今回は、AI初心者でも理解しやすいロジスティック回帰について解説する。
はじめに
ロジスティック回帰とは
ロジスティック回帰は、特定の事象が起こる確率を予測するために使用される統計手法です。ロジックとしては、単純パーセプトロン の活性化関数に シグモイド関数 を使用している。
計算グラフで書くと、以下のような感じ。
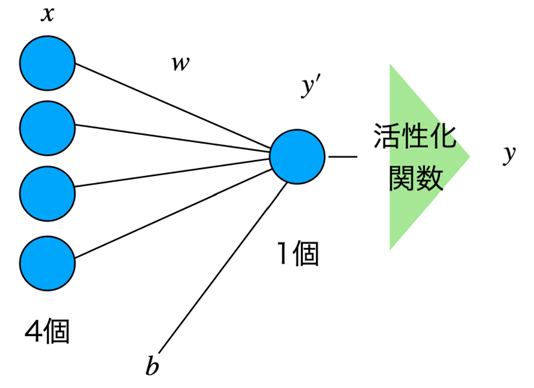
数式は以下のようになる。
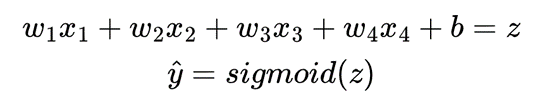
何ができるのか?
ロジスティック回帰は、ある因子から結果を予測するため、または既に出ている結果を説明するために用いられる。 例えば、顧客が商品を購入するかどうかや、病気の発症有無など、結果が2つのカテゴリーに分けられる場合に適している。
使いどころとしては、マーケティングでの応用が多く、顧客がキャンペーンにどのように反応するかを予測したり、特定の商品を購入するかどうかを分析するのに利用される。また、医療分野では、患者の検査値から病気の発生率を予測するために使われたり、金融での信用リスク評価にも応用される。
具体的な例としては、以下のような感じ。
・ある病院が患者のデータ(年齢、体重、血圧など)を用いて、特定の病気にかかるリスクを予測する
・顧客の過去の購買履歴や反応データから、キャンペーンに対する反応を予測し、より効果的なマーケティング戦略を立てる。
このように、ロジスティック回帰は多岐にわたる分野で有用なツールとして活用されています。実際のデータを用いた分析を通じて、より精度の高い予測や意思決定を行うことができるのです。
多クラスロジスティック回帰
通常のロジスティック回帰は2値分類しかできないが、うまく応用すれば多クラスの分類もできる。それが多クラスロジスティック回帰です。
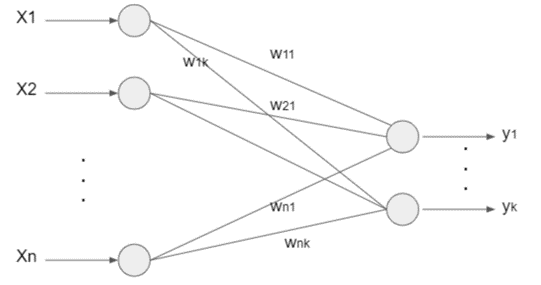
計算グラフとしては、以下のようになっている。
活性化関数でソフトマックス関数を用いるのがポイント。
出力層の各ノードは、各クラスに対応している。
y1,y2,y3・・・ykは、各々のクラスに当てはまる確率を表している。
たとえば、「y1 = 0.9の場合は、90%の確率でクラス1に分類される」みたいな感じ。
ソースコード例
以下のソースコードでは、アイリスデータセットを使用してロジスティック回帰モデルをトレーニングし、テストデータでモデルの精度を評価している。
scikit-learnは機械学習のための非常に便利なライブラリで、多くのアルゴリズムと便利なツールが含まれている。この例では、データセットをトレーニングセットとテストセットに分割し、モデルをトレーニングセットにフィットさせ、テストセットでモデルの精度を評価している。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# アイリスデータセットをロード
iris = load_iris()
X, y = iris.data, iris.target
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ロジスティック回帰モデルを初期化
model = LogisticRegression()
# モデルをトレーニングデータにフィットさせる
model.fit(X_train, y_train)
# テストデータで予測
predictions = model.predict(X_test)
# 精度を計算
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}')
実行結果
「Accuracy: 1.0」ということは、予測が完璧にできたってことですね。

参考にさせてもらったページ