この記事は インフォマティカ Advent Calendar 2022 Day 20 の記事として書かれています。
はじめに
Informaticaには、Intelligent Data Management Cloud(IDMC)というソリューションがあり、その中にデータ品質を管理するためのCloud Data Qualityというサービスがあります。また、CLAIREというメタデータドリブンなAIエンジンが組み込まれており、データ品質管理を効率よくかつ漏れなく行えるようになっています。
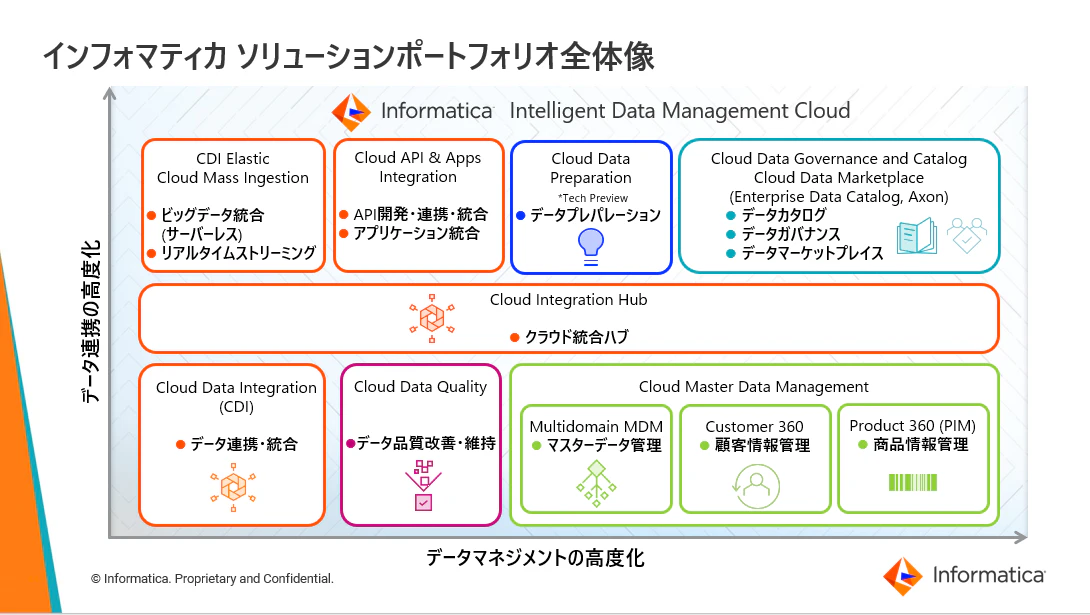
今回は、CLAIREがどのようにデータ品質管理に寄与するかご説明したいと思いますが、最初にデータ品質管理について簡単に説明させていただきます。
データの品質課題とは?
