はじめに
SQL Server Big Data Cluster(BDC)は、SQL Server 2019の非常に期待されている機能です。そもそも、BDCは何ですか、また、それらの機能を最大限に活用するにはどうすればよいですか。このような疑問を持っている方もいらっしゃると思います。ここで少し深く掘り下げて説明していきます。
Reference URLs
SQL Server Big Data Clusterとは
SQL Server Big Data Cluster展開の概要
@kenakamuによるSQL Server 2019 ビッグデータクラスターを AKS で使う - azdata 既定の構成でインストール
Microsoft workshop on BDC Architecture
Masayuki Ozawa's Blog SE雑記
Big Data Clusters Overview presented by Buck Woody at SQLBits 2019
Pluralsight Course by Ben Weissman
Anthony Nocentino’s Blog
Mohammad Darab’s Blog
Bob Pusateri's Blog
SQL Server Big Data Clusterの由来
SQL Server 2017がLinuxのサポートを追加された時に、SQL ServerをSpark、HDFS、および通常はLinuxベースであるその他のビッグデータツールと統合するための基礎が築かれました。SQL Server 2019のBig Data Clusterは、これらの統合の可能性を提供し、リレーショナルデータとビッグデータの両方を簡単に組み合わせて分析できるようにします。
SQL Server Big Data Clusterとは
Big Data Clusterは、SQL Server 2019のPolyBaseの拡張機能を活用して、外部テーブルを介した様々なソースからのデータの仮想化を可能にします。外部テーブルを使用すると、ローカルSQL Serverインスタンスに物理的に配置されていないデータをあたかも存在するかのようにクエリしたり、ローカルテーブルに結合してシームレスな結果セットを生成したりすることができるようになります。それは、PolyBaseというテクノロジーを利用しています。PolyBaseに関しては、Japan SQL Server User Groupの過去の勉強会のセッションで何度も紹介したこともあります。リモートSQL Serverインスタンス、Azure SQL Database、Azure Cosmos DB、MySQL、PostgreSQL、MongoDB、Oracle、およびその他の多くのソースからのデータはすべて、PolyBase外部テーブルを介してアクセスできます。Big Data Clusterでは、SQL ServerエンジンはHDFSの組み込みサポートも備えており、これらすべてのデータセットを結合できるため、リレーショナルデータと非リレーショナルデータの両方を簡単に統合できます。
