背景
先日機会があって、awsのRedshift Query Tuning Workshopに参加させていただいたのでそのとき学んだことを活かして業務で扱うRedshiftのクエリをチューニングしてみました。この記事はその備忘録です。
(その時の資料は一般公開されているそうなので、下記の参考欄に添付しておきます)
初めに
今回のワークショップで口酸っぱく言われたことは
- 分析は時間ベースで行うこと
- システマチックにボトルネックを特定し、チューニングを行うこと
の二つです、その他にもたくさん勉強になることはありましたが誰にでも当てはまることはこの二つだと思います。
この2点を念頭において実際にどのような操作を行なったか書いていきます。
ボトルネックの特定
初めに確認するべきはクエリにおいて時間のかかっているところはどの部分か確認することです。
まず、以下のコードを実行して該当のクエリの全体にかかっている時間を把握します(詳しくはこちら )
SELECT *
FROM sys_query_history
WHERE query_id = **調査対象のクエリID**
出力されたものを一部抜粋するとこんな感じ
execution_timeを見ると23ミリ秒くらいかかってそうですね!
十分早くね?とも思いますが改善できるところはしていきたいですからね!
次に、各セグメントごとの実行時間を確認します(詳しくはこちら)
SELECT
query_id
, child_query_sequence
, stream_id
, segment_id
, step_id
, step_name
, table_id
, coalesce(table_name,'')|| coalesce(source,'') as table_name
, start_time
, end_time
, duration
, input_bytes
, output_bytes
, input_rows
, output_rows
, blocks_read
, local_read_io
, remote_read_io
, is_rrscan
, data_skewness
, time_skewness
, spilled_block_local_disk
, spilled_block_remote_disk
FROM
sys_query_detail
WHERE query_id = **調査対象のクエリID**
ORDER BY
query_id
, child_query_sequence
, stream_id
, segment_id
, step_id;
これで出力されたものはこんな感じ
inputされてる数とoutputされてる数が違ったり、data_skewnessからデータの不均衡かありそうなのがわかります
ここまででどこにどれだけ時間がかかっているのかが把握できました
原因特定
原因特定はそれぞれのケースによって異なるので、自分が行ったことを書いていきます。
まずは調査対象のクエリを先頭に
EXPLAIN
を追加して、実行計画を確認します。(詳しくはこちら)
idとかは見せることができないので微妙な感じですがこんな感じ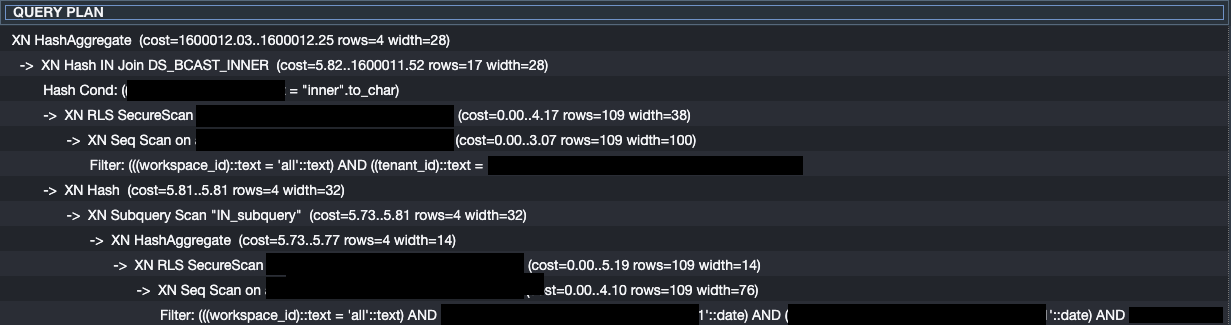
これまでの結果からデータに不均衡がありそうだと判断したため、データの分散とソートキーの効果の確認します(詳しくはこちら)
SELECT "table", diststyle, sortkey1, skew_rows, unsorted
FROM svv_table_info WHERE "table" = **調査対象のテーブル名**
結果はこんな感じ

skew_rowsは1に近いほど分散が小さく、100はかなり分散が大きいです。
unsortedはsortkeyでのソートがうまく行えていない割合なのでこの二つを改善すれば速度は速くなるはずです
改善
ここまでの調査で改善方針が定まったので実際に改善していきましょう!
まずは再ソートを行なってunsortedをなくしたいと思います。
VACUUM FULL **再ソートしたいテーブル名**
そうすると

こうなります。
ちゃんと再ソートできてそうですね!
あとはskew_rowsを小さくするために分散キーを見直します。
ALTER TABLE **分散キーを変更したいテーブル名** ALTER DISTKEY **新しい分散キー**;
クエリの中身を見せることができないので結果論になってしまいますがこうなりました!

変化なし!なんでや!?いろいろ試してみましたが今回はうまく分散キーを設定することはできませんでした…うまくできたら追記します。
結果
ではお待ちかねの結果です
再度クエリを実行して
SELECT *
FROM sys_query_history
WHERE query_id = **調査対象のクエリID**
時間を見てみると・・・

大体14ミリ秒くらいになりました!
元々23ミリ秒ほどかかっていたので、約10ミリ秒早くなりましたね、ほぼ半分です!
感想
今回はRedshiftのクエリの速度改善の一連の流れをやってみました!
色々雑になってしまった部分もありますが楽しかったです。
今回プロセスの理解のために実際にクエリエディタ上で作業をしましたが、実はボトルネックの特定まではmazon Redshift管理コンソールからGUIで確認できます… ていうか多分そっちの方がわかりやすいので、もしこの記事を見て試してみようって思う方がいたら、GUIでの確認をしてみてください。
参考