はじめに
Azure Synapse Analytics Dedicated SQL Poolはワークロードグループ管理機能を利用すると、よりリソースの管理やコントロールができるようになりますので、うまく利用することで、Azureコストダウン効果も出ます。
Reference URLs
ワークロード管理とは
Azure Synapse Analytics の専用 SQL プールのワークロード分類 (Video)
Azure Synapse Analytics ワークロードの重要度(Video)
Azure Synapse Analytics ワークロード グループ分離
Azure Synapse Analytics - ワークロード管理ポータル監視
Azure Synapse Analytics の専用 SQL プールのメモリおよびコンカレンシーの制限
ワークロードグループを利用するシナリオ
- Azure Synapse Analytics Dedicated SQL Poolへのデータのロード
- Azure Synapse Analytics Dedicated SQL Poolのデータを使って、分析とレポート作成
- Azure Synapse Analyticsのデータの管理
- Azure Synapse Analyticsのデータのエクスポート
リソースクラスの存在チェック
ワークロードグループを作成する前に、リソースクラスマッピングの定義が存在するかどうかの確認してください。
存在する場合、リソースクラスマッピングを削除する必要があります。リソースクラスマッピングを利用していない場合、直接ワークロードグループを作成します。
リソースクラスは論理的な推奨事項とパターンの使用法としては、より優れた並行性を得るために、スケールアップ時に静的リソースグループを使用します。
同時実行性をあまり必要としない複雑でリソースを大量に消費するクエリをスケールアップするときに動的リソースグループを使用します。
但し、ワークロードグループはリソースクラスマッピングより進化された技術(ユーザーをリソースクラスの変更は不要になる)で、ワークロードグループを使用することを推奨します。
つまり、リソースクラス(静的クラス、動的クラス)はワークロードグループへシフトするため、ワークロードグループを使用する場合、リソースクラスマッピングを使用しないということです。
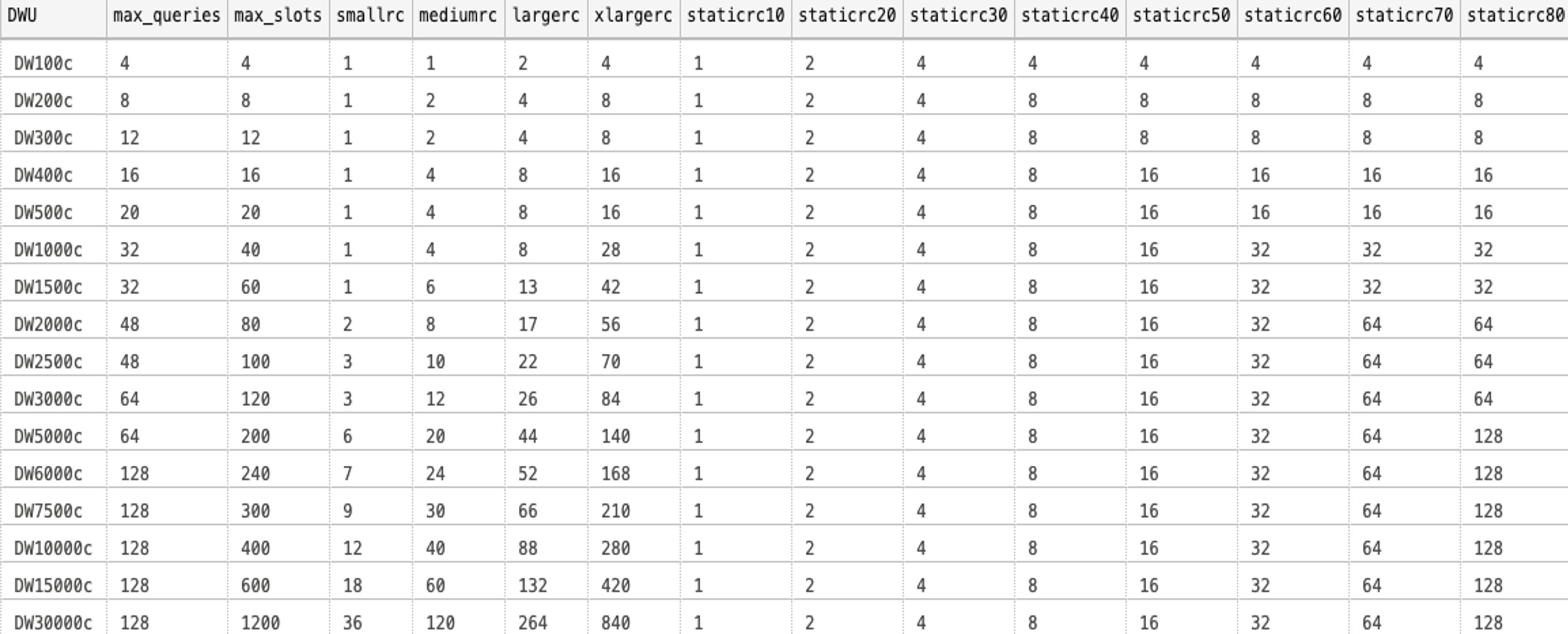
DWUごとのリソースクラスの配分です。(静的、動的)
手順
全体的な流れとしては、
①リソースクラスマッピング存在確認
②リソースクラスマッピング削除
③ワークロードグループの作成
④ワークロードグループにユーザーをマッピング
⑤ワークロードグループにラベリングを行う
このような5ステップになります。
今回の記事は主に、③であるワークロードグループの作成をフォーカスして、説明していきます。
ワークロードグループ定義
AzureポータルでAzure SQL Serverユーザーがすべての権限レベルで強力であり、非常に制限されていることを意味するため、デフォルトでは、各ユーザーは動的リソースクラスsmallrcのメンバーで、サービス管理者のリソースクラスはsmallrcに固定されており、変更できません。そのため、ワークロードグループを使うように、ユーザーを分ける必要があります。
設計の際に、どういったユーザーからAzure Synapse Analyticsに接続しに来るのか、そして、それらのユーザーがアクセスするデータ量などの要件を含めて、把握する必要があります。
実際、ワークロードグループを作成するために、下記のSQL構文を利用しますが、それぞれのパラメータをすべて理解しないといけません。