Apache Spark統合
Big Data ClusterはPolyBase外部テーブルを利用するだけではなく、Apache SparkはBig Data Clusterにも深く統合されているため、データサイエンティストやエンジニアは、スケーラブルな分散メモリ内のコンピューティングレイヤーでデータにアクセスして操作できます。つまり、データの活用では、機械学習、AI、その他の分析タスクにも使用できます。
Big Data Clusterの機能
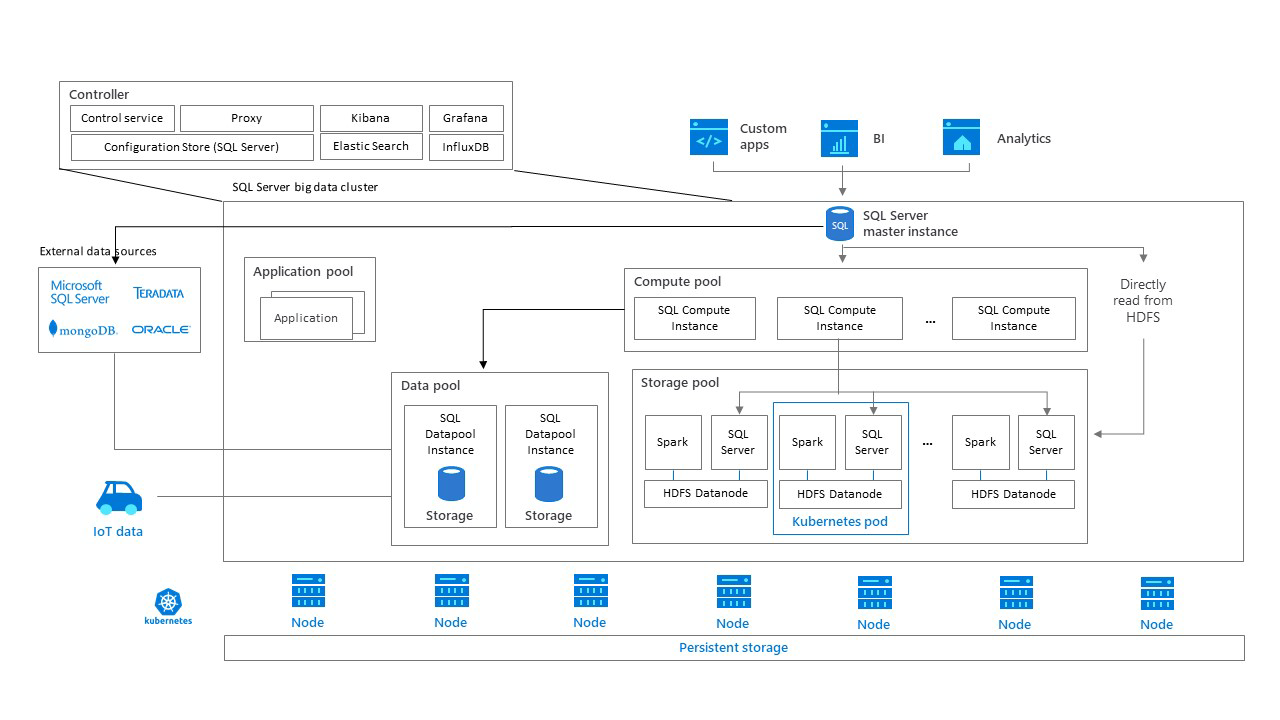
アーキテクチャから言えば、Big Data Clusterはコンテナーのクラスター(Dockerコンテナーなど)です。これらのスケーラブルなクラスターは、SQL Server、Spark、HDFS、およびその他のサービスを実行します。Big Data Clusterのすべての側面はコンテナー内で実行され、これらのコンテナーはすべて、コンテナーオーケストレーションサービスであるKubernetesによって管理されます。Podと呼ばれるコンテナのグループは、Big Data Clusterの主要コンポーネントを構成するプールにグループ化されます。
主な機能を理解するために、下記のコンポーネント(用語)を先に説明します。
Master Instance
SQL Server Big Data Cluster Master Instanceとは
SQLクエリのメイン接続エンドポイントとして機能し、メタデータと読み取り、または書き込みユーザーデータベースをBDCに格納するSQL Server2019インスタンスです。データベースのバックアップをBDCに復元する場合、これもターゲットになります。HAの目的では、これは可用性グループにすることもできます。
Data Pool
SQL Server Big Data Cluster Data Poolとは
データセットをシャーディングできるSQL Serverインスタンスのコレクションであり、頻繁にアクセスされるデータのスケールアウトクエリ機能を可能にします。これは、そうでなければマスターインスタンスに存在する大きなテーブルを格納する場合に非常に役立ちます。また、複数の外部データソースを結合する複雑なクエリの結果をキャッシュするのに最適な場所です。
動画
Storage Pool
