はじめに
FramePack、めっちゃ話題になってますね。
効率的に長尺の動画生成を実現するために、入力フレームを固定調のコンテキストに圧縮する、生成時に過去と未来のフレーム情報を同時に考慮する、一度に全フレームを生成するのではなく、コンテキストを参照しながら逐次生成など、いろいろな工夫がされており、低VRAMで長時間の動画生成が可能なのが特徴です。
HPでは、GUIで動画生成するツールが用意されていますが、一気に大量に生成するためにコマンドラインで動かす方法を試してみました。
Pinokioでの作業
本記事では、FramepackのインストールにPinokioというツールを使います。使い方については、過去の記事をご覧ください。アプリを起動したら、DiscoverページからFramePackを検索し、ダウンロード、インストールしてください。

インストールが終わったら、GUI画面が出るので、ここで一回動画を生成させて動作確認してください(サンプルはHPを参照)
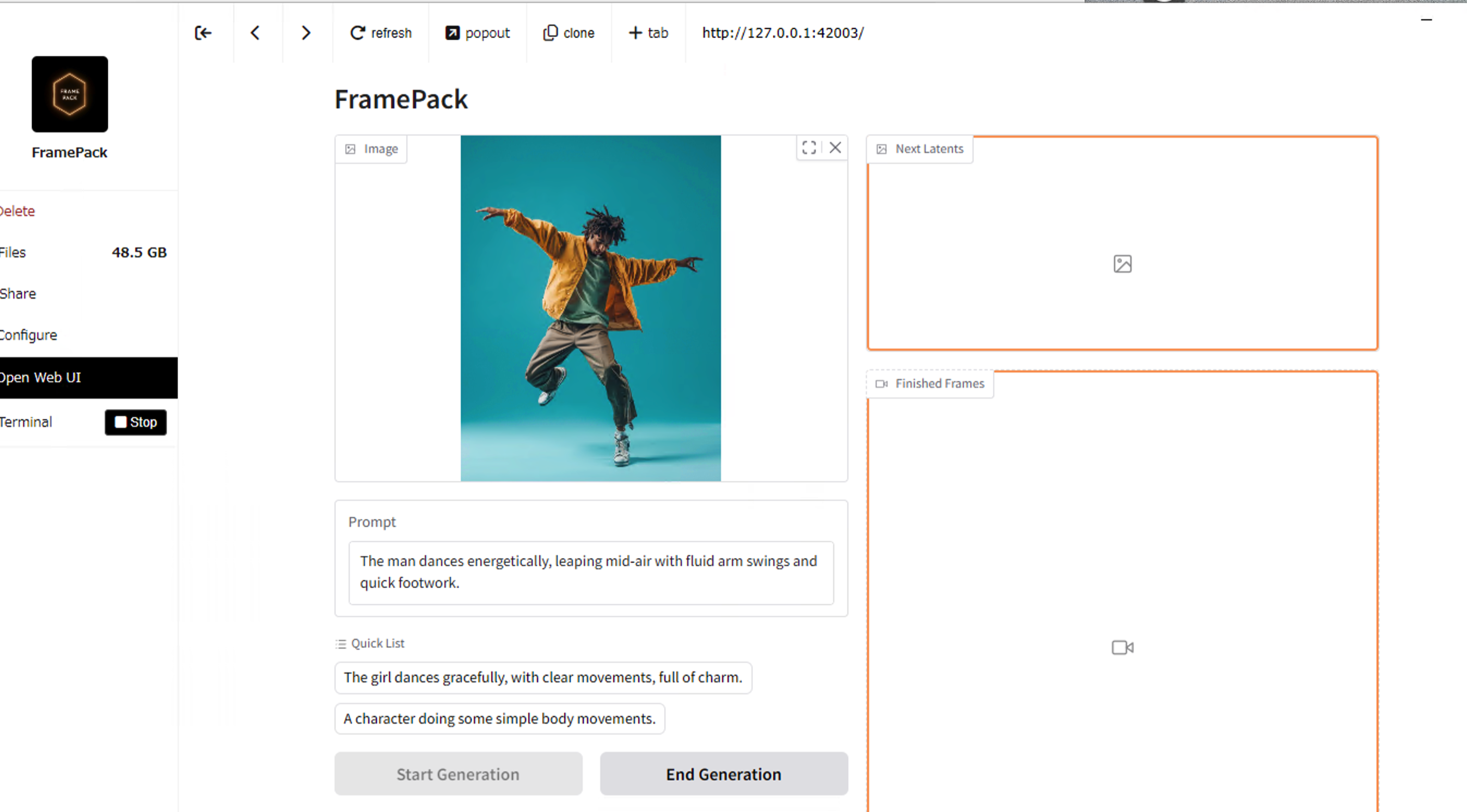
CLI実行の準備
次に管理者権限でコマンドプロンプトを開き、C:\pinokio\api\Frame-Pack.git\appへ移動しましょう。
まず、以下のコマンドを実行して仮想環境を有効にします(これは新しいコマンドプロンプトを開くごとに必要です)。
./env/Scripts/activate
(env) とプロンプトの先頭に表示され、仮想環境が有効になっていることを確認してください。
次に、必要な Python パッケージをインストールします。以下のコマンドを順に実行してください。
まず pip を更新し、devicetorch をインストールします。(これは元の requirements.txt には含まれていません)
pip install --upgrade pip
pip install devicetorch
次に、app ディレクトリにある requirements.txt ファイルを使って基本的な依存関係(gradio, diffusers, transformers など)をインストールします。
pip install -r requirements.txt
(任意) 高速化のための追加ライブラリ:
実行速度を向上させるために、xformers と flash-attn のインストールが推奨されます。
pip install xformers
pip install https://huggingface.co/lldacing/flash-attention-windows-wheel/resolve/main/flash_attn-2.7.4%2Bcu126torch2.6.0cxx11abiFALSE-cp310-cp310-win_amd64.whl?download=true
注意: flash-attn は特定の CUDA/PyTorch/Python バージョン (CUDA 12.6, PyTorch 2.6.0, Python 3.10) 向けにビルドされています。環境が異なる場合は、公式ドキュメントを参照して適切なバージョンをインストールするか、ソースからビルドする必要があります。
さらに、以下のライブラリも検討できます。
pip install triton-windows
pip install https://github.com/deepbeepmeep/SageAttention/raw/refs/heads/main/releases/sageattention-2.1.0-cp310-cp310-win_amd64.whl
