));
} else {
selection.all();
}
}
// パーティションキー抽出
if (fds.getOptions().getExtension(CustomOption.attributeOptions).getPartitionKey() > 0
|| fds.getOptions().getExtension(CustomOption.attributeOptions).getClusteringKey() > 0) {
partitionKeyMap.put(fds.getName(), message.getField(fds));
}
}
// FROM句生成
select = selection.json().from(getTableMetadata(table));
// WHERE句作成
for (Map.Entry<String, Object> entry : partitionKeyMap.entrySet()) {
Object value = entry.getValue();
if (value instanceof String) {
((Select) select).where(eq(entry.getKey(), value));
} else if
... 型判別処理省略
} else {
logger.debug("パーティションの型が不正です");
throw new RuntimeException("unsupported type");
}
}
return select;
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
Cassandraだけでなく、全文検索エンジンとしてElasticSearchも利用しており、
ElasticSearchに投げるクエリも上記のMessageクラスを利用してgRPCモデルから動的にクエリ生成を
してアプリ開発者が直接クエリを実装せずともデータストアにCRUDできるように設計しました。
5. gRPCモデルを利用した便利な処理のTips
上記でも多少紹介しましたが、gRPCモデルを取扱う際に覚えておくと役立つTIPSをいくつか紹介します。
なお今回はgRPC-Javaで実装しているため、Java以外の言語で実装する際は参考程度に留めてください。
(ちょっと時間足りなかったのでTipsは後日足します。。。)
5-1. gRPCモデルからJsonフォーマットで出力
gRPCモデルからJsonフォーマットを出力する。
preservingProtoFieldNamesをつけると、protoに定義したフィールド名で出力される。
preservingProtoFieldNamesをつけなければCamelケースで出力されるので用途によって使い分ける。
JsonFormat.printer().preservingProtoFieldNames().print(gRPCモデル) // proto定義に沿ったフィールド名で出力
JsonFormat.printer().print(gRPCモデル) // camelケースで出力
5-2. gRPCモデルの型判定
for (Descriptors.FieldDescriptor fds : gRPCモデル.getDescriptorForType().getFields()) {
if (fds.isMapField()) {
// フィールドがMap型か判定
} else if (fds).isRepeated()) {
// フィールドがSet型か判定
} else {
// コレクション以外の型
}
}
5-3.Messageクラスからフィールド名を指定して値を取得する
String val = (String) messageModel.getField(messageModel.getDescriptorForType().findFieldByName("フィールド名"));
5-4. gRPCモデル間マージ
あるモデルから別のモデルに値をマージする例。
.ignoringUnknownFields()を利用することで、マージ先に対象のフィールドがなくても無視される。
JsonFormat.parser().ignoringUnknownFields().merge(
JsonFormat.printer().preservingProtoFieldNames().print(merge元のモデル),merge先のモデル);