この記事は DeNA 24 新卒 Advent Calendar 2023 の 23 日目の記事です。
TL;DR
- DBMSの基本的な仕組みを知るのに有益だったリソース
- CMUのDBMS講義
- 先人の素晴らしい自作DBMSの解説記事&ソースコードリーディング
- 小さな小さな自作DBMSの設計と実装
- 最小限SELECTやINSERTなど基本的なSQLが動く
この記事のゴール
データベースの内部構成を超ざっくり理解するために有用なリソースを知り、そして(全開発者のロマンである)自作 DBMS に一歩踏み出すきっかけになればうれしいです。
モチベーション
自分は普段業務でアプリケーションのような割と高レイヤーな開発がメインなこともあって、ミドルウェアやOS、ネットワークと言った低めのレイヤーに憧れを持っており、この気持ちをまずは自作DBMSをやってみることによって解放してあげようと思ったことがきっかけです。
進め方
とはいっても実行計画すらまともに読めないレベルのDB知識だったため、まずはDBMSの仕組みやそこで使われているデータ構造やアルゴリズム、実装パターンについてInputすることにしました。そして(一刻も早くコードを書きたい気持ちを抑えながら)ある程度DBMSについて全体像が見えてから自作に移ることにしました。
Input
DBMS の基礎の勉強
DBMS を実装しようにも内部の仕組みについて何も知らず、何から始めればいいかさっぱり状況だったためまずは DBMS の基礎を勉強しました。
学習にはデータベースシステムの有名な CMU 講義を利用しました。
この講義は Youtube 動画と資料がありますが、自分は資料のみに目を通す形で学習を進めました。英語の資料ですが、Indexのデータ構造の仕組みや、賢くキャッシングしてデータアクセスを高速に行うバッファプールの話、クエリのプランニング、実際のクエリの実行まで全体像が非常にわかりやすくまとまっているのでおすすめです。
他にもDBMSの学習リソースはたくさんあるようです。後にご紹介するSamehadaDBの作者の方が有益な学習リソースをまとめてくれています。(自分もこれを参考にしてこれから知識増やしていきたい)
DBMS 実装の全体感をつかむ
ここまでで DBMS の全体像がある程度クリアになってきたので、実際の自作 DBMS の実装を読んでみることにしました。自分は Go の読み書きに慣れているため、Go 実装の DBMS をいくつか読んでみました。
bodoDB
以下の記事で解説されている DBMS です。Go で実装されていて、かつ実装がシンプルなので読みやすかったです。
リポジトリはこちらです。
SamehadaDB
bogoDB と同じく Go で実装されている DBMS です。この DBMS は上記の CMU 講義のために開発された BusTub という DB を Golang にポーティングする形で開発されています。bogoDB と比べるとコードベースが大きいので、こちらはくまなく読むのはひとまず諦めて、全体像を掴んで後の自作DBMS実装で設計に困った際に参考にしていました。
