
スマートフォーマッティングできっと幸せになれる
- どうゆうこと?
AIが音声を文字に起こしてくれる。いい時代になりました!
リアルタイムで音声がテキストになる様子は何度見てもワクワク・ドキドキするものです。
しかし、WatsonのSpeech-to-Textって、何故か数字を漢数字に変換してくれちゃいます。
「東京オリンピックの開会式は二千二十年七月二十四日の十九時三十分です」
とか表示されても、「え?いつだよ」となりますよね。できれば
「東京オリンピックの開会式は2020年7月24日の19時30分です」
と表示されて欲しいものです。
![]() 開催時刻はデタラメですので悪しからず...
開催時刻はデタラメですので悪しからず...
- 無理なの?
ハイ、できます。
漢数字(二千二十)をアラビア数字(2020)に変換してくれる機能、が組み込まれています。
それがスマートフォーマッティングです。ただし位置付けはまだベータ機能です。(注1)
- 日付や時刻の他にも
日付や時刻の他にも、連続する数字、電話番号、通貨の値、EメールやWebサイトのアドレスがサポートされるとあります。(注1)
サポートされる言語は、英語、スペイン語そして日本語です。
Watson APIの日本語サポート率は他の言語に比べて高いんですよ!
Speech-to-Text以外のAPIに置いても、日本語は"ほぼ"フルサポートです。
早速、確認
- こちらのデモアプリで確認できます
https://speech-to-text-demo.ng.bluemix.net/
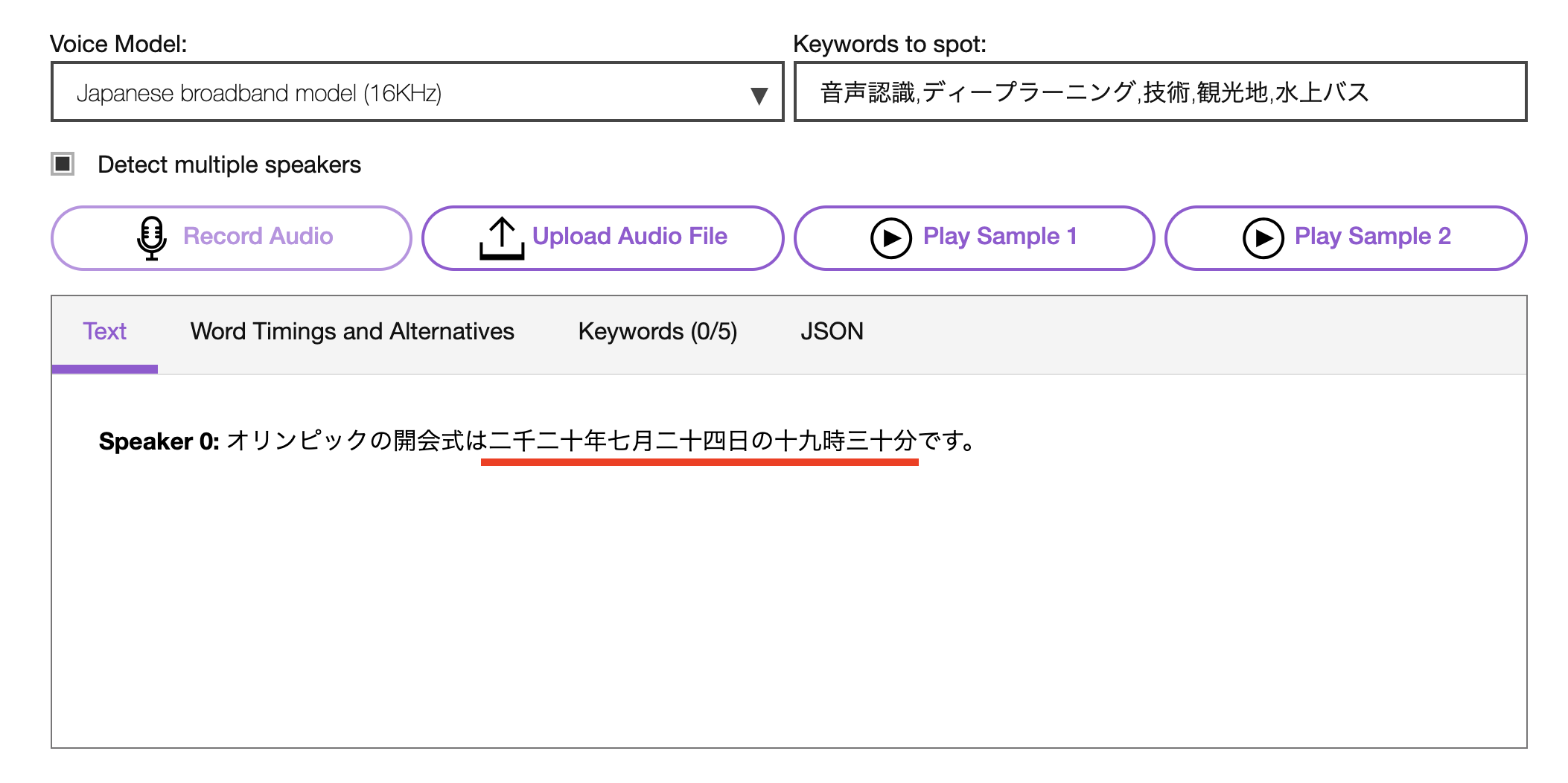
え!相変わらず、漢数字のままだって?
画面中央付近の『ここ』をOFFにしてみてください。

それではもう一度...
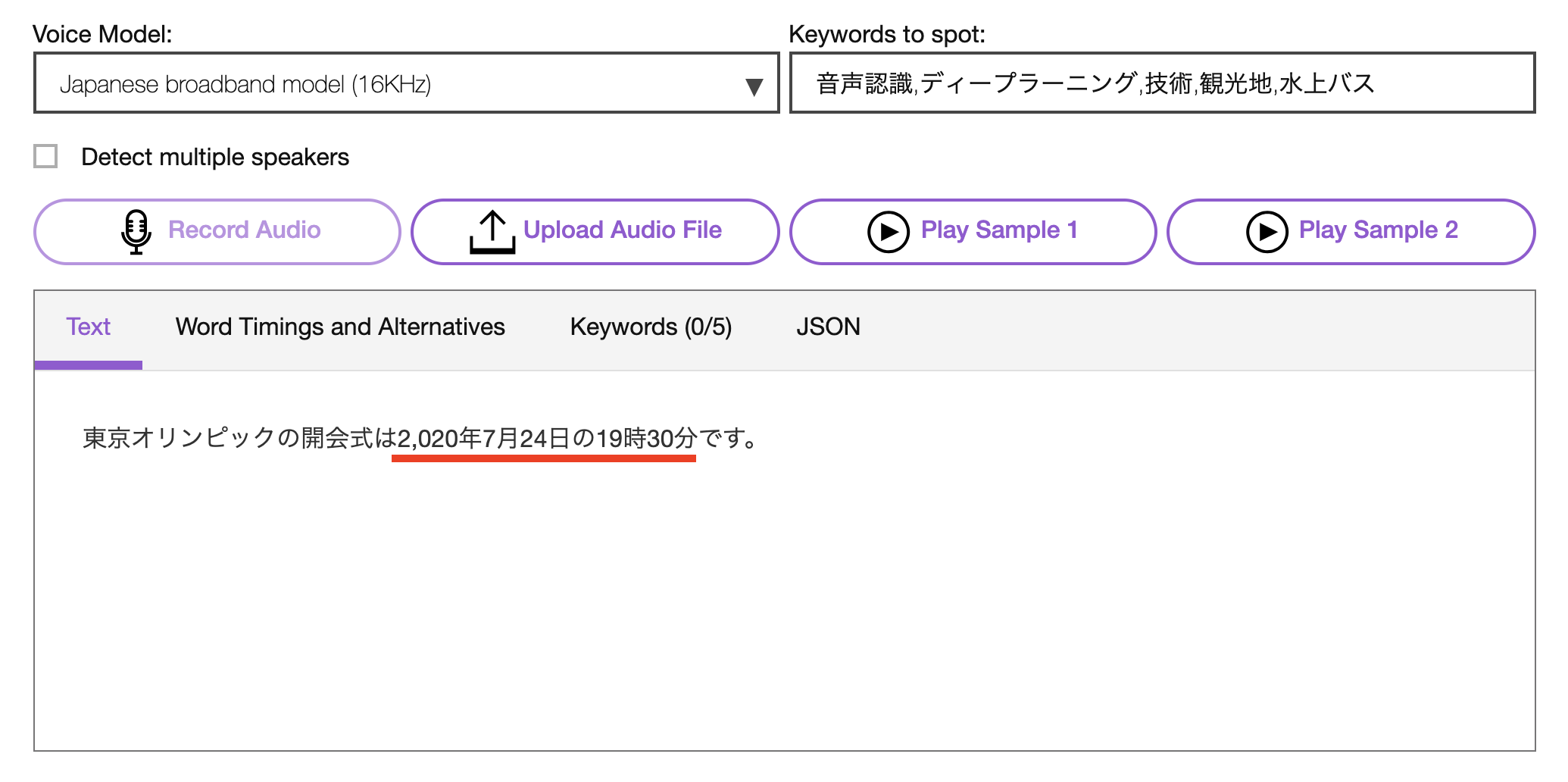
コマンドラインから試したい場合は、こちらです。
実行
