連続投稿って難しい。。。
みなさま、お久しぶりです。夏の初めに記事を投稿してから(前回は7月22日)、気付くとはや2ヶ月が経過しようとしておりました、汗汗。改めて、文章を書き続ける難しさ、やると決めたことを気長に続けることの難しさを感じております。自分のことで言うと、長く続けられているものとしては「ヨガ」があります。「ヨガ」はもう8年から9年くらいずっと続けていますが、もうヨガスタジオに行かないと気持ち悪いくらいのレベルなので、このブログもそれらくらいになるよう、今年の後半は頑張る所存です(こんな感じで、意気込みはいつもいい自分。。。)ということで、本題に戻りましょう♪
Dynatraceの「AIOps」とは?
Dynatraceは Gartner の Magic Quadrant で Observability platform に位置づけられ、Datadog、NewRelic、Splunkなどと並ぶ大手企業一つです。会社毎に特徴がいろいろありますが、Dynatraceの一番の特徴は何でしょうか?皆さんは、何を思い浮かべますか?私は、「AIOps」だと思っています。この「AIOps」を支える一つの大きな機能として、Davis AIと呼ばれるAIエンジンがあり、それは常時バックグラウンドで動き続け、お客様が監視されているシステム内外で起こる、アノマリーを自動的に検知し、その原因も探ってくれる強者です。読者の皆さんも、一度はDynatraceのデモやプレゼンで下記のようなプロブレム画面を見たことがあると思います。この場合、フロントエンドアプリケーション(www.easytravel.com)のユーザアクションが遅くなっているという「プロブレム」に対して、その原因はバックエンドのDatabase(DB1)へのQueryが遅くなったからではないかということを、Davis AIが提起してくれています。この機能を活用できることによって、トラブル対応時の初動が早くなり、結果MTTR(Mean Time To Resolution、問題解決までの時間)を大幅に短縮することが可能となります。