CREATE WORKLOAD GROUP group_name
[ WITH
( [ MIN_PERCENTAGE_RESOURCE = value ]
[ [ , ] CAP_PERCENTAGE_RESOURCE = value ]
[ [ , ] REQUEST_MIN_RESOURCE_GRANT_PERCENT = value ]
[ [ , ] REQUEST_MAX_RESOURCE_GRANT_PERCENT = value ]
[ [ , ] IMPORTANCE = { LOW | BELOW_NORMAL | NORMAL | ABOVE_NORMAL | HIGH } ]
[ [ , ] QUERY_EXECUTION_TIMEOUT_SEC = value ] )
[ ; ]
]
SQLステートメント以外に、Azureポータル、UIからも操作できます。
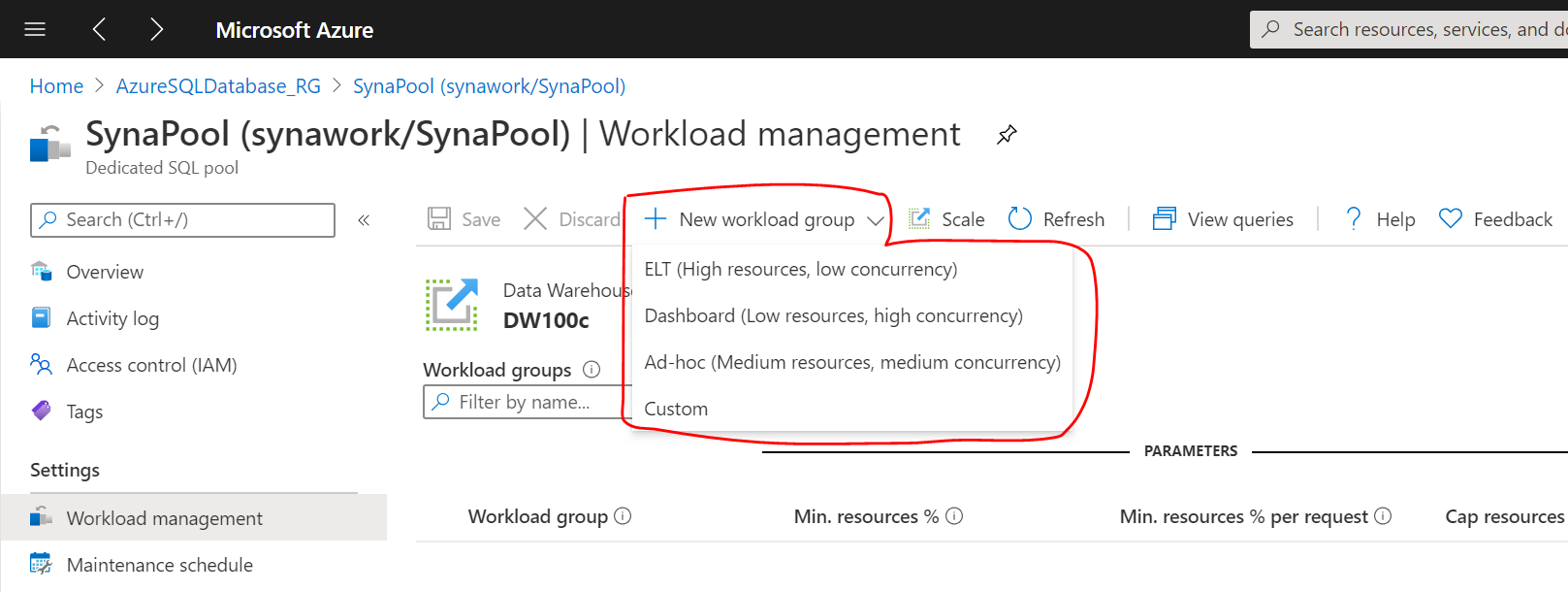
既存にいくつかサンプルがありますが、要件次第ですが、実際はカスタムで、構成します。
- ワークロードグループリソース配分するためのパラメータの理解する必要があります。とても重要ですから、下記の各パラメータの説明を読んでいただければと思います。
MIN_PERCENTAGE_RESOURCE
- 最小リソース%
- ワークロードグループを作成時に必須項目
独自のカスタムリソースグループで使用できる最小の保証されたリソースの割合を定義し、値は0〜100の整数である必要があります。
複数のワークロードグループを定義する場合、MIN_PERCENTAGE_RESOURCE値の合計、この値は100を超えることはできません。
この値はCAP_PERCENTAGE_RESOURCE(上限リソース%)の値を考慮し、それよりも低くする必要があります。
注意点として、選択した階層に応じて、定義の有効な最小値と最大値が適用されます。
REQUEST_MIN_RESOURCE_GRANT_PERCENT
- 要求ごとの最小リソース%
- ワークロードグループを作成時に必須項目
各リクエストに割り当てられるリソースの最小量を定義します。
値は0.75から100.00の間の変数であり、これは使用する階層に定義されたクエリの最大数に依存し、0.25の倍数である必要があります。
たとえば、DW500cを使用している場合、並列クエリの絶対最大数は20に制限されます。つまり、カスタムワークロードグループの絶対最小値は5%に設定する必要があり、DW1000c/DW1500cを使用している場合は、最大32の並列クエリなので、REQUEST_MIN_RESOURCE_GRANT_PERCEN(要求ごとの最小リソース%)の最大値は3%に制限されます。
計算式= 100.00 / [max_queries]
必要に応じて、より低い値を確実に使用できるが、常に0.25の倍数であり、0.75の値を下回ることは許可されていません。
REQUEST_MAX_RESOURCE_GRANT_PERCENT
- 要求ごとの最大リソース%
これらのリソースが要求時に利用可能である場合、リクエストごとの最大リソースの割合を定義します。
REQUEST_MIN_RESOURCE_GRANT_PERCENT(要求ごとの最小リソース%)より高くする必要があります。
IMPORTANCE
- 重要度
- {LOW | BELOW_NORMAL | NORMAL | ABOVE_NORMAL | HIGH}
デフォルト値は通常はNORMALに設定されています。空きリソースの状況を見て、優先に実行します。
分かりやすく説明するために、一つサンプルを見ていきます。

