はじめに
普通のWebスクレイピングは、HTMLを解析してXPathやらCSSやらを指定して値や画像をとってくると思います。
ただ、結構面倒くさいし、HTMLの構造のすこしの変更にも耐えられないし、作った後のメンテナンスも大変です。
そこで、YOLOv3を使って、とってきたいところの項目を学習させれば、とても簡単にとりたいものが取ってこれるのではないかというのを実験してみたいと思います。
環境
Windows10 Pro
Visual Studio 2017
CUDA 10.0
cuDNN 7.3.0.29
OpenCV 4.1.1
実験対象の画面
最近は河川の氾濫等が問題になってますので、そのデータを収集して対処できたりしたらいいなということで、河川情報のスクレイピングをしたいと思います。
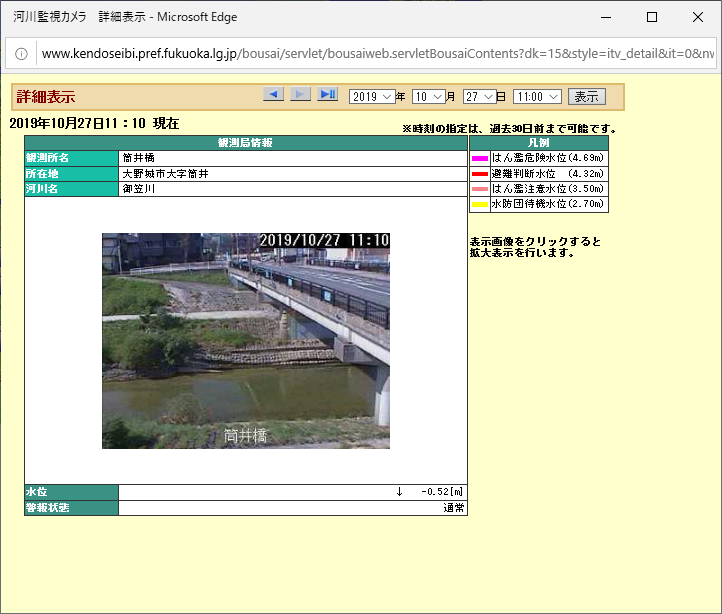
実験としては、この画像の河川情報を一つ一つ切り出して、以下のものを分類できるようにします。
- 観測所名
- 所在地
- 河川名
- 水位
- アップダウン
- 写真
- 状態
- 日時
で、それをこの一覧画像で認識させてみて、すべてうまく取れるかを検証してみたいと思います。
訓練データ準備
いろんな河川の、いろんな時間のデータを準備します。
それを、labelImgを使ってアノテーションしていきます。
※labelImgに関しては、「こちら」を参照してください。
頑張って10枚用意してみました。
分類を定義します。labelImgのpredefined_classes.txtを下記のように編集します。
station
place
name
level
updown
picture
status
datetime
下記コマンドで、labelImgを起動させます。
python labelImg.py
起動したら、「Open Dir」で先ほど画像を保存したフォルダを開きます。
一枚目の画像が表示されるので、アノテーションします。
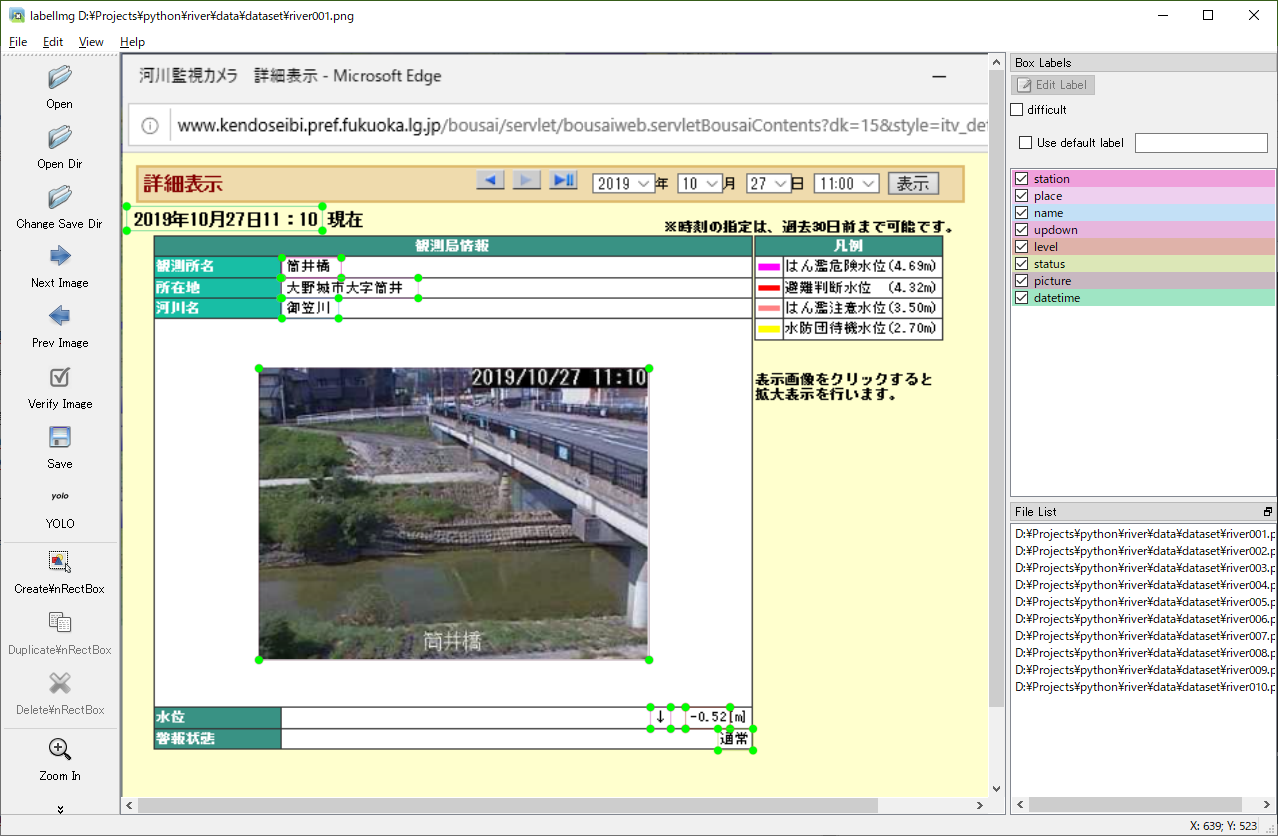
「YOLO」になっていることを確認して、「Save」します。
これを10枚すべてに実施します。
訓練用定義ファイル作成
アノテーションが終わったら訓練用に、YOLOv3で必要とされている各種ファイルを準備します。
最終的に以下のようなディレクトリ構成になります。
| - data
| - river.data
| - river-obj.names
| - river-test.txt
| - river-train.txt
|- backup
|- datasets
|- river001.png
|- river001.txt
|- river002.png
|- river002.txt
|- river003.png
|- river003.txt
|- river004.png