(注意: SageAttention は flash-attn や xformers と機能が重複する可能性があります。また、triton-windows の必要性は環境によります。)
次に、以下のスクリプトをappフォルダにコピーしてください。
import os
os.environ['HF_HOME'] = os.path.abspath(os.path.realpath(os.path.join(os.path.dirname(__file__), './hf_download')))
import torch
import traceback
import einops
import numpy as np
import argparse
import math
from PIL import Image
from diffusers import AutoencoderKLHunyuanVideo
from transformers import LlamaModel, CLIPTextModel, LlamaTokenizerFast, CLIPTokenizer
from diffusers_helper.hunyuan import encode_prompt_conds, vae_decode, vae_encode, vae_decode_fake
from diffusers_helper.utils import save_bcthw_as_mp4, crop_or_pad_yield_mask, soft_append_bcthw, resize_and_center_crop, generate_timestamp
from diffusers_helper.models.hunyuan_video_packed import HunyuanVideoTransformer3DModelPacked
from diffusers_helper.pipelines.k_diffusion_hunyuan import sample_hunyuan
from diffusers_helper.memory import cpu, gpu, get_cuda_free_memory_gb, move_model_to_device_with_memory_preservation, offload_model_from_device_for_memory_preservation, fake_diffusers_current_device, DynamicSwapInstaller, unload_complete_models, load_model_as_complete
from transformers import SiglipImageProcessor, SiglipVisionModel
from diffusers_helper.clip_vision import hf_clip_vision_encode
from diffusers_helper.bucket_tools import find_nearest_bucket
def parse_args():
parser = argparse.ArgumentParser(description="Generate video from image and prompt using FramePack.")