データ品質は、完全性、適合性、関連性、一貫性、重複度などさまざまな観点で評価し、正確に課題を把握する必要があります。
外部データなどの信頼できるソースであっても、「株式会社」と「㈱」や電話番号等の表記フォーマットが異なる可能性があるため、マッチング(名寄せ)の精度を高めるためにも、事前にプロファイリングし課題を把握、各課題に応じたクレンジングをすることが重要です。
データ品質を高めるためのライフサイクル
データの品質を高めるためには、いろいろなデータの課題を苦労して一度だけ修正すれば良いというものではありません。以下のようなライフサイクルを回して、日々品質の確保と向上に取り組んでいくことが必要となります。
- プロファイリング
- 品質改善の定義
- 品質改善の実行
- モニタリング
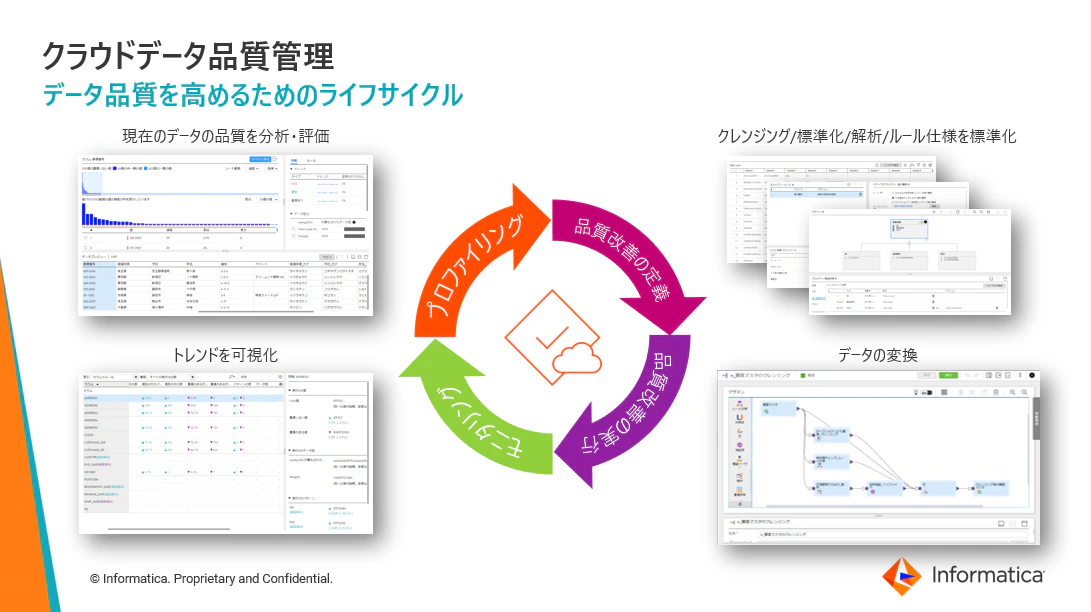