じゃ、あるホストのCPU使用率をわざと上げると、どうなるのか?
このような話を聞いた時、色々試したくなった人はエンジニア魂に溢れる方ではないでしょうか?そんな私も「そうだ自分のVMで同じようなことを試して見よう」と現に思いましした。ということで、早速やってみたいと思います。
"stress" コマンドで Linux ホストのCPUを100%に貼り付けてみる
まずは自分のLaptopでVMを立ち上げ、OneAgentをインストールしてみるとこからはじめます。OneAgentのインストールは、DynatraceのHelpをぜひご覧下さい。インストーラを実行するだけで、フルスタックのモニタリングがすぐに開始できます(必要なライセンスを所有していることが前提です)。インストールが出来たら、Linux の service コマンドで OneAgent が正しく動作していることを確認しておきましょう。「Active」項目がactive (running)になっていれば、OKです。
ubuntu@qiita:~$ service oneagent status
● oneagent.service - Dynatrace OneAgent
Loaded: loaded (/etc/systemd/system/oneagent.service; enabled; preset: enabled)
Active: active (running) since Mon 2024-09-16 20:32:09 JST; 2min 9s ago
Process: 16441 ExecStart=/opt/dynatrace/oneagent/agent/initscripts/oneagent start (code=exited, status=0/SUCCESS)
Main PID: 16527 (oneagentwatchdo)
Tasks: 52 (limit: 4657)
Memory: 195.8M (peak: 201.1M)
CPU: 5.848s
CGroup: /system.slice/oneagent.service
├─16527 /opt/dynatrace/oneagent/agent/lib64/oneagentwatchdog -bg -config=/opt/dynatrace/oneagent/agent/conf/watchdog.conf
├─16536 oneagentos -Dcom.compuware.apm.WatchDogTimeout=900 -watchdog.restart_file_location=/var/lib/dynatrace/oneagent/agent/watchdog/>
├─16635 /opt/dynatrace/oneagent/agent/lib64/oneagenteventstracer --logdir /var/log/dynatrace/oneagent/os --cputimeoffset 0xd8
├─16648 oneagentnetwork -Dcom.compuware.apm.WatchDogTimeout=900 -Dcom.compuware.apm.WatchDogPipe=/var/lib/dynatrace/oneagent/agent/wat>
├─16682 oneagentloganalytics -Dcom.compuware.apm.WatchDogTimeout=900 -Dcom.compuware.apm.WatchDogPort=50000
├─16718 /opt/dynatrace/oneagent/agent/lib64/oneagentebpfdiscovery --log-dir /var/log/dynatrace/oneagent/os/ --log-no-stdout --log-leve>
└─16741 oneagentplugin -Dcom.compuware.apm.WatchDogTimeout=900 -Dcom.compuware.apm.WatchDogPort=50001
Sep 16 20:32:09 qiita systemd[1]: Starting oneagent.service - Dynatrace OneAgent...
Sep 16 20:32:09 qiita oneagent[16530]: 20:32:09 Dynatrace OneAgent service started.
Sep 16 20:32:09 qiita systemd[1]: Started oneagent.service - Dynatrace OneAgent.
ubuntu@qiita:~$
次に、CPUに負荷を与えるため、stress コマンドを sudo apt -y install stress でインストールします。
コマンドラインから引数なく実行し、下記のようにHelpが表示されればOKです。
ubuntu@qiita:~$ stress
`stress' imposes certain types of compute stress on your system
Usage: stress [OPTION [ARG]] ...
-?, --help show this help statement
--version show version statement
-v, --verbose be verbose
-q, --quiet be quiet
-n, --dry-run show what would have been done
-t, --timeout N timeout after N seconds
--backoff N wait factor of N microseconds before work starts
-c, --cpu N spawn N workers spinning on sqrt()
-i, --io N spawn N workers spinning on sync()
-m, --vm N spawn N workers spinning on malloc()/free()
--vm-bytes B malloc B bytes per vm worker (default is 256MB)
--vm-stride B touch a byte every B bytes (default is 4096)
--vm-hang N sleep N secs before free (default none, 0 is inf)
--vm-keep redirty memory instead of freeing and reallocating
-d, --hdd N spawn N workers spinning on write()/unlink()
--hdd-bytes B write B bytes per hdd worker (default is 1GB)
Example: stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
Note: Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size).
ubuntu@qiita:~$
stressコマンドでホストに負荷を与えて、プロブレムを発生させてみる
先ほどインストールした stress コマンドを使って、CPUに負荷を与えてみます。すると、みるみるうちにユーザ空間のCPU使用率が上昇し、その後しばらくするとDynatraceで、プロブレムが検知されました。イベント名は「CPU Saturation」です。
ubuntu@qiita:~$ stress -c 8 -t 10m
stress: info: [16852] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd
- ホスト画面での表示

- プロブレム画面での表示

プロブレムは自動で検知されましたが、Root Cause(上記画像の右側部分)にはホストCPUが上昇した理由が、そのホストのCPU使用率の高騰が原因だったと提案されました。確かに、そうなんですが、こちらの期待値としては、ホストの上昇を引き起こしたのは、stressコマンドが原因だったと言って欲しいところです。ここからが、今回のブログの本題で Event の活用です。stress コマンドを実行したことをDynatraceにEventとして通知することで、「ホストCPUの高騰のトリガーが、stress コマンドの実行によるもの」だとDavis AIに連携してもらうようにします。
stressコマンドの実行結果をログに出力し、Dynatraceにイベントとして通知させてみる
実行したコマンドの結果をログに出力させ、そのログの実行結果を log event として抽出し、Dynatraceへ通知するように、少し設定を追加してみます。手順としては、以下の3つです。
- stress コマンドを sudo 経由で実行し、その実行ログを /var/log/auth.log に出力させる
- Dynatrace の設定で、/var/log/auth.log を読み込みように設定する
- Log processing ルールで、sudo の実行ログを parse して、イベントとしてDynatraceへ通知する
1. stress コマンドを sudo 経由で実行し、その実行ログを /var/log/auth.log に出力させる
Linuxの場合、デフォルトで sudo の実行ログは、/var/log/auth.log に出力させるため、特に設定は不要です。念のため、sudo stress コマンドで実行ログが当該パス上のファイルに出力されるか確認しておきましょう。先ほど、OneAgent をホストにインストールするときに sudo コマンドを使いましたが、そのログがきちんと記録されていましたね。ヨシヨシ。
2024-09-16T11:31:21.131624+00:00 qiita sudo: ubuntu : TTY=pts/0 ; PWD=/home/ubuntu ; USER=root ; COMMAND=/bin/sh Dynatrace-OneAgent-Linux-1.299.34.20240906-143258.sh --set-monitoring-mode=fullstack --set-app-log-content-access=true
2. Dynatrace の設定で、/var/log/auth.log を読み込みように設定する
デフォルトでは、Linux / ubuntu の場合、/var/log/syslog ファイルしか読み込まないので、/var/log/auth.log ファイルを読み込むよう、Dynatraceの設定を変更します。設定は、Settings > Log Monitoring > custom log sources で行います。対象のファイルを読み込むように、明示的にファイルパスを指定します。

