今日は、管理者権限の無い Windows 11で Portableな Apache Spark環境を作ってみます。
Linuxに比べると ちょい面倒だな、と思ったので共有しておきます。
更新履歴
(2023/05/01) Golden Weekに Windows11で色々最新化しておきましたが、コンパイル済みのWinUtilsが提供されなくなっているため、
入れる物
バージョン依存もあるので、あまり環境に影響を与えない形で入れて使う形にします。
VC++のRUNTIME DLLを除けば、今回作る Sparkのフォルダを丸ごとコピーして、
他のマシンにも持っていけるはずです(所謂Portable)。
- Spark: 3.4.0 (Apr 13, 2023)
- Java: OpenJDK17.0.7+7
- Python: 3.7+ latest (3.11.3 - Embedded/Isolated)
- Scala: 2.13.10
必要な物
- Windows11 64bit
- 7-zip(7z.exe)
7-zipは zipと tgz(.tar.gz)の解凍ができればよいので 他に方法があれば それでかまいません。
懸念点
管理者権限が完全無しでいけるかどうか。
Runtime DLL
管理者権限が無い場合、実行ファイルのDLL依存関係が少しやっかいです。
インストールされるファイルの .exe および .dll が static に linkしている DLL (変な表現)で
通常 Windows10の Systemに無いかもしれない DLLは以下の三つがあります。
MSVCP140.dll - MSVC++ 2015
VCRUNTIME140.dll - MSVC++ 2015
MSVCR100.dll - MSVC++ 2012
私の環境では VC++2013と VC++2015-2019の 再頒布可能パッケージが 既に入っていたため、問題ありませんでした。
入っていない場合、 Visual Studio 2019 の Microsoft Visual C++ 再頒布可能パッケージ等から入手してインストールが必要になります。
インストールパス
管理者権限無しでファイルを書き込む事ができる場所のパスに、空白文字が含まれる場合、問題が発生するはずです。
以下の例では C:\tools\spark にインストールしています。
書き込めるパスに空白文字がどうしても入ってしまうという場合、確かSUBSTコマンドは管理者権限でなくても実行できると思うので、別のドライブにアサインする等して回避できるかと思います。
ダウンロード
まず必要なファイルを全部ダウンロード。
下で細かく説明してますが、バージョンにこだわりが無く、まとめてダウンロードしたいなら以下の直リンクから落としてください。
- Eclipse Temurin JDK 17.0.7+7
- Python 3.11.3 Windows Embedded 64-bit
- Scala 2.13.10
- Apache Spark 3.4.0 with Hadoop 3.3+ and Scala 2.13
- winutils
他のバージョンにしたい、mirrorなどの状況もあって直接落とせない場合は以下を参照してみてください。
Eclipse Temurin™
.msiではなく、.zip のアーカイブが欲しいので以下からダウンロードします。
- Operating System で Windowsを選択
- Architectureで x64
- Package Typeで JDK
- Versionで 17
- .zipを押してダウンロード

Python 3.7+
今回 Spark 3.4.0を使うため Python 3.7が Deprecatedになっています。
Python Versionに制約のあるWindows7では、Python 3.8.16が使えるかと思います。
以下から Windows embeddable package (64-bit) をダウンロードします。
Scala 2.13
Version 2 系は以下のページから。
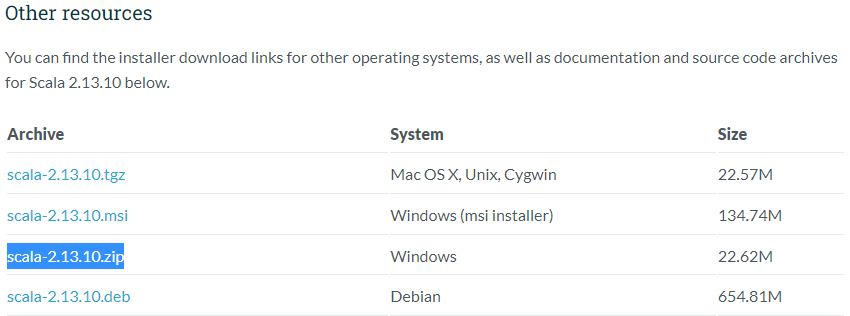