parser.add_argument('--image_path', type=str, required=True, default="C:\\Users\\vzb10\\Pictures\\Screenshots\\enami1.png", help='Path to the input image.')
parser.add_argument('--prompt', type=str, required=True, default="男が壁に聞き耳を立てている様子", help='Text prompt describing the desired video content.')
parser.add_argument('--output_dir', type=str, default='./outputs/', help='Directory to save the output video and intermediate files.')
parser.add_argument('--n_prompt', type=str, default="", help='Negative text prompt.')
parser.add_argument('--seed', type=int, default=31337, help='Random seed for generation.')
parser.add_argument('--total_second_length', type=float, default=5.0, help='Total length of the video in seconds.')
parser.add_argument('--latent_window_size', type=int, default=9, help='Latent window size (should not change).')
parser.add_argument('--steps', type=int, default=25, help='Number of sampling steps.')
parser.add_argument('--cfg', type=float, default=1.0, help='CFG Scale (should not change).')
parser.add_argument('--gs', type=float, default=10.0, help='Distilled CFG Scale.')
parser.add_argument('--rs', type=float, default=0.0, help='CFG Re-Scale (should not change).')
parser.add_argument('--gpu_memory_preservation', type=float, default=6.0, help='GPU memory preservation in GB.')
parser.add_argument('--use_teacache', action='store_true', default=True, help='Use TeaCache for potentially faster generation.')
parser.add_argument('--no_teacache', action='store_false', dest='use_teacache', help='Do not use TeaCache.')
args = parser.parse_args()
return args
@torch.no_grad()
def worker(input_image, prompt, n_prompt, seed, total_second_length, latent_window_size, steps, cfg, gs, rs, gpu_memory_preservation, use_teacache, outputs_folder, high_vram, text_encoder, text_encoder_2, tokenizer, tokenizer_2, vae, feature_extractor, image_encoder, transformer):
total_latent_sections = (total_second_length * 30) / (latent_window_size * 4)
total_latent_sections = int(max(round(total_latent_sections), 1))
job_id = generate_timestamp()
output_filename_final = None
print("Starting video generation...")
try:
# Clean GPU
if not high_vram:
unload_complete_models(
text_encoder, text_encoder_2, image_encoder, vae, transformer
)
# Text encoding
print("Text encoding ...")
if not high_vram:
fake_diffusers_current_device(text_encoder, gpu)
load_model_as_complete(text_encoder_2, target_device=gpu)
llama_vec, clip_l_pooler = encode_prompt_conds(prompt, text_encoder, text_encoder_2, tokenizer, tokenizer_2)
if cfg == 1:
llama_vec_n, clip_l_pooler_n = torch.zeros_like(llama_vec), torch.zeros_like(clip_l_pooler)
else:
llama_vec_n, clip_l_pooler_n = encode_prompt_conds(n_prompt, text_encoder, text_encoder_2, tokenizer, tokenizer_2)
llama_vec, llama_attention_mask = crop_or_pad_yield_mask(llama_vec, length=512)
llama_vec_n, llama_attention_mask_n = crop_or_pad_yield_mask(llama_vec_n, length=512)
# Processing input image
print("Image processing ...")
input_image_np = np.array(input_image)
H, W, C = input_image_np.shape
height, width = find_nearest_bucket(H, W, resolution=640)
input_image_np = resize_and_center_crop(input_image_np, target_width=width, target_height=height)
Image.fromarray(input_image_np).save(os.path.join(outputs_folder, f'{job_id}_input.png'))
input_image_pt = torch.from_numpy(input_image_np).float() / 127.5 - 1
input_image_pt = input_image_pt.permute(2, 0, 1)[None, :, None]
# VAE encoding
print("VAE encoding ...")