設定変更後、ホスト画面の log sources を確認すると、ちゃんと読み込んでくれていました。ここまでは、OKですね。

最後にこのファイルに出力された sudo コマンドの parse 処理とイベント通知を設定します。
3. Log processing ルールで、sudo の実行ログを parse して、イベントとしてDynatraceへ通知する
ここでの手順は、2つあります。1つ目が「sudo ログをParseする処理」で、2つ目が「それをEventとして通知する処理」の2つです。順番に見ていきましょう。
- 3.1 sudo ログをParseする処理
ログをParse処理する場合、出力されたログの構造を最初に抑えておく必要があります。先ほどの OneAgent をインストールしたときのログ出力結果から、sudo のログ構造は、下記のようになっていることが分かります。ここから必要な情報を抽出します。欲しい情報としては、この5つなので、これを週出(extract)していきましょう。- 誰が(username, sudo.from)
- いつ(timestamp, sudo.timestamp)
- どこで(workding directory, sudo.pwd)
- 何をしたか(executed command, sudo.exec)
<timestamp> <hostname> sudo: <username> : TTY=<tty_name> ; PWD=<working directory> ; USER=root ; COMMAND=<executed command> EOL
設定箇所は、Settings > Log Monitoring > processing で行います。Log processing(ログのParse処理)は、それだけで10回くらいのシリーズの記事が書けるので、ここではどうやって処理をしたか、その結果だけをまとめています(ゴメンナサイ)。設定すべきは、3箇所です。
- Rule name
Parse処理する log processing ルール名です。 - Matcher
当該 log processing ルールを適用する条件を記載します。この場合、/var/log/auth.log が log.source attribute に設定されていることが条件です。 - Processor definition
実際にログの中身を解析し、Parse処理するルールそのものです。今回は、下記ルールを適用しています。
PARSE(content,"(TIMESTAMP('YYYY-MM-DDThh:mm:ss.SZ')):sudo.timestamp SPACE LD:sudo.hostname SPACE LD:sudo.cmd ':' SPACE LD:sudo.from ' : TTY=' LD:sudo.tty ' ; PWD=' LD:sudo.pwd ' ; USER=' LD:sudo.to ' ; COMMAND=' LD:sudo.exec")


Parse処理の設定が一通り終わったら、Test the Ruleボタンをクリックし、前述の自分がちが望んでいる5つの情報が抽出(Extract)されているか、画面で確認しましょう。
- 3.2 それをEventとして通知する処理
2つ目の処理です。先ほど抽出した情報が、Event通知された際にDynatraceの画面でPropertyとして表示されるよう、もう一手間加えます。それが、Custom attributesです。ここでは4つの attributes(誰が、いつ、どこで、何をしたか)を設定しました。