特に重要なものは最初のステップとなるプロファイリングです。このステップにおいて、データ品質を見える化して品質改善のアクションを明確化します。そのため、このステップでデータ品質の課題を正しく抽出できていないと、データの品質改善が行われないこととなります。
Cloud Data Qualityでは、このプロファイリング実行時にAIエンジンであるCLAIREがデータ品質について分析を行い、課題がある場合にはその内容をインサイトとして表示してくれます。具体的な例は後ほどお見せします。
プロファイリングの実行
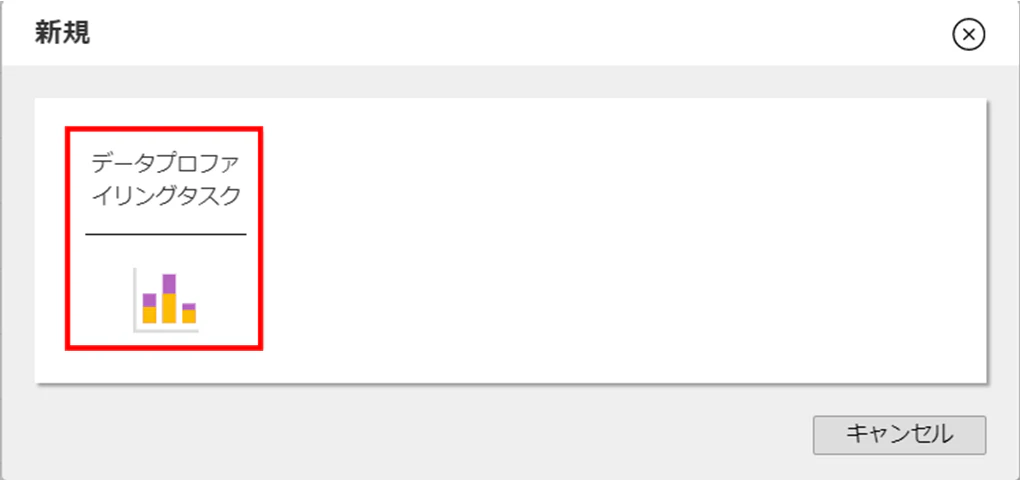
それでは、実際にプロファイリングしてみます。データプロファイリングの画面で、左上の[新規]をクリックして、[データプロファイリングタスク]をクリックします。

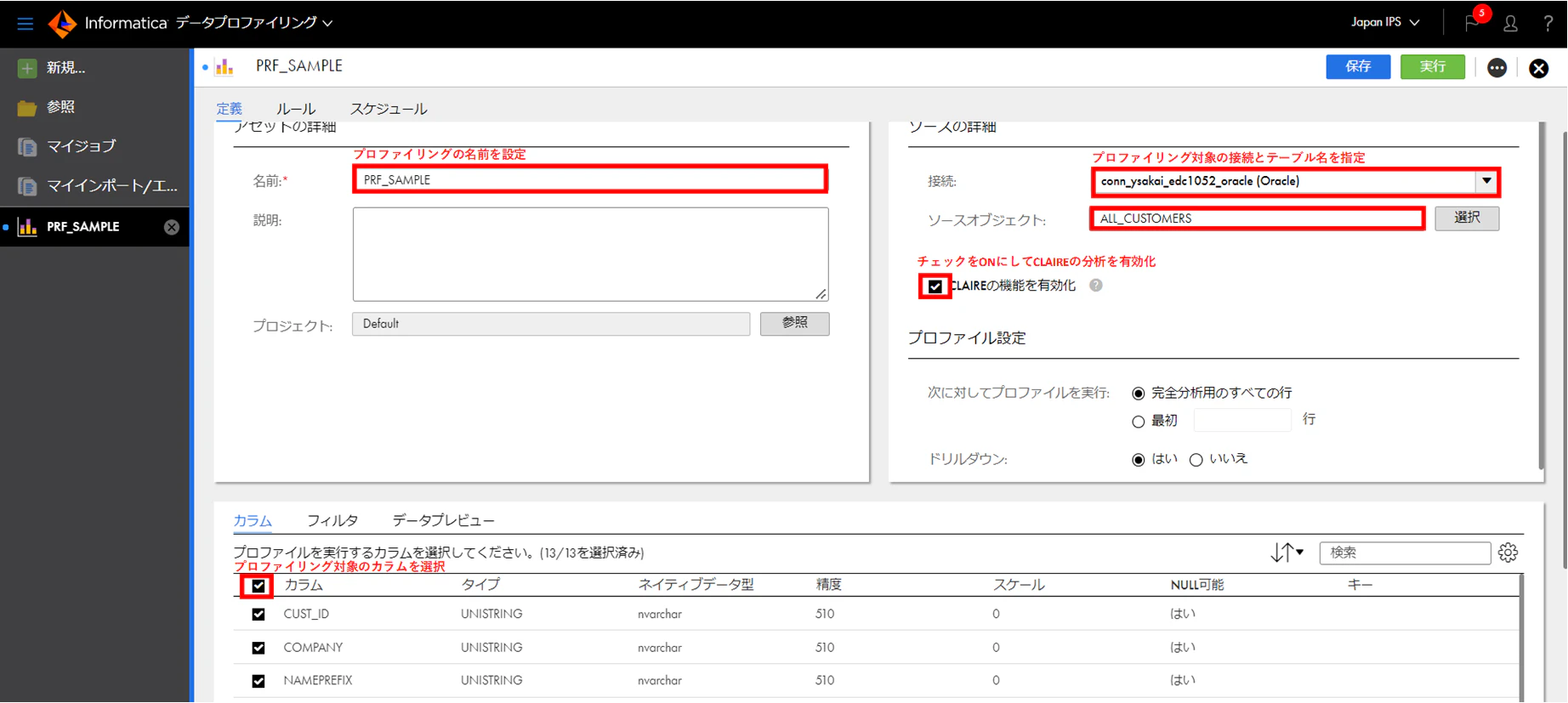
次に、プロファイリングの各設定を以下のように行います。
