はじめに
WEBマンガ、たまに読むんですが、いっぱいありすぎてどれを読めばいいのかわからなくなります。
どのマンガを読むかを選ぶひとつの指標として、コメントが使えないかというの考えました。
人気のある漫画はコメントが多いですし、コメントが少なくても面白いマンガも多い。
それで、いろいろとコメントを解析してみようと思っているんですが、その第一弾として、コメントをワードクラウド化してみたところ、コメントが視覚的に把握できて、興味をそそるマンガかどうかを直感的に見ることができました。
ワードクラウドをもとに新たな切り口でマンガを選ぶことで、作家さんが一生懸命書いたマンガの入り口になって、マンガ界の活性化に貢献できればという思いもこもってます。ちょっと大げさですかね。
環境
python 3.7.6
selenium 3.141.0
ChromeDriver 80.0.3987.16
wordcloud 1.6.0
BeautifulSoup 4.8.2
mecab-python-windows 0.996.3
対象
WEBマンガワードクラウド参照サイト
結果を参照できるサイトを下記に作成しました。ワードクラウドをクリックするとそのマンガに遷移します。
ワードクラウド出力結果
以下が出力結果です。どんなマンガなのか気になってきませんか?
「美人」「好き」などのコメントで、ちょっと読んでみたいなぁなんて考えてしまいます。

規約を確認
スクレイピングを行うので、規約を確認します。
<niconico利用規約より抜粋>
5 禁止事項
利用者による「niconico」の利用に関して、以下の行為が禁止されています。
- ニコニコ活動ガイドライン第3項及び第4項に掲げる行為又はこれらの行為に準じる行為(コメントの書き込みや動画等の投稿以外の手段を通じて行われる行為を含みます)
- 本利用規約の条項に違反する行為
- 公職選挙法に抵触する行為
- 「niconico」のサーバーに過度の負担を及ぼす行為
- 「niconico」の運営を妨害する行為
- 児童買春・ポルノ、無修正ビデオ動画のダウンロードサイト等へのリンク掲載
- 運営会社の許諾を得ない売買行為、オークション行為、金銭支払やその他の類似行為
- 運営会社の許諾を得ない商品の広告、宣伝を目的としたプロフィール内容の公開、その他スパムメール、チェーンメール等の勧誘を目的とする行為
- 13歳以上の未成年者が法定代理人(親権者)の同意を得ずに、「niconico」を利用する行為
- 運営会社が不適切であると考える行為
- その他上記に準じる行為
ということで、過度な負荷をかけないよう注意して実施します。
連続走行させない、スリープを挟むなどを実施しながら実行してます。
処理の流れ
以下の流れで処理を実行します。
- ニコニコにログイン
- ニコニコ静画を更新順で表示しマンガ一覧からURLリストを取得
- 漫画の詳細に遷移
- コメントを取得
- コメントをWordCloudで処理
ニコニコにログイン
ニコニコ静画を参照するにはログインが必要です。
ここでは、seleniumを使って、バックグラウンドでニコニコにログインします。
seleniumとChromeDriverはインストールしてある前提です。
ChromeDriver
ライブラリインポート
下記で必要ライブラリをインポートします。
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import urllib.parse
WebDriver構築
オプションを設定して、ドライバーを構築します。
バックグラウンドで動作させるため、--headlessオプションを指定しています。
また、set_page_load_timeoutでタイムアウトを30秒に設定しています。
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1024,768')
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(30)
ログイン
まず、https://account.nicovideo.jp/login?site=seiga&next_url=%2Fにアクセスします。
つぎに、メールアドレスとパスワードの項目をIDで取得して、それぞれを設定しています。
最後に、ログインボタンをクリックしています。
[メールアドレス]、[パスワード]はご自身のに変更してください。
driver.get('https://account.nicovideo.jp/login?site=seiga&next_url=%2F')
e = driver.find_element(By.ID, "input__mailtel")
e.send_keys('[メールアドレス]')
e = driver.find_element(By.ID, "input__password")
e.send_keys('[パスワード]')
e = driver.find_element(By.ID, 'login__submit')
e.click()
requestsのpostを使ってもログインできるのですが、その場合は、ログイン画面からauth_idを取得してそれもポストする必要があります。そのあたりの処理がseleniumでは不要です。
また、画面表示後にJavaScript等で画面が更新される場合にもrequestsではいろいろと手間がかかりますが、seleniumだとそのあたりも気にせずに処理ができるのが便利です。
ニコニコ静画を更新順で表示しマンガ一覧からURLリストを取得
更新順でマンガの一覧を取得