if not high_vram:
load_model_as_complete(vae, target_device=gpu)
start_latent = vae_encode(input_image_pt, vae)
# CLIP Vision
print("CLIP Vision encoding ...")
if not high_vram:
load_model_as_complete(image_encoder, target_device=gpu)
image_encoder_output = hf_clip_vision_encode(input_image_np, feature_extractor, image_encoder)
image_encoder_last_hidden_state = image_encoder_output.last_hidden_state
# Dtype
llama_vec = llama_vec.to(transformer.dtype)
llama_vec_n = llama_vec_n.to(transformer.dtype)
clip_l_pooler = clip_l_pooler.to(transformer.dtype)
clip_l_pooler_n = clip_l_pooler_n.to(transformer.dtype)
image_encoder_last_hidden_state = image_encoder_last_hidden_state.to(transformer.dtype)
# Sampling
print("Start sampling ...")
rnd = torch.Generator("cpu").manual_seed(seed)
num_frames = latent_window_size * 4 - 3
history_latents = torch.zeros(size=(1, 16, 1 + 2 + 16, height // 8, width // 8), dtype=torch.float32).cpu()
history_pixels = None
total_generated_latent_frames = 0
latent_paddings = reversed(range(total_latent_sections))
if total_latent_sections > 4:
latent_paddings = [3] + [2] * (total_latent_sections - 3) + [1, 0]
for i, latent_padding in enumerate(latent_paddings):
is_last_section = latent_padding == 0
latent_padding_size = latent_padding * latent_window_size
print(f"Generating section {i+1}/{total_latent_sections} (padding={latent_padding}, last={is_last_section})...")
# print(f'latent_padding_size = {latent_padding_size}, is_last_section = {is_last_section}')
indices = torch.arange(0, sum([1, latent_padding_size, latent_window_size, 1, 2, 16])).unsqueeze(0)
clean_latent_indices_pre, blank_indices, latent_indices, clean_latent_indices_post, clean_latent_2x_indices, clean_latent_4x_indices = indices.split([1, latent_padding_size, latent_window_size, 1, 2, 16], dim=1)
clean_latent_indices = torch.cat([clean_latent_indices_pre, clean_latent_indices_post], dim=1)
clean_latents_pre = start_latent.to(history_latents)
clean_latents_post, clean_latents_2x, clean_latents_4x = history_latents[:, :, :1 + 2 + 16, :, :].split([1, 2, 16], dim=2)
clean_latents = torch.cat([clean_latents_pre, clean_latents_post], dim=2)
if not high_vram:
unload_complete_models()
move_model_to_device_with_memory_preservation(transformer, target_device=gpu, preserved_memory_gb=gpu_memory_preservation)
if use_teacache:
transformer.initialize_teacache(enable_teacache=True, num_steps=steps)
else:
transformer.initialize_teacache(enable_teacache=False)
def callback(d):
current_step = d['i'] + 1
percentage = int(100.0 * current_step / steps)
print(f" Sampling Step: {current_step}/{steps} ({percentage}%)", end='\r')
# No preview generation needed for CLI
return
generated_latents = sample_hunyuan(
transformer=transformer,
sampler='unipc',
width=width,
height=height,
frames=num_frames,
real_guidance_scale=cfg,
distilled_guidance_scale=gs,
guidance_rescale=rs,
num_inference_steps=steps,
generator=rnd,
prompt_embeds=llama_vec,
prompt_embeds_mask=llama_attention_mask,
prompt_poolers=clip_l_pooler,
negative_prompt_embeds=llama_vec_n,
negative_prompt_embeds_mask=llama_attention_mask_n,
negative_prompt_poolers=clip_l_pooler_n,
device=gpu,
dtype=torch.bfloat16,
image_embeddings=image_encoder_last_hidden_state,
latent_indices=latent_indices,
clean_latents=clean_latents,
clean_latent_indices=clean_latent_indices,
clean_latents_2x=clean_latents_2x,
clean_latent_2x_indices=clean_latent_2x_indices,
clean_latents_4x=clean_latents_4x,
clean_latent_4x_indices=clean_latent_4x_indices,
callback=callback,
)
print() # Newline after step progress
if is_last_section:
generated_latents = torch.cat([start_latent.to(generated_latents), generated_latents], dim=2)
total_generated_latent_frames += int(generated_latents.shape[2])
history_latents = torch.cat([generated_latents.to(history_latents), history_latents], dim=2)
if not high_vram:
offload_model_from_device_for_memory_preservation(transformer, target_device=gpu, preserved_memory_gb=8)
load_model_as_complete(vae, target_device=gpu)
real_history_latents = history_latents[:, :, :total_generated_latent_frames, :, :]
print(" Decoding latents...")