サービスレベルとしてDW200cを使用している場合、8つの同時クエリが実行されており、他のすべてがキューで待機し、FIFOロジックが発生する順番を待っています。
つまり、Q9を実行するには、Q1〜Q8のいずれかが完了している必要があり、Q10を実行するには、実行しているものの1つが完了している必要があります。
これは、スケジューラが行ったプロセスであり、重要性を使用せずに、これまでも続けています。
この分類子で定義された重要度を使用して、その動きは変わるようになります。
たとえば、Q12の分類子の重要度が高く、Q9〜Q11の方が低い場合、Q1〜Q8のいずれかが完了すると、スケジューラは他のクエリよりも優先度が高いため、クエリを実行します。
ロックと重要度の関係もあるため、すべてのクエリが同じ重みを持つ重要度を使用する前に、Q4がテーブルなどをロックした場合、それは優れた読み取り操作を実行し、Q9はデータのロードまたは同じテーブルでのパーティション切り替えなどで、その他の書き込み操作を実行する必要がありました。Q4が完了するまで待つことになります。
問題は、すでに実行中のクエリが複数あり、同じテーブルを別のリソースにロックしているパターンだと、Q4とQ6が同じテーブルにロックを持っている場合、Q9はそれらが完了するまでキューで待機する必要があります。
Q6が完了する前にQ4が完了すると、実行中のクエリに空きが残り、Q10でカバーされることも妥当で、ただし、Q10もテーブルにロックされている場合、Q6が完了してもQ9は起動できません。
今度は、Q6がQ11に置き換えられ、テーブルもロックするとします。できるだけ早くQ9を実行する可能性はありません。Q9の作業が重要である場合でも、実際に優先されないことがわかります。
結論を言いますと、重要度を高く設定しても、ロックなどの関係で、どうしても優先実行されないパターンもあります。
QUERY_EXECUTION_TIMEOUT_SEC
- 実行完了までのタイムアウト時間
実行が完了していない場合にクエリがタイムアウトする最大秒数を定義します。
デフォルトは0で、タイムアウトしないことを意味します。
このカウントは、クエリの実行が開始されるとアクティブになり、キューにある間ではなく、ピックアップされるのを待機しています。
QUERY_WAIT_TIMEOUT_SEC
- クエリ待機タイムアウト時間
(sys.workload_management_workload_groups)DMVで確認でき、クエリが待機される最大の時間を定義します。
デフォルトは0で、タイムアウトしないことを意味します。
保証されるコンカレンシーと共有プールの計算式
[保証されるコンカレンシー] = [MIN_PERCENTAGE_RESOURCE]/[REQUEST_MIN_RESOURCE_GRANT_PERCENT]
[共有プール] = 100-[すべてのワークロード グループにおける MIN_PERCENTAGE_RESOURCE の合計]
集中データロードタイムとAdHocタイムのモードの切り替え設計
Azure Synapse Analytics Dedicated SQL Poolにデータロードの要件次第で、ワークロードグループでリソース配分を変えたいニーズはきっとあると思います。
その場合、ALTER WORKLOAD GROUP (Transact-SQL)を使って、ワークロードグループの値を変更します。ちなみに、Azureポータル、UIからも変更できます。
ALTER WORKLOAD GROUP { group_name | "default" }
[ WITH
([ IMPORTANCE = { LOW | MEDIUM | HIGH } ]
[ [ , ] REQUEST_MAX_MEMORY_GRANT_PERCENT = value ]