画面右上の[実行]をクリックして、プロファイリングが終わった時点のジョブ結果画面は以下のとおりです。
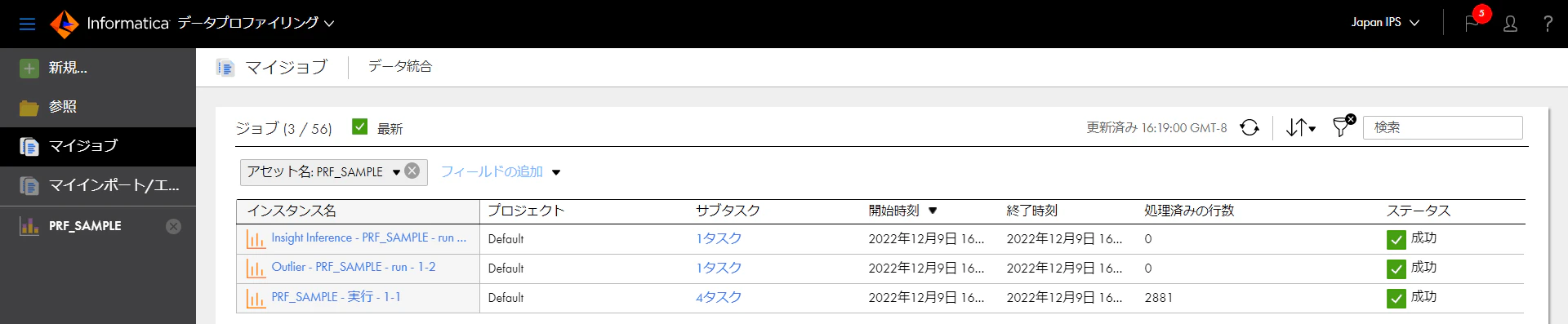
それでは、次に実際のプロファイリング結果の画面を見てみましょう。
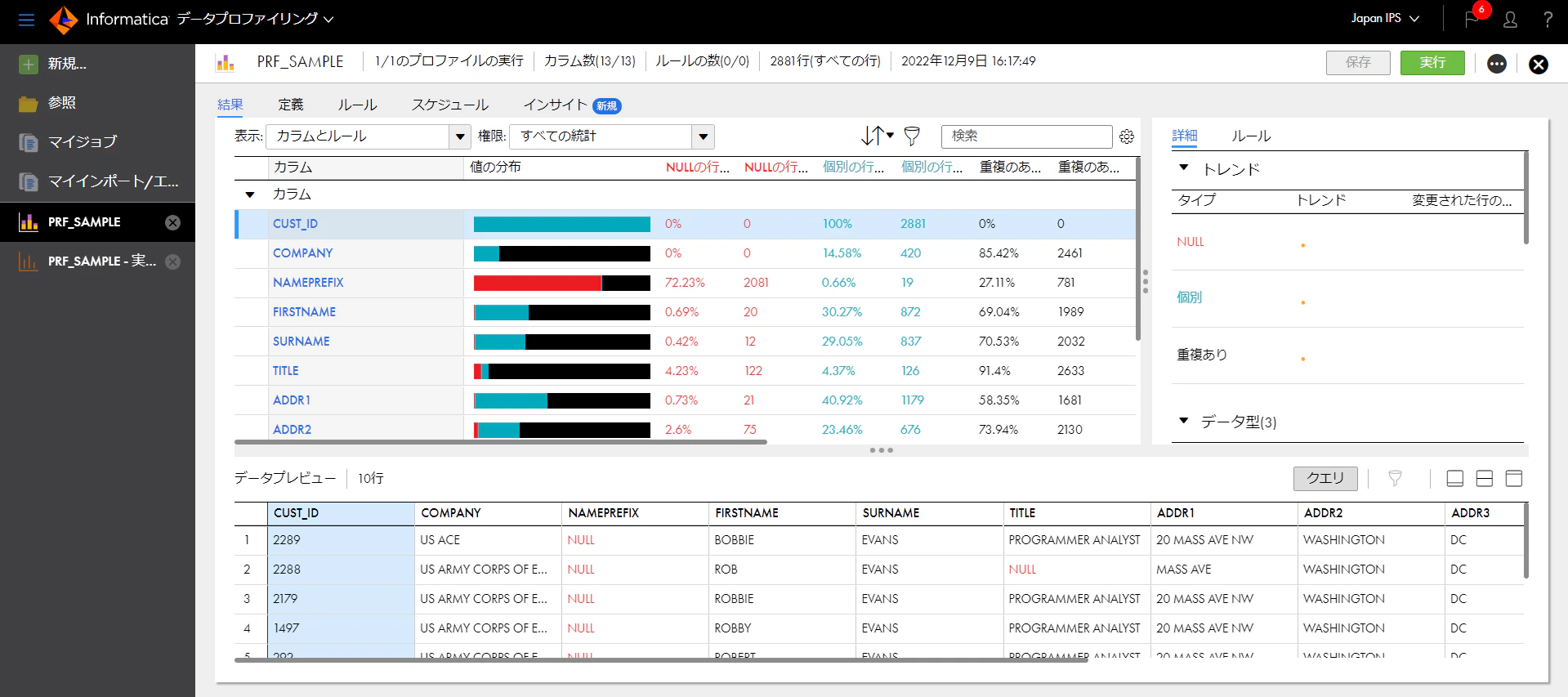
左上の赤、緑、黒のグラフは、それぞれNULL値、一意の値、重複した値の割合を示しています。また、下の画面は実際のデータとなります。
次に、個別のカラムを見ていきましょう。最初に一意の値しかないCUST_ID列のリンクをクリックします。
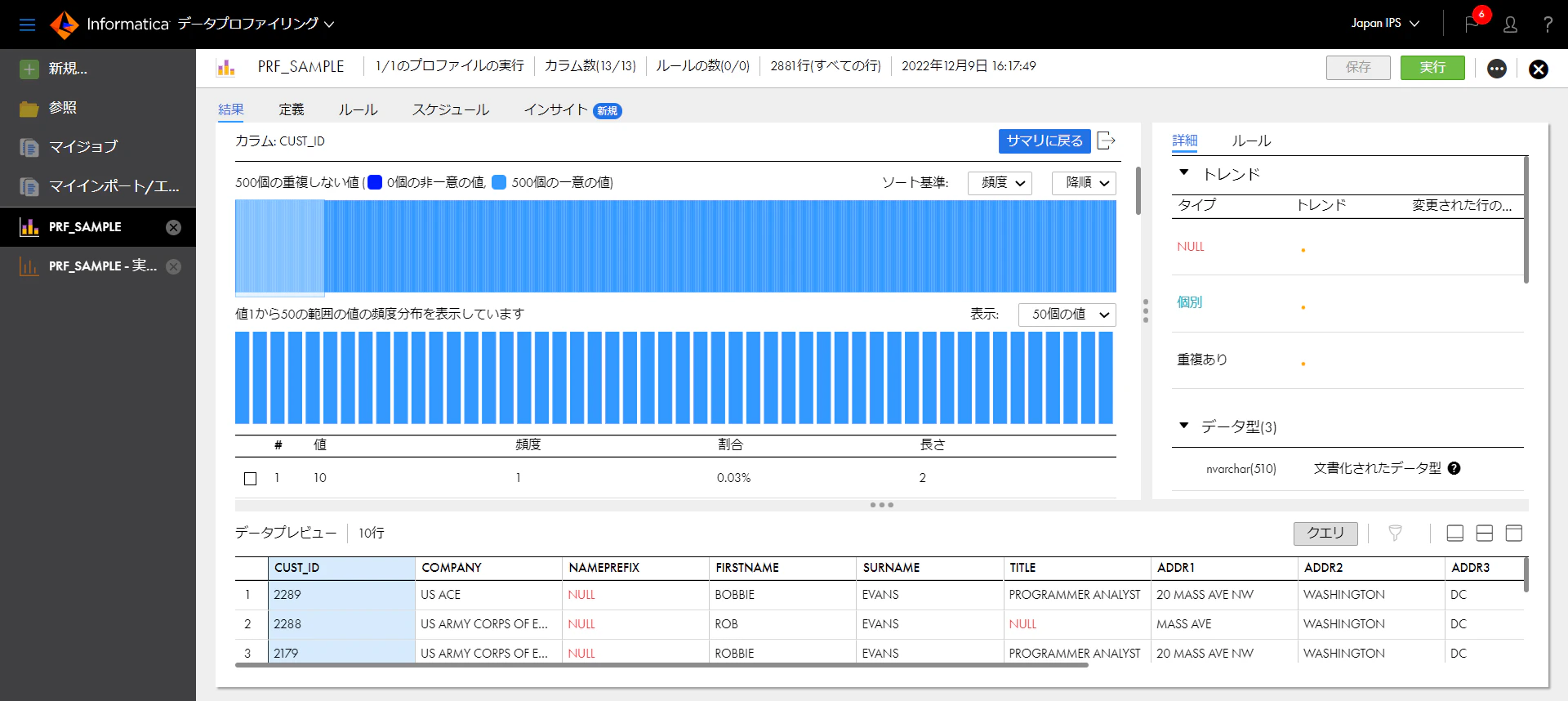
一意の値のみ含むため、それぞれのCUST_IDの値は1つずつのため、同じ高さの棒グラフが並んだ形となっています。
次に、重複した値を含む列、EMAILを見てみます。