このページの Current releasesから 2.13系のLatestに飛びます。今だと SCALA 2.13.10です。
ここの Other Resourcesから scala-2.13.10.zip をダウンロードします。
Apache Spark 3.4.0
Download Apache Sparkのページにいきます。
- Choose Spark Release から バージョンを指定
- Choose Package Type から パッケージタイプを選択(Pre-built for Apache Hadoop ...にしてください)
- ダウンロードリンクからダウンロード
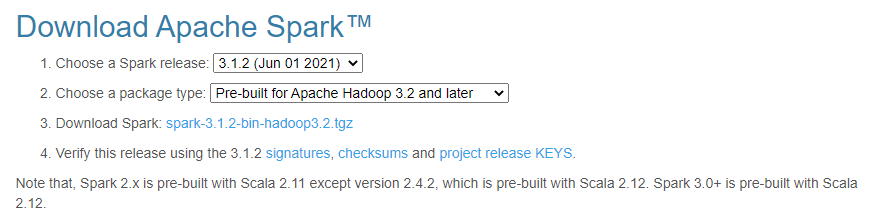
蛇足ですが、Package Typeの選択で user-provided Apache Hadoopを選ぶとファイル名が spark-3.1.2-bin-without-hadoop.tgz になります。Hadoopなんて要らんって思ってこれを選ぶと、必要な Hadoop Client が無くて動きませんので注意してください。
WinUtils
Hadoop 3.3.5向けが無いので自前でコンパイルしてみます。
Windows 11 Proなどを使っているのであればサンドボックスで環境を汚さずに済むと思います。
なお、Visual Studioですが、Build Toolsでは コマンドが足りないため、IDEを入れる必要があります。
- サンドボックス起動
- Visual Studio 2022 Community EditionをDownloadして"C++によるデスクトップ開発"をチェックしてInstall
- OpenJDK17 17.0.7+7をInstall。このとき JAVA_HOMEを設定する項目をチェックしておくこと。
- CMake 3.26.3をインストール。このとき "PATHを設定する" を選択しておく。
- Maven 3.9.1をダウンロードして、C:\tools\apache-maven-3.9.1 に展開して、M2_HOMEを "C:\tools\apache-maven-3.9.1"に設定、PATHに"%M2_HOME%\bin"を追加
- Protocol Buffers v22.3をダウンロードして "C:\tools\protoc"に展開。PATHに "C:\tools\protoc\bin" を追加
- Cygwinを "C:\cygwin64" にインストール。
- gitをinstall
- vcpkgをInstall
git clone https://github.com/microsoft/vcpkg
.\vcpkg\bootstrap-vcpkg.batvcpkg
.\vcpkg\vcpkg.exe install openssl --triplet x64-windows-static
.\vcpkg\vcpkg.exe install protobuf --triplet x64-windows-static
.\vcpkg\vcpkg.exe integrate install
- コマンドプロンプトを立ち上げて以下を実行して Hadoopのソースをダウンロードして展開
SET "PATH=C:\cygwin64\bin;%PATH%"
call "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat"
mkdir C:\work
cd C:\work
curl -LOJR https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5-src.tar.gz
tar xzf hadoop-3.3.5-src.tar.gz
cd hadoop-3.3.5-src
mvn package -Pdist,native-win -DskipTests -Dtar -Dmaven.javadoc.skip=true -Dnative_cmake_args="-DOPENSSL_USE_STATIC_LIBS=TRUE -DProtobuf_USE_STATIC_LIBS=ON -DCMAKE_TOOLCHAIN_FILE=C:/work/vcpkg/scripts/buildsystems/vcpkg.cmake"
