対象
- エクセルが(宗教上)嫌いな人
- なんでもRで片付けたい人
はじめに
まず前提として、以下のようなエクセルファイルがあったとします。
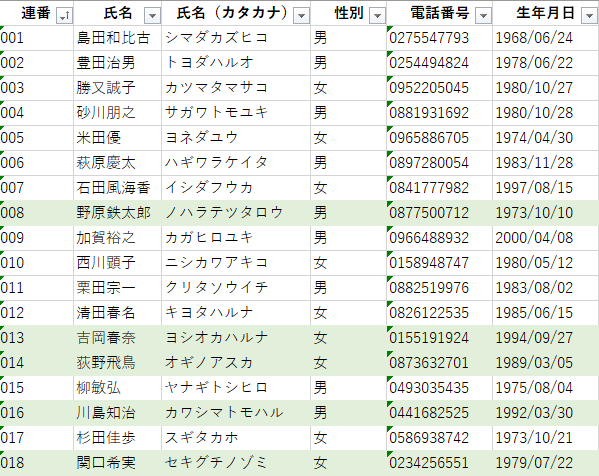
ちなみにこのデータは疑似個人情報データ生成サービスというWebサイトで作成しました。
この中で、色で塗りつぶされているセルだけを抽出して、データの解析を行いたいとします。Excel職人の方は「んなもんフィルタ掛けて「色で並べ替え」をクリックすればできるやん」と言うかもしれません。確かに言った通りのことをすればできるのですが、あのリボンの中からフィルタの項目探すの結構大変です(私だけ?)。さらに言えばシートの数が多かったり複数のエクセルでこれをいちいち手でやるのはメンドクサイ。マクロ組むなんてもっとメンドクサイ。
そんな方に朗報。この操作、Rでもできます。
tidyxl
エクセルシートを読み込むためのパッケージとして、{tidyxl}というものがあります。「{tidyxl}? {readxl}ちゃうんか?」と思うかもしれませんが、別物です。
インストールは例のごとくinstall.packages("tidyxl")。
{tidyxl}でエクセルファイルを読み込む関数に**xlsx_cells()**があります。{readxl}におけるread_excel()ですね。
この挙動を見てみましょう。
library(tidyxl)
tidyxl::xlsx_cells("Sample_data.xlsx")
# A tibble: 1,206 x 21
sheet address row col is_blank data_type error logical numeric date character
<chr> <chr> <int> <int> <lgl> <chr> <chr> <lgl> <dbl> <dttm> <chr>
1 Sheet1 A1 1 1 FALSE character NA NA NA NA 連番
2 Sheet1 B1 1 2 FALSE character NA NA NA NA 氏名
3 Sheet1 C1 1 3 FALSE character NA NA NA NA 氏名(カタカナ)
4 Sheet1 D1 1 4 FALSE character NA NA NA NA 性別
5 Sheet1 E1 1 5 FALSE character NA NA NA NA 電話番号
6 Sheet1 F1 1 6 FALSE character NA NA NA NA 生年月日
7 Sheet1 A2 2 1 FALSE character NA NA NA NA 008
8 Sheet1 B2 2 2 FALSE character NA NA NA NA 野原鉄太郎
9 Sheet1 C2 2 3 FALSE character NA NA NA NA ノハラテツタロウ
10 Sheet1 D2 2 4 FALSE character NA NA NA NA 男
# ... with 1,196 more rows, and 10 more variables: character_formatted <list>, formula <chr>, is_array <lgl>,
# formula_ref <chr>, formula_group <int>, comment <chr>, height <dbl>, width <dbl>, style_format <chr>,
# local_format_id <int>
少し様子が違うことに気づいたでしょうか?そうです、この関数は各セルの情報(シート番号、アドレス、書いてある内容 etc...)を一つの行で格納しているのです。
各セルのフォーマットについてはidが振られており、変数$local_format_idでアクセスすることができます。
cells <- tidyxl::xlsx_cells("Sample_data.xlsx")
cells$local_format_id[1:10] #長いので一部を抜粋
> cells$local_format_id[1:10]
[1] 4 4 5 4 4 4 9 9 9 9
1番目からA1, B1, C1,...のセルの書式について数字が振られています。A1 ~ F1までの書式がボールド体である一方、A2から通常の書式になっているので番号が大きく変わっています。しかしこれだけでは、「どのセルが塗りつぶされたセルか」がわかりません。そこで、同じパッケージ内にある関数**xlsx_formats()**を使います。
公式曰く、
Cell formatting is returned by xlsx_formats(). ~(中略)~
To look up the local formatting of a given cell, take the cell's local_format_id value (my_cells$Sheet1[1, "local_format_id"]), and use it as an index into the format structure. E.g. to look up the font size, my_formats$local$font$size[local_format_id]. To see all available formats, type str(my_formats$local).