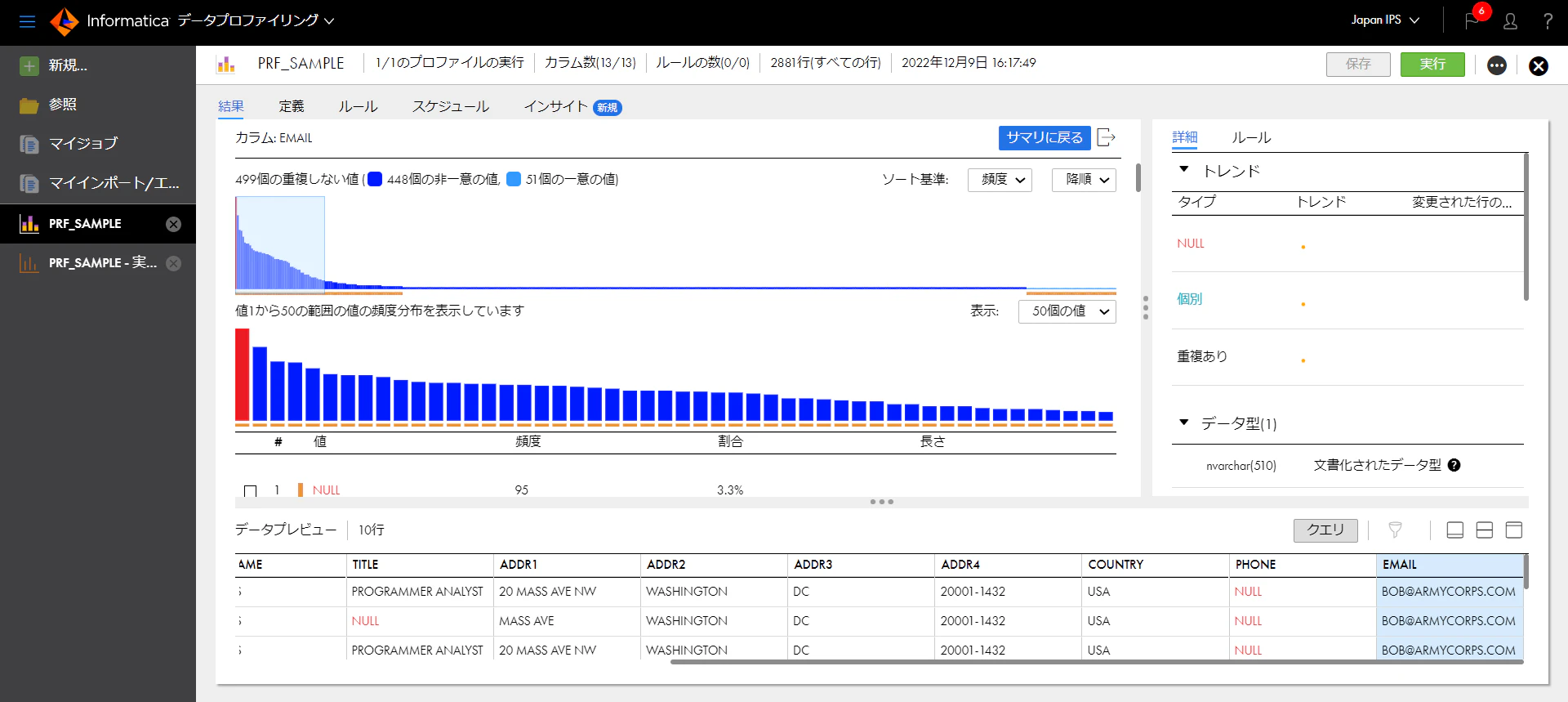
列に含まれるデータの個数順に並べると、このようななだらかな傾斜となることが分かります。ただ、一番多いのが赤い色になっています。これはNULL値を表しています。そのため、多くのEMAILがNULLになっているということで、データ品質の課題があることがわかりました。
ところで、画面には以下のようにインサイトタブのところに"新規"と表示されていることにお気づきになられたでしょうか。これはCLAIREの分析により課題が見つかったことを示しています。それでは、具体的に見てみましょう。
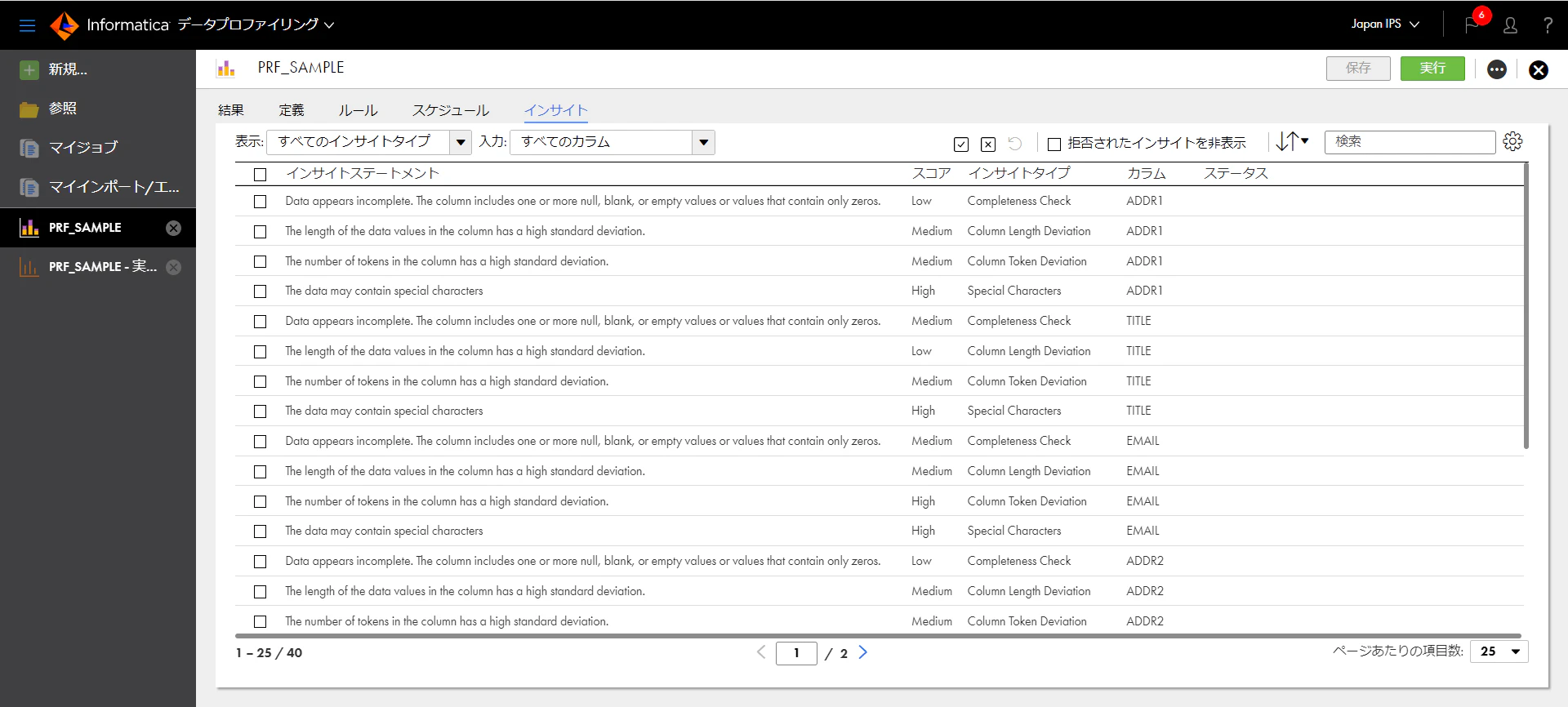
このように多くの課題があることが判明しましたが、まずはEMAIL列に絞ってみてみましょう。