SQL Server Big Data Cluster Storage Poolとは
HDFS、Spark、SQLServerをホストするスケーラブルなストレージ層。列構造のテキスト(parquet)や区切りテキストなどの非構造化および半構造化データファイルをここに保存し、SQL Server外部テーブルまたはHDFSに接続できるその他のツールを介してアクセスできます。
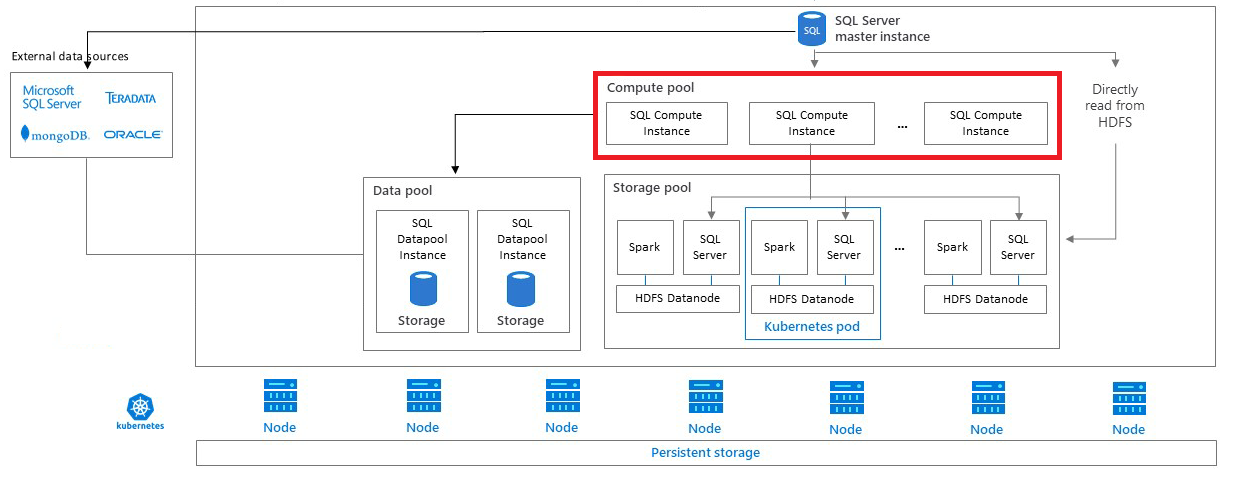
Compute Pool
SQL Server Big Data Cluster Compute Poolとは
Data PoolまたはStorage Poolにアクセスする必要があるMaster Instanceからのクエリを分散する(worker的な役割)ことで、スケールアウト処理を可能にするSQL Server Compute Nodeのコレクション(集合体)です。Compute Poolには、エンドユーザーが直接アクセスすることはありません。
動画
Application Pool
SQL Server Big Data Cluster Application Poolとは
R、Python、SSIS、およびMLeapランタイムを使用するアプリケーションがBig Data Clusterで実行され、そのデータと計算リソースにアクセスできるようにする一連のインターフェイスです。
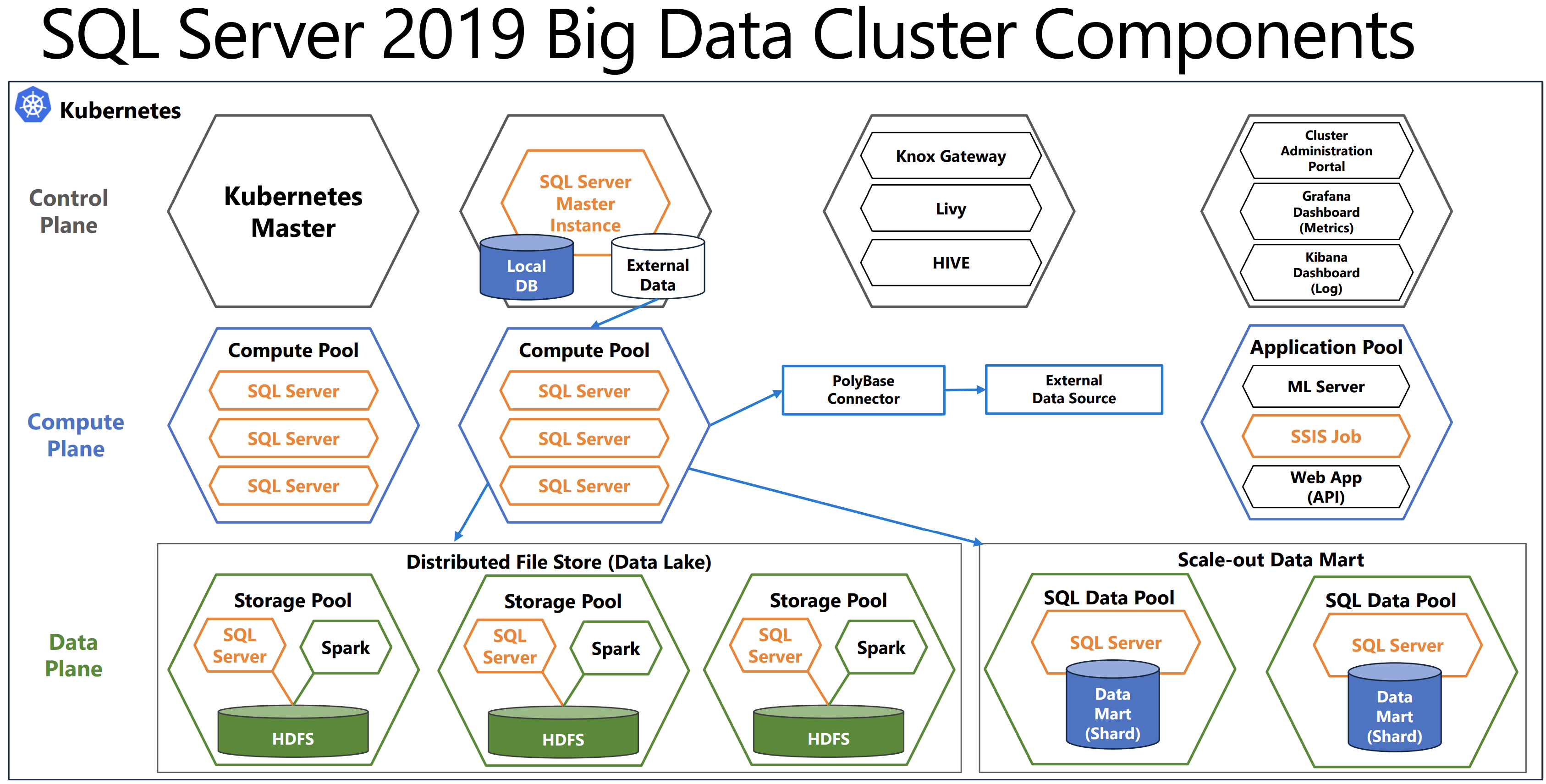
図からわかるように、Big Data Clusterには、クラスターとそのコンポーネントを監視および管理するためのWebサービスや、Big Data Clusterを管理するためのCLIであるazdataなど、他のいくつかのコンポーネントが含まれています。
Azure Data Studioを使ってSQL Server Big Data Clusterにアクセスする
GUIの使用を好む人にとって、Azure Data Studio(ADS)はBig Data Clusterの管理において重要な役割を果たすことができます。ADSを使用すると、SQL Serverタスクに加えて、Big Data Clusterの作成と管理、ファイルのアップロードとダウンロードなどのHDFSタスクの実行、ウィザードによる外部テーブルの作成、T-SQL、Spark、Pythonノートブックの実行などを行うことができます。確かに必須ではありませんが、Azure Data Studioは、で多くの一般的なBig Data Clusterタスクを実行するのに最適な環境です。
Azure Data Studio Download
SQL Server Big Data Clusterユースケース