|- river004.txt
|- river005.png
|- river005.txt
・・・
| - cfg
|- yolov3-voc.cfg
| - models
|- darknet53.conv.74
river.data
以下の通り定義します。今回は8つに分類するのでclasses= 8と定義します。
classes= 8
train = data/river-train.txt
valid = data/river-test.txt
names = data/river-obj.names
backup = data/backup
river-obj.names
分類名を定義します。
station
place
name
level
updown
picture
status
datetime
river-train.txt river-test.txt
この二つのファイルには、訓練とテスト用の画像のパスを指定します。今回は訓練させるだけなので、とりあえず同じものを指定しておきます。
data/datasets/river001.png
data/datasets/river002.png
data/datasets/river003.png
data/datasets/river004.png
data/datasets/river005.png
data/datasets/river006.png
data/datasets/river007.png
data/datasets/river008.png
data/datasets/river009.png
data/datasets/river010.png
yolov3-voc.cfg
書き換える部分は、まず画像の幅と高さを指定します。
width=704
height=608
32の倍数で一番近い値を指定します。
次に、下記を書き換えます。
605行目: filters=39
611行目: classes=8
689行目: filters=39
695行目: classes=8
773行目: filters=39
779行目: classes=8
ちなみにfiletersは(classes + 5) * 3という計算式で算出します。今回は39です。
訓練する
下記コマンドを実行します。
※ここいらの詳細も、「こちら」を参照してください。
darknet.exeはパスが通っていればこれでOKですし、とおってなければフルパスで指定してください。
darknet.exe detector train data\river.data cfg\yolov3-voc.cfg models\darknet53.conv.74
訓練が始まります。下記のようにコマンドプロンプトに表示され続けたら訓練がうまく開始できています。
