なぜSTL-10か
GANや識別モデルなどの実験において、画像データセットは必須です。
そして、それらのモデルを簡単に追試しようとした時にベンチマークとして使用されるデータは主にMNISTやらCIFAR10やらなのかなと思います。
ただし、これらのデータは画像のサイズが32x32であり、特にGANなど生成系のモデルで『良い』『悪い』を判断するにはすでに力不足です。
よって、(主観ですが)ちょうどいいサイズである、96x96のSTL-10データセットを、Colaboratoryから使えるようにしていきます。
STL-10とは
- スタンフォード大学が公開している10クラスの画像データセット
- 学習用データ、テスト用データ、ラベルなしデータがある
- 学習用データは1クラスにつき500枚
- テストデータは1クラスにつき800枚
- ラベルなしデータは10万枚ある

(画像例. STL-10の公式サイトより)
手順
1. データのダウンロード
STL-10の公式サイトから以下の赤丸で囲まれた部分のBinary filesをダウンロードする

シェルで以下のコマンドを走らせる
$ tar -zxvf stl10_binary.tar.gz
するとstl10_binaryというディレクトリが同じ階層にできる
2. データをバイナリから変換する
以下のコードを走らせる
参考: KerasでSTL-10を扱う方法
(参考サイトではダウンロードもコードで行なっているが、僕の場合うまくいかなかったのでダウンロードはwebから直接行なった)
※バイナリファイルごとGoogle Driveにあげ、Colabo側から画像に変換をする、ということも考えられるが面倒なので画像にしてから保存する
また、unlabeledな画像は扱いません。
なぜなら、train+testの画像容量が230MBほどであるのに対してunlabeledのみで2GBあるからです。
※もしskimageがなければpip install scikit-imageでいれるか、適宜別ライブラリで代替してください。
import os
import numpy as np
from skimage.io import imsave
class STL10:
def __init__(self, img_dir='stl10'):
self.img_dir = img_dir
self.bin_dir = 'stl10_binary'
def get_files(self, target):
assert target in ["train", "test", "unlabeled"]
if target in ["train", "test"]:
images = self.load_images(os.path.join(self.bin_dir, target+"_X.bin"))
labels = self.load_labels(os.path.join(self.bin_dir, target+"_y.bin"))
else:
images = self.load_images(os.path.join(self.bin_dir, target+"_X.bin"))
labels = None
return images, labels
def load_images(self, image_binary):
with open(image_binary, "rb") as fp:
images = np.fromfile(fp, dtype=np.uint8)
images = images.reshape(-1, 3, 96, 96)
return np.transpose(images, (0, 3, 2, 1))
def load_labels(self, label_binary):
with open(label_binary) as fp:
labels = np.fromfile(fp, dtype=np.uint8)
return labels.reshape(-1, 1) - 1 # 1-10 -> 0-9
def save_images_and_labels(self, images, labels, mode):
"""modeは train, test のいずれか"""
assert mode in ["train", "test"]
img_dir = f'{self.img_dir}/{mode}'
if not os.path.exists(img_dir):
os.mkdir(img_dir)
for i, img in enumerate(images):
imsave(f'{img_dir}/{i}.png', img)
with open(f'{img_dir}.txt', 'w') as f:
f.write(','.join([str(label) for label in train_y.flatten()]))
if __name__=='__main__':
stl10 = STL10('./stl10')
train_X, train_y = stl10.get_files("train")
test_X, test_y = stl10.get_files("test")
unlabeled_X, _ = stl10.get_files("unlabeled")
print(f'train_X.shape: {train_X.shape}')
print(f'test_X.shape: {test_X.shape}')
print(f'unlabeled_X.shape: {unlabeled_X.shape}')
print('save_images_and_labelsの最後はこんな感じ')
print(','.join([str(label) for label in train_y.flatten()[:10]]))
# unlabeledは今回扱わない
stl10.save_images_and_labels(train_X, train_y, 'train')
stl10.save_images_and_labels(test_X, test_y, 'test')
# => train_X.shape: (5000, 96, 96, 3)
# => test_X.shape: (8000, 96, 96, 3)
# => unlabeled_X.shape: (100000, 96, 96, 3)
# => save_images_and_labelsの最後はこんな感じ
# => '1,5,1,6,3,9,7,4,5,8'
これにより、
% ls stl10
test test.txt train train.txt
となります。
これをGoogle Driveにアップロードします。
3. Google Driveにアップロード+Colaboから読み込み
ドライブは画像が多く入っているディレクトリをアップロードしようとするとかなり時間がかかるので一旦zipファイルにしてからアップロードします。
$ zip -r stl10.zip stl10
アップロードしたら、Colaboを開いて
import google.colab.drive
google.colab.drive.mount('gdrive')
を実行、するとリンクが現れるのでそれにしたがって認証を行います。
実行後、別セルにて
!ls gdrive/My\ Drive | grep stl
# => stl10.zip
となればOKです。あとは
!unzip gdrive/My\ Drive/stl10.zip
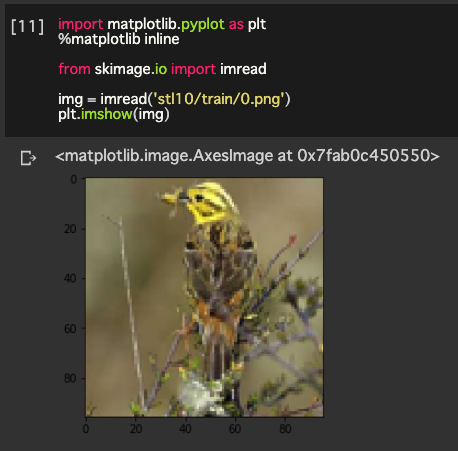
で解凍し、以下のようなコードで確認できれば終わりです!
※解凍して現れるディレクトリは現在の位置にあることに注意してください(つまり、 gdrive/My\ Drive/train/0.pngではなくstl10/train/0.png)
最後に、何かもっと良い方法等あればコメントにて教えていただければと思います。