if history_pixels is None:
history_pixels = vae_decode(real_history_latents, vae).cpu()
else:
section_latent_frames = (latent_window_size * 2 + 1) if is_last_section else (latent_window_size * 2)
overlapped_frames = latent_window_size * 4 - 3
current_pixels = vae_decode(real_history_latents[:, :, :section_latent_frames], vae).cpu()
history_pixels = soft_append_bcthw(current_pixels, history_pixels, overlapped_frames)
if not high_vram:
unload_complete_models()
output_filename_final = os.path.join(outputs_folder, f'{job_id}.mp4') # Use a consistent final name
print(f" Saving video segment to {output_filename_final}...")
save_bcthw_as_mp4(history_pixels, output_filename_final, fps=30)
print(f" Decoded. Current latent shape {real_history_latents.shape}; pixel shape {history_pixels.shape}")
if is_last_section:
break
except Exception as e:
traceback.print_exc()
print(f"Error during generation: {e}")
finally:
if not high_vram:
print("Unloading models...")
unload_complete_models(
text_encoder, text_encoder_2, image_encoder, vae, transformer
)
print("Video generation finished.")
return output_filename_final
if __name__ == "__main__":
args = parse_args()
print("Arguments:")
for k, v in vars(args).items():
print(f" {k}: {v}")
print("\nInitializing...")
free_mem_gb = get_cuda_free_memory_gb(gpu)
high_vram = free_mem_gb > 60
print(f'Free VRAM {free_mem_gb} GB')
print(f'High-VRAM Mode: {high_vram}')
# Load Models
print("Loading models...")
text_encoder = LlamaModel.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder='text_encoder', torch_dtype=torch.float16).cpu()
text_encoder_2 = CLIPTextModel.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder='text_encoder_2', torch_dtype=torch.float16).cpu()
tokenizer = LlamaTokenizerFast.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder='tokenizer')
tokenizer_2 = CLIPTokenizer.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder='tokenizer_2')
vae = AutoencoderKLHunyuanVideo.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder='vae', torch_dtype=torch.float16).cpu()
feature_extractor = SiglipImageProcessor.from_pretrained("lllyasviel/flux_redux_bfl", subfolder='feature_extractor')
image_encoder = SiglipVisionModel.from_pretrained("lllyasviel/flux_redux_bfl", subfolder='image_encoder', torch_dtype=torch.float16).cpu()
transformer = HunyuanVideoTransformer3DModelPacked.from_pretrained('lllyasviel/FramePackI2V_HY', torch_dtype=torch.bfloat16).cpu()
print("Models loaded.")
# Configure Models
vae.eval()
text_encoder.eval()
text_encoder_2.eval()
image_encoder.eval()
transformer.eval()
if not high_vram:
vae.enable_slicing()
vae.enable_tiling()
transformer.high_quality_fp32_output_for_inference = True
# print('transformer.high_quality_fp32_output_for_inference = True') # Less verbose
transformer.to(dtype=torch.bfloat16)
vae.to(dtype=torch.float16)
image_encoder.to(dtype=torch.float16)
text_encoder.to(dtype=torch.float16)
text_encoder_2.to(dtype=torch.float16)
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
text_encoder_2.requires_grad_(False)
image_encoder.requires_grad_(False)
transformer.requires_grad_(False)
if not high_vram:
print("Installing dynamic swap for low VRAM...")