この前準備ができたら、やっとEvent通知の設定です。Event通知は、Settings > Log Monitoring > Events extractionで設定します。先ほどの/var/log/auth.logの中でも、sudo が実行されたことを示すログだけをイベントとして通知する必要があるため、条件を絞り込み、USER=rootが含まれていたら sudo が実行されたと見なします。それが、Matcherの部分です。
あと、ここでの設定で一番大切な箇所は、Event Type の選択です。Dynatraceでは Custom alert や Info event type は Davis AI が Root cause analysis の対象に含めないため、それ以外のもので最も近いイベントを選択します。ここでは「Custom deployment」を選択します。

設定お疲れ様でした。これで準備は完了です。
今度は sudo stress コマンドを実行して、負荷を与える
今回も、同じ stress コマンドを実行しますが、sudo を付けて sudo stress -c 8 -t 10m と実行します。さて、プロブレムの結果はどう変化するでしょうか? Dynatraceでは同じように「CPU saturation」としてプロブレムが検知されましたが、Root Cause部分に変化が見られました。ホストのCPUが高騰した原因として、その前に「Deployment event」があったことを教えてくれました。更に、そのイベントの中身についても、先ほど log processing で処理した内容に基づき、これらの情報をまとめて教えてくれるので、すぐに実行した人含めて特定できるようになりました。
- 誰が(attribute名:sudo.from)
- いつ(attribute名:sudo.timestamp)
- どこで(attribute名:sudo.pwd)
- 何をしたか(attribute名:sudo.exec)

まとめ
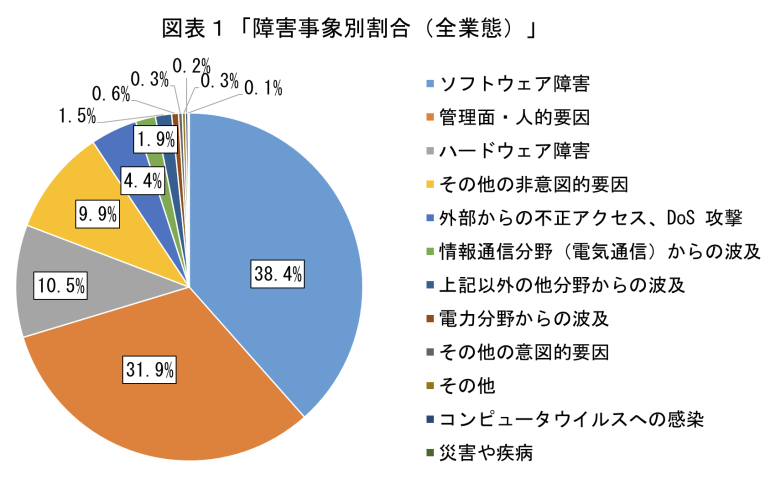
設定などの準備の話が少し長くなりましたが、DynatraceのEventを利用したDavis AIのRCA活用についてまとめたブログは如何だったでしょうか?なぜ、今回のように人が実行したイベントログを利活用しようと提案したかというと、2024年6月に金融庁から発表された「金融機関のシステム障害に関する分析レポート」の結果を読んだからです。このレポートを読むと分かりますが(P11ページ)、業態全体の障害傾向を見ると管理面・人的要因は全障害のうち31.9%も該当します。日々の運用で発生する変更、新しいソフトのDeploymentなど、なにか既存のシステムに対して人が手を加えたことで発生する障害は意外と多いということが分かります。そういった金融庁からの分析レポートもあり、今回のようにあるコマンドを実行したログを活用し、それをDynatraceへEvent通知させることで、原因分析の初動を早めることに繋がるのではないかと思っています。Dynatraceは単なる監視ツールではなく、オブザーバビリティ・プラットフォーム なので、監視機能のみならず、分析機能、解析機能、セキュリティ機能など幅広い機能を有しているがゆえ、単にメトリクス、ログ、トレースを見るだけでは無く、監視対象システムの変更やコマンドの実行履歴に関するイベントをうまく取り込み、日々の運用監視のギアをひとつ上げて頂ければと思います。
まだ、Dynatraceを触ったことがない方、このブログを見てやってみたいと思われた方は、下記フリートライアルにてお試し下さい。↓↓↓
Dynatraceフリートライアル → https://www.dynatrace.com/ja/trial/