自作DBMS: GarakutaDB
ここからは自分の実装した、小さな小さなDBMS 「GarakutaDB」についての話です。
以下のリポジトリで実装しています。
対応する機能を決める
初めから風呂敷を広げすぎるとモチベーション的に続かないなと思ったため、まずは最低限DBMSとして動作するために必要な機能の実装をやり切ろうと決めました。
具体的にはざっくり以下のような方針にすることにしました。
- 入れる機能
- SELECT,INSERT,UPDATE,DELETE Statementを実行できる
- DDL は CREATE TABLE のみ実行できる
- トランザクションを利用できる
- ストレージ回りの実装
- Index
- B-tree で実装
- Catalog (テーブル定義)
- データに比べたらサイズはあまり大きくないのでJSON形式で保存
- Page (実データ保存の1単位)
- シリアライズ/デシリアライズは、bogoDB と同じく Protocol Buffer に任せることにした
- Index
- ※SQLパーサー
- ストレージ回りやクエリ実行に集中したかったため、ここはライブラリに頼る: https://github.com/xwb1989/sqlparser
- ※バッファプールはひとまず入れない
- 理由は、キャッシュアルゴリズムやディスクとの同期に気を付けた実装が恐らく大変&なくても成立する
- 全てディスクアクセスにする
- 軌道に乗ったらパフォーマンス改善で入れるようにしたい
設計と実装
ざっくりとした方針が決まったため、ここからはひたすらに実装を進めました。実装の詳細が気になる方はGarakutaDBのソースコードを見て頂ければと思うので、ここでは全体的な設計の紹介をさせてもらいます。
まず、全体的なアーキテクチャはこんな感じになっています。四角で囲われたエリアはGoのpackageに対応しています。
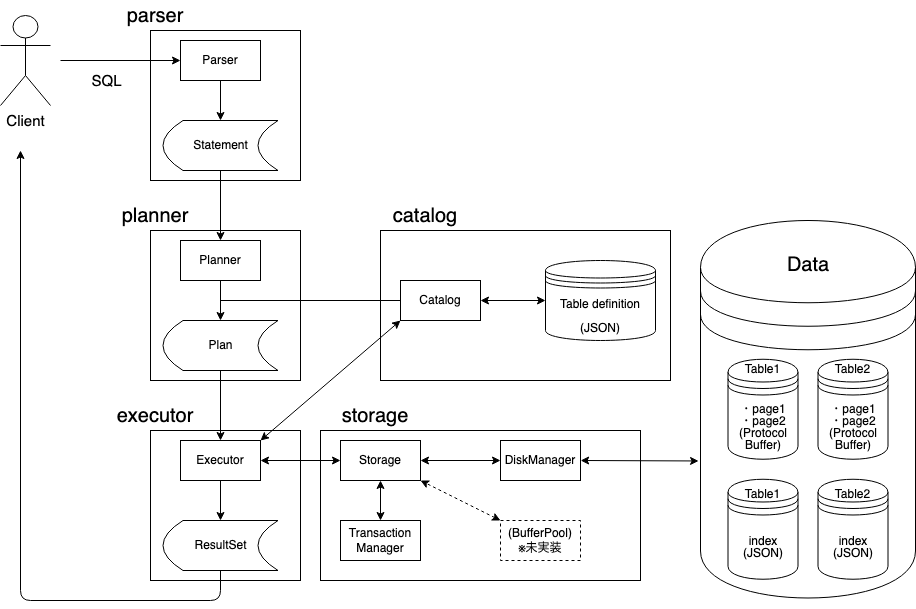
以下ではこの図を見ながら、SQLの実行から結果の返却までの流れを追っていきます。このアーキテクチャは上で紹介したbogoDB, SamehadaDB、CMUの講義で紹介されているDBMSのアーキテクチャと類似したものとなっているため、これを理解できれば他の自作DBMSのソースコードがある程度スムーズに読めるようになると思います。
Parse
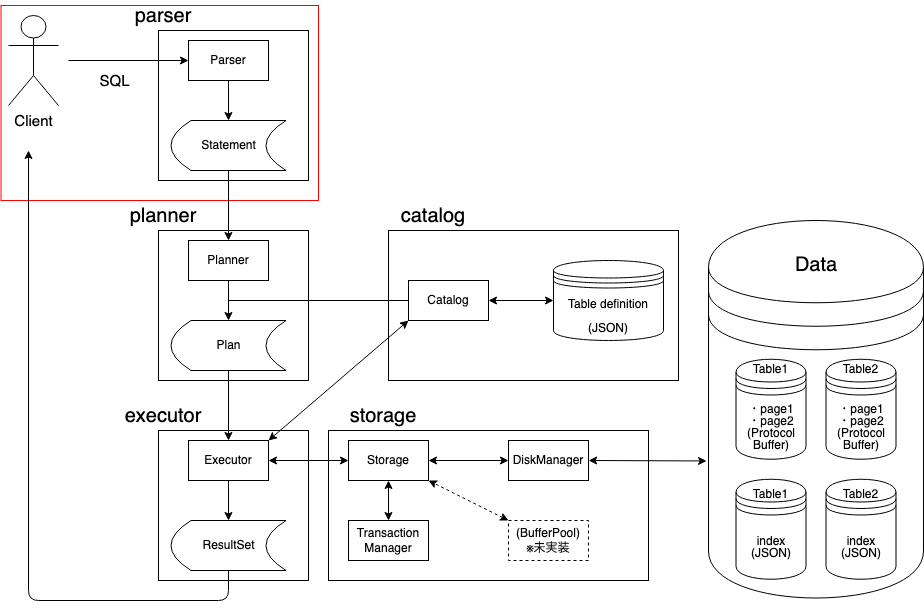