DynamicSwapInstaller.install_model(transformer, device=gpu)
DynamicSwapInstaller.install_model(text_encoder, device=gpu)
else:
print("Moving models to GPU (High VRAM)...")
text_encoder.to(gpu)
text_encoder_2.to(gpu)
image_encoder.to(gpu)
vae.to(gpu)
transformer.to(gpu)
os.makedirs(args.output_dir, exist_ok=True)
# Load Input Image
print(f"Loading input image from: {args.image_path}")
try:
input_image = Image.open(args.image_path).convert('RGB')
except FileNotFoundError:
print(f"Error: Input image not found at {args.image_path}")
exit(1)
except Exception as e:
print(f"Error loading image: {e}")
exit(1)
# Run Worker
final_video_path = worker(
input_image=input_image,
prompt=args.prompt,
n_prompt=args.n_prompt,
seed=args.seed,
total_second_length=args.total_second_length,
latent_window_size=args.latent_window_size,
steps=args.steps,
cfg=args.cfg,
gs=args.gs,
rs=args.rs,
gpu_memory_preservation=args.gpu_memory_preservation,
use_teacache=args.use_teacache,
outputs_folder=args.output_dir,
high_vram=high_vram,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
vae=vae,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
transformer=transformer
)
if final_video_path:
print(f"\nSuccessfully generated video: {final_video_path}")
else:
print("\nVideo generation failed.")
以下のスクリプトで実行します。画像のpathとプロンプトは適宜変えてください。
python run.py --image_path ./sample.jpg --prompt "The man dances energetically, leaping mid-air with fluid arm swings and quick footwork."
うまくいけば、outputsフォルダに生成された動画が保存されます。

ここまでうまくいけば、あとはスクリプトで動画を大量生産するだけです。例えば、下のスクリプトはサンプルの画像からスタートして、1つの感情をテーマにした動画を作ったら、その最後のフレームから次の動画を作る、ということで5種類の感情を連続的に表現しました。
import subprocess
import os
import time
import sys
import cv2 # Import OpenCV
import shutil # To clean up temporary file if needed
# --- Settings ---
initial_image_path = "./test.jpg" # Starting image for the first prompt
base_output_dir = "continuous" # Single output directory
emulate_script_path = "run.py" # Assuming it's in the same directory (app)
video_segment_length_seconds = 5.0 # Desired length for each segment
last_frame_temp_filename = "_last_frame_for_next_step.png" # Temporary file for the last frame
# Dictionary of emotions and prompts - Order matters now!
# Using a list of tuples to guarantee order explicitly
prompts_ordered = [
("joy", "The man dances with joyful energy, spinning lightly and clapping his hands with a big smile"),
("anger", "The man stomps with force, arms cutting through the air sharply in an angry rhythm"),
("sadness", "The man moves slowly and fluidly, arms drooping as he spins with a somber expression"),
("surprise", "The man jolts upright mid-dance, arms flaring outward in a startled motion, then quickly steps back"),
("excitement", "The man bursts into rapid footwork and high jumps, pumping his fists with excitement"),
]
# Create the base output directory if it doesn't exist
os.makedirs(base_output_dir, exist_ok=True)
# Get the path to the Python executable in the current environment
python_executable = sys.executable
print(f"Using Python executable: {python_executable}")
print(f"Base output directory: {os.path.abspath(base_output_dir)}")
sys.stdout.flush() # Flush initial messages
# --- Execution Loop ---
current_image_path = initial_image_path # Start with the initial image
last_generated_video_path = None # Keep track of the last video
for i, (emotion, prompt_text) in enumerate(prompts_ordered):
print(f"\n===== Starting generation {i}: {emotion} =====")
print(f"Prompt: {prompt_text}")
print(f"Using input image: {current_image_path}")
# Determine the output video filename
output_video_filename = f"{i:02d}_{emotion}.mp4"
output_video_path = os.path.join(base_output_dir, output_video_filename)
print(f"Output video: {output_video_path}")
# Construct the command using the environment's Python
command = [
python_executable,
emulate_script_path,
"--image_path", current_image_path, # Use the current image path
"--prompt", f'"{prompt_text}"',
"--output_dir", base_output_dir, # Output to the main directory
"--total_second_length", str(video_segment_length_seconds), # Set video length
# Add other arguments here if needed, e.g.:
# "--seed", "42",
]