mvn package -Pdist,native-win -DskipTests -Dtar -Dmaven.javadoc.skip=true "-Dnative_cmake_args=--trace-expand -DOPENSSL_ROOT_DIR=C:/work/vcpkg/installed/x64-windows-static -DOPENSSL_USE_STATIC_LIBS=TRUE -DProtobuf_USE_STATIC_LIBS=ON -DCMAKE_TOOLCHAIN_FILE=C:/work/vcpkg/scripts/buildsystems/vcpkg.cmake" -rf :hadoop-hdfs-native-client
展開
ダウンロードしたファイルを展開します。
私は C:\tools\spark\ に展開する事にしますのでダウンロードしたファイルを集めます。
C:\tools\spark>dir
2021/06/26 11:09 196,371,089 OpenJDK11U-jdk_x64_windows_hotspot_11.0.11_9.zip
2021/06/26 11:16 8,427,568 python-3.9.5-embed-amd64.zip
2021/06/26 10:31 21,133,076 scala-2.12.14.zip
2021/06/26 11:28 228,834,641 spark-3.1.2-bin-hadoop3.2.tgz
2021/06/26 11:51 20,758,178 winutils-master.zip
これを適宜解凍しますが、pythonだけは zipがフォルダ名を含んでいないので python-3.9.5に解凍します。
以下は7z.exeを使った場合のバッチ
7z x OpenJDK11U-jdk_x64_windows_hotspot_11.0.11_9.zip
7z x scala-2.12.14.zip
7z x -opython-3.9.5 python-3.9.5-embed-amd64.zip
7z x spark-3.1.2-bin-hadoop3.2.tgz
7z x spark-3.1.2-bin-hadoop3.2.tar
7z x winutils-master.zip
こんな感じでフォルダに展開されると思います。
C:\TOOLS\SPARK
├───jdk-11.0.11+9
├───python-3.9.5
├───scala-2.12.14
├───spark-3.1.2-bin-hadoop3.2
└───winutils-master
調整と利用
環境設定用バッチファイルの作成
ファイルを置いただけなので、利用するためにはいろいろ設定する必要があります。
C:\tools\spark 配下に バッチファイルを一つ準備します。
@ECHO OFF
SETLOCAL ENABLEEXTENSIONS ENABLEDELAYEDEXPANSION
SET "SPARK_ROOT=%~dp0"
SET "SPARK_ROOT=%SPARK_ROOT:~0,-1%"
SET "JAVA_HOME=%SPARK_ROOT%\jdk-11.0.11+9"
SET "SCALA_HOME=%SPARK_ROOT%\scala-2.12.14"
SET "SPARK_HOME=%SPARK_ROOT%\spark-3.1.2-bin-hadoop3.2"
SET "HADOOP_HOME=%SPARK_ROOT%\winutils-master\hadoop-3.2.0"
SET "PYTHONHOME=%SPARK_ROOT%\python-3.9.5"
SET "PATH=%JAVA_HOME%\bin;%PYTHONHOME%;%PYTHONHOME%\Scripts;%SCALA_HOME%\bin;%SPARK_HOME%\bin;%HADOOP_HOME%\bin;%PATH%"