EMAIL列で4パターンの課題が検出されていますが、それぞれにインサイトタイプが異なるようです。それぞれのインサイトタイプの説明は以下のとおりです。
| インサイトタイプ | 説明 |
|---|---|
| Completeness Check | データが不完全のようです。列には、1 つ以上の NULL 値、空白値、または 0 のみを含む値が含まれています。 |
| Column Length Deviation | 列のデータ値の長さには大きなばらつきがあります。 |
| Column Token Deviation | 列に含まれるトークンの数に偏りがあります。 |
| Special Characters | 上位80%のパターンに含まれない特殊文字を含む列があります。 |
これらのインサイトを承認すると、次回以降プロファイリング実施時にそのロジックを用いたチェックが行われるようになります。
それでは、実際に承認してプロファイリングを実行してみましょう。以下のように4つのインサイトのチェックボックスをONにして、承認を行います。
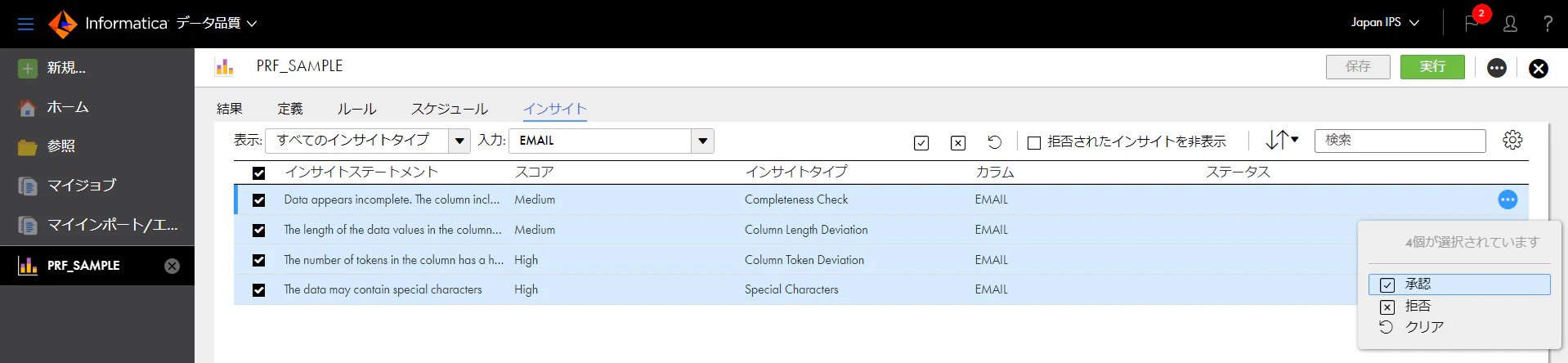
承認済みとなったら、再度[実行]をクリックします。そして、結果画面で[ルール]タブをクリックすると、以下のように4つのルール仕様が表示されます。
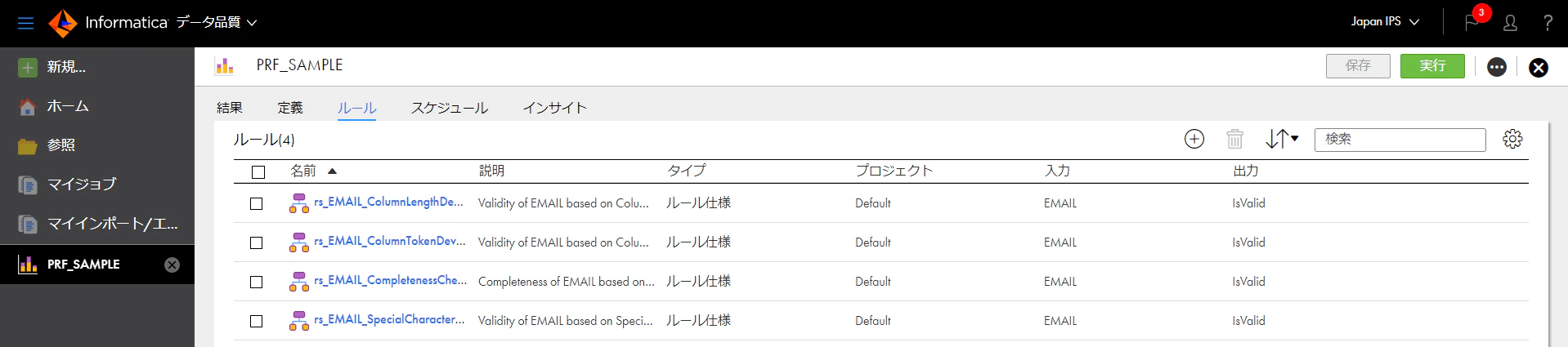
実際にこのルールをもとに判断された結果を見てみます。結果の画面でルールをベースとして表示します。

2番めのCompleteness checkの結果を見てみると、右の方にValidが96.7%、Invalidが3.3%であることがわかります。
次に、Invalidのデータを見てみます。

上記のように、EMAILはInvalidの列は95個となります。次に、EMAILの列の値を見て、95個の内訳を確認します。