[ [ , ] REQUEST_MAX_CPU_TIME_SEC = value ]
[ [ , ] REQUEST_MEMORY_GRANT_TIMEOUT_SEC = value ]
[ [ , ] MAX_DOP = value ]
[ [ , ] GROUP_MAX_REQUESTS = value ] )
]
[ USING { pool_name | "default" } ]
[ ; ]
- CONTROL SERVER権限が必要です。要注意です。
下記は、パラメータで、対象のワークロードグループを変更するAzure Synapse Analytics Dedicated SQL Poolのストアドプロシージャのサンプルです。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[usp_SQLPoolChangeWorkLoadGroup]
@strWorkLoadGroupName [NVARCHAR](50),
@intMIN_PERCENTAGE_RESOURCE [INT],
@intCAP_PERCENTAGE_RESOURCE [INT],
@intREQUEST_MIN_RESOURCE_GRANT_PERCENT [INT],
@intREQUEST_MAX_RESOURCE_GRANT_PERCENT [INT],
@strIMPORTANCE [NVARCHAR](50),
@intQUERY_EXECUTION_TIMEOUT_SEC [INT]
AS
BEGIN
SET NOCOUNT ON
DECLARE @strSQLCode NVARCHAR(4000) = N''
DECLARE @strIsErr INT = 0
--重要度チェック
IF ISNULL(TRIM(@strIMPORTANCE),'') NOT IN ('LOW','BELOW_NORMAL','NORMAL','ABOVE_NORMAL','HIGH')
BEGIN
SET @strIsErr = 1
RAISERROR('IMPORTANCE contains an invalid value.',11,1)
END
--WorkLoadGroup存在チェック
IF NOT EXISTS(
SELECT 1
FROM sys.workload_management_workload_groups
WHERE [name] = @strWorkLoadGroupName)
BEGIN
SET @strIsErr = 1
RAISERROR('WorkLoadGroupName does not exist.',11,1)
END
IF @@ERROR = 0 AND @strIsErr = 0
BEGIN
SET @strSQLCode = 'ALTER WORKLOAD GROUP'
+ SPACE(1) + QUOTENAME(@strWorkLoadGroupName)
+ SPACE(1) + 'WITH'
+ SPACE(1) + '('
+ SPACE(1) + 'MIN_PERCENTAGE_RESOURCE = ' + TRY_CONVERT(NVARCHAR(3),@intMIN_PERCENTAGE_RESOURCE) + ','
+ SPACE(1) + 'CAP_PERCENTAGE_RESOURCE = ' + TRY_CONVERT(NVARCHAR(3),@intCAP_PERCENTAGE_RESOURCE) + ','
+ SPACE(1) + 'REQUEST_MIN_RESOURCE_GRANT_PERCENT = ' + TRY_CONVERT(NVARCHAR(3),@intREQUEST_MIN_RESOURCE_GRANT_PERCENT) + ','