下記の状態の時の静画の一覧を取得していきます。

ページ遷移をしながら各ページのマンガ一覧のマンガのURLを一覧で取得します。負荷のことを考え、ここでは1~3ページまでを取得します。
url_root = 'https://seiga.nicovideo.jp'
desc_urls = []
for n in range(1, 4):
target_url = urllib.parse.urljoin(url_root, 'manga/list?page=%d&sort=manga_updated' % n)
try:
driver.get(target_url)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
# change to loop
for desc in soup.select('.mg_description'):
title = desc.select('.title')
desc_urls.append(urllib.parse.urljoin(url_root, title[0].find('a').get('href')))
except Exception as e:
print(e)
continue
desc_urlsリストにマンガへのURLを保存します。
target_urlに各ページへのURLを設定します。QueryString の page= に数字を設定することでページ制御されていますので、そこに取得したいページの数字を設定します。
driver.getでページを取得します。取得したら、driver.page_source.encode('utf-8')で中身のHTMLを取得し、扱いやすいようにBeautifulSoupに設定しています。
BeautifulSoupに設定しなくても扱えますが、こっちのほうが慣れているのでこっちにしたという程度です。WebDriverはXPathとかも使えるので、そのままでも十分大丈夫だと思います。
BeautifulSoupのselectはCSSセレクターなので、.mg_descriptionを取得して、その中の.titleとそこに設定されている a タグの href を取得しています。
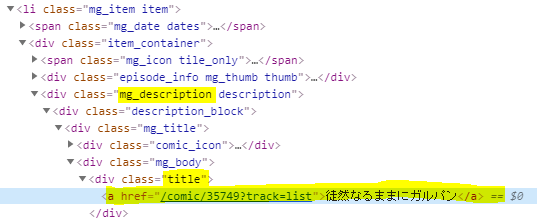
これで、ページ上のマンガのタイトルとURLの一覧が取得できました。
漫画の詳細に遷移
リスト内のURLでページを取得
desc_urlsに保持したURLでページを取得します。取得は、driver.get(desc_url)でやってます。
取得したら同様にHTMLを取得して BeautifulSoupに設定します。
for desc_url in desc_urls:
try:
driver.get(desc_url)
html = driver.page_source.encode('utf-8')
soupdesc = BeautifulSoup(html, 'html.parser')
タイトルと著者を取得して確認
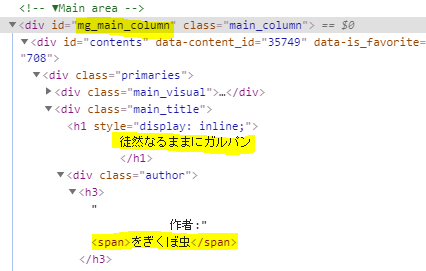
div タグで id が ng_main_columnのエレメントを取得します。
その中の、`.main_title'クラスのエレメントを取得し、タイトルと著者を取得します。
print してみて、きちんと取得できているかを確認してみます。
maindesc = soupdesc.find('div', id = 'mg_main_column')
titlediv = maindesc.select('.main_title')[0]
title = titlediv.find('h1').text.strip()
author = titlediv.find('span').text.strip()
print(title)
print(author)
HTMLの構造は以下のようになっています。
エピソード一覧からサブタイトルと詳細へのURLを取得して遷移
クラスが .episode_item のエレメントに各エピソードがあるので、そのリストを CSSセレクタの select で取得します。
複数のエレメントが取得されるので、それぞれのエレメントから、サブタイトルと詳細へのURLを取得します。
for eps in soupdesc.select('.episode_item'):
eps_ttl_div = eps.select('.title')
eps_title = eps_ttl_div[0].find('a')
eps_url = urllib.parse.urljoin(url_root, eps_title.get('href'))
eps_t = eps_title.text
print(eps_t)
try:
driver.get(eps_url)
html = driver.page_source.encode('utf-8')
soupeps = BeautifulSoup(html, 'html.parser')
タイトルは、.titleクラス、URLは a タグの href から取得しています。
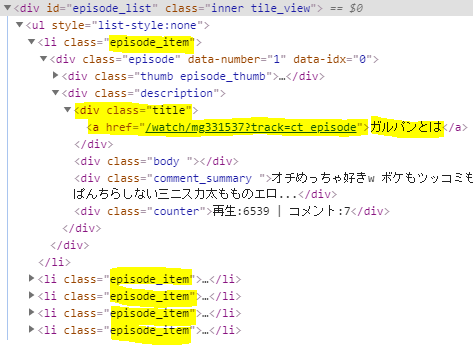
driver.get(eps_url)で詳細画面を取得しています。
取得したら、BeautifulSoupに設定します。
コメントを取得
コメントのリストを取得し、その中のテキストを配列に設定
クラスが .comment_listのエレメントを取得し、その中の .commentをすべて取得しています。