(DeepL訳:セルの書式設定はxlsx_formats()で返されます。これらは、xlsx_formats()の$styleサブリストと$localサブリストで返され、構造は同じです。あるセルのローカルな書式を調べるには、そのセルのlocal_format_id 値 (my_cells$Sheet1[1, "local_format_id"]) を取り、それを書式構造のインデックスとして使用します。例えば、フォントサイズを調べるにはmy_formats$local$font$size[local_format_id]と入力します。利用可能なすべてのフォーマットを見るには、str(my_formats$local)と入力します。)
とあります。ちょっと何言ってるかわからないと思うので噛み砕いて説明します。
まずxlsx_formats()を使うと、各セルの全ての書式情報(フォントのサイズや色、罫線の有無、背景色 etc...)。が格納されたオブジェクト(リスト)が生成されます。先程、cells$local_format_idで得られた番号が割り当てられるということを話しましたが、実際にはxlsx_formats()によって割り当てる番号を決定していることになります。
セルの背景色については変数$local$fill$patternFill$fgColor$rgb[変数$local_format_id]でアクセスすることができます。
つまり、
cells <- tidyxl::xlsx_cells("Sample_data.xlsx")
formats <- xlsx_formats("Sample_data.xlsx")
formats$local$fill$patternFill$fgColor$rgb[cells$local_format_id][1:50]
> formats$local$fill$patternFill$fgColor$rgb[cells$local_format_id][1:50]
[1] NA NA NA NA NA NA
[7] NA NA NA NA NA NA
[13] NA NA NA NA NA NA
[19] NA NA NA NA NA NA
[25] NA NA NA NA NA NA
[31] NA NA NA NA NA NA
[37] NA NA NA NA NA NA
[43] NA NA NA NA NA NA
[49] "FF70AD47" "FF70AD47"
これで背景色の情報を得ることができました!見てみると多くはNA(背景色なし)ですが、
FF70AD47というデータがあります。これが今回探している背景色のカラーコードです。
ここまで来れば後は簡単!
local_format_idの中で"FF70AD47"というカラーコードになっている行をフィルターすれば背景色のあるセルのみを抽出できます。
cells %>%
filter(
local_format_id %in% which(formats$local$fill$patternFill$fgColor$rgb == "FF70AD47")
)
# A tibble: 210 x 21
sheet address row col is_blank data_type error logical numeric
<chr> <chr> <int> <int> <lgl> <chr> <chr> <lgl> <dbl>
1 Sheet1 A9 9 1 FALSE character NA NA NA
2 Sheet1 B9 9 2 FALSE character NA NA NA
3 Sheet1 C9 9 3 FALSE character NA NA NA
4 Sheet1 D9 9 4 FALSE character NA NA NA
5 Sheet1 E9 9 5 FALSE character NA NA NA
6 Sheet1 F9 9 6 FALSE character NA NA NA
7 Sheet1 A14 14 1 FALSE character NA NA NA
8 Sheet1 B14 14 2 FALSE character NA NA NA
9 Sheet1 C14 14 3 FALSE character NA NA NA
10 Sheet1 D14 14 4 FALSE character NA NA NA
# ... with 200 more rows, and 12 more variables: date <dttm>,
# character <chr>, character_formatted <list>, formula <chr>,
# is_array <lgl>, formula_ref <chr>, formula_group <int>,
# comment <chr>, height <dbl>, width <dbl>, style_format <chr>,
# local_format_id <int>
A9からのtibbleになっていることから、正しく背景色のあるセルだけを選択できています。解析の際には、これをtidy dataに直せば良いのでRのみでセル抽出→データ解析ができるようになります。また、「背景色がある」という条件だけでいいのであれば、filter()の条件式を!= "NA"と記述することでも同様の結果が得られます。
(pivot_wider()やselect()については多くの記事があるので割愛)
pacman::p_load(
tidyverse,
readxl,
here,
tidyxl
)
col_names_excel <- read_excel("Sample_data.xlsx") %>% colnames() # もともとの列名を保存
cells <- tidyxl::xlsx_cells("Sample_data.xlsx") # セルの情報を取得
formats <- xlsx_formats("Sample_data.xlsx") # セルの書式情報を取得
df <-
cells %>%
filter(
local_format_id %in% which(formats$local$fill$patternFill$fgColor$rgb != "NA")
) %>%
select(row, col, character) %>%
pivot_wider(
names_from = col,
values_from = character
) %>% select(!row)
colnames(df) <- col_names_excel
> df
# A tibble: 35 x 6
連番 氏名 `氏名(カタカナ)` 性別 電話番号 生年月日
<chr> <chr> <chr> <chr> <chr> <chr>
1 008 野原鉄太郎 ノハラテツタロウ 男 0877500712 1973/10/10
2 013 吉岡春奈 ヨシオカハルナ 女 0155191924 1994/09/27
3 014 荻野飛鳥 オギノアスカ 女 0873632701 1989/03/05
4 016 川島知治 カワシマトモハル 男 0441682525 1992/03/30
5 018 関口希実 セキグチノゾミ 女 0234256551 1979/07/22
6 022 猪俣遥華 イノマタハルカ 女 0192956110 1971/03/30
7 024 三宅穂乃佳 ミヤケホノカ 女 0189808393 1971/12/07
8 025 野呂千春 ノロチハル 女 0883007604 1969/01/31
9 031 小森実 コモリミノル 男 0990693955 1970/09/21
10 037 持田麗奈 モチダレナ 女 0451228474 1996/06/15
# ... with 25 more rows
おわりに
今回の記事では「色で塗りつぶされたセルを抽出する」ということにフォーカスをしました。しかし、この方法を応用することで「フォントがbold体になっているセル」や「コメントの入っているセル」の抽出も可能になります。
割とクセがありますが一度関数化してしまえば反復処理もできるので非常に良いパッケージと言えるのではないでしょうか。