SET "PROMPT=(Spark 3.1.2) %PROMPT%"
REM SET PYSPARK_DRIVER_PYTHON=ipython.exe
CMD /K "ECHO Enable Spark on %SPARK_ROOT%"
ECHO Bye
ENDLOCAL
Spark環境にしたい場合は、CMD.exe等を起動して このバッチファイルを実行します。
実行するとプロンプトが変わります。

終わるときは exit してください。
Windows Terminal で Spark プロファイルの作成
私は Windows Terminalで使っているのでSpark用のプロファイルをこんな感じで登録しています。

※ この場合、先程のバッチファイルの最後に EXIT 0 を追加しています。
spark-shellの実行
この時点で Spark環境で Windows Terminalを開いて spark-shell が実行できます。pysparkはまだ動きません。
spark-shellを実行するとこんな感じになります。
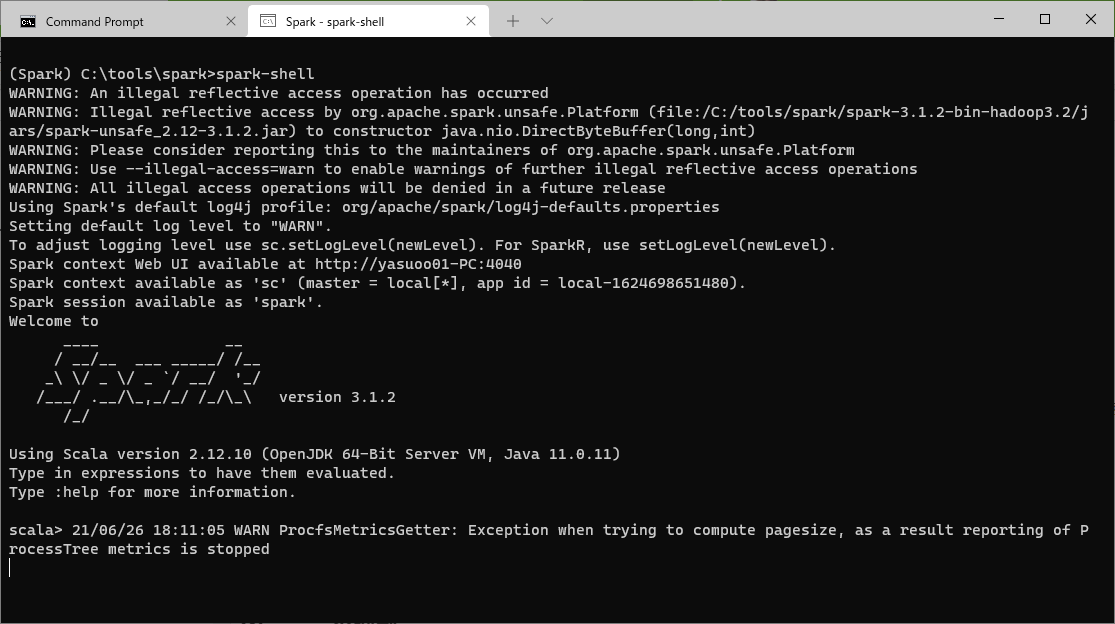
port 4040で Web UIが起動するため、Windows Firewallなどが警告をあげてくるかと思います。
この許可には特権昇格して 管理者権限がどうしても必要になってしまうかもしれません。
最初に 5行ほど、盛大に出るWarningは JDK11を使っているためで、--illegal-access=permit がデフォルトのためです。
permitのため JVM起動後一回で 無視できますが、気持ち悪いので抑制したいところです。
それとプロンプトが出た後、しばらくすると WARN ProcfsMetricsGetter が出てきます。
さらに :quit で終了させると最後に盛大にワーニングが出ます。
Warningの抑制
Reflection
最初に出る Warningについてです。
いくつかのパッケージに対して Private Fieldに対する Reflectionを許可します。
SparkのJVM起動オプションを調整します。
cd C:\tools\spark\spark-3.1.2-bin-hadoop3.2\conf
copy spark-defaults.conf.template spark-defaults.conf
notepad spark-defaults.confで、最後に以下の数行を追加します。
spark.driver.extraJavaOptions --add-opens java.base/java.lang=ALL-UNNAMED \
--add-opens java.base/java.nio=ALL-UNNAMED \
--add-opens java.base/java.util=ALL-UNNAMED \
--add-opens java.base/java.util.concurrent=ALL-UNNAMED
作業によっては、これでも WARNINGが出るかと思います。その場合は更にパッケージを追加する等してください。
driverだけじゃなく、executorも同じ設定があります。
とりあえずLocalで触ってるだけなら影響ないので、ここでは設定していません。
ProcfsMetricsGetter
以下の箇所でprivateフィールドの初期化の瞬間にエラーが出てるみたいです。
Github ProcfsMetricsGetter.scala
Windowsには procfsはもちろん無いので、無視するというか、Log4Jで表示しないようにしてしまいます。
confの下の log4jテンプレートをコピーします。
cd C:\tools\spark\spark-3.1.2-bin-hadoop3.2\conf
copy log4j.properties.template log4j.properties
以下の二行を log4j.propertiesに追加します。
# Disable logging for ProcfsMetricsGetter
log4j.logger.org.apache.spark.executor.ProcfsMetricsGetter=OFF