ユーザー(Client)からSQLの実行命令が来たら、まずはそのSQLをParserにかけ、Statementというデータ構造を得ます。ここにはSQLから抽出した、クエリ実行に必要な情報が入っています。例えばSELECT文であればこんな感じのStatementを作っています。本来はサブクエリなどサポートすべきものがたくさんありますが、まだ最低限の実装となっています。
Plan
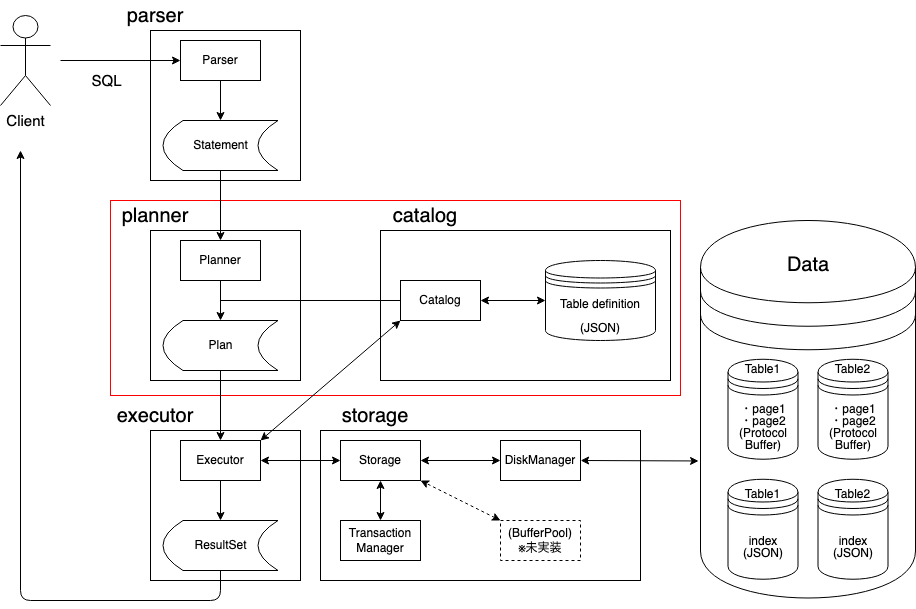
次にこのStatementをInputとしてPlannerの処理が実行されます。ここではStatementを読んで、実際にどのような処理を実行すればいいかを決定します。例えばSELECT文であれば、どのテーブルからどのカラムを取得するか、どのような条件で絞り込むか、といったことを決定し、クエリの実行計画としてPlanというデータ構造を得ます。またテーブル名やカラム名などのバリデーションも、Catalogというテーブル定義を扱うコンポーネントを利用してここで行います。
Execute
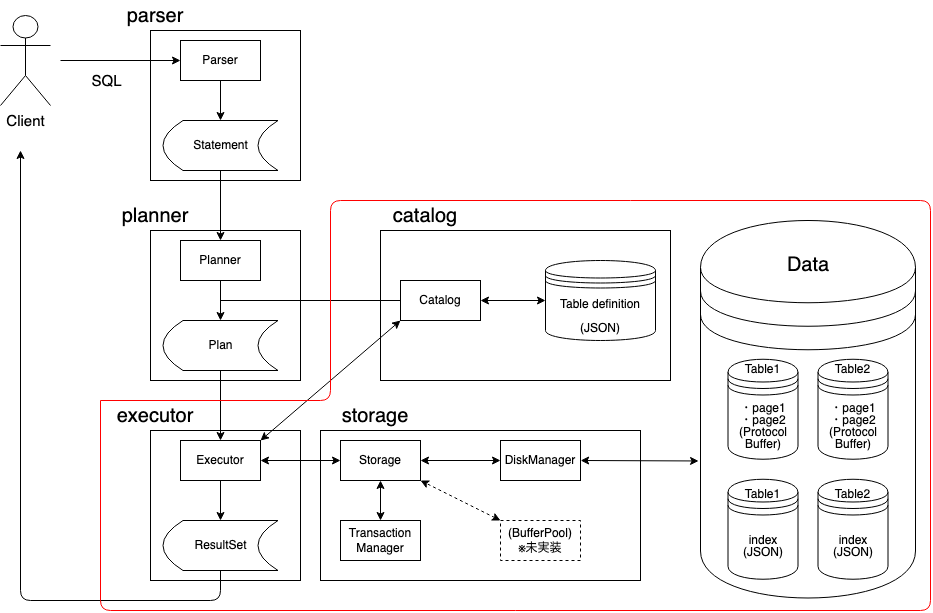
次に、このPlanをInputとしてExecutorの処理が実行されます。ここではPlanにある実行計画を、データの読み書きを行うStorageというコンポーネントを利用して実行します。
Storageは、IndexやTupleといったデータ構造を扱います。Tupleは行データを表す128バイトのデータ構造で、ディスクではこのTupleをProtocol Bufferでシリアライズし、それらをPageという単位でディスクに書き込みます。1Pageに入れるTupleの数は32にしました。つまり1Pageのサイズは約4KB (=128*32) です。
Indexは、Tupleのキーを管理するデータ構造です。ここではB-treeを実装しています。
また、ExecutorからTupleを読み書きするためのメソッドをStorageから提供していますが、このメソッド内部でTransactionの機能を実装しており、他トランザクションの未コミットのTupleを読み込まないようにしたり、他トランザクションでRead中のTupleに対しては書き込みを行わないようにしたりしています。
Executorの結果として、クエリの実行結果を表すResultSetという二次元の表形式のデータ構造を得、これをユーザー(Client)に返します。
終わりに
簡単なSQLが書けるだけのDBMS初心者でしたが、今回は小さな自作DBMSを完成させることができました。「データベースいつも使ってるけど、内部の仕組みについてはさっぱり、、」な人が仕組みを勉強して、あわよくば自作DBMSに取り組むきっかけになればとってもうれしいです。
そして今回作ったGarakutaDBは引き続き機能拡充を続けていくつもりなので、また面白いトピックがあれば記事にしたいと思います。
そして明日は @jmsrsyunrinsyunki さんの記事です!まだまだよろしくお願いします🏄♂️