小売業者のデータウェアハウスを管理することを想定してください。トランザクションデータは、店舗の場所やWebサイトから定期的に受信されます。DWH内の一部のデータは確実にリレーショナルであり、そのように保存する必要があります。但し、毎日に区切られたテキストファイルを介して配信される数百万数のトランザクションはそうではありません。つまり、毎回に保存したり、ETLしたりすると、余計なコストがかかります。
ETLプロセスを使用して、このすべてのデータをリレーショナルデータベースにロードすることもできますが、複雑さが増し、維持する別のプロセスが作成され、実行に時間もかかります。SQL Server Big Data Clusterを活用すると、トランザクションの「Big Data」をネイティブ形式で保存し、さらに処理することなく分析できるようになります。そして、他のSQLクエリと同じように、物理テーブルと仮想テーブルを結合することで、リレーショナルデータとBig Dataの両方を組み合わせることができます。最後に、Big Dataは、Spark、R、またはHDFSに保存されているデータにアクセスできるその他のアプリケーションで分析もできるようになります。
- SQL Server Big Data Clusterはデータの入力、変換、出力、分析までの一気通貫できるSQL Server 2019ベースのプラットフォームです。
SQL Server Big Data Clusterシナリオ
SQL Server Data Clusterによって提供される柔軟性により、多くのユースケースが可能になりますが、最も一般的なシナリオは下記です。
- リレーショナルデータや非リレーショナルデータからBig Dataの組み合わせ、または何れの組み合わせ
- データ仮想化によるデータへの即時アクセス(リアルタイム要件)
- 重複することなくSQL ServerとSparkの両方を介して同じデータをクエリする機能
- Microsoft Azure内、他のパブリッククラウド、またはオンプレミスにデプロイできる一貫性のあるソリューション
SQL Server Big Data Clusterのまとめ
SQL Server Big Data Clusterはデータの入力、変換、出力、分析までの一気通貫できるSQL Server 2019ベースのプラットフォームです。
SQL Serverビッグデータクラスターは、Microsoft Data Platformへの非常に歓迎された革新的な追加であり、SQL Serverの機能を構築し、信じられないほどの柔軟性とスケーラビリティを提供します。
この度、ぜひSQL Server 2019 Big Data Clusterを利用してみたらいかがでしょうか。
SQL Serverの導入及び相談を承ります。