はじめまして。yamaimo (@yarnaimodev) です。Qiita 初投稿...というかネット上にちゃんとした記事を上げるの自体初めてな気がします。
1998 年生まれで、プログラミングとか Web デザインは独学で 3 年ぐらいやってます。TypeScript / Firebase / Node.js / React あたりが特に好きです。
この前 coliss で紹介された Can't Unsee を試してみたら 1 回目が 7,630 点、2 回目が 7,930 点でした。1
小規模ですが Mastodon インスタンスを管理してます。あと Helix キーボード をこの前組み立てた2んですがキー配列を変えたのがなかなか覚えられなくて死んでます。
開発環境は基本的に WSL + Hyper + fish shell と VSCode です。
今回 Puppeteer を使って Web ページをそのままの状態でローカルに保存するツールを作ったので紹介します。
🤔🤔
Web 上の記事などを HTML でローカルに保存したいとき、名前を付けて保存で「ウェブページ 完全」を選ぶと問題なく保存できるサイトもありますが、Web フォントとか CSS の background-image だったり、<iframe> の中身が保存できず不完全な状態になってしまうこともよくあると思います。
いろいろ探してみると Puppeteer を使って画像や PDF で保存するライブラリは見つかったのですが、サイズが固定されて扱いにくかったり、動画/GIF の保存や全文検索が難しいという問題がありました。
そんな訳でページ内のコンテンツを完全に保存できるツールがほしいと思って作り始めたんですが、色々と不都合が生じて設計を大幅に変えたりしながら 2 ヶ月でなんとか使える状態になりました。(例えば最初は単一ファイルで保存することを重視して Base64 で直接埋め込んでたけど容量がすごいことになってやめたり)
作ったものがこちらです ✨🎉🎉
Vanilla Clipper
https://github.com/yarnaimo/vanilla-clipper
1 つのコマンドでページ内の動画・CSS・Web フォント・iframe・Shadow DOM などもすべてローカルに保存することができます。
ℹ️ 使い方
Vanilla Clipper を使うにはまず Chrome と Node.js のインストールが必要です。
Node.js は https://nodejs.org/ja/ から最新版をダウンロード・インストールできます。
📦 インストール
Vanilla Clipper を npm (または yarn) でインストールします。
npm i -g vanilla-clipper
インストールが完了するとホームディレクトリ3に .vanilla-clipper ディレクトリが作成されます。
中の構成はこちらです。
📃 Web ページを保存してみる
例えばこのコマンドを実行すると、https://qiita.com が .vanilla-clipper/pages/main/{日付}-qiita.com.html として保存されます。
vanilla-clipper https://qiita.com
# 失敗する場合は -n オプション
vanilla-clipper -n https://qiita.com
保存されたページがこちらです
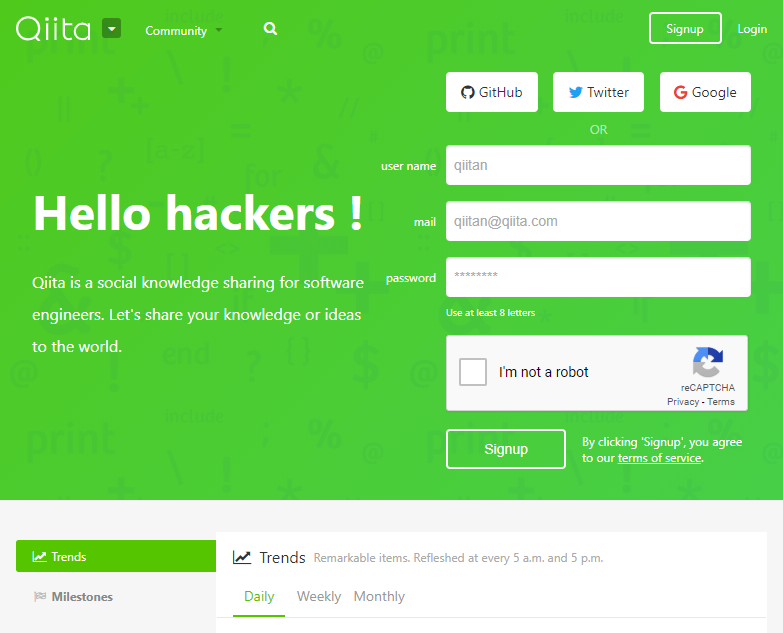
Web フォントとか iframe (reCAPTCHA のところ) も表示できてますよね。
試しにデベロッパーツールで Offline にしても表示できるので、ローカルに保存されていることがわかると思います。
🎛️ vanilla-clipper コマンドのオプション一覧
| オプション名 | デフォルト値 | 説明 | 例 |
|---|---|---|---|
| --headless, -h | true | Chrome を headless モードで起動する。 | -h false |
| --language, -l | ブラウザの言語を指定する。 | -l ja-JP | |
| --directory, -d | 'main' | 保存先フォルダを指定する。 | -d tech |
| --account-label, -a | 'default' | ログインアカウントのラベルを指定する。(後述) | -a sub |
| --device | エミュレートするデバイスを指定する。一覧はこちら。 | --device 'Pixel 2' | |
| --element, -e | 切り抜きたい HTML 要素のセレクタ。 | -e '[role=main]' | |
| --click, -c | クリックさせたい HTML 要素のセレクタ。 | ||
| --scroll, -s | 最下部までスクロールさせたい HTML 要素のセレクタ。指定しない場合は <html> と <body>。 |
||
| --max-scrolls, -x | 10 | -s で指定した要素を最下部までスクロールする回数。タイムラインの無限スクロールなど。 | -s 5 |
📌 ページごとにオプションを変えたい場合、vanilla-clipper をローカルインストールしてスクリプトから直接実行すると一括で保存できます。
⚙️ 設定ファイル
🔒 ログインに必要な情報を設定ファイルに書くと自動でログインさせることができます。
module.exports = {
resource: { maxSize: 50 * 1024 * 1024 },
sites: [
{