curl -X POST -u apikey:YOURKEY --header 'Content-Type: audio/mp3' --data-binary @yourfile.mp3 'https://stream.watsonplatform.net/speech-to-text/api/v1/recognize?model=ja-JP_BroadbandModel&smart_formatting=true'
・YOURKEYに自分のAPI_KEYをセットしてください。
・音声認識させるファイルがmp3以外の場合は、'content-Type'の値を変更してください。
サポートされる音声ファイルはこちらに記載があります。
https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-audio-formats#formats
・URLはSpeech-to-Textのインスタンスを作成した場所によって異なります。東京リージョンに作成した場合は、'gateway-tok.watsonplatform.net'になります。
・スマートフォーマッティングを有効にするために、パラメータ:smart_formatting=trueを追加します。
実行結果
{
"results": [
{
"alternatives": [
{
"confidence": 0.95,
"transcript": "東京 オリンピック の 開会式 は 2,020 年 7月 24日 の 19時 30分 です "
}
],
"final": true
}
],
"result_index": 0
}
めでたしめでたし。

改めまして、どうゆうこと?
- その前に「Detect multiple speakers」について
複数人によって話された内容だと判断された場合、話者単位にラベルを付与してくれます。同じラベルが付与された場合は同じ人が発話した内容だと判断できますが、今の所、位置付けはベータであり、それほど精度が高いわけではないので参考程度の利用にとどめておくのが無難です。
最大6人まで認識できるとありますが、最適化は2人までとのこと。
They can handle up to six speakers, but more than two speakers can result in variable performance.
(注2)
- 何故「Detect multiple speakers」をOFFしなければいけないの?
デモアプリでも内部的には、スマートフォーマッティングが有効化(パラメータ:smart_formattingがtrue)されているのですが、「Detect multiple speakers」がチェックされている場合(オプションパラメータ:speaker_labelがtrueになる)は、スマートフォーマッティングが無効になります。
開発側に問い合わせたところ、speaker_labelとsmart_formattingは同時に使用できない(known limitation)とのこと。
誰かの疑問が多くの人の役に立ちますように...
スマートフォーマッティング機能を有効にすると随分と見やすくなりますね。
**【現場からの声】**シリーズ第二弾、いかがでしたでしょうか?
参考
(注1)[Smart Formatting]
(https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-output#smart_formatting)
(注2)[Speaker labels]
(https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-output#speaker_labels)
現場からの声シリーズ第一弾:あなたのそのアイディアがWatsonをもっとよくする