# Note: run.py needs to save the video with a predictable name
# or we need to modify it. Assuming it saves ONE .mp4 in the output_dir.
# Let's modify the command to potentially include the specific output filename
# if run.py supports it, otherwise we'll rely on finding the
# latest mp4 file in the directory. For now, let's assume run.py
# saves a uniquely named file (like job_id.mp4) in the output_dir.
print(f"Executing command: {' '.join(command)}") # Log the command
sys.stdout.flush() # Flush before starting subprocess output
generated_video_this_step = None # Reset for this step
# Run the command and stream output
try:
start_time = time.time()
# Use Popen to stream output in real-time
process = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT, # Redirect stderr to stdout
text=True,
encoding='utf-8',
errors='replace', # Replace characters that cannot be decoded
bufsize=1, # Line buffered
cwd=os.path.dirname(__file__) or '.' # Ensure execution in app directory
)
print("--- run.py output (streaming) ---")
sys.stdout.flush() # Flush before streaming
process_output_lines = []
# Read and print output line by line, storing it
while True:
line = process.stdout.readline()
if not line:
break
stripped_line = line.strip()
print(stripped_line) # Print the line to the console
process_output_lines.append(stripped_line) # Store for later parsing
sys.stdout.flush() # Ensure each line from subprocess is flushed
process.wait() # Wait for the process to complete
end_time = time.time()
if process.returncode == 0:
print(f"----- Subprocess finished successfully -----")
print(f"Duration: {end_time - start_time:.2f} seconds")
sys.stdout.flush()
# --- Find the generated video ---
# Option 1: Parse output from run.py (if it prints the filename)
# This is more robust if run.py prints a specific line like "Successfully generated video: ..."
found_path = None
for line in reversed(process_output_lines):
# Adjust this marker based on run.py's actual success message
marker = "Successfully generated video:"
if marker in line:
found_path = line.split(marker)[-1].strip()
# Ensure the path exists and is relative to the base_output_dir or absolute
if not os.path.isabs(found_path):
found_path = os.path.join(base_output_dir, os.path.basename(found_path)) # Make path relative to script execution? No, base_output_dir
if os.path.exists(found_path):
generated_video_this_step = found_path
print(f"Parsed generated video path: {generated_video_this_step}")
break
else:
print(f"Warning: Parsed path '{found_path}' does not exist. Falling back to directory scan.")
found_path = None # Reset if path doesn't exist
# Option 2: Fallback - Find the most recently created MP4 file in the output directory
if not generated_video_this_step:
print("Parsing failed or video not found in output, trying directory scan...")
try:
list_of_files = [os.path.join(base_output_dir, f) for f in os.listdir(base_output_dir) if f.lower().endswith(".mp4")]
if list_of_files:
generated_video_this_step = max(list_of_files, key=os.path.getctime)
print(f"Found most recent video via scan: {generated_video_this_step}")
else:
print(f"Error: No MP4 files found in {base_output_dir} after generation.")