url: 'example.com', // サイトのURL
accounts: {
default: {
// ↑ アカウントラベル
username: 'main',
password: 'password1'
},
sub: {
// ↑ アカウントラベル
username: 'sub_account',
password: 'password2'
}
},
login: [
// ログインの手順
[
'goto',
'https://example.com/login' // URL
],
[
'input',
'input[name="session[username_or_email]"]', // セレクタ
'$username' // -> accounts.{アカウントラベル}.username
],
[
'input',
'input[name="session[password]"]', // セレクタ
'$password' // -> accounts.{アカウントラベル}.password
],
[
'submit',
'[role=button]' // セレクタ
]
]
}
]
}
- ログイン情報は複数アカウント保管することができます。デフォルトでは
defaultが使用され、コマンドで-a subのようにアカウントラベルを指定するとsubの中の各値が使用されます。 - ログイン情報には文字列を返す関数を指定することもできます。
-
loginフィールドの値は、$usernameのように $ で始まる場合、accountsにあるログイン情報の値に置き換えられます。
例えばコマンドでsubアカウントを指定した場合、$usernameの部分はsub_accountが、$passwordの部分はpassword2が入力されます。
📂 .vanilla-clipper ディレクトリ内の構成
📂 .vanilla-clipper
📂 pages
📂 main
📃 20190213-page1.html
︙
📂 {任意のフォルダ}
📃 20190213-page2.html
📃 20190214-page3.html
︙
📂 resources
📂 20190213
📎 {ランダムな26文字}.jpg
📎 {ランダムな26文字}.svg
︙
📂 20190214
📎 {ランダムな26文字}.woff2
︙
💎 resources.json
💎 config.js
-
📂 pages
ダウンロードしたHTMLの保存先。この中の任意のフォルダ (指定しない場合はmainフォルダ) に保存されます。 -
📂 resources
HTML に含まれる画像などの外部ファイルの保存先。yyyyMMdd形式のサブフォルダに保存されます。 -
💎 resources.json
外部ファイルの情報を保存するデータベース。ファイルのハッシュ値などを保存。 -
💎 config.js
設定ファイル。
✨ Vanilla Clipper のいいところ
- CSS は
document.styleSheetsから取得するので CSS in JS などにも対応 - CSS 内の
background-imageなどの外部ファイルも保存できる - CSS の
@importも再帰的に処理 -
@font-faceに WOFF・TTF など複数の形式を含む場合は最適なものを保存 - iframe・Shadow DOM の内容も埋め込まれる
- 外部ファイルはすでに保存されているものと一致する場合新たに保存しない
ファイルは各 URL で複数バージョン保存できるようになっています。すでに保存されているファイルとハッシュ値が一致する場合はそのまま利用され、逆に更新されている場合は新しいバージョンとして保存されるので容量を抑えることができます。
🕯️ 実装のポイント
Puppeteer と jsdom を併用する
Puppeteer で表示したページをそのまま書き換えてしまうと、その途中でページ自体のスクリプトによって変更が加えられてしまう可能性があります。そのため、Puppeteer で取得した HTML を一度 jsdom に移してから DOM 操作を行うようになっています。
ページのスクロール
スクロールしないとコンテンツが読み込まれない場合もあるので最下部まで自動でスクロールするようになっています。スクロールする要素はデフォルトでは <html> と <body> ですが -s オプションで変更できます。
スクロールが最下部に達すると 2.5 秒待機し、待機後に要素の高さが変化している場合はもう一度スクロールします。この 最下部までスクロール + 2.5 秒待機 の動作をデフォルトでは 10 回繰り返します。
CSS の最適化
Vanilla Clipper は CSS 内の url() で指定されているファイルも保存しますが、そのままだとページ内で使われていないものも保存されるのでその前に CSS を最適化しています。
- 未使用ルールの一部を削除
ルール内でurl()関数が使用され、かつそのルールがページ内で使われていない場合はルールが削除されます。 - Web フォントは最適な形式のみ保存
@font-faceで定義された Web フォントに複数の形式が含まれる場合、woff2・woffが優先して保存されます。
まとめ
ここ2年で貯まった800以上のwebページを振り分ける作業が待っている
— 𝕪𝕒𝕞𝕒𝕚𝕞𝕠 ⁽ᴵⱽᐟᵇⱽᴵᴵ⁾ (@yarnaimo) 2019年2月13日
保存したページを管理する GUI もほしいですよね…。というかこれを組み込んだ個人用ナレッジベースみたいなのを作りたいと思ってます。
ありがとうございました~ ✋
-
Windows は
C:\Users\{ユーザー名}、macOS は/Users/{ユーザー名}↩