Setting default log level to "WARN"
ついでなので、最初に出ていた Default log level to "WARN"という表示も抑制します。
先ほどの log4j.properties を編集します。
# Set everything to be logged to the console
log4j.rootCategory=INFO, console
↓ ここの INFO を WARN に書き換えます。
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
終了時に大量に出る警告メッセージを抑制する
Sparkが Shutdownするタイミングで テンポラリディレクトリを削除しに行くのですが、
そのタイミングでロード済みの classファイル等はロックされているみたいで消せません。
ここだけは良い対応方法が分からず。
エラーの表示は抑制できるので、臭いものに蓋をします。
# Disable logging for ShutdownHookManager
log4j.logger.org.apache.spark.util.ShutdownHookManager=OFF
#log4j.logger.org.apache.spark.SparkEnv=ERROR
2行目、コメントアウトしてありますが、同様に SparkEnv側をERRORまで落として
WARNINGを抑制する事が Googleで検索するとたくさん出てきます。
私が軽く触った範囲だと気にならなかったので コメントアウトして様子見しています。
なお、終了時に消したい物が消せないので
spark.repl.class.outputDir(%TEMP%\spark-*) フォルダに
毎度ファイルが残留する事になります。
通常これは %TEMP% 配下なので、ディスクのクリーンアップで消えると思います。
方法はどうあれ、%TEMP%\spark-... の定期的に削除する事が必要になるので注意してください。
定期削除を避ける
spark-shell起動時にバッチファイルで ユニークなフォルダを作って、
--conf spark.repl.class.outputDir=... で、そこを明示的に指定。
バッチファイルの最後でそこを消す。というやり方で問題回避できるかと思ってます。
今のところ、このやり方はCTRL+C等の影響受けるて、好きじゃないのでやってないです。
Warningを抑制した結果
だいぶすっきりしました。

PySparkの利用
PySparkが必要なら以下も行います。
まず、python-3.9.5\python39._pth ファイルを編集します。
このファイルは消さずに隔離モード1で使う形にしています。
PYTHONPATHを追加したい場合はこのファイルに書く様にしてください。
../spark-3.1.2-bin-hadoop3.2/python
../spark-3.1.2-bin-hadoop3.2/python/lib/py4j-0.10.9-src.zip
python39.zip
DLLs
Lib
Lib/site-packages
.
# Uncomment to run site.main() automatically
import site
python3.exe の作成
python.exeだけだと 一部で python3.exe を呼び出されてエラーになるので、
python.exe を python3.exe としてコピーしておきます。
cd C:\tools\spark\python-3.9.5\
copy python.exe python3.exe
pipの取得
pipぐらい無いとなぁと思ったので入れておきます。
pythonを使うので Spark環境で操作します。
Spark環境が立ち上がったら以下を実行します。
python -c "import urllib.request as r; r.urlretrieve('https://bootstrap.pypa.io/get-pip.py', 'get-pip.py')"