+ SPACE(1) + 'REQUEST_MAX_RESOURCE_GRANT_PERCENT = ' + TRY_CONVERT(NVARCHAR(3),@intREQUEST_MAX_RESOURCE_GRANT_PERCENT) + ','
+ SPACE(1) + 'IMPORTANCE = ' + @strIMPORTANCE + ','
+ SPACE(1) + 'QUERY_EXECUTION_TIMEOUT_SEC = ' + TRY_CONVERT(NVARCHAR(3),@intQUERY_EXECUTION_TIMEOUT_SEC)
+ SPACE(1) + ')'
EXEC SP_EXECUTESQL @strSQLCode
IF @@ERROR != 0
BEGIN
RAISERROR('{Your Error Message}',11,1)
END
END
END
ストアドプロシージャを定義できた後に、呼び出す側のSQLコードを用意します。
DECLARE @strMsg NVARCHAR(4000) = N''
BEGIN TRY
EXEC [dbo].[usp_SQLPoolChangeWorkLoadGroup] '{WorkLoadGroupName}',{Parameter},{Parameter},{Parameter},{Parameter},'{Parameter}',{Parameter}
END TRY
BEGIN CATCH
SELECT @strMsg = ERROR_MESSAGE()
SELECT ERROR_NUMBER() AS ErrorNumber,ERROR_SEVERITY() AS ErrorSeverity,ERROR_STATE() AS ErrorState,ERROR_PROCEDURE() AS ErrorProcedure,ERROR_MESSAGE() AS ErrorMessage
RAISERROR(@strMsg,11,1)
END CATCH
IF @@ERROR = 0 AND ISNULL(@strMsg,'') = ''
BEGIN
SELECT 'Changed the WorkLoadGroup settings.'
END
その呼び出す側はAzure Data Factory V2のPipelineでも、該当プロセスをコントロールするツールを入れ込めばいいです。
ちなみに、Azure Data Factory V2を使う場合、ストアドプロシージャというアクティビティを使ってもいいですし、LoopUpアクティビティを使って、スクリプトを埋め込んでもいいわけです。
Azure Synapse Analytics Dedicated SQL Pool Workload groupsのまとめ
今回、ユーザーマッピングとラベリングの内容を触れていないですが、ワークロードグループを使うための第1歩とするポイントは、ワークロードグループのパラメータの理解だと思います。
Azure Synapse Analytics Dedicated SQL Poolを使っている方は、ワークロードグループで、リソースコントロールすることで、Dedicated SQL Poolの最大限に利用でき、うまく使えば、無駄な使い(課金)は無くすことができます。
昔は、リソースクラスでしたが、今はワークロードグループです!リソースクラスより進化されています。

この度、ぜひAzure Synapse Analytics Dedicated SQL Pool Workload groupsを利用してみたらいかがでしょうか。
Azure Synapse Analytics、またSQL Serverの導入及び相談を承ります。