# Decide how to handle: stop or continue? Let's stop for now.
raise FileNotFoundError(f"No MP4 file found in {base_output_dir}")
except Exception as scan_e:
print(f"Error scanning directory {base_output_dir}: {scan_e}")
raise scan_e # Propagate error
# Rename the found video to the desired sequential name
final_video_path = os.path.join(base_output_dir, output_video_filename)
if os.path.abspath(generated_video_this_step) != os.path.abspath(final_video_path):
print(f"Renaming {generated_video_this_step} to {final_video_path}")
try:
shutil.move(generated_video_this_step, final_video_path)
last_generated_video_path = final_video_path
except Exception as move_e:
print(f"Error renaming video: {move_e}")
# Decide how to proceed, maybe stop?
raise move_e
else:
print("Generated video already has the correct name.")
last_generated_video_path = final_video_path
# --- Extract last frame for next iteration ---
if i < len(prompts_ordered) - 1: # Only if it's not the very last prompt
print(f"Extracting last frame from: {last_generated_video_path}")
try:
cap = cv2.VideoCapture(last_generated_video_path)
if not cap.isOpened():
raise IOError(f"Cannot open video file: {last_generated_video_path}")
# Get frame count (may be inaccurate for some formats)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
last_frame_index = frame_count - 1
print(f"Total frames (approx): {frame_count}")
if last_frame_index < 0:
raise ValueError("Video appears to have no frames.")
# --- Method 1: Seek to the end (faster but potentially less reliable) ---
# cap.set(cv2.CAP_PROP_POS_FRAMES, last_frame_index)
# ret, last_frame = cap.read()
# if not ret:
# print("Warning: Seeking to last frame failed. Trying frame-by-frame reading.")
# # Fallback to Method 2
# --- Method 2: Read all frames (slower but more reliable) ---
last_frame = None
frame_read_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
last_frame = frame
frame_read_count += 1
cap.release()
if last_frame is None:
raise ValueError(f"Could not read any frames or the last frame from {last_generated_video_path}. Frames read: {frame_read_count}")
# Save the last frame
next_input_image_path = os.path.join(base_output_dir, last_frame_temp_filename)
cv2.imwrite(next_input_image_path, last_frame)
print(f"Last frame saved to: {next_input_image_path}")
current_image_path = next_input_image_path # Update for the next loop
except Exception as frame_e:
print(f"----- Error extracting last frame for: {emotion} -----")
print(f"Error: {frame_e}")
print("Cannot continue without the last frame. Stopping.")
sys.stdout.flush()
raise frame_e # Stop the script
else:
# Raise an error if the process failed (will be caught below)
raise subprocess.CalledProcessError(process.returncode, command)
except subprocess.CalledProcessError as e:
print(f"\n----- Error during generation for: {emotion} -----")
print(f"Return code: {e.returncode}")
print(f"Command failed: {' '.join(e.cmd)}")
print("Stopping the script due to generation error.")
sys.stdout.flush()
break # Stop the loop on error
except FileNotFoundError as e:
print(f"Error: {e}")
print("Please ensure Python, scripts, and necessary files are accessible.")
sys.stdout.flush()
break # Stop if essential files are missing
except KeyboardInterrupt: # Catch KeyboardInterrupt specifically
print("\n" + "#"*10 + f" Process interrupted by user during generation for: {emotion} " + "#"*10)
sys.stdout.flush()
print("Stopping the script.")
break # Stop the loop if interrupted
except Exception as e:
print(f"\n----- An unexpected error occurred for: {emotion} -----")
import traceback
traceback.print_exc()
print("Stopping the script due to unexpected error.")
sys.stdout.flush()
break # Stop the loop on unexpected error
# --- Cleanup ---
final_temp_frame_path = os.path.join(base_output_dir, last_frame_temp_filename)
if os.path.exists(final_temp_frame_path):
try:
os.remove(final_temp_frame_path)
print(f"\nCleaned up temporary file: {final_temp_frame_path}")
except Exception as clean_e:
print(f"\nWarning: Could not clean up temporary file {final_temp_frame_path}: {clean_e}")
print("\n===== Continuous generation finished or script stopped =====")
sys.stdout.flush() # Flush final message
おわりに
やっぱり、ローカルで作れるって良いですよね。色々工夫した使い方ができそうなので、また記事で取り上げてみたいです。