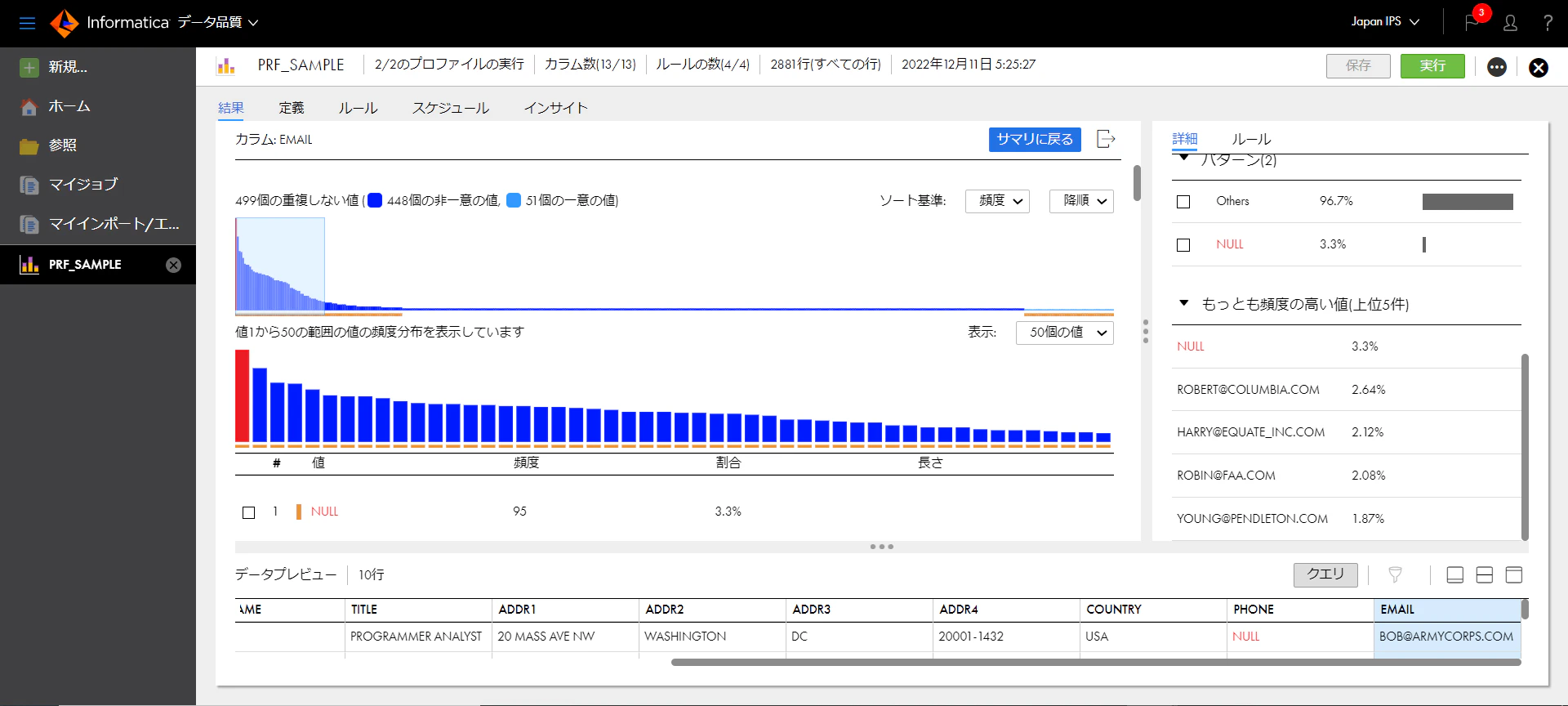
上記のように、NULLが一番頻度が多く、95個ということになります。
すなわち、InvalidのものはすべてNULLであったということがわかります。
このように、AIを用いることでどの列の値が不正になっているか、簡単に検出できることがわかりました。
人が時間をかけてデータを見て、課題を検出することも不可能ではありませんが、このようにAIを用いれば簡単に検出することが可能となります。
さいごに
今回はCloud Data QualityにおけるCLAIREの利用方法を簡単にご紹介しましたが、いかがでしたでしょうか。クラウドサービスのため、インストールも不要で簡単にトライアル利用が可能です。興味を持たれた方は、以下のリンクから登録をお願いします。
マニュアルは以下から参照可能です。