その中の文字列を c.textで取得し、配列comments_textに設定しています。
配列への設定は、リスト内包表記を使っています。pythonの内包表記はチューリング完全だそうです。
crlist = soupeps.select('.comment_list')
comments = crlist[0].select('.comment')
comments_text = [c.text for c in comments]
コメント部分のHTML構成は以下のようになっています。comment_viewerの find でもできそうですね。この辺りはいい感じに指定していきましょう。
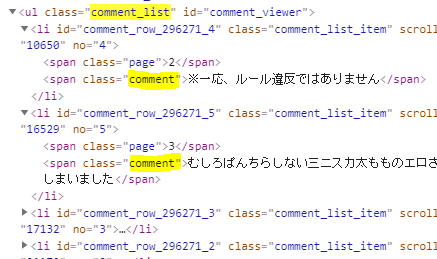
コメントをWordCloudで処理
MeCabで形態素解析
取得したコメントの文字列は、MeCabで形態素解析します。
インポート分を付け加えましょう。
import MeCab
MeCab の parse で形態素解析をします。
m = MeCab.Tagger('')
parsed = m.parse('。'.join(comments_text))
形態素解析した結果は、以下のようになります。
'流石\t名詞,形容動詞語幹,*,*,*,*,流石,サスガ,サスガ\nに\t助詞,副詞化,*,*,*,*,に,ニ,ニ\nなかっ\t形容詞,自立,*,*,形容詞・アウオ段,連用タ接続,ない,ナカッ,ナカッ\nた\t助動詞,*,*,*,特殊・タ,基本形,た,タ,タ\nwww\t名詞,一般,*,*,*,*,*\n。\t記号,句点,*,*,*,*,。,。,。\nそれ\t名詞,代名詞,一般,*,*,*,それ,ソレ,ソレ\nは\t助詞,係助詞,*,*,*,*,は,ハ,ワ\n筆記具\t名詞,一般,*,*,*,*,筆記具,ヒッキグ,ヒッキグ\nで\t助詞,格助詞,一般,*,*,*,で,デ,デ\nは\t助詞,係助詞,*,*,*,*,は,ハ,ワ\nあり\t動詞,自立,*,*,五段・ラ行,連用形,ある,アリ,アリ\nませ\t助動詞,*,*,*,特殊・マス,未然形,ます,マセ,マセ\nん\t助動詞,*,*,*,不変化型,基本形,ん,ン,ン\n…\t記号,一般,*,*,*,*,…,…,…\n。\t記号,句点,*,*,*,*,。,。,。\nキシガイ\t名詞,一般,*,*,*,*,*\n。\t記号,...
\nが一行ごとなので、splitlines で一行ずつ取り出し、\tで区切られている右側の7番目から、形態素の基本形を取得します。
その際、助詞と助動詞、代名詞、そして「する」や「てる」などのいくつかの文字列を除外しています。
除外しないと、ワードクラウドを作ったときに、そればっかりが大きな文字れ表示されてしまいます。
words = ' '.join([x.split('\t')[1].split(',')[6] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] not in ['助詞', '助動詞'] and x.split('\t')[1].split(',')[1] not in ['代名詞'] and x.split('\t')[1].split(',')[6] not in ['する', 'てる', 'なる', 'さん', 'そう', 'この', 'ある']])
WordCloudでワードクラウドを作成
WordCloudの to_file で、ワードクラウドを作成します。
comic_titles comic_subtitles comic_images comic_urls は配列で宣言してある変数で、後ほどHTMLを作成するときに使用します。それぞれ、タイトル、サブタイトル、画像名、URLを保持しています。
WordCloud構築時は、フォント、背景色、サイズを指定しています。フォントは、YouTubeでよく使われているらしい「ラノベPOP」というものを使っています。この辺りはお好みで指定してください。
wordcloud.to_file でファイルに出力しています。
if len(words) > 0:
try:
comic_titles.append(title)
comic_subtitles.append(eps_t)
comic_images.append('%d.png' % (comic_index))
comic_urls.append(eps_url)
wordcloud = WordCloud(font_path=r"C:\\WINDOWS\\Fonts\\ラノベPOP.otf", background_color="white", width=800,height=800).generate(words)
wordcloud.to_file("[保存したいパス]/wordcloud/%d.png" % (comic_index))
comic_index += 1
except Exception as e:
print(e)
出力結果は、最初にお見せしたものです。
これらでHTMLをつくってサイトに公開します。
公開したサイト
上記URLにアクセスすると、下記のようなワードクラウドの一覧が表示されます。
ワードクラウドをクリックすると、そのマンガが開きます。

おわりに
ジャンプ+とかマンガワンとかのコメントって、結構辛辣なコメントが多いですが、ニコニコはみんな優しいコメントが多いです。やはり、コメント慣れしているんでしょうね。
ワードクラウドを作るだけではなくいろいろな分析をして、今まで出会うことが難しかった名作への扉を開くことができたらいいなと思います。