python get-pip.py
del get-pip.py
pip install pandas とかして インストールできれば問題無いと思います。
ポータブルに、と書きましたが、PIPについてはポータブルではないようです。
Scripts配下のpip.exeを調べると以下のようにパスが埋め込まれていました。
strings pip.exe | findstr /i python.exe
#!C:<get-pip.pyを実行したときのパス>\python.exe
このPython環境では モジュールが含まれていませんので venvは使えません。
一応、私の環境では Installer版のPythonから Lib/venvと Lib/ensurepipの二つをコピーして持ってくることでvenvも使うことができました。この二つはpipで持ってくることができないモジュールです。
IPython で PySparkを動かす
ipython を install します。
pip install ipython
その後 pysparkを起動するときに環境変数を設定します。
set PYSPARK_DRIVER_PYTHON=ipython.exe
起動するとこんな感じです。
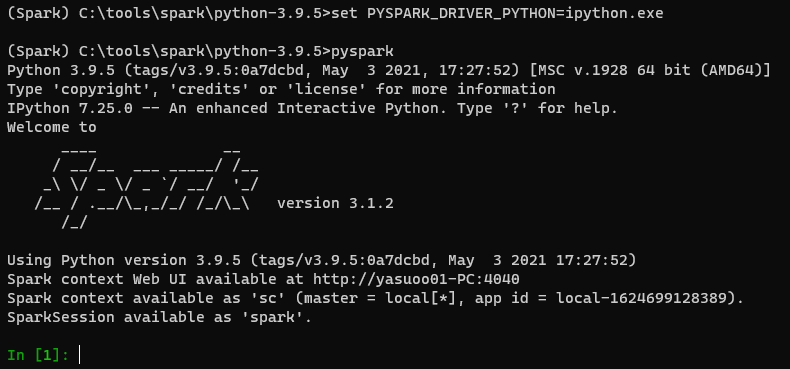
テスト実行
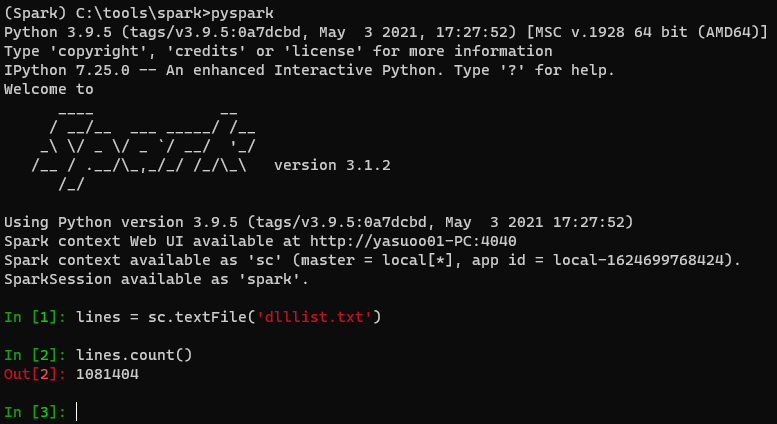
テキストファイルの行数数えてみる
- 先ほどの方法で IPython を使って PySpark を起動する。
- lines = sc.textFile('適当なテキストファイル')
- lines.count()
これでテキストの行数が出てくるかと思います。wc -l の方が速いとか言わない(笑)。
円周率を計算
spark-submit --class org.apache.spark.examples.SparkPi spark-3.1.2-bin-hadoop3.2\examples\jars\spark-examples_2.12-3.1.2.jar 100
回数を変えて二回実行してみます。

まとめ
こんな感じで Windowsでも 環境をあまり変えずにSpark環境を作る事ができました。
フォルダを丸ごとコピーすれば環境を持ち運べるので わりと便利に使えるのではないかと思います。
VCのRuntimeだけはインストール必要ですが、Office入ってたりすれば 多分大丈夫。
まだ、サンプルを流したくらいで、そんなに使い込んでいません。
何か問題等あれば コメント等いただけると ありがたいです!
蛇足:話の発端
いままで会社から支給される PCは macをお願いしており、いろいろやるときはその上に LinuxをVMで立てて使っていました。
3月、会社PCの入れ替えがあったときに「たまにはWindowsにするか」と思って なんとなく変えてみました。これで次の入れ換えまで 3年間は Windowsです。
それと同じ頃、会社が Spot Waveという、Cloud上のSpark Cluster(Cluster ManagerはKubernetes)のインフラコストを最適化するというサービスを発表してました。
計画は以前からあったのと、ベースは Spot Ocean なので、「出てきたなー」というだけの感じだったのですが、つい5日ほど前に「DataMechanics買収しちゃうよ」というアナウンス。
こちらは SparkのUI/History サーバとしてDelightの開発・提供と、SparkのJob設定の自動チューニングをしてくれる物です。
シンプルに Spark Jobを Submitすれば、SparkのJobのパラメータを最適化してくれて、インフラもお得に準備してくれる。そんな環境を提供できるようになります。楽ちんそう(小並感)。
おぉ、弊社 Cloud上の Sparkに本気?2と思ったので、久しぶりに Spark 入れておくかと思ったのが発端です。
私の会社では PCの管理者権限を一応取得できるのですが、環境を汚したくないというのもあって今回こんな記事を書きました。
Spot Waveについては、また別の機会に。