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: 0.309588, GIOU: 0.309587), Class: 0.173368, Obj: 0.475214, No Obj: 0.472567, .5R: 0.000000, .75R: 0.000000, count: 1
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.203723, GIOU: 0.075682), Class: 0.260459, Obj: 0.280586, No Obj: 0.492792, .5R: 0.000000, .75R: 0.000000, count: 2
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.177836, GIOU: -0.001493), Class: 0.488313, Obj: 0.613542, No Obj: 0.505994, .5R: 0.000000, .75R: 0.000000, count: 5
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: 0.276711, GIOU: -0.021736), Class: 0.518737, Obj: 0.440650, No Obj: 0.474075, .5R: 0.000000, .75R: 0.000000, count: 1
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.408596, GIOU: 0.313846), Class: 0.489304, Obj: 0.510784, No Obj: 0.492447, .5R: 0.000000, .75R: 0.000000, count: 2
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.201348, GIOU: 0.007115), Class: 0.409500, Obj: 0.605816, No Obj: 0.505792, .5R: 0.000000, .75R: 0.000000, count: 5
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: 0.166027, GIOU: -0.228276), Class: 0.482262, Obj: 0.395937, No Obj: 0.473088, .5R: 0.000000, .75R: 0.000000, count: 1
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: -nan(ind), GIOU: -nan(ind)), Class: -nan(ind), Obj: -nan(ind), No Obj: 0.493458, .5R: -nan(ind), .75R: -nan(ind), count: 0
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.256849, GIOU: 0.125769), Class: 0.511742, Obj: 0.531665, No Obj: 0.506529, .5R: 0.000000, .75R: 0.000000, count: 4
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: 0.533735, GIOU: 0.441372), Class: 0.500885, Obj: 0.622335, No Obj: 0.472076, .5R: 1.000000, .75R: 0.000000, count: 1
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.429220, GIOU: 0.408887), Class: 0.743075, Obj: 0.325747, No Obj: 0.493080, .5R: 0.000000, .75R: 0.000000, count: 1
v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.073086, GIOU: -0.048264), Class: 0.374560, Obj: 0.673746, No Obj: 0.506537, .5R: 0.000000, .75R: 0.000000, count: 3
学習が完了したので、訓練データの中の一つを指定して確認してみます。
darknet.exe detector test data\river.data cfg\yolov3-voc.cfg data\backup\yolov3-voc_final.weights
ラベルが黒くなってしまってますが、きちんと認識できているようです。
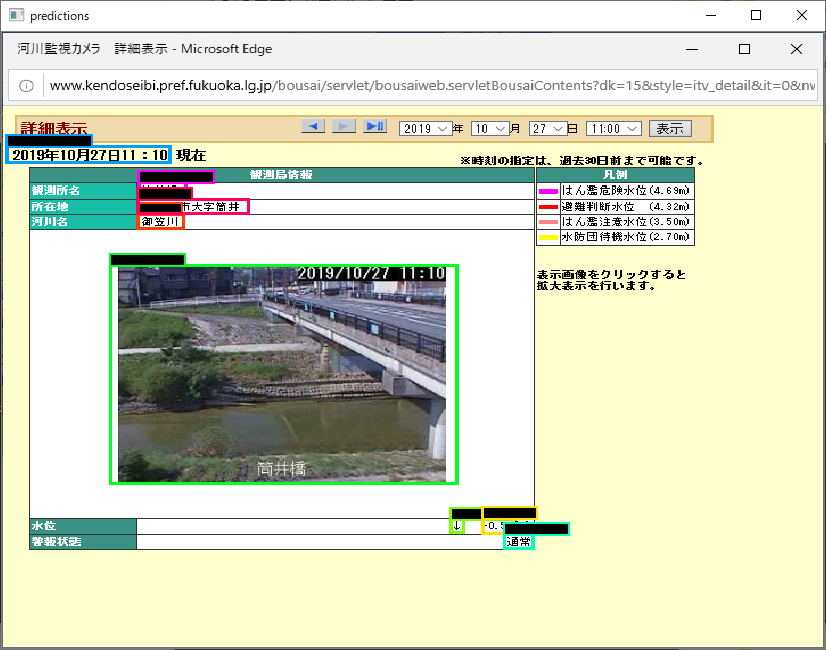
ただ、これだとただ過学習しているだけかもしれないので、新たな画像で確認してみます。
きちんと認識できてますね。
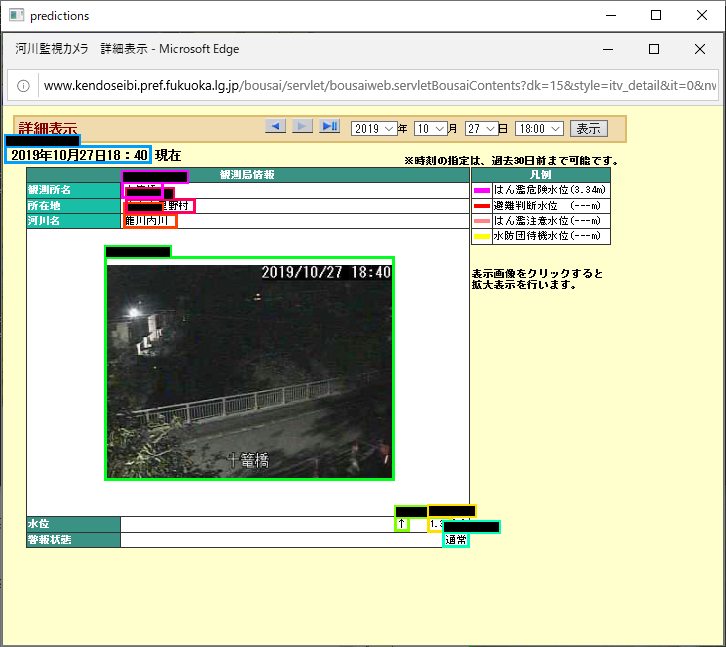
次は、すこし観測所名が長く、水位と警報状態が無いデータです。
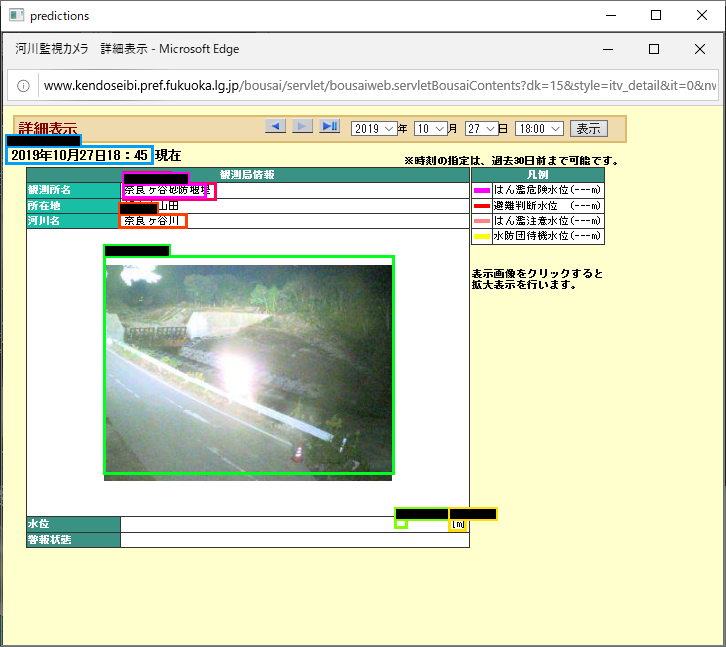
所在地が観測所名として認識されてしまっています。
そう簡単にはいかないようです。
つづく
少し長くなってきたので、今回はここまでにします。
次は、認識率を高める工夫を色々としてみたいと思います。